-
Логи SQL
Расскажу один прием, полезный в разработке.
Если я работаю с PostgreSQL, то включаю логирование всех выражений. В Докере это делается передачей параметра
-Eкак в примере ниже:version: "3.6" services: postgres: image: postgres:14 command: -EС ним все запросы видны в терминале, где запущен Докер.
Если база работает нативно, в файлик
postgresql.confдобавляю выражение:log_statement = 'all'Оно там есть из коробки, но закомментировано. В отдельной вкладке вызываю вечный
tail:> tail -f '/path/to/postgresql.log'Далее я пишу код, гоняю тесты и посматриваю логи. Зачем? Потому что за много лет я выявил столько чуши, что просто не описать. Например:
-
запросы
WHERE ID INна тысячи айдишников; -
группировка по всем(!) полям таблицы:
GROUP BY id, name, email, etc...; -
молчаливый откат транзакции без выброса исключения. Запрос упал, но разработчик молча идет дальше;
-
изменения без транзакции там, где она должна быть;
-
мусорные запросы в
pg_catalogи другие служебные таблицы, потому что какие-то свойства не заданы в коде; -
чтение записей поштучно по ID в цикле (200, 500 шагов и больше);
-
просто всякие дикие конструкции.
Все это я собираю и открывают тикеты. Некоторые даже удается исправить.
Лог базы — своего рода осиное гнездо. Открой его — и почти наверняка уйдешь в ступор от того, какую дичь генерит ORM или “умная” библиотека. Или разработчик, вооруженный всем этим добром.
Так и живем.
-
-
Задачник по Паскалю
В сотый раз повторяется одно и то же. Человек учит язык — неважно Питон, Кложу, что угодно — и спрашивает: посоветуйте задачки. Ему кидают ссылки на Exercism, Project Euler и похожие сайты. Мой ответ не меняется годами: покупаешь задачник по Турбо-Паскалю за 300 рублей и решаешь на своей Кложе, Питоне или PHP. Или просто качаешь из интернета первый попавшийся.
Думаете, кто-то так делает? Конечно, нет. Мало того, поднимается драма: как так, у нас современные языки, а ты со своим Паскалем! Оставь дерьмо мамонта в покое.
Сколько себя помню, всегда поражала эта избирательность. Эти задачи буду решать, а эти не буду. Эти современные и хорошие, а эти старые. Иной раз мне доказывают, мол, концепции Паскаля плохо ложатся на Кложу, поэтому решать их неудобно.
Я аж представил себе. Начальство: Иван, вот тебе задача, надо сделать то и это. А я такой: ребята, она плохо ложится на концепцию языка, не буду делать. А они: конечно, дорогой, вот задача получше, а эту делать не будем. Исправим, чтобы ложилась.
Думаю, ясно, что решать надо все задачи. В том числе те, что в старых учебниках. А почему именно из учебников, тому следуют пункты.
-
Сразу много задач. Купив сборник, вы получите не две-три интересных задачки, а две-три сотни.
-
Если это толковый сборник, задачи в нем собраны по разделам: арифметика, циклы, массивы, связные списки, файлы, графика и так далее. В каждом разделе задачи идут по нарастанию сложности. Это позволит набить руку в той теме, где вы плаваете.
-
Поскольку задачи составлены для школьников и студентов, они перекликаются с учебной программой. Решая задачи, вы заодно ее подтяните.
Примеры задач, которые можно сделать на любом языке:
-
квадратное уравнение. По коэффициентам a, b, c найти корни или сообщить, что их нет.
-
игра “угадай число”. Компьютер загадывает число от 0 до 100, ваша задача — угадать его. На ваши попытки компьютер отвечает “нет, больше”, “нет, меньше” или “угадал”.
-
пересечение прямоугольников, точки и окружности по их координатам
-
задачи на массивы и связные списки, чтобы лучше понимать коллекции
-
графики, исследование функций.
-
запись данных о сотруднике в файл и их чтение.
Что из этого плохо ложится на современный язык? Может, за “не хочу” стоит “не могу” или “лень вспоминать”?
Какой смысл открывать условный Exercism, регистрироваться, подтверждать почту, отписываться от рассылки? Чтобы что? Я уже накидал задач на неделю, сиди решай. В учебнике их на год. Что ты хочешь найти? Чего не хватает?
