-
Русская речь в фильмах
Иногда русская озвучка бывает, мягко говоря, спорной. Актеры кричат в тех местах, где персонаж шепчет; интонация странная, пропадают акценты, идиомы, игра слов. Так что если вам позволяют условия (знаете язык, партнер(ша) не возражает), потребляйте фильмы и игры в оригинале (или хотя бы ключевые сцены). У этого правила, однако, есть исключение: иногда в оригинале звучит русская речь. В таком исполнении, что хочется не слышать ее ни за какие деньги.
Имеем американского персонажа. Всем он хорош: и силен, и умен, и женщину спас. Одна беда – русского происхождения. И вот на середине фильма всплывает русская мафия, дядюшка или бывшая, с которыми герой изъясняется по-русски. То есть как по-русски: в Гугл-транслейт набивается текст на английском, тот выдает русский транслит. Актер учит его наизусть как абракадабру: “Татиана, как дафно ти юже десь?” Татьяна: “Пивет Джон, две ньидели ка пиехаля”.
Разумеется, у меня нет претензий к американскому зрителю. Им без разницы – русский, бурятский, венгерский – все это наречия каких-то варваров. Но куда смотрят создатели фильма? Разные факт-чекеры и консультанты, которые отвечают за реалистичность сцен. Неужели нельзя найти русскоговорящего актера с похожим голосом и озвучить пару фраз? В чем сложность?
Когда русский бандит обращается к американцам, проблемы не возникает. Тут даже переигрывают: “лэт мы спык ынглиш фр-р-ром май хар-р-рт”. Плохой персонаж всегда будет с рокочущим “р”. Как обезьянничать, так все мастера. А как насчет нормальной речи?
Много лет назад со мной был случай. Я играл в одну игру, и там на хороших парней (американцев) напали плохие (конечно, русские). Атаку отбили, и одного молодого бандита взяли в плен. А он оплакивает убитую шальной пулей сестру: Наташа, очнись, солнышко, пойдем… и все это – на чистом русском. Ощущение, словно за спиной кто-то говорит. Я аж подскочил на стуле.
Из Википедии и всяких ссылок я узнал, что этот фрагмент – инициатива русскоязычного сотрудника студии. Изначально дорожку записали как есть – транслитом. Вообразите, как звучали слова скорби из уст человека, который не знает языка? Картавые “встаувай, Натащья, ти живуа? Нье умиай!” Все это – в момент смерти? Это даже не кринж, а пиздец, и так делать нельзя.
Разработчик прекрасно это понимал и сделал вот что. Когда все ушли, он записал дорожку на нормальном русском и подменил в ассетах. Никто не заметил, и русская речь ушла в релиз. Позже игру хвалили в том числе и за это: впервые за вечность в игре адекватная речь, а не транслит.
Выходит, что инди-студия смогла, а Голливуд не может? Слабо верится.
Интересно, что в локализации фильмов мы не сталкиваемся с подобным кринжем: герой говорит с родными на нормальном языке, в то время как в оригинале звучит тарабарщина. Оригинал, увы, нет-нет да подкинет подобный сюрприз. Длятся подобные сцены недолго, но даже их хватает, чтобы свалится на пол от отчаяния и стыда.
-
Kill the cookie banner
Как-то давно, аж в 2023 году, я жаловался на куко-баннеры. Проблема вот в чем: сегодня почти любой сайт выстреливает плашкой, что использует куки. Десятилетиями мы с этим жили, но пришли европейские бюрократы и сказали: непорядок. Надо не только уведомлять, но и предлагать пользователю выбор. А то как же он, бедняга, без выбора? Изволь: все куки, только обязательные, необязательные и обязательные, свой выбор. Дополнительно прилагается простыня о том, как эти куки используются.
За европейскими бюрократами подтянулись другие по всему миру. Одновременно нам не повезло с дизайнерами: никто не стал договариваться, каждый пошел кто в лес, кто по дрова. Один сайт показывает выпадашку, другой две, третий – полоску, четвертый прячет контент и так далее.
