-
Граждане выгорающие
Скажите, куда делись все эти выгорающие? У которых все плохо, токсичные коллеги и прочее. Помню, год назад открываешь Хабр, и там каждую неделю очередной выгоревший. С обсуждением на десять экранов.
Как я выгорел и пережил это. Как я выгорел и пошел в автослесари. Как не выгореть тимлиду. Курсы для выгоревших. Исповедь выгоревшего менеджера.
Сколько вас, нечисти, развелось.
Так вот — повестка ушла, выгорание больше не модно. Сейчас что ни день, то новые потрясения, и очередного выгоревшего не поймут. Люди умирают, переезжают, теряют работу, а ты выгораешь. Серьезно?
Стоит миру перевернуться, как уходит всякое выгорание. Из чего следует печальный факт. Массовое выгорание прошлых лет — пошлое ковыряние в себе на фоне скуки. Подобно организму, который в стерильных условиях борется с собой, человек в комфортных условиях ищет страдания.
Все это было фарсом, позерством, пафосом.
Повестка ушла, а задача ничуть не изменилась: все так же профессионально делать свое дело.
За работу.
-
Возня с файлами
В одной из прошлых заметок я рассказал, как настроить cron с отправкой почты на свой ящик. В завершении обещал уточнить, для каких конкретно целей я использую крон, но не сделал этого. Исправляюсь.
Если коротко, с помощью крона я бекаплю файловый архив. До недавнего времени пользовался S3, но из-за последних событий вынужден переезжать. Ниже — мои изыскания на тему хранения файлов.
Полагаю, у каждого из нас есть архив личных файлов. Как правило, это фотографии с первой мыльницы, код с прошлых проектов или просто файлы, которые приятно иной раз посмотреть. Например, сделанный своими руками ролик про университет, первые работы в рекламе или в типографии.
Кроме фоток, крайне важны сканы документов. Паспорт, загран, снилс, ИНН и так далее. Все то же самое для жены и троих детей, плюс свидетельства о рождении. Полноценный скан документа (именно скан, а не фотка) неистово полезен. Распечатать его на принтере занимает минуту, а поход в ближайший копицентр — двадцать минут. Когда после рождения третьей дочки бегал по инстанциям, идею со сканами я просто боготворил: в каждую дверь нужно сдать пачку копий, а таких дверей десятки.
Из-за уникальности файлов возникает вопрос, где их хранить. Техника недолговечна: нельзя доверять даже жестким дискам, не то что флешкам. Если архив лежит в нескольких местах, должна быть синхронизация, иначе убьешся синхронизировать вручную.
До недавнего времени вопрос не стоял остро: бери любое облачное хранилище и вперед: дропбокс, яндекс-драйв, гугло-драйв, айклауд. Но даже до “спецоперации” и отвала русских пользователей ни один из этих сервисов мне не подошел. Все они намертво завязаны на конкретный бренд и любят выкручивать мозг. О деградации того же дропбокса я писал неоднократно (раз, два), и аналоги ничуть не лучше.
Основная претензия с синхронизаторам файлов — интерфейс, точнее желание его не видеть. Хочется, чтобы ни при каких условиях не вылазил попап или окошко на электроне. Чтобы в углу не маячили уведомления, которые забыл выключить. Чтобы не оценивать сервис по десятибалльной шкале. Словом — настроил и забыл.
Я попробовал AWS S3, и неожиданно понравилось: все происходит молча, разве что в раз в месяц получаю счет. Настроить просто: ставим питонячий AWS CLI. Далее прописываем креды и настройки в файлах:
# ~/.aws/config [default] region = us-east-1 output = json # ~/.aws/credentials [default] aws_access_key_id = ... aws_secret_access_key = ...Если теперь выполнить команду
s3 sync:aws s3 sync my-bucket s3://my-bucket --delete, то произойдет синхронизация файлов из первого источника (папки) во второй (бакет). Флаг
--deleteозначает, что файлы, которых нет в источнике, будут удалены в удаленном хранилище. Другими словами, если удалили локальный файл, то при синхронизации он будет удален и в S3. Без флага происходит простое слияние файлов.Вот как оформить все это дело в кронтаб:
BUCKET=my-bucket 0 */3 * * * cd /Users/ivan/s3 && aws s3 sync ${BUCKET} s3://${BUCKET} --exclude '*.DS_Store' --delete && echo OKДля удобства я назвал локальную папку так же, что и бакет, чтобы ссылаться на переменную.
Вопрос в том, насколько часто запускать синхронизацию. Раньше я делал это каждые три часа (
0 */3 ...), но со временем понял, что это слишком часто. На практике хватает двух раз в день: в обед и вечером (0 12,22 ...).О результатах синхронизации я узнаю по письму следующего содержания:
Subject: Cron <ivan@ivan> cd /Users/ivan/s3 && aws s3 sync ... Completed 60.5 KiB/~60.5 KiB (34.3 KiB/s) with ~1 file(s) remaining (calculating...) upload: my-bucket/docs/text/links.md to s3://my-bucket/docs/text/links.md Completed 60.5 KiB/~60.5 KiB (34.3 KiB/s) with ~0 file(s) remaining (calculating...) OKПро деньги: хранение 130 гигабайт с синхронизацией каждые 3 часа стоит 4.6 доллара в месяц. Это дешевле дропбокса и и аналогов с интерфейсом. Важное преимущество в том, что платишь в точности за те ресурсы, что потребляешь. Никаких обрыдлых подписок.
С началом “не-войны” Амазон начал вести себя странно. Файлы по-прежнему доступны, но теперь я не могу войти в консоль управления. Амазон требует ввести код, отправленный на телефон, но сообщения не приходят. Не работают и другие способы его получить, например голосовым звонком робота. Запросил восстановление двухфакторной авторизации, но что-то Амазон не спешит.
Написали бы прямо: не работаем с проклятыми фашистами и агрессорами, и я бы все понял. Не дожидаясь отвала файлов, решил мигрировать, тем более что все равно нельзя оплатить российской картой.
Приятная вещь: S3 уже давно не монополист в области хранения файлов, и многие фирмы выкатили свои решения. Которые, кстати, работают по протоколу S3. Файловые хранилища предлагают DigitalOcean, Exoscale, Яндекс.Облако. Будучи в Exoscale, я, хоть и немного, но работал над хранилищем.
Миграция сводится к тому, чтобы перенацелить клиент AWS на другой сервис. По понятным причинам выбрал Яндекс — западные партнеры сейчас не подходят. Регистрируемся на
cloud.yandex.ru, переходим в Object Storage. Создаем бакет. Советую холодный тип хранения, потому что читать файлы вы будете редко, а синхронизация работает по методу HEAD — через метаданные.Когда бакет создан, понадобится пара открытый-закрытый ключ. Как слепой щенок, долго я мыкался по интерфейсу, пока не нашел “сервисные аккаунты”. Создайте новую пару и сохраните ключи. Добавьте в настройки клиента AWS секции:
# ~/.aws/config [ya] region = ru-central1 output = json # ~/.aws/credentials [ya] aws_access_key_id = ... aws_secret_access_key = ...Теперь выполните:
aws --profile ya --endpoint-url=https://storage.yandexcloud.net s3 sync ..., и файлы польются в Яндекс. К сожалению, в настройких нельзя задать свой
endpoint-url, поэтому приходится таскать его за собой в командной строке. Народные умельцы сделали плагин, который это фиксит, но я не проверял.Как закончится синхронизация, удалите старые файлы из Амазона:
aws s3 rm s3://my-bucket --recursiveПоздравляю, вы переехали. Осталось только исправить
crontab, чтобы синхронизация стала регулярной.У питонячьего AWS-клиента есть недочет: при синхронизации он оставляет на сервере пустые папки. Предположим, вы удалили папку “photos”, и AWS CLI честно выполнит DELETE для каждого файла:
DELETE photos/IMG_001.jpeg DELETE photos/IMG_002.jpeg DELETE photos/IMG_003.jpeg ...Что касается пути “photos/”, то он благополучно останется на сервере. Ясное дело, что со временем накопится масса таких пустышек, и скачав файлы с S3, вы обнаружите папки, удаленные давным давно. На эту тему пять лет назад создан issue, в котором отметился и ваш покорный слуга. Каждый месяц я получаю письма с комментариями +1 и пальчиком кверху, но исправлять его никто не спешит.
