-
Опыт с телевизором
Сегодня не модно любить бренды вроде Эпл и Икеи, которые якобы заботятся о пользователях. Уже не новость, что за мнимую заботу потребитель дорого платит и подсаживается на иглу бренда. Однако у других фирм с заботой вообще все плохо.
Первое января 2022 года. Имеем дорогущий телевизор LG с OLED-матрицей. Это не просто хороший телевизор, а в принципе лучший вариант, что предлагает рынок. Своего рода Макбук-Про M2, если судить в таких категориях.
Так вот, казалось бы. Даже при столь высокой цене ни упаковать, ни подготовить к распаковке в LG его не смогли. Видимо, нет отдела, который занимается тем же в Эпле. Плюс ворох мелких косяков.
Например: достаю телевизор из коробки, собираюсь повесить на кронштейн. Выясняется, что в комплекте нет болтов для VESA-крепления. Дырки есть, а четырех болтов стоимостью, сука, 50 копеек каждый — нет.
Ладно, открываю пакетик с крепежом для кронштейна. Вижу два набора болтов: большие и маленькие. А на телевизоре дырки под СРЕДНИЕ. Получается чемодан без ручки. Дорогой, топовый чемодан. Но без ручки.
В тот момент я подумал, что неплохо бы вернуть смертную казнь, причем трансграничную. В Корею или Китай вылетает наш истребитель, захватывает служащих LG, от рабочего до исполнительного директора, и везут в Воронеж. Там показательно четвертуют на площади с трансляцией в интернет. Чтобы запомнили: если есть резьба, то в комплект должен быть болт под нее.
Отрываюсь от мечтаний. Первое января, магазины закрыты, купить болты не получится. Спокойно, товарищи: поставим телек на подставку и подождем до послезавтра. Беру подставку. При перемещении слышу, как брякает кусок металла. Елозит внутри, словно мыло в раковине. Уроды из LG не закрепили его, просто стыд.
После сборки подставка шатается. Поначалу мозг отказывается это принимать: подставка, предназначенная держать экран стоимостью около ста тысяч рублей, шатается. Кот пробежит, хвостиком махнет, и плакал твой телевизор. Ну или дети.
Эта гифка стоит тысячи слов и океана эмоций:

Вращается как шайба на льду. Это еще пол кривой, а на ровной поверхности крутится как спиннер.
В общем, обшарил я все полки-коробки и нашел пару нужных болтов. Еще пару скрутил здесь и там. Шайбы из комплекта оказались слишком толстыми, заменил на свои. Весь этот колхоз удачно лег друг на друга, как парад планет, и телек я повесил. С удовольствием повесил бы еще пару корейцев, которые отвечают за комплектацию.
Поймите меня — я не просто ною. Так делать нельзя, просто нельзя. Когда товар дорогой, забота о покупателе не просто желательна, она обязательна. В комплекте должно быть буквально все, что только понадобится: болты, гайки, стяжки, крепления, клипсы и остальное. Еще шестигранники и одноразовые отвертки. Все это стоит гроши — я ведь не прошу из закаленной инструментальной стали.
Та же Икея кладет в набор все перечисленное. Собираешь шкаф — вот тебе шестигранник, гаечный ключ и отвертка. Купил четыре кресла — получишь четыре пачки отверток и прочего. До сих пор по тумбочкам лежат.
Еще лучше пример — Эпл. Одно время я интересовался их 6К-монитором стоимостью в полмиллиона. Не чтобы купить, конечно (он мне не нужен), а с точки зрения товара. Как он выглядит, как упакован, как подключается?
Я был поражен процессом его распаковки. Ощущение, что сидела команда и рассчитывала все варианты: что покупатель подумает, что ему покажется и прочее. Распаковка напоминает запуск космической ракеты. Все уложено именно в таком порядке, и разрезы сделаны в тех местах, и материалы подобраны так, что отклонений быть не может.
Видосы:
Учтено, что сначала ты ставишь не до конца распакованный экран на подставку и только потом снимаешь остатки упаковки, чтобы не заляпать экран. При этом нет никаких инструкций. На каждом этапе доступен строго один следующий шаг, который как-то выделен. Пользователя не держат за идиота, а помогают ему.
Ясное дело, кто-то проделал большую работу, и она повышает стоимость товара. Это правильно: человек, который покупает монитор за полмиллиона, вряд ли думает о выживании, его волнует комфорт. Легче заплатить условные тридцать тысяч вместо того, чтобы одуплять сборку самому. Сборка — это досадная процедура, которая отделяет от пользования товаром. Поэтому умные люди стремятся ее сократить.
Да что там, я бы спокойно купил телевизор и за сто пять тысяч рублей, лишь бы в нем был весь нужный крепеж. Заплатил бы по тысяче за болт, только бы все было на месте. Да, такой я лошок-лопушок: не хочу бегать за болтами в строительный магазин. Подставку бы еще починить — долить миллиметр пластмассы. Не разорились бы.
Кстати, забавно вспоминать, сколько было шуток про подставку для эпловского монитора. Нога за тысячу долларов! Какой идиот ее купит? Вспоминаю анекдот про Тарантино:
— Квентин, вы так и не сняли фильма лучше “Криминального чтива”!
— А кто снял?
Смех смехом, а лучше той подставки ничего нет. Я ее видел, держал, шатал. Уверяю, когда будут бомбить Воронеж, подставка устоит. Она держит монитор и при этом красива. Видимо, сочетание этих двух и делает ее столь дорогой.