Наконец, еще один пункт в пользу сборника задач — это работа с книгой. Не знаю как это работает, но бумажная книга эффективней, чем тупление в монитор. Для меня это совершенно очевидно. Скорей всего, включается другой отдел мозга, но объяснение не так важно.
Изучать язык тяжело. Красивые сайты пытаются это скрыть или развлечь пользователя, потому что их цель — донаты и показ рекламы. У задачника этой цели нет. Это более хардкорный вариант, но тем он и лучше.
-
-
Звонки в мессаджерах
Совет — чтобы не бесить людей, звоните на обычный мобильный. Не в Телеграм, не в Ватсап и не Вайбер. Мало что раздражает так сильно, как звонки в какой-то программе.
Только что звонил родственник в Телеграме. Это просто п..здец, простите. У меня три устройства: телефон, ноут, комп. Все три одновременно завыли, на каждом распахнулось окно. Ощущение, что воздушная тревога. Через две секунды вызов на телефоне пропал, но продолжился на ноуте. Что происходит?
То же самое с Ватсапом. Сидишь, быдлокодишь под музыку, весь в себе. Внезапно подскакиваешь от звонка и окна на весь экран. Просто издевательство.
Даже если не обращать на это внимание, есть важный момент. У звонков в Телеграме и иже с ним ужасное качество. Звук пропадает, сыпется, словом — гораздо хуже мобильной связи.
Причина в том, как устроены звонки в приложениях. Каждое из них звонит на местный номер. Там сервер, который заворачивает звук в трафик и шлет куда-то далеко. Оттуда он направляется в страну получателя, и ему звонят с местного номера. Получается звонок с местного на местный с целой пропастью посередине. Даже если собеседники в одном здании, маршрут выходит изрядный.
Конечно, при звонке из России в условную Турцию вариантов не остается — не платить же опсосу по 70 рублей за минуту. Здесь Телеграм и Ватсап выручают. Но удивляют нищеброды-соседи или знакомые из твоего города, которые упорно звонят из приложения. Зачем? Чтобы сэкономить пять минут? Они везде идут пакетами, что там экономить? Хуже пенсионеров, честное слово.
Раздражает еще то, что на Айфоне последние номера хранятся с учетом приложения. Например, когда мне звонят с Ватсапа, я сбрасываю и перезваниваю с мобильного. Но если нажать на последний вызов, выскочит проклятый Ватсап. Приходится заходить в контакт и жать на тот же номер с мобильным типом.
Раз и навсегда: для связи внутри страны — только мобильная связь. Мессенджеры — если вы в разных странах или важна приватность, причем по обоюдному согласию. В остальном звонить из приложения — днище и зашквар. Объясните, пожалуйста, тем, кто этого не понимает.
PS: в Телеграме можно запретить входящие звонки всем или с учетом контактов. В других программах, кажется, это невозможно.
-
PG: Postgres-related libraries for Clojure
The PG project holds a set of packages related to PostgreSQL. This is a breakdown of my unsuccessful attempt to write a PostgreSQL client in pure Clojure (stored in the
_directory). Although I didn’t achieve the goal, some parts of the code are now shipped as separated packages and might be useful for someone.At the moment, the most interesting modules are
pg-copyandpg-copy-jdbcthatCOPYthe data using the binary Postgres format which is faster than CSV.Table of Contents
-
Свое
Иногда в фирме пишут велосипеды даже с учетом того, что есть открытые библиотеки. Раньше я по-разному к этому относился, а теперь пришел к компромиссу.
С одной стороны, кустарные поделки напрягают меня как разработчика. Устраиваясь в фирму, меньше всего хочется встретить свою ORM, свой роутинг или шаблонную систему. Обычно это глючный код, написанный по принципу “потому что можем”. Хочется работать с популярными библиотеками, у которых документация, сообщество, канал в Слаке.
С другой стороны, свои решения продвигают фирму на рынке и в сообществе. Это привлекает разработчиков, служит рекламой, упрощает найм. В вакансиях можно указать, что задание должно быть сделано именно на этих библиотеках, потому что на них построены решения фирмы.