Впрочем, удалить пустые папки можно командой
find . -type d -empty -delete, что не такая уж и проблема.
Согласно калькулятору Яндекса, хранение 150 гигов обойдется в 215 рублей в месяц, что, прямо скажем, по-божески. По текущему курсу это два доллара, дешевле даже представить нельзя.
Во время изысканий я в том числе пробовал программу SyncThing. Кто не знает, это программа для анонимной синхронизации файлов. Никаких регистраций: поставил у себя и на удаленной машине, обменялся QR-кодами, и процесс пошел. Работает как часы. Висит в трее, настройки через браузер на локальном хосте.
На мой взгляд, SyncThing подходит в тех случаях, когда файлы постоянно меняются, и изменений ждут на обоих концах. Например, обмен документами между группой лиц или торрент-трекер, ожидающий файлы в нужной папке. Перекинуть файл с макбука на игровой комп — тот еще челендж, если настраивать сеть по правилам. А со SyncThing работает прекрасно. Словом, замена старому доброму Дропбоксу.
А вот делать бекапы через SyncThing как-то не зашло. Для этого нужно поднимать VPS и ставить там SyncThing. Виртуалки с большим диском нынче от 700 рублей в месяц. Не катастрофа, но выбор между 200 и 700 рублями в месяц очевиден. Да и заморачиваться не охота.
В общем, вот как я синхронизирую файлы. Слово читателям: расскажите, как делаете это вы.
UPD: продолжение.
-
Bogus: a simple GUI debugger for Clojure
(This is a copy of the readme file from the repository.)
Bogus is a small, GUI-powered, NIH-reasoned debugger for Clojure.
Installation
Lein:
[com.github.igrishaev/bogus "0.1.0"]Deps.edn
{com.github.igrishaev/bogus {:mvn/version "0.1.0"}}The best way to use Bogus is to setup it locally in your
profiles.cljfile:;; ~/.lein/profiles.clj {:user {:dependencies [[com.github.igrishaev/bogus "0.1.0"]] :injections [(require 'bogus.core)]}}Usage
Once you have the dependency added and the
bogus.corenamespace imported, place one of these two forms into your code:(bogus.core/debug) ;; or #bg/debugFor example:
(defn do-some-action [] (let [a 1 b 2 c (+ a b)] #bg/debug ;; or (bogus.core/debug) (+ a b c)))Now run the function, and you’ll see the UI:
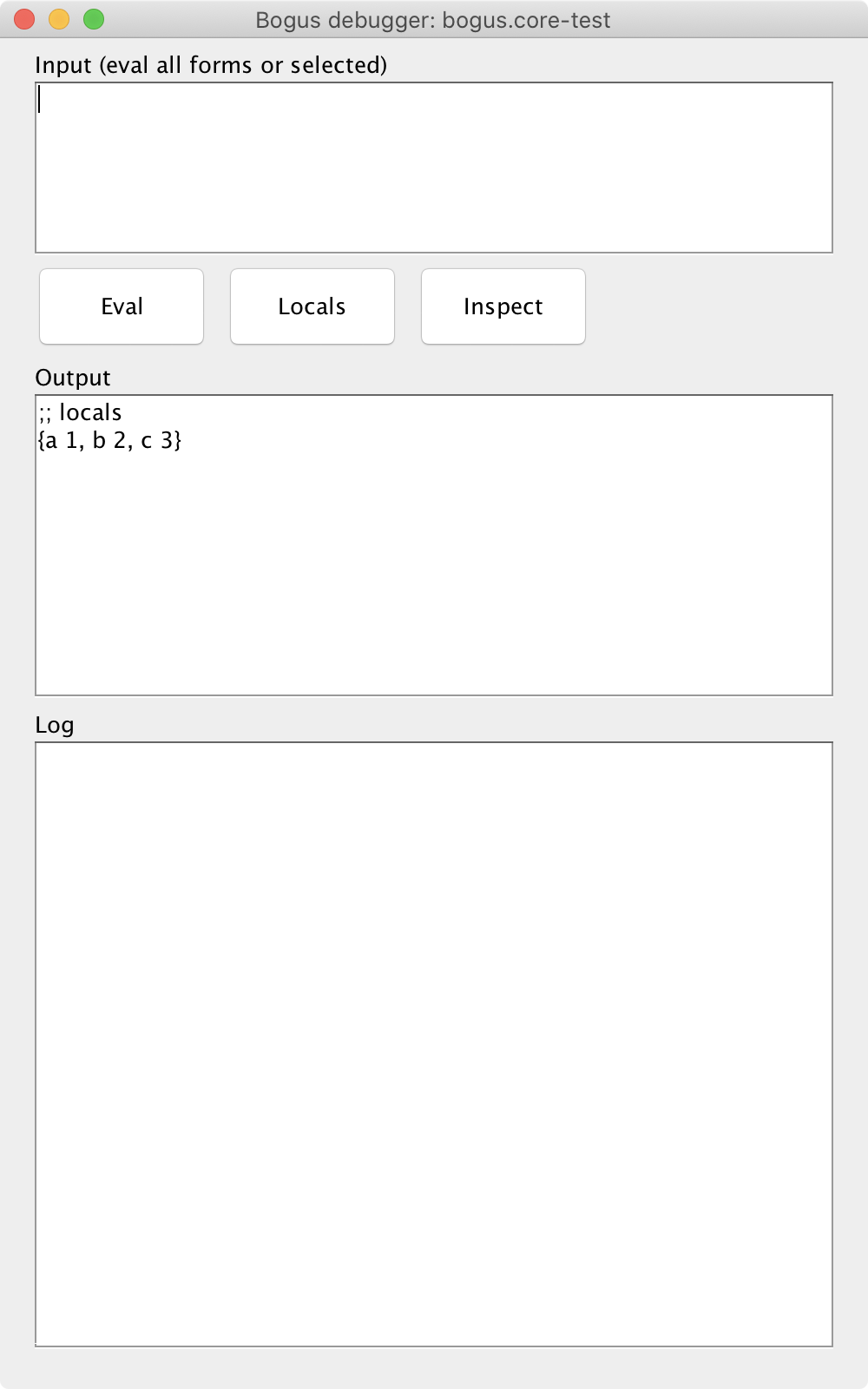
The UI window blocks execution of the code. In the example above, you’ll hang right before executing the next
(+ a b c)form. Close the window to continue execution of the code.The UI consists from three parts: the input area, the output, and the log. Type any Clojure-friendly form in the input textarea and press “Eval”. The result will take place in the output textarea. You can copy it from there to your editor.
The input can take many Clojure forms at once. They are executed as follows:
(eval '(do (form1) (form2) ...))so you’ll get the result of the last one.
If you mark some text in the input with selection, only this fragment of code will be executed.
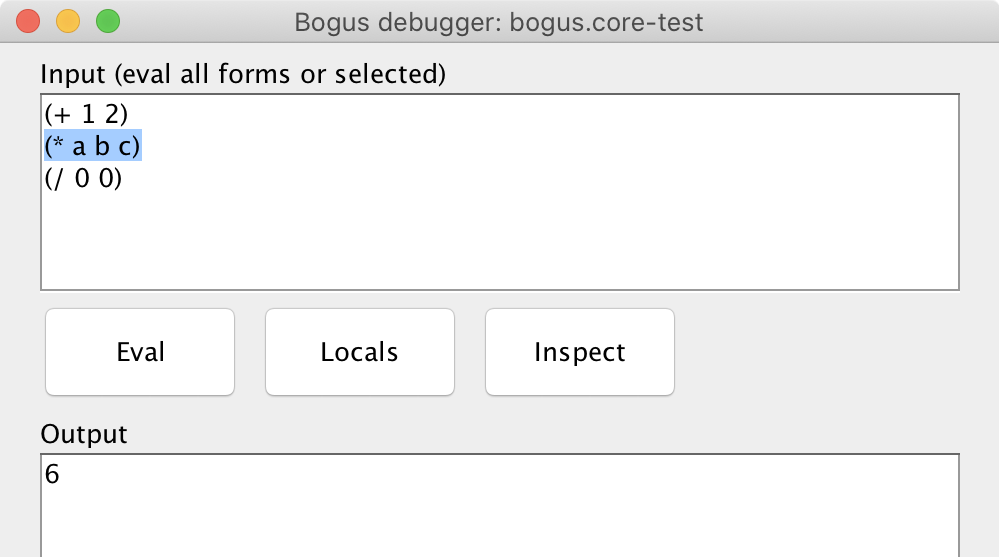
In the input code, you can use any local variables as they’re global ones. In the example above we’ve executed the
(+ a b c)form referencing locala,b, andcfrom theletclause.The “Locals” button pretty-prints the local variables. Bogus does it in advance when the window opens the first time. The “Inspect” button opens the standard
clojure.inspector/inspect-treewidget rendering the locals. This is quite useful when examining massive chunks of data.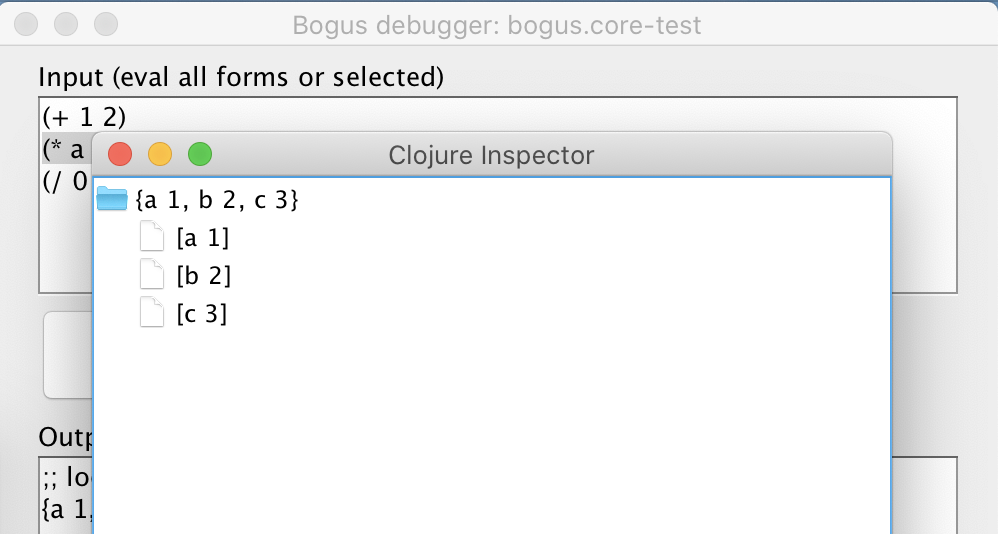
The Log area tracks the history of the expressions you executed and their results. That’s useful sometimes to copy-paste it somewhere. Should you get an exception, it gets rendered with the
clojure.stacktrace/print-stack-tracefunction (which probably needs some improvements).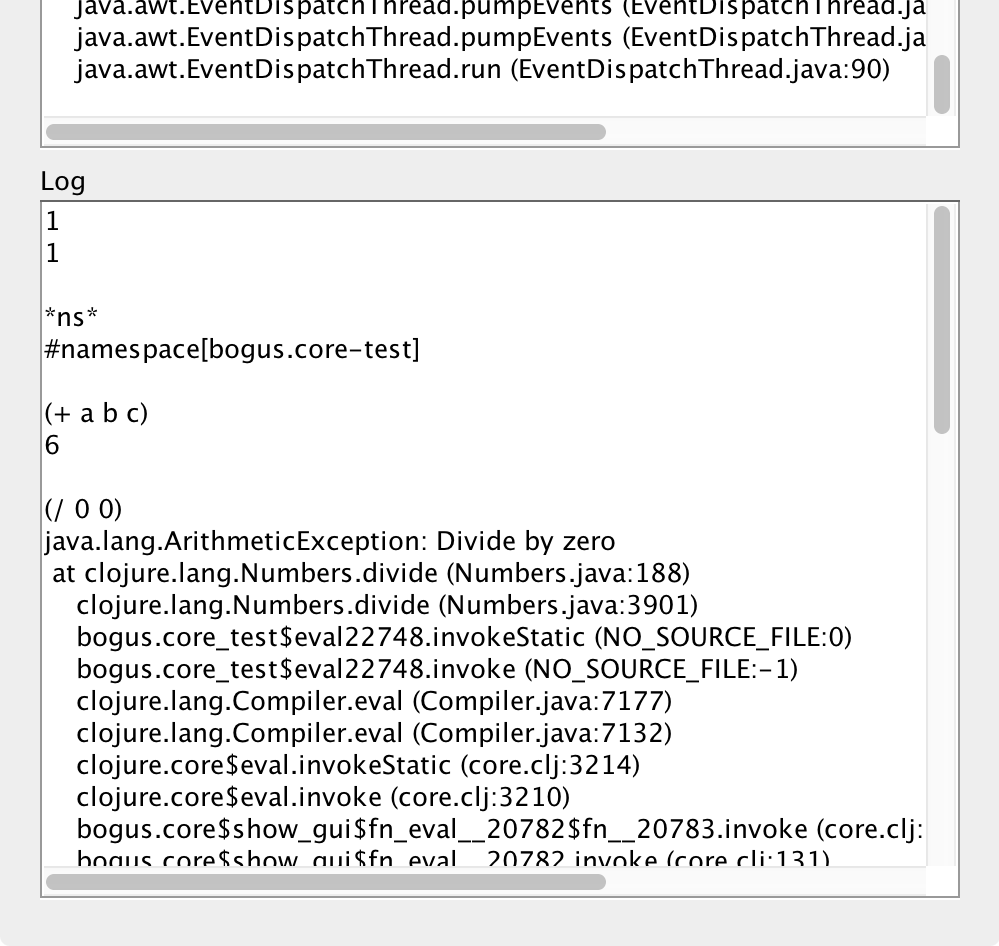
You can have several debug breakpoints, for example:
(defn do-some-action [] (let [a 1 b 2 c (+ a b)] #bg/debug (+ a b c) (let [d 9] #bg/debug (* a b c d))))The first debug session will take the
a,b, andclocals, whereas the second one will havea,b,c, andd. You won’t proceed to the second session until you close the first window.Bogus debugger works in tests, in nREPL, in ordinary REPL, in Manifold, in the futures as well. Here is a small demo of having two debug sessions in parallel threads:
(let [f1 (future (let [a 1] #bg/debug (+ a 1))) f2 (future (let [b 2] #bg/debug (+ b 1)))] (+ @f1 @f2))If you run this code, you’ll get the two windows each having their own locals:
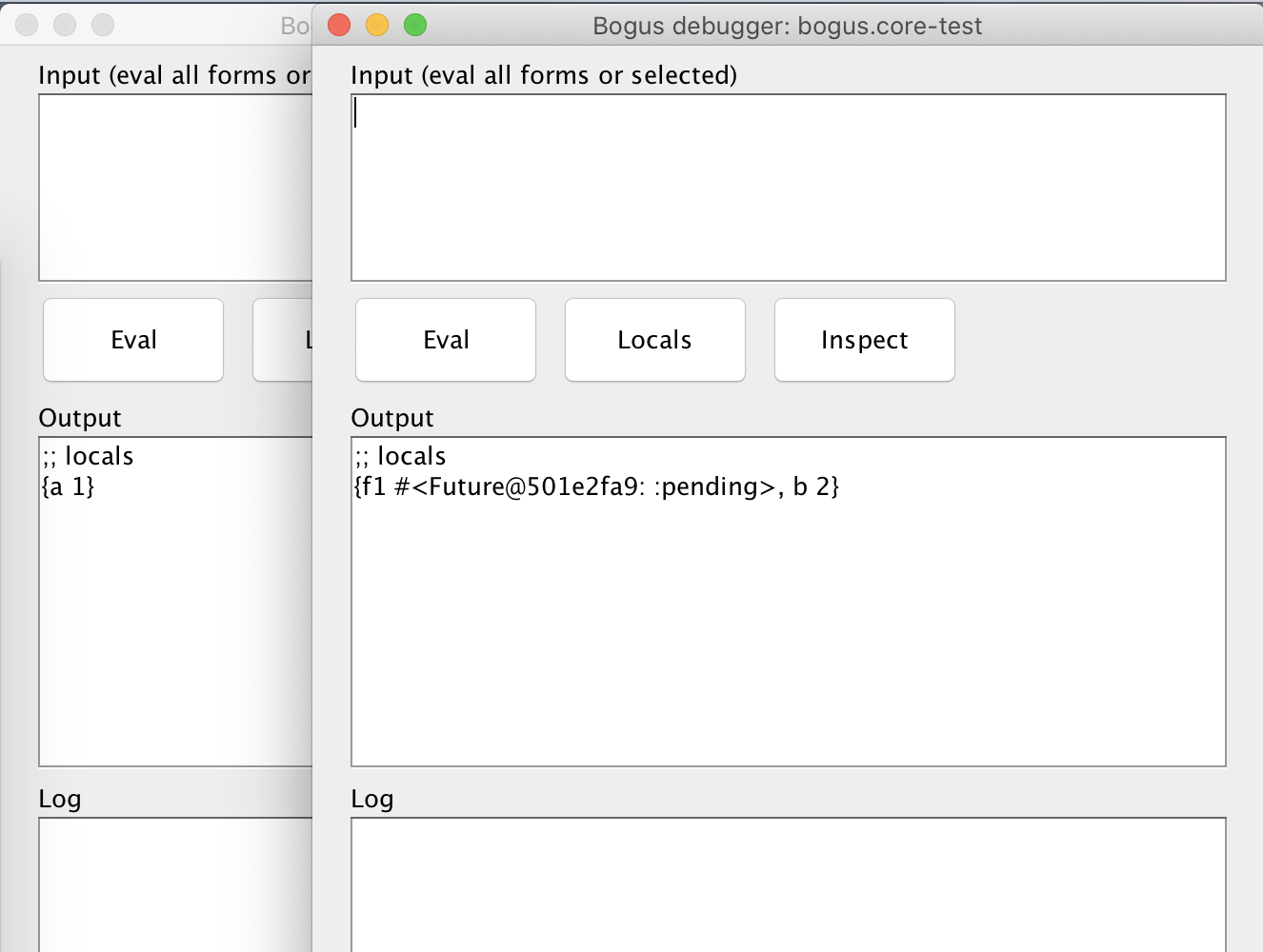
The second session has the
f1local var captured from theletclause. If you try toderefit, the entire REPL will hang due to the mutual blocking, so be careful when dealing with parallel debugging.How it works
The under-hood of Bogus is simple: it captures the local vars from the
&envmapping available in a macro. Then there is a couple of functions that “globalize” the locals by injecting them into the origin namespace usingclojure.core/intern. Once the namespace is populated, theevalform treats local vars as globals. Before leaving the macros, the vars are “deglobalized” meaning all the injected vars are removed. The macros is smart enough to preserve existing global vars: it temporary assigns them another name like__OLD_my-var__.Why
The idea of making my own debugger came into my mind while I was writing a new chapter about nREPL and code evaluation. Although Cider provides much more powerful tools for debugging, I still believe Bogus might be useful for someone new to Clojure. The main benefit of Bogus is, it doesn’t require the whole nREPL stuff and Emacs. One can use it with any editor or environment. After all, tinkering with Bogus gave me some good material for the book.
Other
Copyright © 2022 Ivan Grishaev
-
Увольнение
Прошлый понедельник запомнился слитыми письмами, где фирмы разрывали контракты с российскими удаленьщиками. Вроде того, что от Гугла по ссылке. Тенденция не обошла меня стороной. Понедельник я провел в смутной тревоге, понимая, что работодатель способен на этот шаг. В пять вечера получил письмо об увольнении.
По этическим причинам не будут постить сюда скрин — по моим меркам слив переписки находится ниже любого дна. Это был такой же абстрактный текст, как и у Гугла. Что-то в духе “мы ценим твою работу, ничего личного, прощай”.
Дело в том, Иван, что как бы мы ни ценили три с половиной года твоей работы, есть некие полиси, которые предписывают порвать наши отношения. Что это за полиси, где их увидеть и прочесть – начальство не уточнило.
Не то чтобы меня расстроила потеря работы — не конец света, найду другую. Но такой стремительный конец отношений заставляет мысленно к нему возвращаться. Еще в пятницу расписываешь коллегам задачи, проводишь созвоны, планов громадье. В понедельник — до свидания.
Казалось бы, кому как не мне, удаленьщику с семилетним стажем, понимать, насколько ты не защищен от подобных ситуаций. В отличие от всяких EULA, договор с заказчиком я читаю по слогам до подписания. Прекрасно знаю, что одним пинком меня могут выставить. Но на созвоне все улыбаются, и это кажется невозможным. Оттого пинок ощущается сильнее.
Удивила скорость всей процедуры. В 17:00 я получаю персональное письмо. Через пятнадцать минут приходит анонс всей команде: Иван больше не с нами, будем скучать. Еще через десять минут отваливается доступ ко всей инфраструктуре. Никаких обсуждений, торгов: все линейно, от тебя ничего не зависит.
Интересно, что адекватная реакция была только у одного человека – украинского коллеги. Он эмоционально ответил в тред с анонсом, что увольнение русских не поможет Украине и ваша гнилая солидарность никому не нужна. Но разве его кто-то слушал? Швейцария знает лучше Украины, как ей помочь.
Начальство взялось отвечать на выпад: теперь мы не можем платить Ивану. Сухо возражу — никаких проблем с оплатой не было. МодульБанк, в котором я счастлив обслуживаться, не под санкциями, свифты доходят. Кроме свифта, в нем работает альтернативная система Visa B2B Connect, доступная и в Швейцарии. На какое-то время я бы согласился получать Пейпал или Transfer Wise. Можно попробовать крипту: биток, USD-токены. Тоже норм, есть знать как обращаться (а я знаю).