Если посмотреть на другие мониторы и телевизоры, станет ясно: их подставки либо не держат, либо уродливы. Нет, правда, все подставки отвратительны: какие-то лапы птеродактиля. На работе у меня монитор на 144 герц, который два года назад стоил 87 тысяч. На подставку нельзя смотреть без стыда. Дома монитор на 120 герц, тоже не дешевый. Подставка рвотная. Про телевизор я уже рассказал — у топовой модели она шатается.
Особое изумление вызывают инструкции к дорогим товарам. Мудаки-производители печатают брошюры объемом на сотни страниц. Плюс всякие купоны, реклама, гарантийные талоны. В итоге набегает на томик Чехова. Но почему-то схему сборки надо обязательно уместить на один лист. Чтобы картинки были со спичечный коробок. Чтобы подносить лист к глазам. Напечатать крупно на трех, четырех листах почему-то нельзя. Бумагу экономят?
Смотрите, в LG считают, что это понятная инструкция:

Забавный факт: инструкция предупреждает, что экран хрупкий и при установке его легко продавить пальцем. Как же, мудачье вы этакое, мне его держать? Почему бы не надеть на края тонкие пенопластовые бамперы, которые стоят вообще нисколько? Может, вместо предупреждений лучше обезопасить покупателя?
Короче, выводы.
-
Даже покупая дорогой товар, будьте готовы, что не хватит винтиков за два рубля. Почему это считается нормой — загадка.
-
Свою продукцию нормально пакуют только Эпл и Икея. Эти фирмы не сахар и порой вытирают ноги о покупателей. Но после их упаковки иметь дело с чем-то другим невозможно.
-
Если вы что-то производите, кладите в комплект все, что может понадобиться. Если покупатель побежал в магазин за чем-то недостающим — фирма обосралась.
-
Сложный товар нуждается в продумывании процесса распаковки и установки. Это повышает цену, но отбивается обзорами и опытом покупателя. Люди готовы платить дороже за комфорт и заботу.
-
Инструкции — крупнее. Нет, еще крупнее. ЕЩЕ СУКА КРУПНЕЕ. Один рисунок — одна страница.
-
Руководствами на малайском, болгарском и т.д. пусть подтирается СЕО.
-
Пригласите случайного Васю с улицы распаковать и включить ваш продукт. Уверяю, узнаете много нового.
Все, выговорился. Отпустило. Полегчало.
С наступившим!
-
-
Ютуб в настольном приложении
Открывая очередной видос на Ютубе, подумал — так жить нельзя. Мне ведь нужно только видео, а Ютуб в довесок льет рекламу, трекинг, похожее видео, комментарии. Браузер Brave и сторонние блокировщики помогают, но все тормозит. Плюс Гугл постоянно меняет что-то в интерфейсе, и чувствуешь себя животным, чью миску с едой передвинули в другой угол.
Наверняка же есть настольная прога, которой даешь урл — и она показывает. Слегка погуглил, и выяснилось, что так и есть.
Знаменитый плеер VLC умеет играть ютубные урлы. И не только ютубные, но и Вимео, BBC и другие (Порнохаба, увы, нет). Реализовано это скриптом на Lua, который по урлу вычисляет прямую ссылку на гугловый стрим.
Однако выяснилось, что то ли скрипт поломали, то ли Гугл обновился, и теперь просмотр Ютуба не работает. Вот что надо сделать, чтобы его починить.
Скачайте скрипт
youtube.luaс Гитхаба по этой ссылке. Далее зайдите в папку/Applications/VLC.app/Contents/MacOS/share/lua/playlistНа винде и линуксе, понятно, путь будет другим. Удалите файл
youtube.luac— это скомпилированный модуль, который сейчас не работает. