-
Числа №8. Битовый формат
В этой заметке мы рассмотрим, как числа с плавающей запятой хранятся в памяти. Напомню, что в прошлый раз мы говорили о нормализации, и это был второй этап (после приведения десятичной дроби к двоичной).
Нормализованную дробь нужно хранить в битовом контейнере и при этом выдержать несколько требований. Запись должна быть плотной, чтобы вместить больше информации. Борьба идет за каждый бит. В идеале запись должна упростить некоторые операции, например, чтобы мы проверяли только конкретные биты, а не все число.
Еще запись должна быть монотонной: накрутка битов как в целом числе должна монотонно увеличивать вещественное число.
Давайте запишем несколько нормализованных дробей:
1.110011101 * 2^3 -1.010101 * 2^10 1.001 * 2^6 -1.11101 * 2^100Что между ними общего? Все их можно выразить тремя показателями:
- был ли спереди минус;
- степень двойки;
- биты дробной части.
Возьмем наше любимое число
-42.515625. В нормализованном виде оно равно:-1.01010100001 * 2^5Тройка его параметров выглядит так:
- 1 (впереди минус);
- 5 (степень);
01010100001(биты).
Вопрос: почему не учитывается целая часть? Та самая единица перед разделителем. Ответ – у нормализованной дроби целая часть всегда равна единице, поэтому она не хранится, а подразумевается. Имея тройку
(1, 5, 01010100001), получим исходное число:-1.01010100001 * 2^5Далее тройка записывается в 32 бита (4 байта). Старший бит хранит знак, еще восемь бит – степень. На дробную часть остается 23 бита, она называется мантиссой. И напомню – целая часть дроби, равная единице, подразумевается.
Со степенью есть одна тонкость: она записывается со смещением 127 (половина размерности). Смысл в том, чтобы записать знаковое число как беззнаковое. Это необходимо, чтобы обеспечить монотонное возрастание числа при накрутке битов. Так, к степени 5 будет прибавлено 127 и получится 132. В двоичном виде это 10000100.
Итак, в битовом виде число -42.515625 равно:
1 10000100 01010100001000000000000Пробелы разделяют смысловые части: знак, экспоненту с выравниванием, мантиссу. Битов 32, и они помещаются в 4 байта. Как с ними работать, рассмотрим позже.
Float определяет особые числа. Прежде всего это ноль, когда все биты нулевые. Особенность нуля в том, что его нельзя нормализовать. Помните, мы двигали разделитель, пока он не окажется за первым единичным битом? С нулем это невозможно – такого бита нет.
Еще одно интересное число – минус ноль:
1 00000000 00000000000000000000000Минус ноль полезен в инженерных расчетах, например при сходимости рядов. Есть ряды, которые стремятся к нулю, но попеременно слева и справа. Минус ноль означает, что дальнейшие вычисления дают ноль и при этом мы были слева от нуля.
Другие интересные случаи:
- экспонента 11111111, мантисса = 0 -> бесконечность (может быть отрицательной за счет первого бита)
- экспонента 11111111, мантисса не равна 0 -> NaN
- экспонента 0000000, мантисса не равна 0 -> субнормальные числа.
Субнормальные числа выровнены так, что экспонента равна нулю. Они поддерживаются процессорами, однако требуют внутренних преобразований.
Особые числа нельзя получить в лоб: чаще всего для этого возводят специальные флаги процессора, чтобы при
NaNне возбуждалось исключение. Ну или у вас JavaScript.В следующей заметке я планирую рассмотреть, как процессор складывает два числа с плавающей запятой.
-
Числа №7. Нормализация
Возвращаемся к числам. Мы выяснили, что любая десятичная дробь приводится к двоичной чередой делений и умножений на два. Чаще всего вы получите периодическую дробь как в случае с 0.1. Но бывают и удачные варианты: например, число
42.515625в двоичном представлении дает101010.100001.Легко заметить: проблем не создают те десятичные числа, которые являются половинками, четвертинками, восьмушками и так далее. Объяснение простое: помните таблицу умножения на 2 из прошлой заметки? Мы останавливаемся, когда получаем единицу, вычитаем из нее единицу и получаем ноль. Это значит, что очередное умножение должно вернуть 1. Если размотать алгоритм назад, на предыдущем шаге должно быть 0.5, перед ним — 0.25 и так далее.
Поэтому 25% — это ок: в двоичном виде 0.25 будет 0.01. А 10% — не ок: 0.1 будет
0.0(0011). Двоичная природа дает о себе знать.Хорошо, мы привели десятичную дробь к двоичной, что дальше? Как ее хранить? Наивное решение — выделить группу бит под целую и дробные части отдельно. Например, если float занимает 4 байта, разделим его пополам: по два байта под каждую часть. В два байта умещаются числа от -32,768 до 32,767. Выходит, подобный float сможет хранить числа от -32,768.32768 до 32,767.32767. Не густо, если сравнить с нормальным float.
Стандарт чисел с плавающей запятой предусматривает другой принцип хранения. Первый шаг на пути к нему — нормализовать двоичную дробь. Возьмем число 42.515625, которое привели к двоичному виду:
101010.100001Это же число я могу представить так:
101010.100001 * 2^0Оператор “крышка” означает возведение в степень. Два в нулевой степени равно единице, поэтому такое умножение ничего не изменит.
Далее: я могу побитово сдвинуть число влево или вправо и компенсировать это степенью двойки. Например, если я передвину точку влево, это равносильно тому, что поделить число на 2. Чтобы уравновесить это деление, я умножу число на два — то есть увеличу степень на единицу. Поэтому число можно записать так:
10101.0100001 * 2^(0+1)Оно ничуть не изменилось: это все то же число, только в другой записи.
Теперь сделаем обратное: сдвинем разделитель на два разряда вправо. Это равносильно тому, что дважды умножить число на 2. Чтобы компенсировать умножение, вычтем из степени двойки два:
1010101.00001 * 2^(0+1-2)Выходит, что разделитель можно двигать куда угодно и компенсировать его степенью. Если у нас безграничное число битов, точность не пострадает. Разумеется, на практике это не так: биты конечны, и передвижение разделителя приводит к тому, что их часть отбрасывается.