Да что там: на худой конец я бы мог формально уволиться и поработать бесплатно, а потом, как все наладится, заключить контракт по новой ставке, чтобы компенсировать потери. За пять минут я назвал пять вариантов, а если подумать, найдутся другие. Но если сказано “не можем” — значит не можем.
Украинский коллега, кстати, тоже попал в поле зрения “помогаторов” Украине. Если мой контракт расторгнут (агрессор), то его — “временно приостановлен” до тех пор, пока “ситуация не придет в норму” (жертва). Временно — это на сколько? Норма — как это понимать?
Не надо быть гением, чтобы понять: “временно” означает “пока ты сам не уволишься”. Будешь заморожен месяц, год, пять. Ты жертва, поэтому увольнять тебя опасно: еще сольешь переписку в Твиттер и подорвешь репутацию фирмы. Поэтому прояви инициативу.
Схожее происходит и в других фирмах: от русских надо избавиться, агрессоры, все дела. Но от украинцев тоже, только слегка по-другому. “Временно отключим” вас, пока ситуация “не придет в норму”.
По идее я должен ругать Путина и его “спецоперацию”. Но дело в том, что уволил меня не Путин — это сделали конкретные люди. Которые, в свою очередь, вешают на меня груз: это не мы, это ваш президент, к нему и обращайтесь. Со мной это не работает. Я потерял работу потому, что менеджеры решили что-то доказать. Не сегодня Путин, так завтра нашелся бы другой предлог.
Наши с фирмой отношения не прошли проверку на прочность. Фирме важнее следовать международной повестке, чем сохранить ведущего разработчика, взятого три с половиной года назад. Хорошо, как считаете нужным.
Не вздумайте меня жалеть: уже подсуетился, собеседуюсь туда-сюда. Назревают два варианта. Пишу не ради нытья, а чтобы сбросить мысли в текст и двигаться дальше.
То, что происходит с нами сегодня, ново и непонятно. Замечаю тенденции, которых раньше не было; жизнь стремительно меняется, и не так уж важно, в какую сторону. Искренне надеюсь, что смогу как-то выразить мысли на эту тему в следующем тексте.
-
Если бы тебе сказали
У демагогов популярен дешевый прием — если бы десять лет назад тебе сказали X, ты бы не поверил. Например:
— если бы десять лет назад вам сказали, что Россия нападет на Украину, вы бы не поверили.
— Если бы десять лет назад вам сказали, что мир сойдет с ума из-за ковида, вы бы не поверили.
Этим трюком демагог пытается усилить свою позицию — никто не верил в то, что случилось, но оно случилось. Поэтому в то, что я говорю сейчас, тоже сперва не верят, а потом оно сбудется.
Не дайте вас обмануть. Мир непредсказуем и сложен, и никакой прогноз на десять лет не будет точным. Прогнозы не учитывают открытия, изобретения, психические отклонения политиков и прочие вещи, которые вокруг нас. Прогноз подразумевает, что за десять лет окружение не изменится, и за это время придет в то состояние, что показывает модель. А это неверно, неважно обычный у вас машын-лернинг или дип-машин-лернинг с подкреплением (Греф.jpeg).
Возьмите любое событие и подставьте впереди “если бы десять лет назад”. Результат всегда будет истинным:
— Если бы десять лет назад вам сказали, что биткоин будет стоить пять миллионов, вы бы не поверили.
— Если бы десять лет назад вам сказали, что незаконно построенный павильон на остановке снесут, вы бы не поверили.
— Если назвать человеку дату смерти за десять лет до нее, он бы не поверил.
— За десять лет до Pokemon Go никто бы не поверил, что люди будут ловить виртуальных зверей на улице.
— За десять лет до Чернобыля никто бы не поверил.
— За десять лет до Титаника…
— За десять лет до Чечни…
— За десять лет до Гитлера…
Короче, вы поняли — важные события предсказать невозможно. Отдельным личностям остается спекулировать: если случилось то, значит случится другое. Но это неверно.
Любопытно, что то же самое было и сто, и двести лет назад. Достаточно взять Толстого, Достоевского или хронику. Их персонажи живут в изменчивой среде, никто не знает, что будет через год и каждый движется как может. И это нормально: спокойным может быть только час или день. Будущее всего тревожит — как положительно, так и негативно — своей неизвестностью.
Меньше слушайте тех, кто говорит про прогнозы десятилетней давности.
-
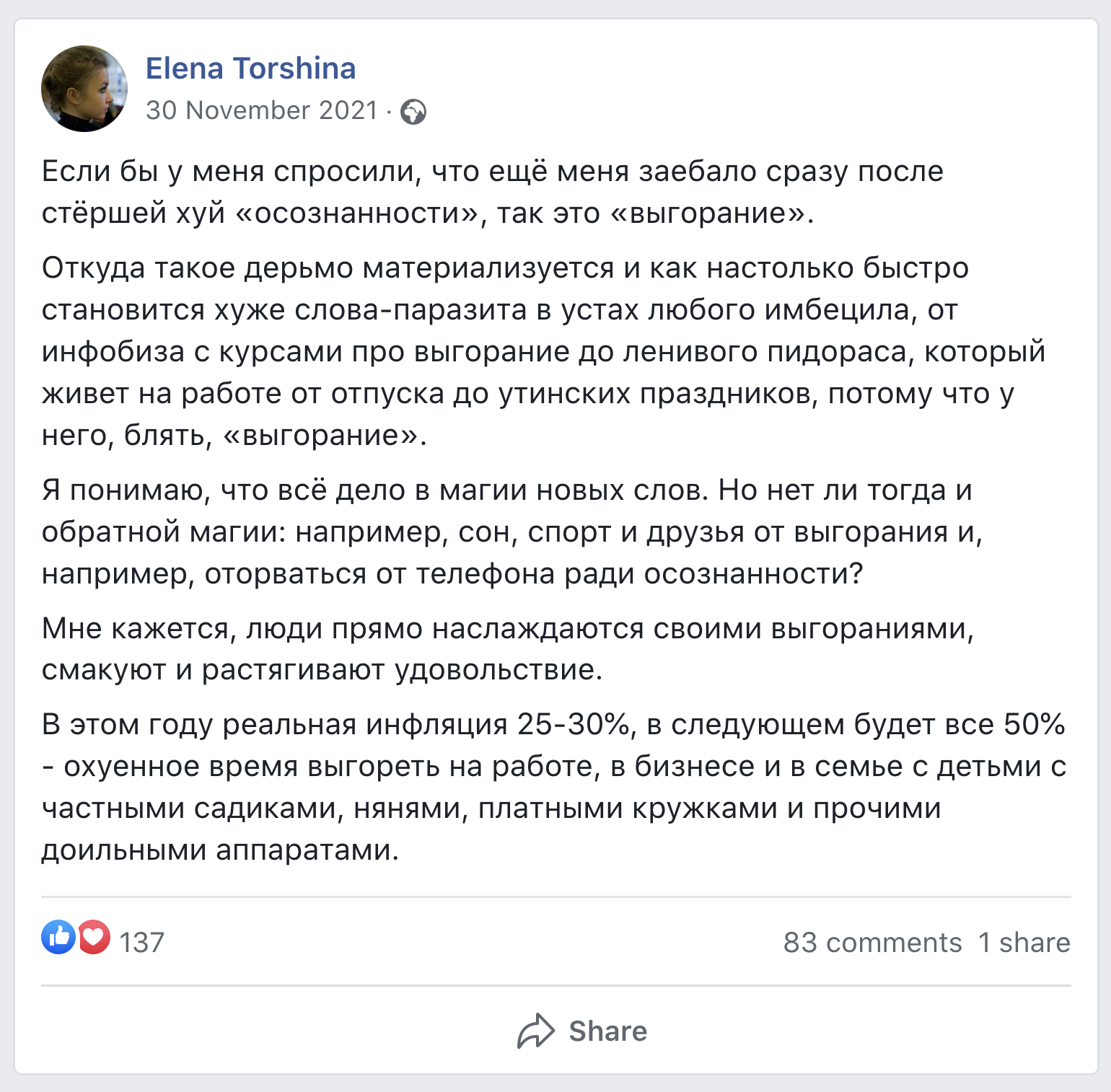
Единомышленники (+18)
Давно не читал Торшину и вдруг. Скриню для истории, на Фейсбук полагаться нельзя.