Правда, чтобы это работало, фирма должна как можно раньше выкладывать свои решения в open source. Это то же самое, что с ребенком: если вечно держать его взаперти, будет вред. Библиотека должна быть на Гитхабе, должно быть сообщество, словом — фирма должна как можно сильнее пиарить свой код, чтобы считаться центром идей в своей области. И программисты будут в нее стремиться.
Удивляет порой, что у фирмы есть неплохие решения, но они киснут в приватных репозиториях — без документации, без развития. Что бы не выложить их в паблик? Я вообще не припомню кода, который нельзя было бы опубликовать именно по причине кражи бизнеса. За любым кодом стоит понимание его командой и видение будущего. Скачав исходники Яндекса вы не сделаете новый Яндекс. Единственное опасение — это ошибки и низкий уровень кода, за который стыдно. Именно это и лечит open source: его код сразу готов к жизненным трудностям.
Бесит, когда делаешь тестовое задание на популярных библиотеках, а в команде говорят: забудь, чему тебя учили, у нас своя атмосфера. Ребят: свою атмосферу нужно проталкивать вовне! Задавать стандарты, вовлекать людей, а не держать в тайне от мира. Вы что-то скрываете, а скрывать нечего.
-
Уровень
Пока мир сходит с ума по искусственному интеллекту, всплакну о низком уровне разработчиков. Подкатило, нужно выплеснуть.
Ситуация: разработчик пишет функцию
get-by-id, чтобы достать сущность из базы. Не моргнув глазом, он передает ее вmapна пять тысяч элементов. Это, на минутку, один запрос, а запросов может десятки в секунду. Подобные вещи приходится ловить в code review и объяснять, что один запрос лучше, чем пять тысяч.Идет 2023 год, а программисты пишут SQL конкатенацией строк. В порядке вещей код на два экрана с
format,strиjoin, который ни понять, ни отладить. Полученный запрос уходит в базу, и дай бог, чтобы оно работало. Если передать nil или пустой список, получим битый SQL, потому что автор этого не предусмотрел. И конечно, инъекции во все поля.Почему-то программисты не могут записать и получить данные из базы. Им нужна ORM, и чтобы она сразу мапилась на REST. Получается километр глючного кода без документации и поддержки. Автор ORM отлынивает от задач под видом ее доработки. Часть команды уходит в партизаны: работают с базой через SELECT и UPDATE в обход ORM. Так спокойней, главное чтобы автор ORM не зашел в пулл-реквест.
Разработчики игнорируют линтеры. Проект уже не раз сменил команду, люди пишут в разных редакторах, и ни у кого он толком не настроен. Кривые отступы, экраны закомментированного кода, неиспользуемые импорты и переменные. Это в порядке вещей.
Программисты не доводят дело до конца, хотя в бóльшей степени это упрек руководству. Например, у кого-то задача, чтобы была документация Swagger. Человек пишет генератор json-файла, покрывает тестами, все готово. Осталось захостить, чтобы документацию увидели клиенты. Но прилетает горящая задача или девопс-инженер уходит в отпуск. В итоге документация есть, но ее никто не видит. Задача не достигнута, время потрачено зря, но это никого не смущает. Недостигнутые цели я вижу постоянно.
Сюда же относятся висящие пул-реквесты. Открываешь борду и видишь у кого пять, а у кого семь пул-реквестов. Зачем программист писал код, если его не принимают? Если бы он смотрел Ютуб, эффект был бы тот же. Почти во всех системах можно задать auto-expire, не говоря уж о ботах, которых полно.
Беда с локальным окружением. Программисту лень потратить день на
docker-compose.yaml, чтобы сервисы работали локально. Приходится объяснять, что локальный ресурс лучше стейджинга где-то в Амазоне.Иной программист генерит айдишники для базы вручную. Берет рандом от 0 до 9999 и густо перчит номером треда, числом миллисекунд и фазой Луны. И это работает в проде.
Программисты любят кокетничать, что уперлись в базу: терабайты данных, не вывозит нагрузку, все дела. При этом в базу уходят кривейшие запросы, а сама она превратилась в свалку, потому что там хранят кэш, логи S3 и черт знает что.
У программистов туго с отладкой. Под отладкой я имею в виду остановку кода на середине, чтобы выяснить локальные переменные. Это могут единицы. Остальные либо ставят принты и мотают экраны логов, либо вообще сдаются. Иные заявляют, что в божественной Кложе отладчик не нужен. Это вообще за гранью.