Так вот: что же значит нормализовать двоичную дробь? Ответ — сдвинуть разделитель так, чтобы он оказался позади первого единичного бита. При этом неважно, в какой части встречается этот бит: целой или дробной. Мы сканируем биты слева направо, находим первый единичный и передвигаем разделитель так, чтобы он был сразу за ним.
С числом
101010.100001 * 2^0нам повезло: оно начинается сразу с единицы (в отличии, скажем, от 0.00001). Потребуется пять сдвигов влево. Это равносильно тому, чтобы поделить число на 2 пять раз. Компенсация степени составит +5. Вот как выглядит нормализованное число:
1.01010100001 * 2^5Этой процедуре подвергаются все числа после перевода из десятичной системы к двоичной.
Теперь вспомним 0.1 — оно становится
0.0(0011)в двоичной системе. Чтобы разделитель оказался за единицей, нужно четыре сдвига вправо. Это равносильно умножению, поэтому степень уменьшается. Вот что было до:0.0(0011) * 2^0и после:
1.1(0011) * 2^-4Обращаю внимание: только сейчас мы рассмотрели ключевое свойство чисел с плавающей запятой — их разделитель плавает! Ни одна из прошлых заметок не раскрывала этого, но теперь вы в курсе. Как мы увидим позже, разделитель плавает и в других случаях, например при сложении чисел. Вот почему в их названии есть слово float.
После нормализации следует третий этап — битовая упаковка, который мы рассмотрим в следующей заметке.
-
Числа №6. 0.1 в двоичном виде
В прошлой заметке был подвох. Чтобы привести десятичную дробь к двоичной, я выбрал число
42.515625. Оно подобрано так, чтобы результат был коротким и без периода. Хорошо, а что нас ждет с другими числами? Давайте проверим.Возьмем самое банальное число: 0.1 (одну десятую). Приведем ее к двоичной дроби. Напомню, что нужно умножать дробную часть на два в цикле. Если результат меньше единицы, пишем ноль. Если больше, то пишем один и вычитаем единицу. Продолжаем до тех пор, пока не получим ноль.
Для 0.1 получается следующая таблица:
| number | x2 | bit | next | |--------|-----|-----|------| | 0.1 | 0.2 | 0 | 0.2 | | 0.2 | 0.4 | 0 | 0.4 | | 0.4 | 0.8 | 0 | 0.8 | | 0.8 | 1.6 | 1 | 0.6 | | 0.6 | 1.2 | 1 | 0.2 | | 0.2 | 0.4 | 0 | 0.4 | | 0.4 | 0.8 | 0 | 0.8 | | 0.8 | 1.6 | 1 | 0.6 | | 0.6 | 1.2 | 1 | 0.2 | | 0.2 | 0.4 | 0 | 0.4 | | 0.4 | 0.8 | 0 | 0.8 | | 0.8 | 1.6 | 1 | 0.6 | | 0.6 | 1.2 | 1 | 0.2 | ... 0.1 = 0.0001100110011... 0.1 = 0.0(0011)Очевидно, образовался повтор из
0011. Цикл никогда не закончится: это дробь с периодом. Как ни утруждайся, точно выразить ее в двоичной системе невозможно. Дело не в запасе точности: будь у нас хоть миллион битов, все равно мы потеряем какую-то часть после запятой.Таблица для 0.1 весьма интересна. Из нее следует, что числа 0.2, 0.4, 0.6, 0.8 и другие тоже приводят к периодическим дробям. Например, 0.2 – это всего лишь 0.1 * 2, то есть очередной шаг итерации. В двоичной системе 0.2 дает 0.(0011), то есть то же самое, только без первого нуля.
Теперь ясно, что происходит, когда вы пишете в коде
float f = 0.1. Десятичное 0.1 приводится к двоичной дроби, и получается0.0(0011)Дробь нормализуется, отсекаются лишние биты, и получается0.00011001100110011001101. Лишние биты могут как отсекаться, так и округлятся в зависимости от компилятора. Именно из-за округления на конце 01, а не 00.Поэтому то, что вы видите как
0.1, в двоичном представлении является0.00011001100110011001101. То же самое происходит с 0.2. Это косвенно дает ответ на вопрос об их сумме. Оба числа лишь приблизительно равны их десятичным литералам. Поэтому сумма тоже равна 0.3 лишь приблизительно.Предлагаю подумать: почему при печати числа 0.1 и 0.2 выглядят адекватно, а их сумма –
0.30000000000000004? Ведь мы выяснили, что в двоичном виде оба они – мешанина нулей и единиц. На это я отвечу в одной из следующих заметок. -
Числа №5. Знакомство с float
Переходим к числам с плавающей запятой, которые для краткости будем называть флотами. Они бывают половинной точности (16 бит), единичной (32, float), двойной (64, double) и больше. Для простоты будем работать с обычным 32-битным флотом.
Как мы выяснили, компьютер хранит числа в двоичном виде. Сложение и вычитание устроены по школьному принципу “в столбик”, и каждый разряд должен быть двоичным числом. По-другому компьютер не умеет – так устроены сумматоры (логические схемы): они принимают битовые входы по одному на разряд и выдают битовую маску разрядов результата. И еще бит переноса или переполнения.
Любое число, объявленное в коде, приводится к двоичному виду. Когда вы пишете в программе:
float f = 42.01нужно понимать, что 42.01 – это еще не число. Это литерал, который задает число. Литерал может быть другим, например 0.53 или
-4.5234e5. Важно, что на этапе лексера он хранится как строка с метаданными, мол, из этой штуки надо извлечь флоат.Дробные числа тоже приводятся к двоичному виду. В примере ниже – двоичная дробь:
1010111.011011Кого-то она вводит в ступор, но ничего особенного в ней нет. Мы привыкли к десятичным дробям, но аналогично записывается дробь с любым основанием. Например, вот дроби в шестнадцатеричной и восьмеричной системах счисления:
0xfa523.ac591 05627.6232Так что когда вы пишете
f = 42.515625, помните – после компиляции никакого числа42.515625нет. Оно преобразуется к двоичной дроби. Если точнее, это только первый шаг: после преобразования двоичная дробь нормализуется и помещается в специальный битовый контейнер. Но пока что мы рассмотрим только преобразование.Итак, как привести 42.515625 к двоичному виду? С целой частью все просто: делим на два и выписываем остаток, пока не получим ноль. Ниже – таблица для 42:
expr rem bit 42/2 21 0 21/2 10 1 10/2 5 0 5/2 2 1 2/2 1 0 1/2 0 1 = (101010)2Для остатка алгоритм, по сути, тот же самый: умножаем его на два (то есть делим на два в отрицательной степени). Если результат меньше единицы, пишем ноль и продолжаем. Если больше единицы, то пишем единицу, вычитаем ее и продолжаем.