-
The Pact library for Clojure
(This is a copy of the readme file from the repository.)
Pact is a small library for chaining values through forms. It’s like a promise but much simpler.
Installation
Lein:
[com.github.igrishaev/pact "0.1.0"]Deps.edn
{com.github.igrishaev/pact {:mvn/version "0.1.0"}}How it works
The library declares two universe handlers:
thenanderror. When you apply them to the “good” values, you propagate further. Applying theerrorfor them does nothing. And vice versa:thenfor the “bad” values does nothing, but callingerroron “bad” values gives you a chance to recover the pipeline.By default, there is only one “bad” value which is an instance of
Throwable. Other types are considered positive ones. The library carries extensions for such async data types asCompletableFuture,Manifoldandcore.async. You only need to require their modules so they extend theIPactprotocol.Examples
Import
thenanderrormacros, then chain a value with the standard->threading macro. Boththenanderroraccept a binding vector and an arbitrary body.(ns foobar (:require [pact.core :refer [then error]])) (-> 42 (then [x] (-> x int str)) (then [x] (str x "/hello"))) "42/hello"If any exception pops up, the sequence of
thenhandlers gets interrupted, and theerrorhandler gets into play:(-> 1 (then [x] (/ x 0)) (then [x] (str x "/hello")) ;; won't be executed (error [e] (ex-message e))) "Divide by zero"The
errorhandler gives you a chance to recover from the exception. If you return a non-exceptional data inerror, the execution will proceed from the nextthenhandler:(-> 1 (then [x] (/ x 0)) (error [e] (ex-message e)) (then [message] (log/info message))) ;; nilThe
->macro can be nested. This is useful to capture the context for a possible exception:(-> 1 (then [x] (+ x 1)) (then [x] (-> x (then [x] (/ x 0)) (error [e] (println "The x was" x) nil)))) ;; The x was 2 ;; nilBesides
thenanderrormacros, the library provides thethen-fnanderror-fnfunctions. They are useful when you have a ready function that processes the value:(ns foobar (:require [pact.core :refer [then-fn error-fn]])) (-> 1 (then-fn inc) (then-fn str)) ;; "2" (-> 1 (then [x] (/ x 0)) (error-fn ex-message)) ;; "Divide by zero"Chaining with
thenanderroris especially good for maps as allowing destructuring:(-> {:db {...} :cassandra {...}} ;; Get a user from the database and attach it to the scope. (then [{:as scope :keys [db]}] (let [user (jdbc/get-by-id db :users 42)] (assoc scope :user user))) ;; Having a user, get their last items from Cassandra cluster ;; and attach them to the scope. (then [{:as scope :keys [cassandra user]}] (let [items (get-user-items cassandra user)] (assoc scope :items items))) ;; Do something more... (then [...] ...))Fast fail
To interrupt the chain of
thenhandlers, either throw an exception or use thefailurefunction which is just a shortcut for raising a exception. The function takes a map or a message with a map:(ns foobar (:require [pact.core :refer [then error failure]])) (-> 1 (then [x] (if (not= x 42) (failure "It was not 42!" {:x x}) (+ 1 x))) (error-fn ex-data)) ;; {:x 1 :ex/type :pact.core/failure}Supported types
The
corenamespace declares thethenanderrorhandlers for theObject,Throwable, andjava.util.concurrent.Futuretypes. TheFuturevalues get dereferenced when passing tothen.The following modules extend the
IPactprotocol for asynchronous types.Completable Future
The module
pact.comp-futurehandles theCompletableFutureclass available since Java 11. The module also provides its ownfuturemacro to build an instance ofCompletableFuture:(-> (future/future 1) (then [x] (inc x)) (then [x] (/ 0 0)) (error [e] (ex-message e)) (deref)) "Divide by zero"Pay attention: if you fed an instance of
CompletableFutureto the threading macro, the result will always be of this type. Thus, there is aderefcall at the end.Infernally, the
thenhandler calls for the.thenApplymethod if a future and theerrorhandler boils down to.exceptionally.Manifold
The
pact.manifoldmodule makes the handlers work with the amazing Manifold library and its types. The Pact library doesn’t have Manifold dependency: you’ve got to add it on your own.[manifold "0.1.9-alpha3"](-> (d/future 1) (then [x] (/ x 0)) (error [e] (ex-message e)) (deref)) "Divide by zero"Under the hood,
thenanderrorhandlers call thed/chainandd/catchmacros respectively.Once you’ve put an instance of Manifold deferred, the result will always be a
Deferred.Core.async
To make the library work with core.async channels, import the
pact.core-asyncmodule:(ns foobar (:require [pact.core :refer [then error]] [pact.core-async] [clojure.core.async :as a]))Like Manifold, the
core.asyncdependency should be added by you as well:[org.clojure/core.async "1.5.648"]Now you can chain channels through the
thenanderroractions. Internally, each handler takes exactly one value from a source channel and returns a new channel with the result. Forthen, exceptions traverse the channels being untouched. And instead, theerrorhandler ignores ordinary values and affects only exceptions. Quick demo:(let [in (a/chan) out (-> in (then [x] (/ x 0)) (error [e] (ex-message e)) (then [message] (str "<<< " message " >>>")))] (a/put! in 1) (a/<!! out) ) ;; "<<< class java.lang.String cannot be cast ..."Testing
To run the tests, do
lein testor justmake test.© 2022 Ivan Grishaev
-
Стоп-слова
Перечислю слова, которые никогда не использую и не советую вам. С объяснением почему.
Токсичный. Это слово по праву считается словом 2021 года. Внезапно всё у всех стало токсичным: коллеги, начальство, рекрутеры, близкие, родственники. Бездумно выдернутое из английского языка, слово перешло в русский без какого-либо смысла или конкретики.
Когда я слышу о токсичном человеке, мне не хватает деталей. Ну, токсичный, а что это значит? Чаще всего под этим имеют в виду “неприятный”, но все равно — чем именно неприятен человек? Он матерится? Делает замечания по работе? Не по работе? Он курит и затем дышит табаком на коллег (токсичен в буквальном смысле)?
Короче, мне нужны детали — что именно делает человек, как он себя ведет, что говорит. На практике оказывается, что его токсичность — плод воображения рассказчика, который с кем-то не ужился. Поэтому без конкретики слово “токсичный” ничего не значит.
Скам. От этого слова у меня просто горит. Бездумно вырванное из английского, в русском оно совершенно чужеродно. Скамом назывыют все то, в чем не разбираются, но считают подозрительным: криптовалюту, проекты Илона Маска. Нормальным считается заголовок в духе “Почему X это скам”. Хочется разбить автору лицо.