И вот мечта еврочиновника сбылась: сайты уведомляют. Стало ли пользователю удобней и безопасней? Нелепый вопрос. Пользователю ничего не остается как ставить плагин “I don’t care about cookies”. Схожую функциональность добавили в блокировщики рекламы.
Последнее особенно забавно: между рекламой и куко-баннером нет разницы. Не все ли равно, что там в выпадашке? То и другое загораживает контент, поэтому выход — резать.
На мой взгляд, совершенно очевиден следующий факт. Если каждый сайт спрашивает о какой-то ерунде, эту ерунду выносят в настройки браузера. Должен быть особый раздел, где я жму галочку “пофиг на куки”. Это свойство доступно в JavaScript; сайт читает его и определяет, показывать окно или нет. Другой способ без JavaScript – отправить заголовок вида
X-Cookie-Policy-Preferences: pofigБэкенд проверяет значение на множество
all,none,essential-onlyи другие и определяет, показывать окно или нет.Можно написать спецификацию, которая учитывает важность кук, их характер (только айтишник, личные данные, настройки сайта) факт их передачи сторонним лицам и так далее. Все это технические детали, но важно одно: когда есть соглашение, под него можно сделать интерфейс.
Повторюсь, текущая ситуация, когда каждый сайт кукарекает о куках, никуда не годится. Чиновник доволен, а нам-то с вами этим пользоваться. Вспомните, что было, когда в браузеры добавили уведомления. Каждый сайт при открытии долбил: включи нотификации, включи нотификации, че ты как лох, включи-включи-включи. А еще дай доступ к геолокации и трекингу, чтобы два раза не вставать. Позже нотификации и прочий мусор вынесли в настройки: можно задать глобальное умолчание и исключения.
(В скобках: удивляюсь, почему нет глобального запрета на перевод страницы. Открыл сайт на английском – перевести на русский? Открыл на русском – перевести на английский? Чинится системной опцией в Firefox, а настройки “никогда ничего не переводить” до сих пор нет).
Так вот, к чему это все. Появилась инициатива под названием Kill the cookie banner! От каждой страны набираются волонтеры, которые будут сражаться за то, чтобы куко-баннер настраивался в браузере. Проект полезен уже тем, что показывает: есть люди, которым не все равно. Не хомяки вроде меня с плагином-банерорезкой, а те, кто хотят что-то изменить. Искренне желаю им успехов, пусть даже локальных, например на территории отдельных стран.
Напоследок напомню, что в интернете все еще есть сайты, которые прекрасно работают без кук. Например, мой. Посещайте его!
-
Блокнот
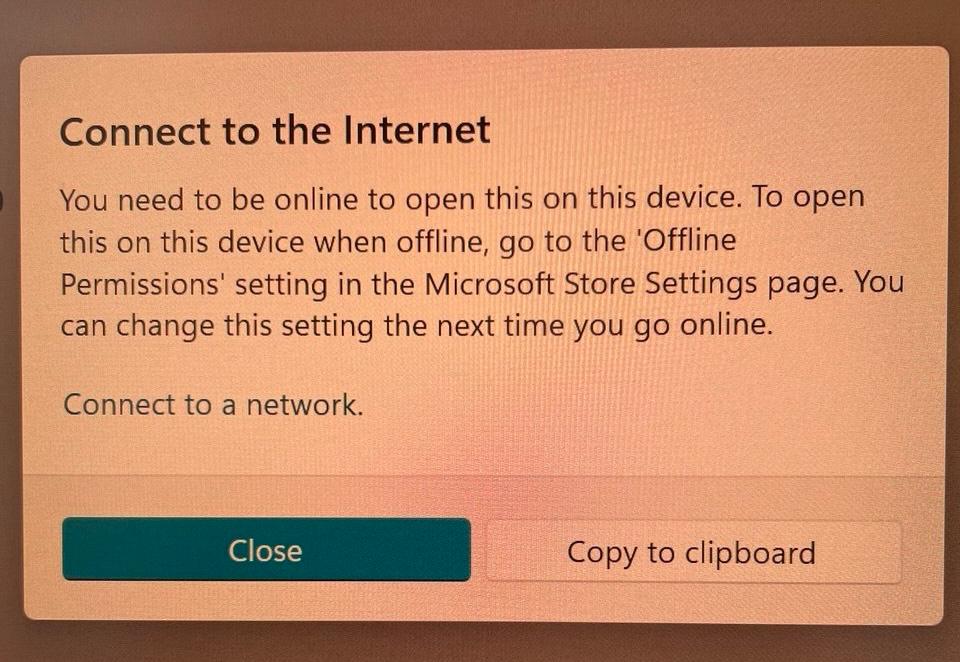
Оказывается, на 11 винде нельзя открыть блокнот (notepad.exe), если нет подключения к интернету. Причем как и все у микрософта, даже это ограничение сделано через задницу. По нажатию на иконку 20 секунд ничего не происходит, после чего вылезает плашка:
“Я не могу запустить это на этом устройстве. Чтобы запустить это, идите туда-то…”.