Вот что получится для
0.515625:number *2 bit next 0.515625 1.03125 1 0.03125 0.03125 0.0625 0 0.0625 0.0625 0.125 0 0.125 0.125 0.25 0 0.25 0.25 0.5 0 0.5 0.5 1 1 - = (0.100001)2Итого – в двоичном виде
42.515625становится(101010.100001)2. Это все еще не конечный набор битов – впереди несколько других операций. Но уже на этом шаге видны некоторые проблемы. Я оставлю их на следующую заметку, а вы в качестве упражнения сделайте вот что: приведите к двоичному виду какие-нибудь числа вроде 1.1, 10.135 и так далее. Алгоритмы у вас есть. -
Числа №4. Натуральные дроби
Прежде чем мы перейдем к числам с плавающей запятой, напомню о натуральных дробях. Иногда с их помощью можно решить задачу, не прибегая к флоатам.
Натуральная дробь — это отношение двух целых чисел, например 1/2, 1/3, 4/9 и так далее. Их достоинство в том, что иногда из них можно выйти обратно к целым числам. Например, кто-то меняет коров на лошадей по курсу 2/3, то есть за две коровы — три лошади. В случае с флоатами курс был бы 0.666666… или 0.(6) в периоде. Далее нам дают 6 лошадей. Умножаем 6 на 0.66666… и получаем 3.999996 коровы. Округляем до четырех и совершаем обмен. Но если учесть, что:
- коров и лошадей может быть много;
- операции совершаются часто;
- операции строятся в цепочку: коровы на лошадей, лошади на кур и все это по разным курсам,
то погрешность рано или поздно даст о себе знать.
Если хранить курс обмена в виде натуральной дроби 2/3, то умножение на 6 даст целое число:
2 6 12 - * - = -- = 4 3 1 3Легко написать класс для работы с натуральными дробями. Это пара целых чисел. Операции над парой повторяют школьную программу. Чтобы сложить две дроби, их проводят к общему знаменателю. Например, чтобы сложить 1/6 и 1/12, мы:
- приводим 1/6 к знаменателю 12 и получаем 2/12;
- складываем числители;
- сокращаем дробь.
1 1 2 1 3 1 - + -- = -- + -- = -- = - 6 12 12 12 12 4Вычитание — то же самое, только меняется знак. Умножение несложное: перемножаем числители и знаменатели, затем сокращаем результат. Деление аналогично, только вторая дробь переворачивается.
Для всех этих действий нужны две вещи: наименьшее общее кратное (НОК) и наибольший общий делитель (НОД). Принцип их поиска был найден еще греками.
В Кложе из коробки идет тип
Ratio, который устроен как пара чиселBigInteger. Если я поделю одно целое на другое, и результат дает остаток, то получу дробь:(/ 2 3) 2/3 ;; clоure.lang.RatioУмножив дробь на целое, которое сокращает знаменатель, я получу целое:
(* (/ 2 3) 6) 4 ;; clоjure.lang.BigIntНикаких 3.999996 коровы, все честно. Здесь Рич Хикки ничего не придумал, а взял реализацию из Common Lisp, который еще до вашего рождения считал натуральные дроби из коробки.
Понимаю, что примеры с лошадьми звучат забавно. Но есть область, где натуральные дроби в высшей степени оправданы — недвижимость. Доли собственников хранятся в натуральных дробях, например у Васи — 1/2, у Пети — 1/3, у Маши — 1/6. В сумме они дают единицу. Предположим, Вася поделил свою долю 1/2 между Колей и Жорой: каждый получил по 1/4 от общей площади. Сумма долей по-прежнему дает единицу.
В недвижимости бывают и более сложные доли. Скажем, недавно я участвовал в сделке, где моя доля была 49/125. Так получилось в результате наследства, выкупа долей у других собственников и так далее.
Приступая к делению, подумайте: можно ли выразить его натуральной дробью. Не всегда это возможно, но если все-таки да, вы обезопасите себя от проблем, связанных с флотами. Об этих проблемах мы поговорим в следующих заметках.
-
Числа №3. Сложение
Продолжаем тему чисел, на этот раз – что-то более серьезное. Поговорим, как компьютеры складывают числа. На эту тему написаны хорошие статьи и книги, поэтому в формате заметки изложить тему невозможно. Напишу только то, что считаю наиболее важным.
Мы, люди, учимся считать в десятичной системе счисления. Если нужно сложить два числа, мы делаем это в столбик. Мы складываем разряды, при этом может случиться переполнение, например 5 + 7 = 12. В текущем разряде останется 2, а старший переедет к следующему, и нужно учесть его при сложении. Покажем это на примере:
1 1 23.55 12.97 ----- 36.52Мы складываем по две десятичные цифры за раз: 2 и 3, 4 и 9 и так далее. Компьютер делает то же самое, но в двоичном виде. Он не может сложить 2 и 3 за один машинный такт – это невозможно. Его система счисления доведена до предела: в ней только нули и единицы. Такой подход следует из природы полупроводников и транзисторов: они принимают два сигнала и выдают один. Были машины на троичной логике, но они не получили распространения.