У английского слова scam есть точный, однозначный перевод — мошенничество. Других синонимов нет, точка. Вопрос — на кой черт притягивать слово, у которого есть четкий перевод? Я еще пойму английское privacy, которое трудно уместить в одно слово. Но для scam в этом нет смысла — обман, мошенничество.
Скамом называют все то, что им не является. Если учесть, что скам — мошенничество, то называя что-то скамом, вы должны понимать, в чем оно состоит. Ради интереса я спрашивал у некоторых людей, почему они называют скамом криптовалюту. Ответ удивил своей убогостью: потому что криптой платят за оружие и наркотики. Ох, беда.
Когда кто-то платит за оружие криптой, это не скам — обе стороны отдают и получают именно то, что ожидали, поэтому мошенничества нет. А когда вам звонит сотрудник безопасности Сбербанка и предлагает перевести деньги на “защищенную” карту — это мошенничество. Это значит, одно лишь участие криптовалюты не делает операцию с ней скамом, и операции с рублями не означают, что все чисто.
Короче, осторожней со “скамом” — слово короткое, а объяснить, что за ним стоит, трудно. Считаю дурным тоном использовать слова, смысл которых не понимаешь.
Лайфхак. Пошлое, уныле слово, которое заменило бездну русских слов. Способ, метод, прием, подход, решение, рецепт, алгоритм, подсказка, находка, идея — продолжать можно до бесконечности. Где-то в сети я видел картинку: перечислены эти слова, и подпись: если всё это у вас “Лайфхак”, то вы долбоёб. Грубовато, но в целом верно. Совершенно не вижу смысла в “лайфхаке”, когда говорю о способе решить проблему.
Ивент, риквест. Аналогично скаму, у этих слов есть точный, однозначный перевод. Event — событие, мероприятие, request — заявка, обращение. Поэтому когда вижу текст вроде “проведем корпоративный ивент”, становится стыдно от чужой тупизны. Самое дно — писать эти слова через и, то есть ивент и риквест. Получается декартово произведение тупизны и стыда.
Сторителлинг. Глупость этого слова обеспечена тем, что оно состоит из двух английский слов: story (история) и tell (сказать кому-то). В русском языке есть более емкое “рассказ”, когда человек доносит мысль или историю до слушателей. Как устно, так и письменно.
Таким образом, сторителлинг становится рассказом. Сторителлер, прости господи, это рассказчик. Курсы сторителлинга — курсы навыка рассказа, уроки рассказывания, мастерство рассказчика.
Современный сторителлинг, как правило, это гнилая реклама. К ней добавляют нелепых персонажей и дурацкий сюжет в надежде, что прокатит. Другой тип сторителлинга — доклады со сцены, когда человек рассказывает очевидные истины, прохаживаясь по сцене взад-вперед, смотря в пол и делая глубокие паузы.
Бумеры, зумеры. Не припомню случая, чтобы понадобилось выделить часть аудитории по возрасту. Подобная выборка отдает расизмом — предвзятостью к людям по определенному признаку. Фраза “зумеры не поймут” или “бумеры проходят мимо” в принципе не могут звучать вежливо и подходят только для пререканий в сети. Ответ “окей, бумер” я считаю настолько тупым, что кроме вздоха у меня нет другой реакции.
Выгорание. Никакого выгорания нет, есть доведенная до крайности усталость. То “выгорание”, которым страдает половина интернета, лечится сном, отказом от гаджетов в вечернее время, планированием дел на бумаге, разговорами с коллегами, начальством, родными. Всё, вы здоровы.
Уверен, читатели подскажут другие вредные слова, которых лучше не говорить.
-
Не словом, а делом
Как правило все сервисы, когда мы в них логинимся, присылают письмо. Там написано когда и с какого устройства был выполнен вход. Подобные письма присылают банки, мессаджеры, социальные сети, крипто-биржи. Это хорошо и правильно.
Как-то раз я внимательно прочитал подобное письмо. Смутила фраза, которую можно перевести так:
Если это вы, все в порядке. Если нет, немедленно заблокируйте ваш аккаунт.
Давайте представим, что вас взломали. Вы ничего не делали, тупили в телефон, и вдруг пришло письмо, что из Украины зашли ваш клиент-банк или биржу. Все, паника. Время идет на секунды. У мошенников все отработано, они моментально переводят деньги.
Что делать? Писать в техподдержку на
support@foobar.lol? Уже сам факт того, что этоsupport, говорит о том, что они доберутся до моего тикета в лучшем случае через час. Звонить? Номера нет под рукой, надо найти и потом висеть в очереди, слушая дурацкую музыку. Можно заблокировать личный кабинет через личный кабинет, но чтобы это сделать, надо сперва попасть в личный кабинет, верно? А мошенники могут этому помешать, например сменив пароль.Оказавшись в подобной ситуации, вы поймете: фраза “немедленно заблокируйте ваш аккаунт” — чистой воды профанация. Это можно сделать, только заранее потренировавшись. А кто будет тренироваться, да к тому же еще на разных сервисах?
Должно быть так. Вместо фразы “немедленно заблокируйте ваш аккаунт” в письме должна быть жирная красная кнопка “ЭТО НЕ Я!!! ЗАБЛОКИРОВАТЬ АККАУНТ!!!”. Ссылка подписана токеном, который действует пять-десять минут. Даже если письмо со временем утечет, ссылкой нельзя будет воспользоваться.
Ссылка перебрасывает на форму, где нужно подтвердить блокировку. Форма отправляется методом POST, чтобы всякие preview-сервисы не стриггерили блокировку за вас. После отправки формы аккаунт замораживается, все активные сессии завершаются, транзакции в очереди отменяются. Далее восстанавливаем доступ через поддержку.
Такая схема — истинная забота о клиенте. Не просто “заблокируйте аккаунт”, а все необходимое на месте. Конечно, она тяжелее в реализации, но сохранит деньги клиента и репутацию фирмы.
-
Качество Excel
Каждый раз, когда запускаю Эксель, поражаюсь, насколько он ужасен. Годы идут, столько всего меняется в лучшую сторону, а офисный пакет Микрософта так и остается дном.