Зыс он зыс, ран зыс. Господи, какие же беспросветные уроды!
Честно говоря, не знаю, как можно пользоваться операционкой, где даже блокнот не запустишь без приключений. Яблочный софт в последнее время тоже не сахар, но хотя бы блокнот все еще открывается.
Кстати, недавно на работе была драма: люди обновили Edge и потеряли закладки, куки, историю. Взамен получили чистый браузер с приветствием: добро пожаловать в Edge!
Недаром Микрософт в последнее время называют Микрослопом. Все сходится.
-
Ссылки в терминале
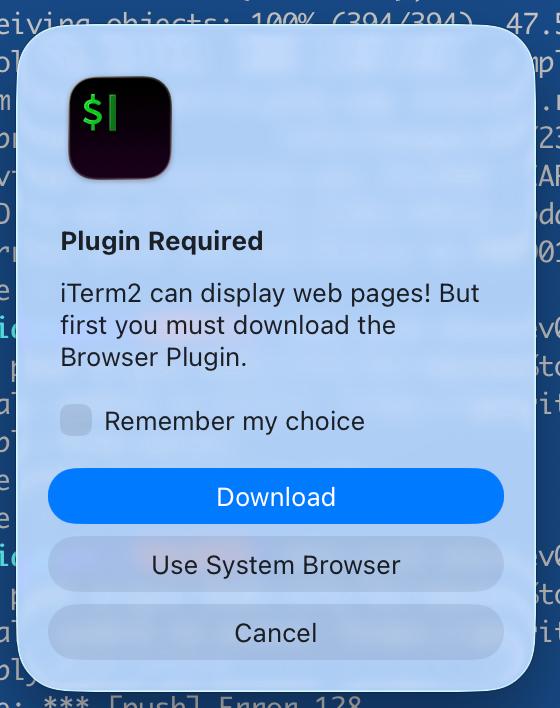
Искренне интересно: кто эти люди, которые открывают ссылки из терминала не в родном браузере, а в неком плагине? Представьте себе: у человека установлен Хром, возможно, Фаерфокс, системные браузеры: Edge или Сафари. И человек такой: нет, это не подойдет, открою-ка я ссылку в ПЛАГИНЕ. И кто-то сидел, писал этот плагин, настраивал интеграцию, добавлял модальное окошко, чтобы при первом клике по ссылке спросить: тебе родной браузер или плагин?
Апофеоз подобного дурдома поражает. Этот ваш браузер из плагина, где он хранит куки? Как долго? Что с защитой от трекинга и блокировкой рекламы? Как он настраивается? Очевидно же, что никак. Зачем писать барахло и засорять когда-то хорошую программу? Неужели все проблемы уже решили? Но самое главное — тезис из начала заметки: что было в голове у тех, кто написал этот плагин? А также у тех, кто добавил эту функциональность в релиз.