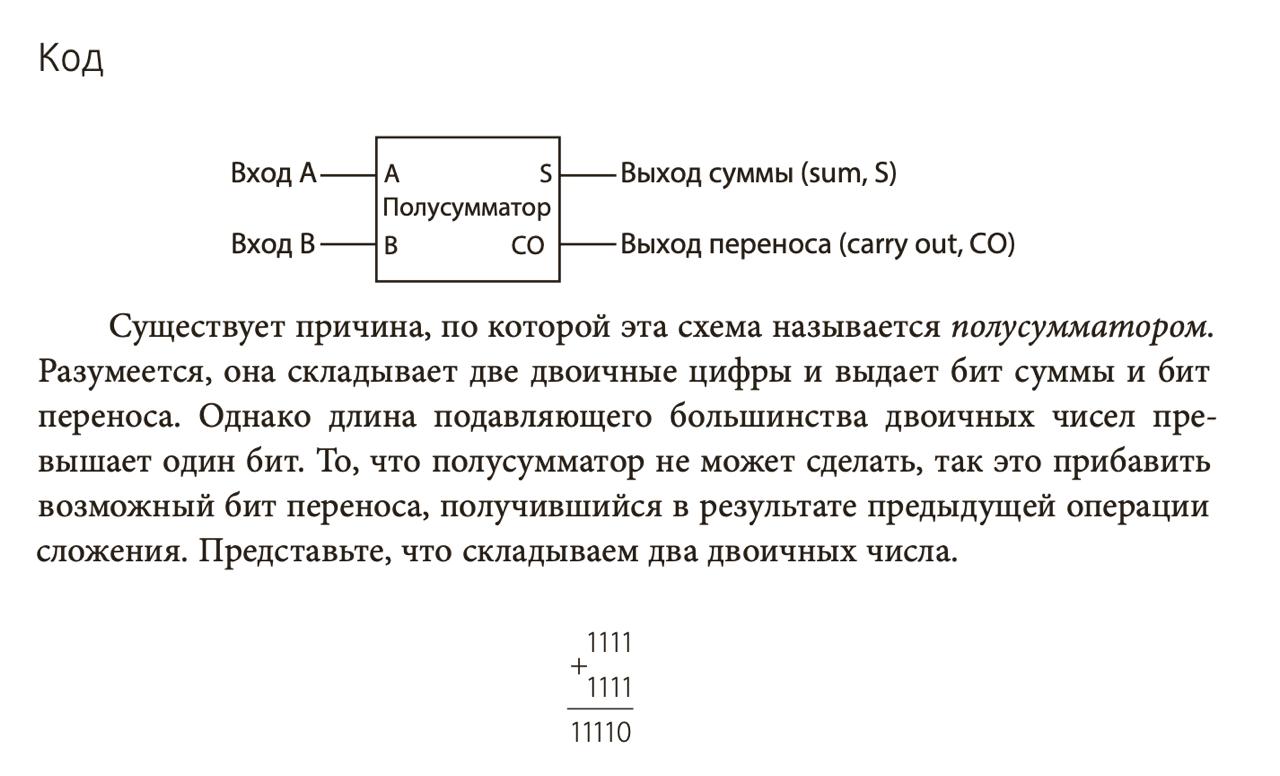
Чтобы сложить два бита, для начала проектируют полусумматор. Это логический элемент, который состоит из других элементов проще. Полусумматор принимает два бита (входы) и возвращает бит результата. Если подать нули, результат будет ноль, если 0 и 1 или наоборот, то 1.
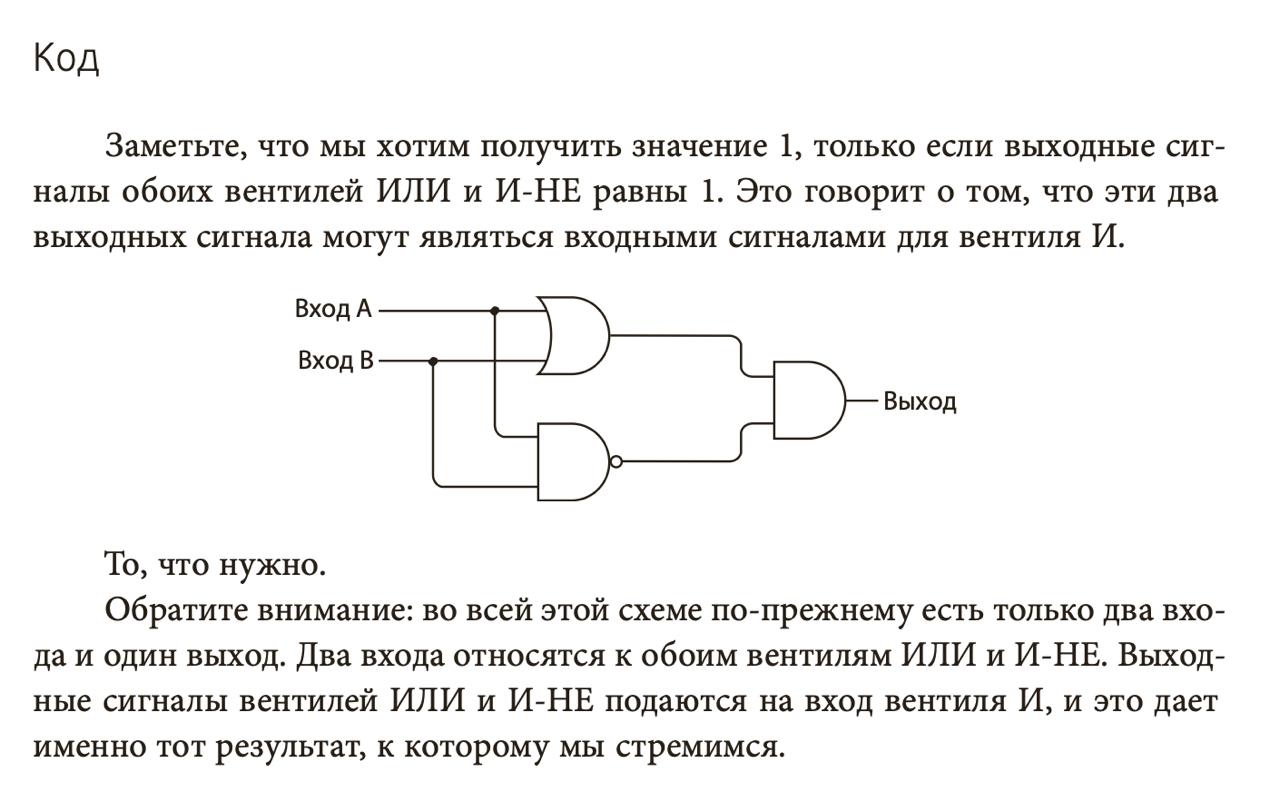
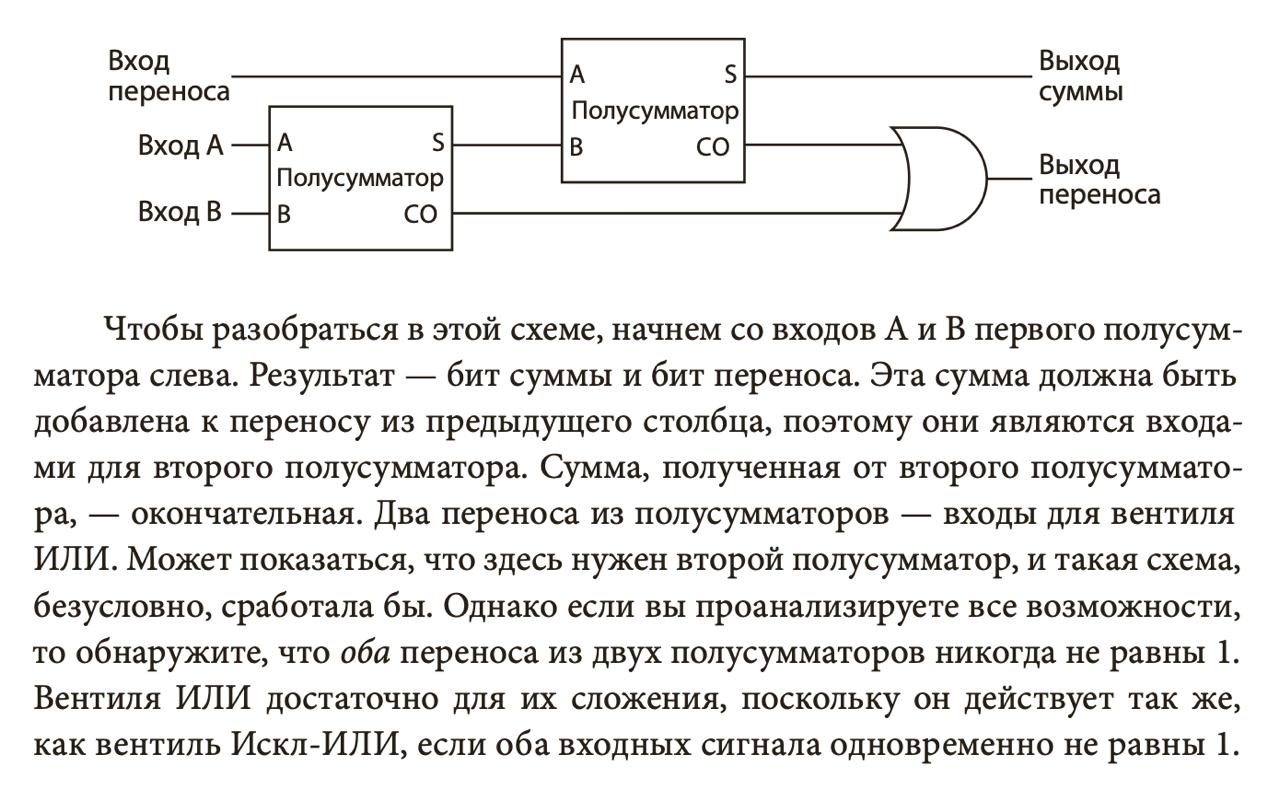
Почему “полу”? Потому что если подать 1 и 1, мы должны получить 0 (результат) и 1 (бит переноса). У полусумматора нет переноса, поэтому бит 1 пропадет. Чтобы этого не случилось, из двух полусумматоров делают полный. Он принимает не два, а три входа: два бита (входы) и перенос, который, возможно, образовался при сложении прошлого разряда.
Множество сумматоров объединяют в каскад, и можно складывать многобитные числа: 4-, 8-, 16- и 32-битные. Пусть вас не смущают четырехбитные числа: такие архитектуры были в старых калькуляторах. Обратите внимание, что последний флаг переноса никуда не делся: складывая числа, мы должны быть готовы к тому, что последний разряд переполнился, и с этим нужно что-то делать.
Проблему последнего переноса решают так: этот бит подключается к специальному регистру флагов. У процессора есть регистр, где каждый бит означает особое состояние. Один из них определяет, был ли перенос в последнем разряде (carry flag). Есть особая команда семейства jump, которая переходит на нужный адрес, если флаг не ноль. В высокоуровневых языках по этому адресу находится код, который возбуждает исключение.