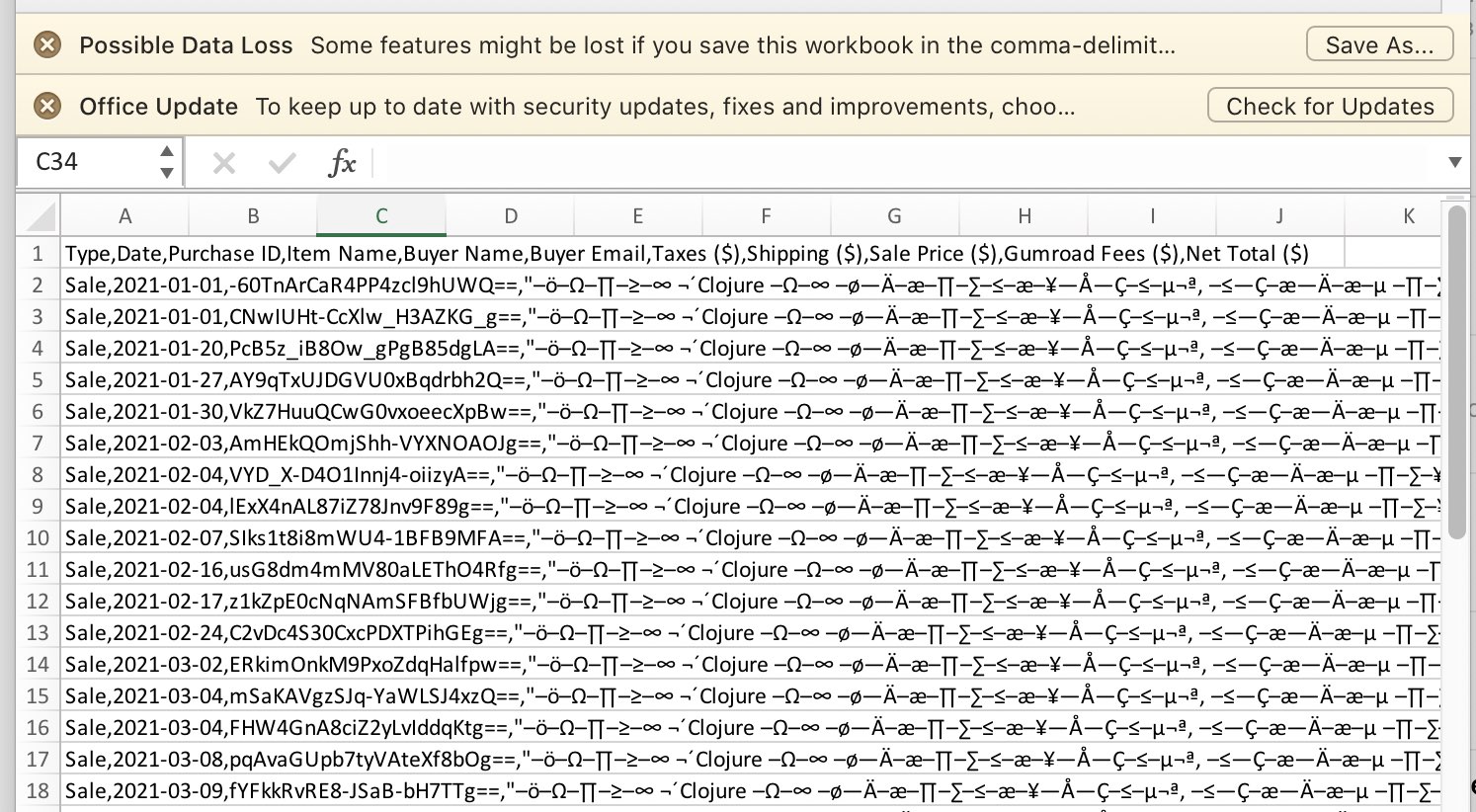
Например, прислали мне CSV-файлик. Эксель уверен, что умеет его открывать, потому что при установке связал с собой расширение .csv. Тыкаю. Открывается картина:
Ну еб жеж тебя! Не умеешь открывать – зачем полез?
По пунктам:
-
Все поля слиплись в одну строку. CSV это Comma Separated Values, так? Comma значит запятая. Но придурочный Эксель делит поля по точке запятой. Comma, любезнейший, вы понимаете английский? Почему нельзя добавить простой детектор — пробежать строку и проверить, каких разделителей больше? Не понимаю.
-
Вместо русских букв — даже не кракозабры, которые случаются, если читать utf-8 как cp1251, а какие-то греческие письмена. Омеги, сигмы. Что происходит? Опять же, нельзя что ли прочитать десять строк и сделать анализ кодировки?
-
Ссыкливая надпись Possible Data Loss в первой желтой полоске. Некоторые данные могут быть потеряны. Что бы мне об этом пишешь, идиотский эксель? Сразу открой в формате Экселя, чтобы я мог пользоваться всеми возможностями. И только потом, если захочу, экспортирую проект в csv. А храниться он будет в Эксель-файле. Короче, разработчики не понимают разницу между проектом и промежуточным форматом. Беда.
-
Еще одна ссылкивая полоска с информацией о том, что нужно обновиться. Ни за что не поверю, что эти проблемы исправили в последней версии, так что зачем?
Другие мелочи. В нормальных программах, если мы редактируем элемент, нажимаем ввод. В экселе для редактировании ячейки надо нажать F2. Почему не F9 или F12? Тоже хорошие клавиши, и в них столько же логики.
Нажатие Enter перемещает курсор на ячейку вправо. Почему? Если я хочу вправо, то нажму стрелочку. Почему ввод что-то перемещает?
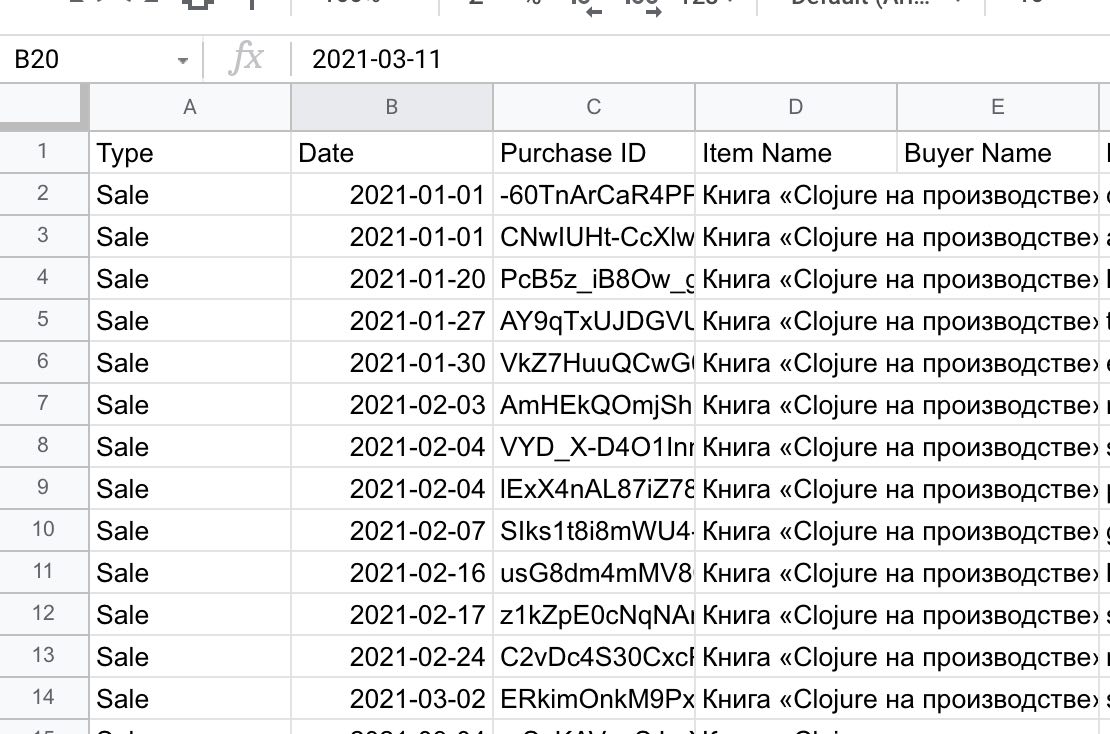
А вот тот же документ в Google Sheets. Кодировка нормальная, все разбилось по ячейкам, вопросов нет:
К чему это все?
Отдельные персонажи поругивают веб-приложения, что не натив, а декстоп весь такой шустрый, нативный, си-плюс-плюс. В широком плане это неправда — бывает так, а бывает наоборот.
Браузерный JS уже давно быстрый как незнамо что. Сравните работу в Adobe Illustrator (плюсовую настольную программу) и Фигму (Js, React + Canvas). И все станет ясно.
Или настольный Эксель с гугловым Sheets.
Десктопный софт может нещадно тормозить, а браузерный — плясать на кончиках пальцев. Десктопный софт может застрять в прошлом на два десятка лет, потому что там же застряли его разработчики.
Так что нет одного пути, все условно и не ложится на обобщения.
-
Writing on programming, education, books and negotiations.
{kind=link}