-
Статьи в Телеграме
Долгое время в Телеграме нельзя было постить текст с картинками. То есть было можно, но со скрипом. К обычному тексту нельзя добавить картинку, а если это сделать, то сообщение становится типом “медиа”, и его текстовая часть сильно меньше. Премиум закрывает этот недостаток, но появляется другая беда: текст выравнивается по ширине картинки. Если картинка маленькая, текст превращается в мышиный хвост.
В результате народ постил текст и картинки отдельно, чтобы не страдало ни то, ни другое. Но получается два сообщения, и если хочешь поделиться ими, приходится пересылать пару. Словом, бред.
Со временем Телеграм стал полноценной медиаплощадкой; есть даже проекты, у которых единственный канал – месаджер. При публикации картинок каждый извращался как умел: выносил их в галереи, объединял в коллажи и так далее.
И вот в Телеграм завезли полноценный визивиг-редактор. Это когда картинки и текст чередуются, и нет смысла делить публикацию на текстовый блок и медиа. Также сделали заголовки, списки и редактор таблиц – этакий Ворд.
Что ж, на словах все прекрасно, а вот на деле… ради интереса я сверстал небольшую статью: три абзаца, а между ними картинки. Сбросил в сохраненные сообщения и проверил на ноутбуке и телефоне. Оказалось, что шрифт статьи на один-два пункта меньше, чем обычный текст. Получается, тот, кто читает с ноута, будет напрягать глаза. Проверил настройки: шрифт выкручен на максимум, отдельной опции для статей нет.

Также в статьях нет отступа между параграфами, приходиться лепить переносы строк.
На телефоне оба шрифта – обычной публикации и статьи – одинаковы, и это хорошо. Но блок статьи срезан слева на один сантиметр. Почему? Зачем его срезать? Для чего пустота слева? Там ни одной кнопки, просто щель шириной в сантиметр, и через нее сквозит фон.
На обоих устройствах клиенты последних версий.
Надеюсь, что в будущем шрифты подтянут. Пока что я не готов оформлять текст с картинками в виде статей: щурить глаза ради чередования картинок – так себе удовольствие.
-
Таблицы в маркдауне
Уж если вы взялись набирать таблицы в маркдауне, то делайте не так:
| id | title | comment | |---|---|---| | 1 | some title one | a long comment one | | 1001 | some | small commant | | 5551312 | - | foo |а вот так:
| id | title | comment | |---------|----------------|--------------------| | 1 | some title one | a long comment one | | 1001 | some | small commant | | 5551312 | - | foo |Как я эту кашу буду читать на ревью?
В емаксе это делается ОДНОЙ клавишей — TAB. Для других редакторов есть плагины. Вы и так все сгенерили нейронкой, неужели нельзя хоть чуть-чуть причесать?
-
О присваивании (2)
Небольшая добавка к заметке про
x += 5.В жизни каждого программиста был момент, когда учитель информатики писал на доске:
x = x + 1,после чего смотрел на класс – поймут или нет? Класс, разумеется, не понимал и смотрел на учителя: что он несет? В школьной математике переменные неизменяемы: если взялся решать квадратное уравнение или систему уравнений, x не может по ходу дела переобуться во что-то другое. Да, можно подать на вход разные иксы и получить разные игреки. Но одно дело входные данные, а другое – их мутация в полете.
Учитель начинал рассказывать про коробочку, из которой достали сто рублей, прибавили рубль и положили обратно в коробочку. Что ж, какое-то объяснение это давало. Чувствуя наше сомнение, учитель откровенно продавливал свою аргументацию: если написать в Паскале
x := x + 1, то икс увеличится. Видите?Спорить с этим было нельзя, но ясности не добавляло. Класс принимал объяснение как данность, но знаете что? Где-то глубоко во мне сидела мысль, что учитель сам не понимает, как это работает. Да, он знает, какой получится результат, но не понимает истинных причин. Просто потому, что когда что-то знаешь, объяснение простое.