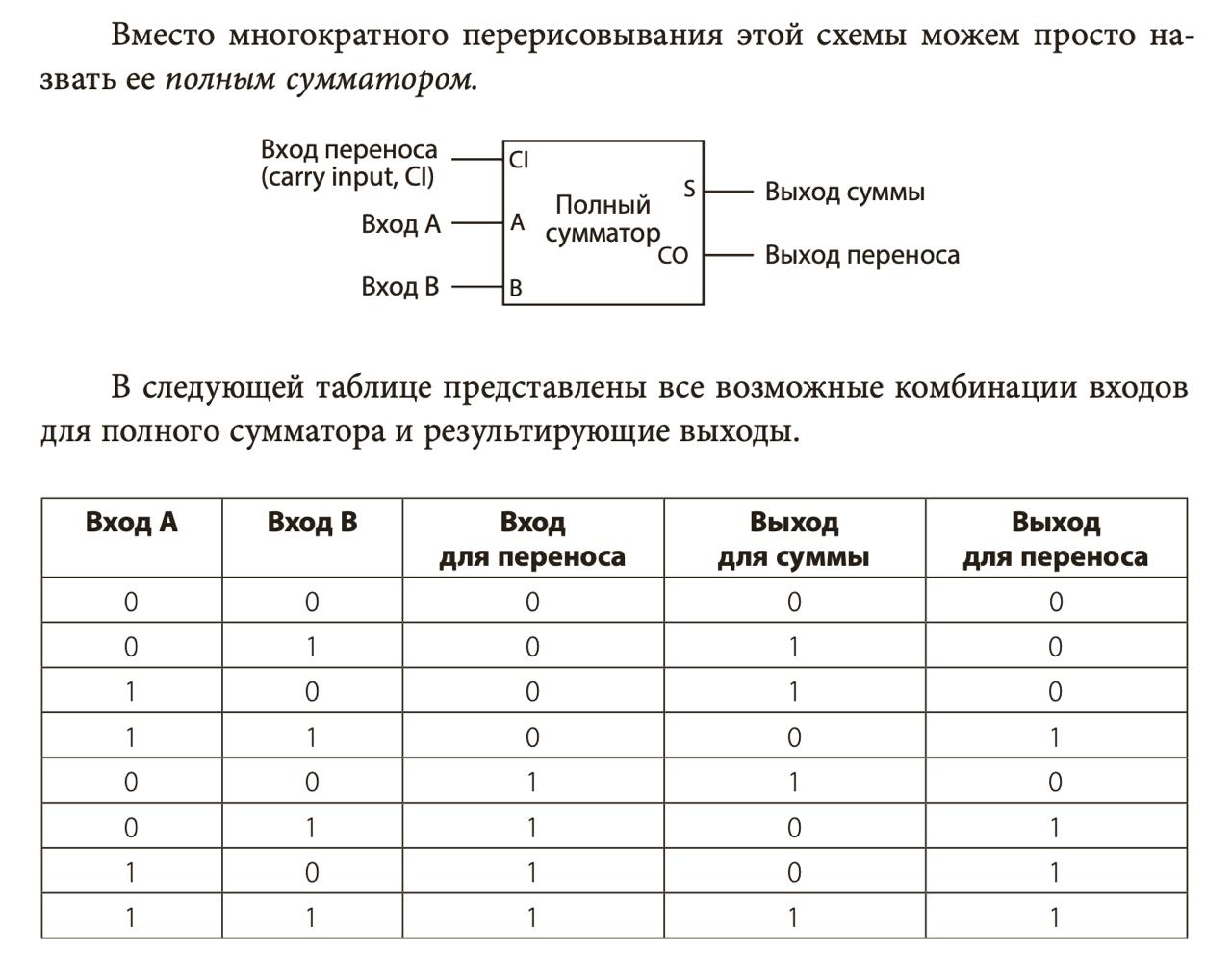
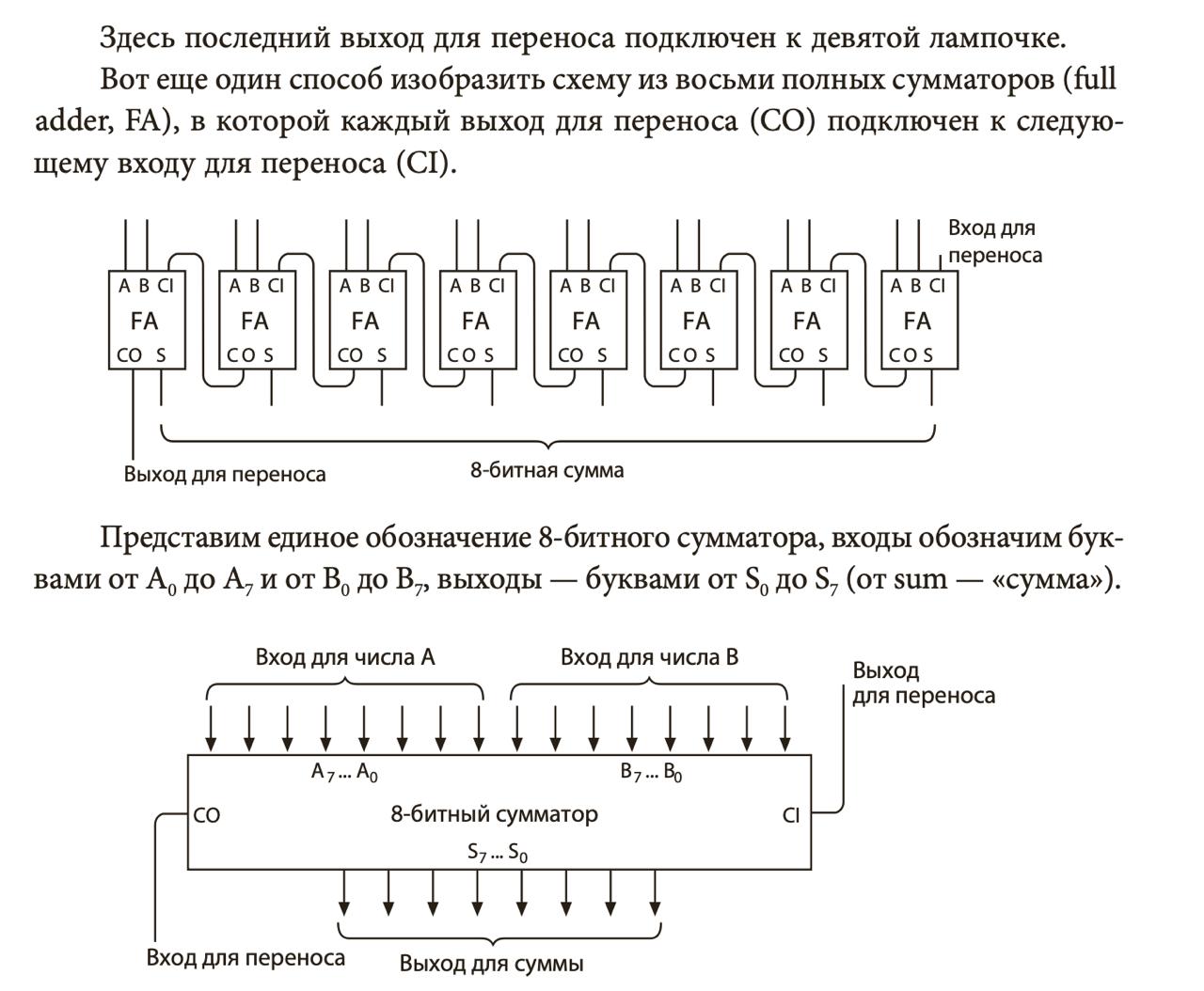
До сих пор я использовал слова “перенос” и “переполнение” вместе, но на самом деле это разные вещи. Перенос (carry) используется для беззнаковых чисел, а для знаковых мы говорим о переполнении (overflow). В регистре флагов это два разных бита и две разные команды jump.