И наконец, главное: карго-культ. Так писали до нас, так пишем и мы. Кривой нейминг? Дурацкая организация кода? Ничего, консистенси важнее. И хотя прошлый разраб видел Кложу второй раз в жизни, все следуют его бредовым начинаниям.
Все это я видел даже когда писал на Дельфи и 1С до прихода в промышленную разработку. Меняются лица, а косяки остаются с нами. Конечно, я их тоже совершал, но будучи записанными, они переживаются легче.
Все, отпустило, работаем дальше.
-
Помощь Chat GPT
Сегодня я столкнулся с “помощью” Chat GPT, а точнее — его необдуманным применением.
Я немного занимаюсь Латехом, и когда верстал книгу, решал массу технических вопросов. Что-то вышло изящно, а что-то нет: работает, но коробит душу. Хочу закрыть эти недостатки в будущем.
Добрые люди подсказали группу в Телеграме, где тусят любители Латеха. Зашел туда и задал наболевший вопрос про жирный шрифт в minted. Через какое-то время один пользователь (судя по био, женщина), скинула ответ с примером на Латехе. Я горячо поблагодарил и побежал пробовать.
Запускаю — ошибка, что нет такого-то свойства. Ладно, думаю, устарели пакеты. Обновил все под чистую. Запускаю — то же самое. Что же это за свойство? Полез в документацию пакета, а там его вообще нет. Пакет ничего не знает об этом свойстве.
Посмотрел на ответ свежим взглядом и понял — это Chat GPT (вчера вечером мозги были уже не те). Во-первых, в нем повествовательный стиль: “обратите внимание”, “вы можете” и так далее. От первого лица в Телеграме так не пишут. Во-вторых, в копипасте я нашел артефакты, свойственные интерфейсу Chat GPT. В частности, название языка перед участком кода (python, latex). Их всегда забывают вычистить при копировании ответа целиком.
Что тут можно сказать? История не нова. Помните сервисы вопросов и ответов на Яндексе и Мейл.ру? Раньше домохозяйки копировали с Википедии. Теперь то же самое, только научились пользоваться Chat GPT. Понимаю, почему на StackOverflow запретили им пользоваться — можно засрать сервис нерабочим кодом без какой-либо ответственности.
Лишний раз убеждаюсь в том, о чем писал недавно. Chat GPT — это никакой не интеллект. Это языковая модель, которая производит текст, максимально близкий к вопросу. Ей неважно, работает код или нет, у нее другие метрики. А мне, наоборот, важно. Мне платят за код, который не только выглядит хорошо, но и работает хорошо. Единственный способ проверить код — запустить его и предъявить результат работы. Этого Chat GPT не может, и поэтому мне с ним не по пути.
-
Выпадашки
Бич современного интерфейса — это выпадающие элементы, которые я называю “выпадашками”. Часто упоминаю их, когда пишу об интерфейсе, и вот пора сделать отдельный пост.
Я не люблю выпадашки по одной причине: почти всегда в интерфейсе хватает места, чтобы уместить скрытые элементы. Непонятно почему дизайнер прячет их от меня, оставляя три точки или гамбургер. Приходится кликать, чтобы узнать, что под ними.
Типичный пример — форма комментариев на Хабре. Действие “Ответить” выражено текстом, к этому вопросов нет. Затем идет иконка закладки. Далее выпадашка, под которой ссылка, редактирование и жалоба. Зачем было их прятать? Места хватит и для иконок, и для текстовых ссылок.