Если бы меня попросили объяснить, как работает
x = x + 5, я бы ответил так.В языках высокого уровня мы работаем с переменными:
x,yи так далее. Этот код становится машинными командами, а в них никаких переменных нет. Лучше всего это видно на примере ассемблера. В ассемблере нет переменных – только адреса. Для удобства некоторым адресам можно сопоставить метку – логическое имя. Меткой может быть что угодно: переменная, точка входа в процедуру, место, куда нужно совершить условный переход и так далее.Выше я написал “переменная”, но это не совсем верно: в ассемблере нет переменных. Мы резервируем память и одновременно добавляем к ней метку. Если метку убрать, программа скомпилируется и будет работать, просто мы не сможем сослаться на эту память – или сможем, но косвенно, отталкиваясь от других меток.
Таким образом, метка – это адрес, просто именованный. Метка представляет собой число, и к нему можно что-то прибавить, чтобы сместиться в памяти. Если же взять метку в квадратные скобки, получим значение по указанному адресу. В этом и состоит двойственная природа метки: это адрес (число), однако можно либо взять ее значение по адресу, либо поместить значение по этому адресу.
Если предположить, что в ассемблерном коде есть метки
a,bиc, то выражениеa = b + cвыглядит так (пишу по памяти):mov eax [b] ; поместить в eax ЗНАЧЕНИЕ b add eax [c] ; добавить к eax ЗНАЧЕНИЕ c move a eax ; поместить ПО АДРЕСУ a значение eaxВидим, что в случае с “переменными”
bиcмы использовали оператор[], чтобы получить значение. А когда мы “присваиваем” результат вa, квадратные скобки не требуются – метка используется как адрес.Вот почему выражение
a = b + cследует читать так: в адресaзаносится выражение, полученное как… Важно, что не “aстановится” чем-то, а именно “в адресa” заносится то-то и то-то. Большая разница.Язык Си предлагает указатели – читай, именованные адреса с той же семантикой. Мы вправе работать с ними как вздумается: использовать как числа для адресной арифметики или получать из них значения. Указатели – непростая тема, но по крайней мере здесь есть какой-то контроль. В выражении
x = x + 5этого контроля нет. Как я уже говорил, слева от присваивания стоит адрес, а если это что-то сложное вродеitems[get_index(foo)], оно вычисляется, чтобы получить этот адрес.Таким образом, переменная в Си — это тоже метка, и компилятор трактует ее по ситуации: иногда как значение, а иногда как адрес. Единственный язык, где адрес и значение не перемешиваются — это ассемблер. В нем
foo— это всегда адрес, а[foo]— значение по адресу.Как ни странно, присваивание неплохо ложится на объектную модель. Как мы выяснили, переменная – это пара адрес-значение. Ее операции: дай адрес, дай значение по адресу, помести значение по адресу. Можно представить переменную объектом с методами
getиset. В этом случае выражениеa = b + cмы бы записали так:a.set(b.get() + c.get())Или, если речь идет об
x = x + 1:x.set(x.get() + 1)Другое дело, что на тот момент, когда на доске впервые записано
x = x + 1, ученик еще не знает об объектах. Поэтому в ход идет коробочка, из которой достали сто рублей, добавили и положили обратно.Повторюсь: кому-то сказанное покажется банальным, но я считаю, о присваивании говорят мало – а тема очень интересная и сложная.
-
О присваивании (1)
Предположим, у нас следующий код:
x += 5Если спросить программиста, как он устроен, то скорее всего, ответ будет таким: это то же самое, что
x = x + 5Во-первых, это не верно, а во-вторых, такой ответ все равно ничего не объясняет.