В целом процессор складывает числа как мы: столбиком по разрядам. Разница в том, что размерность разряда минимальна: всего два значения. Перенос работает как в школьной математике. Последний перенос заносится в регистр флагов, чтобы после условной команды ADD AX BX мы могли бы проверить, был ли выход за последний разряд. Понимание этих принципов пригодится нам в следующих заметках.
Картинки взяты из замечательной книги “Код: тайный язык информатики”. Горячо рекомендую ее к прочтению.
-
Числа №2. Арабские числа
В современном мире пользуются арабскими числами. Они удобны и не зря вытеснили другие системы счисления. Есть у них, однако, момент, на который редко обращают внимание: мы читаем их не слева направо, а справа налево.
Вы, конечно, скажете: Иван, ты несешь ахинею. Арабские числа читаются слева направо, например
12.423читается как двенадцать тысяч четыреста двадцать три. Но чтобы прочитать тысячи, сотни и так далее, сперва нужно распрасить их. Встретив число, сперва мы переходим в конец и шагаем по три цифры, чтобы определить сотни, тысячи, миллионы и так далее. Только потом, распарсив, мы читаем число.На коротких числах это незаметно, и уж тем более, если кто-то расставил разделители: точки, полупробелы. Но попробуйте прочесть это число:
5512346134У вас не получится. Сначала вы мысленно добавите разделители:
5 512 346 134и таким образом поймете, что первая 5 – это миллиарды. Только теперь число можно прочесть.
Я уж не говорю о том, что нельзя прочитать число, если его конец неизвестен.
Сами арабы не страдали от проблем с написанием. В арабском и его диалектах слова читаются справа налево, и числа тоже читались справа налево. Другими словами, порядок чтения арабских цифр был нативным: он совпадал с направлением письма.
Пример: составим фразу “У меня 125 овец”. Сильно упрощая, на арабском она выглядела бы так:
.цево 125 янем УКогда носитель арабского читает эту фразу, он воспринимает цифру 125 как пять единиц, два десятка и одна сотня.
При этом число записано одинаково: в обоих случаях это 125. Однако его чтение отличается: арабы начинают с младшего порядка и идут по нарастанию. Западный человек читает от старшего ко младшему, при этом он либо распознает порядки, если число короткое, либо мысленно вставляет их.
Если бы мы изменили порядок арабских чисел в соответствии с направлением письма, получилось бы так: “У меня 521 овец”: пять единиц, два десятка и одна сотня. Это удобно для длинных чисел. Мы уже выяснили, что число
5512346134нельзя прочитать, пока не расставишь разделители. Но если бы оно было записано задом наперед:4316432155, то вот как я бы его прочел: четыре тридцать сто шесть сорок триста тысяч два десять пятьсот миллионов пять миллиардов. Один проход.
Ясно, что хватились мы поздновато: вряд ли кто-то будет менять направление чисел. Вдобавок и мы, и арабы используем одну и ту же запись, что довольно удобно. Представьте, если бы в зависимости от языка нужно было бы зеркалить цифры! Поэтому то, что сейчас, хорошо. Просто не мешает иной раз посмотреть на привычное под другим углом.
-
Чистка компа
Заметка самому себе. Если у вас стационарный комп, чистите его каждые два года, а в идеале – каждый год. Заодно меняйте термопасту.
Дело в том, что в компьютере много вентиляторов. Пара сзади, пара спереди, кулер на процессоре, пара мелких на материнке, два-три на видеокарте, и еще блок питания. В сумме их где-то десять. Все они засасывают пыль, волосы, шерсть. Пыль изнашивает вентили, удерживает тепло и так далее.
Базовую пыль можно убрать пылесосом с тонкой насадкой. Но есть много мест, куда ему не добраться. Поэтому самое лучшее – разобрать комп на части и протереть каждую из них. Заодно скрутить материнку и очистить пыль за ней.
Много пыли скапливается в радиаторе видеокарты. Если аккуратно потянуть вентиляторы, их можно снять, и откроется радиатор. Однако так легко сломать лопасти. Если таки сломали, приклейте лопасть обычным супер-клеем (нужно сильно прижать) и зафиксируйте скотчем с обеих сторон.
Пригодится пинцет: просуньте его между лопастями и выдерните клочки пыли из радиатора. Также удалите пыль, застрявшую между шлейфами – ее там тоже немало.
Много грязи скапливается в блоке питания. Не бойтесь его разбирать: гарантия на блок дается в лучшем случае на два-три года, и за это время он не успеет наглотаться пыли. На пятый год это может стать проблемой, а гарантия вам уже не поможет. На фотографии ниже – блок, который я не чистил со дня покупки (около 8 лет).
Если вы не знали – пыль неплохо горит и порой становится причиной пожара.
Термопаста тоже деградирует. Покупайте марку М6, а лучше М8. Старую сотрите салфеткой; не используйте ватные палочки, потому что они оставляют волоски. Новой пасты должно быть с горошину. Не размазывайте ее как варенье по хлебу, потому что возникнут пустоты с воздухом.
Спонтанные выключения компа – один из признаков, что пора менять термопасту. Об этом легко забыть: я несколько месяцев тупил, не понимая, что делать, прежде чем вспомнил – термопаста! Конечно, могут быть и другие причины, но в моем случае все исправилось чисткой. Не забывайте об этой простой процедуре.
PS: на самом деле комп целиком почистил мой сын, а я просто умничаю.

-
Глава 3. JSON в таблицах
Главы
- Введение в документы
- Базовые возможности JSON
- JSON в таблицах
- Индексирование JSON
- Ограничения в документах
- Язык путей JSONPath
- Отчеты, функции, расписание
- Функции на языке Python
- Версионирование и архивация документов
- Релевантный поиск
Содержание
- Главы
- Определение сущности
- Дизайн таблицы
- Тосты, сжатие и хранение
- Множественность и статистика
- Генерация и вставка
- Псевдослучайные значения
- Чтение
- Вставка
- Обновление
- Вставка с обновлением (UPSERT)
- Удаление
До сих пор мы работали с документами, которые не превышали нескольких строк. На практике документы объемны и занимают сотни килобайт. В этой главе мы обсудим, как хранить JSON в таблицах, читать его, изменять и удалять – полностью и частично.