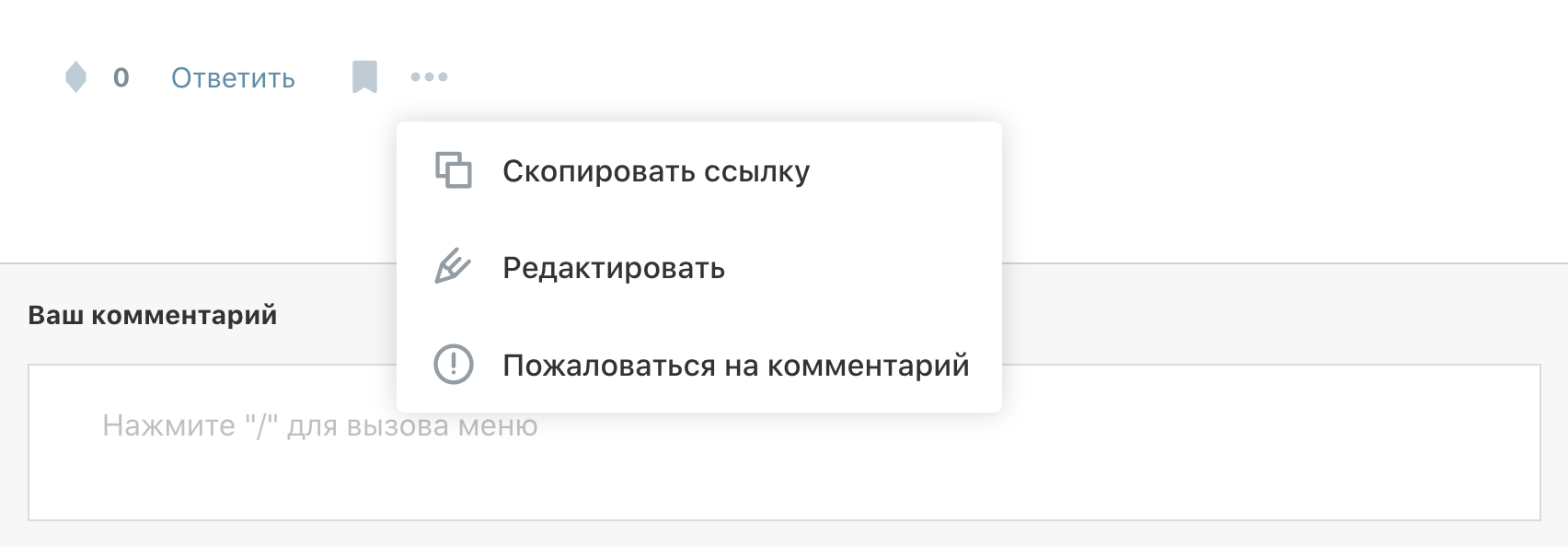
Пользуясь случаем, замечу, что у выпадашки адская разреженность. Ее можно было сжать в два раза без какого-либо ущерба.
Другой пример — форма закладок на том же Хабре. Закладки бывают двух типов: статьи и комментарии. Почему переключалка сделана в виде выпадашки? Что мешало расположить элементы по горизонтали: Статьи / Комментарии?
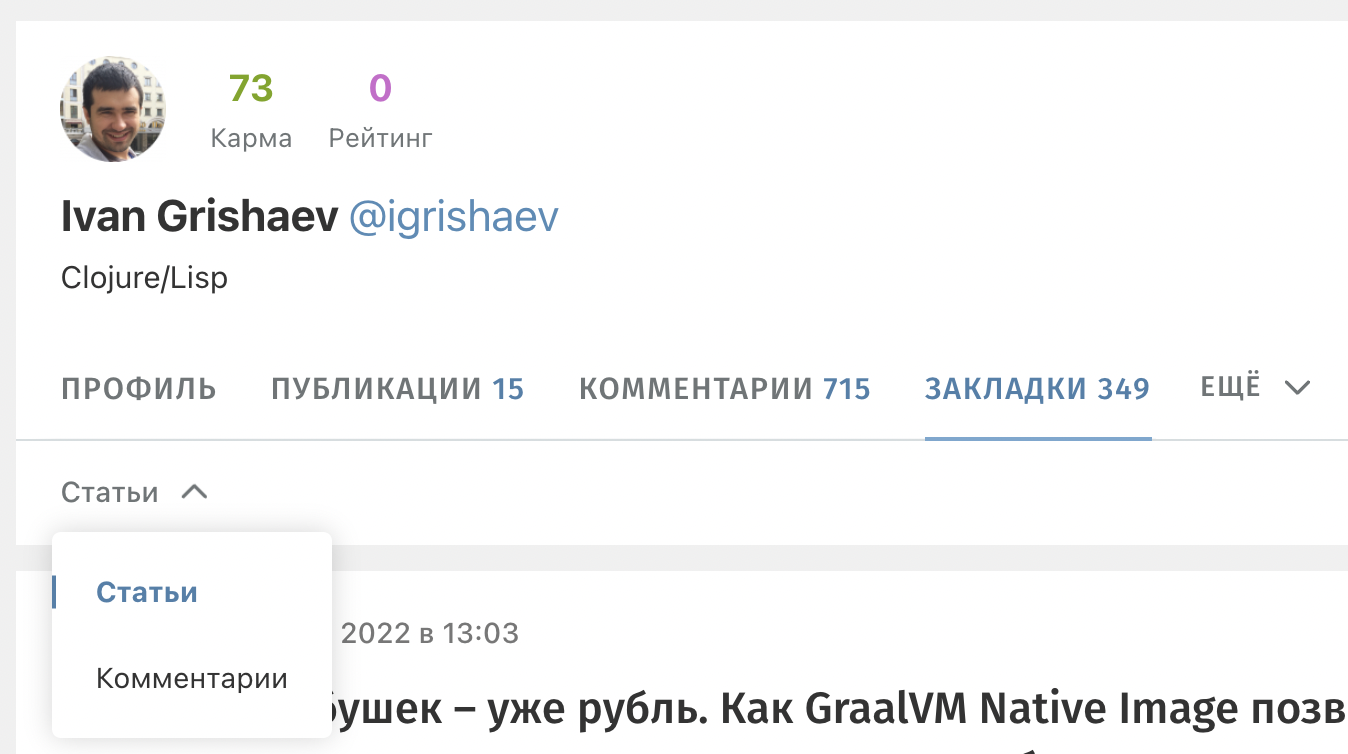
Выпадашки пришли к нам с мобильных устройств. Там мало места, поэтому приходится что-то прятать. Но почему пользователь десктопа должен страдать? Кому-то лень добавить проверку на разрешение или прописать стиль. В итоге на мониторе места столько, что влезет несколько страниц книги, но кнопки спрятаны под выпадашку.