Ошибка кроется в следующем. Если предположить, что
x += 5означаетx = x + 5, то из этого можно сделать вывод: любое выражение<whatever> += 5под капотом становится<whatever> = <whatever> + 5Представим теперь, что есть массив
m, и нужно увеличить его элемент на пять. Индекс этого элемента дает функцияfбез параметров. Таким образом, я запишу:m[f()] += 5Если следовать ошибочному предположению выше, это выражение становится таким:
m[f()] = m[f()] + 5Видим, что функция
f()вызывается дважды: сначала справа, чтобы посчитать значение, затем слева, чтобы присвоить его. Предположим теперь, функцияf()возвращает индекс случайно: в первый раз 2, а во второй — 7. Итоговое выражение станет таким:m[7] = m[2] + 5что совершенно неправильно. Так что тезис о том, что
x += 5равносильноx = x + 5— ошибочный.Если рассмотреть выражение
x = x + 5внимательней, станет ясно: у символаxв зависимости от положения слева или справа равенства разная семантика. Справа он используется для того, чтобы получить значение, а слева — адрес, по которому нужно его записать.В стандартах языков Си и Си++ для этого служат термины
lvalueиrvalue, что переводится как “лево-“ и “праводопустимые значения”. Так, на местеlvalue(слева от равенства) может быть любое выражение, от которого можно взять адрес. У правого выражения требования другие, и взятие адреса не требуется. Именно поэтому записьx = 5верная: отxможно взять адрес. По той же причине5 = xне пройдет компиляцию: от литерала 5 взять адрес нельзя.Даже если упростить выражение до предела и оставить
x = x, у обоих иксов будет разная семантика. Тот, что слева означает адрес, а справа — значение.Имея все это в виду, посмотрим, что происходит с выражением
m[f()] += 5. Его левая часть вычисляется, чтобы получить адрес, куда позже поместится результат. Если бы мы написали простоx += 5, то адрес x вычислять не надо — компилятор уже его знает. Однако дляm[f()]понадобится вычислитьf()и за счет адресной арифметики получить конечный адрес.Далее: значение из этого адреса помещается в отдельный регистр для вычислений, например
EAX. К этому регистру добавляется пятерка командойADD EAX 5(добавить что-то к ячейке памяти нельзя, только к регистру). После этого значение изEAXперемещается в тот адрес, что был вычислен в левом выражении. Функцияf(), таким образом, была вычислена один раз.Вывод таков, что даже если выражение записывается кратко, оно занимает несколько (порой много) машинных команд. Может, кому-то это очевидно, но не мешает лишний раз проговорить.
-
Глава 8. Функции на языке Python
Главы
- Введение в документы
- Базовые возможности JSON
- JSON в таблицах
- Индексирование JSON
- Ограничения в документах
- Язык путей JSONPath
- Отчеты, функции, расписание
- Функции на языке Python
- Версионирование и архивация документов
- Релевантный поиск
Содержание
- Главы
- Предварительные шаги
- Простые функции на Python
- Сторонние пакеты
- Работа с json(b). Трансформации
- Функции для работы с заявками
- Прочие сведения
Обсудим тему, которая, надеемся, разожжет в читателе интерес: как подключить к Postgres другие языки, например Python? Техника предлагает интересные возможности, особенно для работы с документами. Читатель узнает, как связать интерпретатор Python с базой данных и что можно сделать с его помощью. Считайте эту главу факультативом к предыдущей – дополнением, которое оказалось слишком длинным для параграфа и публикуется отдельно.
В прошлой главе мы познакомились с основами функций. В числе прочего мы упомянули, что функции можно писать на разных языках. По умолчанию это SQL, который не отличается от обычных запросов. Диалект plpgsql предлагает переменные, циклы, исключения и все то, что свойственно императивным языкам.
-
Пароли в Unix pass
Расскажу, как я храню пароли.
Когда-то давно я, как и все, пользовался 1Password. В те времена это была казуальная программка, легкая и незаменимая. Я купил ее долларов за 50, когда она была версии 4 или 5, и счастливо ей пользовался.
Как это часто бывает, программа прошла зенит своего удобства. Фирма, которая ей занималась, возомнила себя центром мира по безопасности. Штат раздули, программа все больше усложнялась, фирма вышла на корпоративный рынок… В какой-то момент 1Password развернул облачную инфраструктуру и ввел подписку. Вдобавок программу переписали на электрон и Node.js, так что еще одним процессом Хрома стало больше.
Я начал искать замену, нагуглил различные Bitwarden и аналоги. Программы хорошие, не спорю. Но вышло так, что мне, как Раскольникову, захотелось “страданье на душу принять”. Другими словами, я выбрал самый сложный способ хранить пароли – утилиту Unix pass. Вообще-то программа называется просто pass, но к ней добавляют Unix, чтобы было понятно – та самая.