Для начала обсудим задачи, которые выполним ниже по тексту. План таков:
-
мы определим сущность, с которой будем работать до конца книги. Ее структура повторяет аналог из проекта, в котором работал автор. Сущность содержит разные типы данных и вложенные поля. На ней мы опробуем техники, которые уже рассмотрели, и многое другое.
-
Подготовим таблицу для документов. Здесь же мы рассмотрим сжатие типов (compression) и понятие множественности (cardinality).
-
Запишем в базу миллион документов. Это будут не клоны одной и той же записи, а псевдослучайные данные. Пороги случайности мы определим сами.
-
Выполним простые запросы: поиск по ключу, поиск по реквизитам, обновление, вставку с конфликтом и другие частые операции.
Цель – получить миллион разнообразных документов и опробовать на них все, что мы изучили.
-
Числа №1. Счет на пальцах
Несколько постов на тему чисел. Начнем с чего-нибудь несерьезного, например счета на пальцах.
Мы привыкли разгибать пальцы при счете. На две руки приходится десять пальцев, а этого мало – хотелось бы больше.
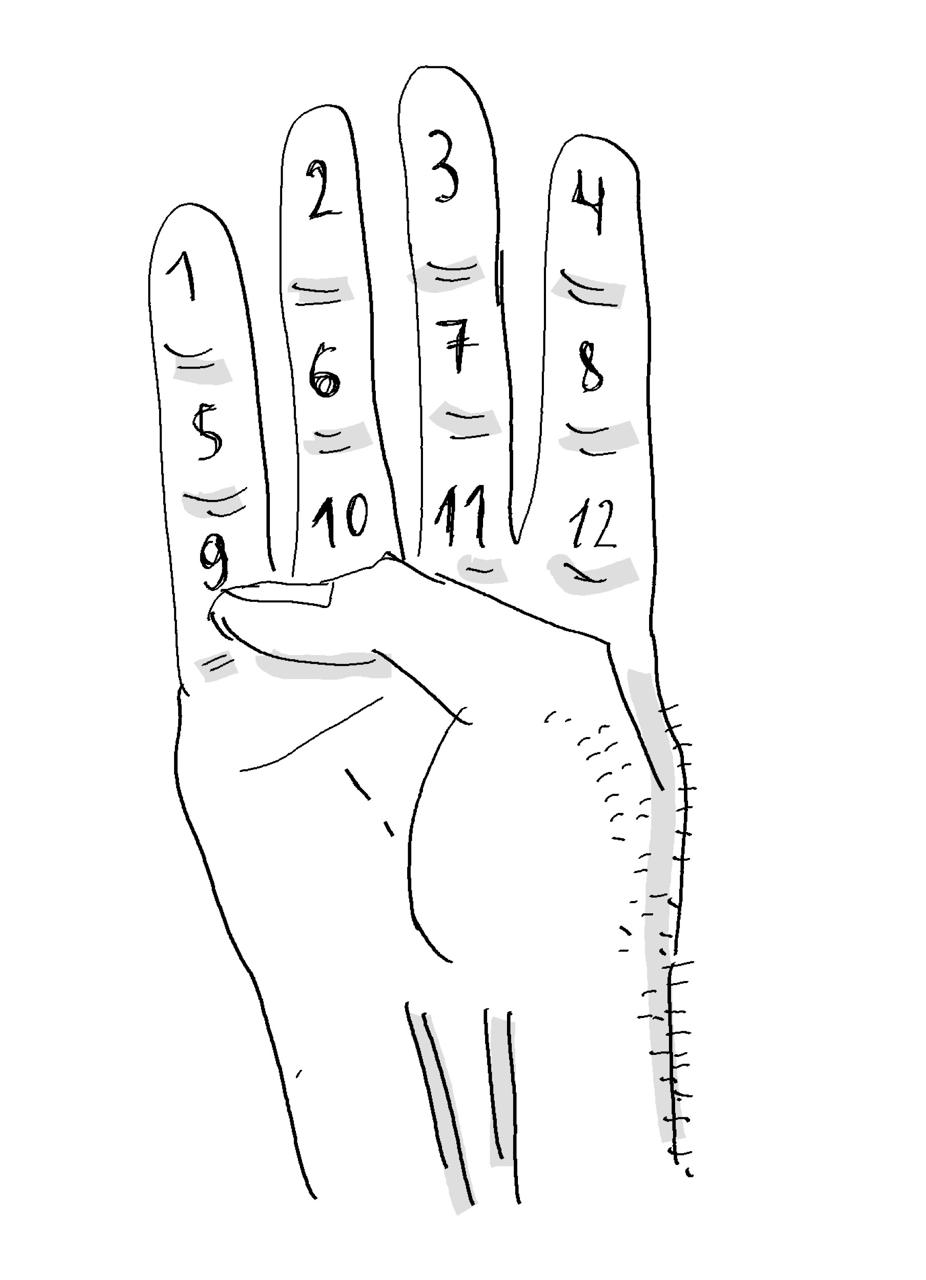
У каких-то шумеров или Майя (не помню точно) был счет на фалангах. Берем все пальцы кроме большого; у каждого по три фаланги. На одной руке их, следовательно, двенадцать. Считают, прикладывая большой палец фаланге. Можно слева направо и вниз, можно снизу вверх и направо – как душе угодно.
Две руки — 24 единицы! Почти в два с половиной раза больше, чем обычно.
Когда я прочитал про эту систему, то некоторое время ей пользовался. Привыкаешь быстро – это дело механики. Когда подходишь к десяти, возникает странное чувство – вроде бы много, а пальцы не кончились! И даже руку не сменил.
Счет на фалангах – один из частных случаев счета на пальцах. Разные народы придумали способы, чтобы обойти лимит в десять пальцев. Ознакомьтесь в Википедии.
Writing on programming, education, books and negotiations.