Впрочем, и на Айпаде я видал интерфейсы, когда на весь экран пустота и в правом верхнем углу жалкое многоточие.
Из недавнего: в англоязычной Википедии обновился интерфейс. Конечно, самое нужное убрали под выпадашку. Если раньше на язык достаточно было кликнуть, то теперь он заботливо спрятан в выпадающее меню.
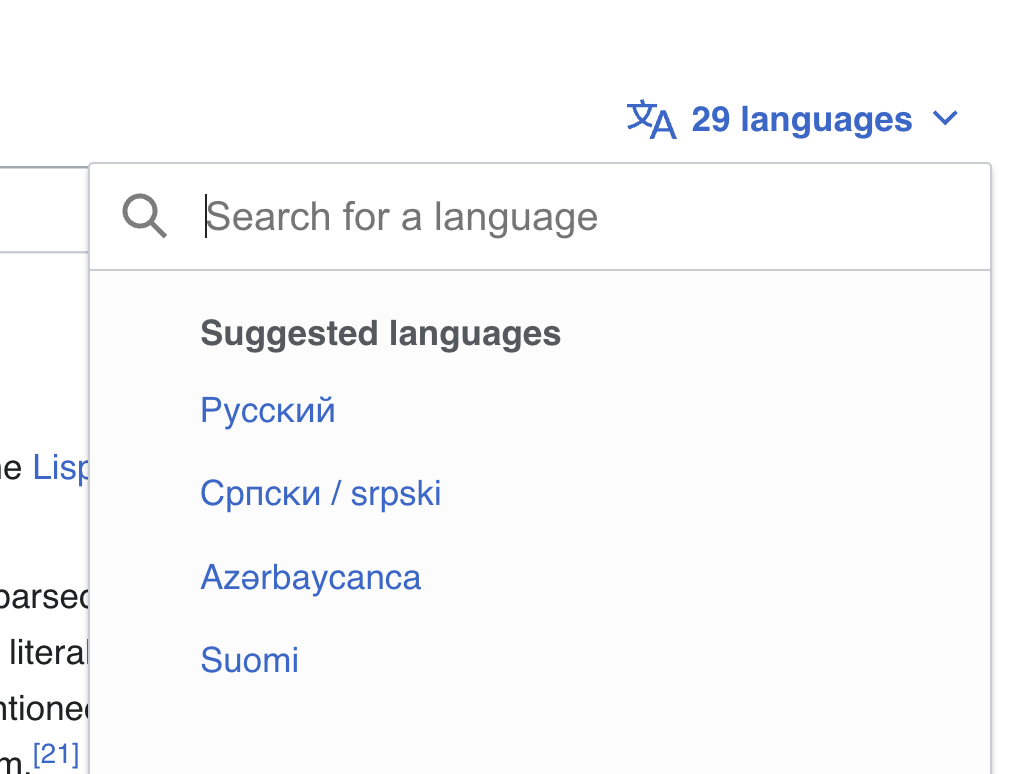
Выпадашки ради выпадашек. У меня есть инструмент — значит, воспользуюсь, неважно нужен он или нет. К сожалению, сегодня для выпадашки даже не нужен Джаваскрипт, хватает обычного CSS, и это только усугубляет положение.