Программа pass – это попытка передать философию ранней эпохи Unix. Pass написана даже не Си, а на шелле. Это скрипт на шесть экранов, который ничего не делает сам, а только командует следующими утилитами:
- gpg для (де)шифрования файлов;
- git для истории хранения и репликации;
- редактором для ввода данных;
- pinentry для безопасной передачи пароля от GPG-ключа.
Просто же, да?
Хранилище паролей выглядит как обычный гит-репозиторий с деревом папок и файлов. Никакой жесткой структуры, все определят пользователь. Единица хранения – файл. В файле может быть что угодно, однако со временем устоялись следующие соглашения:
- первая строка файла содержит пароль;
- другие строки хранят пары поле-значение в качестве метаданных.
Пример файла с паролем:
1dAfs@#sh_t335 email: ivan@grishaev.me username: igrishaev url: https://some.site/loginКоманда
pass path/to/fileдешифрует этот файл и выплюнет в консоль. Командаpath path/to/file -cпрочитает первую строку (пароль) и поместит в буфер обмена.Pass generateсоздает случайный пароль с разными параметрами (длина, алфавит),pass editоткрывает редактор, чтобы изменить существующий файл и так далее. Командаpass git ...совершает любое действие с репозиторием; чаще всего понадобитсяpushиpull. Коммиты на каждое действие программа создает сама.На маке вместо
pinentryпонадобитсяpinentry-mac– порт этой утилиты под яблочные устройства. Пропишите к ней путь в этом файлике:# ~/.gnupg/gpg-agent.conf pinentry-program /opt/homebrew/bin/pinentry-macЧтобы хранить все это добро, вам понадобится две пары ключей. Первая пара – публичный и закрытый ключи GPG. Вторая пара – SSH для репозитория. Дополнительно каждый приватный ключ должен быть зашифрован кодовым словом.
Все эти ключи следует распечатать на бумаге и хранить в разных местах: на работе, дома, у бабушки в деревне. Кодовые слова – в голове.
Поскольку unix pass – консольная утилита, для нее написана тьма графических оберток. Как и сам pass, они ужасны: поделки на C++, Tcl/Tk и прочее. В том числе есть плагины для Емакса и Вима. Попробовав пару оберток, я принял верное решение – предпочел консольную версию. Ее вполне достаточно.
Для Андроида написано несколько программ, для айфона – одна, которой я и пользуюсь. Обновляется она примерно раз в пять лет; топорная, местами странная, но работает. Первичная настройка тяжела: нужно перетащить GPG- и SSH-ключи на телефон, а они, как вы помните, занимают лист А4. В идеале вы копируете ключ на яблочном ноуте и телефон подхватывает буфер обмена — конечно, при соблюдении десятка условий.
Серьезный недостаток приложения в том, что оно не умеет решать конфликты Git. Если вы поправили файл одновременно на компе и телефоне, то при синхронизации программа скажет “конфликт”, и все – даже нет кнопки “принять своё” или “принять чужое”. Решается повторным скачиванием всего репозитория.
Вы, наверное, хотите знать, как я перенес пароли из 1Password в pass? В интернете полно Питон-скриптов, которые обходят экспорт 1Password и вставляют куда надо. Но сказано же: “страданье принять”. Я все сделал вручную. Примерно год я жил в режиме hit or miss: когда нужен был пароль, искал его в pass, а если не находил, переносил руками из 1Password. Со временем все нужное переехало в pass, а в старой системе остался хлам, который мне не нужен. У меня и сейчас установлен 1Password со старой базой, но я не открывал его уже много лет.
В этой статье я не буду описывать все детали установки. Предлагаю вам замечательный сайт-одностраничник, посвященный программе. Также есть достойная статья на Хабре “Знакомьтесь, pass”, где все подробно описано (но к некоторым вещам я пришел сам). Если у вас будут вопросы, задавайте: я отвечу и дополню заметку.
Writing on programming, education, books and negotiations.