С ростом экрана дизайнер не знает, как им воспользоваться. Поэтому искусственно раздувает интерфейс: больше отступы, крупнее иконки, половину кнопок под выпадашку. Скрытая профессиональная импотенция.
Обычно желаешь таким дизайнерам всяческих наказаний, но сейчас у меня хорошее настроение, и хотелось бы закончить на позитивной ноте. Если вы дизайнер интерфейсов и часто пользуетесь выпадашкой — займитесь физическим и печатным дизайном. У предметов и бумаги почти не бывает выпадающих элементов, а если они и есть, то их тяжело и дорого делать: во-первых, дольше процесс, а во-вторых, оторвутся на раз-два.
Со временем придет ясность, что все элементы можно расположить, не пряча один под другой. Но это требует усилий над собой.
-
Clojure + GraalVM framework for AWS Lambda
Lambda is a small framework to run AWS Lambdas compiled with Native Image.
Motivation & Benefits
There are a lot of Lambda Clojure libraries so far: a quick search on Clojars gives several screens of them. What is the point of making a new one? Well, because none of the existing libraries covers my requirements, namely:
- I want a framework free from any Java SDK, but pure Clojure only.
- I want it to compile into a single binary file so no environment is needed.
- The deployment process must be extremely simple.
As the result, this framework:
- Depends only on Http Kit and Cheshire to interact with AWS;
- Provides an endless loop that consumes events from AWS and handles them. You only submit a function that processes an event.
- Provides a Ring middleware that turns HTTP events into a Ring handler. Thus, you can easily serve HTTP requests with Ring stack.
- Has a built-in logging facility.
- Provides a bunch of Make commands to build a zipped bootstrap file.
Installation
Leiningen/Boot:
[com.github.igrishaev/lambda "0.1.1"]Clojure CLI/deps.edn:
com.github.igrishaev/lambda {:mvn/version "0.1.1"} -
Заменят ли ИИ разработчиков и почему? Если да, то на каких задачах?
Меня попросили ответить на вопросы из заголовка. Думал, будет абзац, но как обычно вышла простыня. Впрочем, мысли об ИИ были уже давно, и это отличный повод собрать их в статью.
Что ж, если коротко, то нет: ИИ, который у нас сегодня, не заменит программистов. Волноваться незачем, продолжайте работу. Если вы учитесь на программиста и испытываете тревогу, успокойтесь и продолжайте. Никакие чаты и боты программистам не угрожают. А также журналистам, учителям и вообще — любым профессионалам своего дела.
Да, про ИИ говорят и пишут из каждого утюга. Но важно знать, что информационная волна всегда сильнее повода, который ее вызвал. Изданиям нужен трафик, а люди склонны экстраполировать: если сегодня бот написал Тетрис, то через год он сделает Киберпанк. Увы, это не так.
Причина моего скепсиса в том, что все помощники и боты слабы в деталях. У меня есть колонка Яндекса, она прекрасно играет музыку и говорит погоду. Но ее крайне легко ввести в ступор. Например, играет песня, и я хочу послушать альбом, которому она принадлежит (пусть даже первый, если их несколько). Однако этой функции не предусмотрено: какую бы фразу я ни высказал — перейди к альбому, включи альбом, из какого это альбома, — Алиса не понимает. Хотя в мобильном приложении это одна кнопка “show album”.
Writing on programming, education, books and negotiations.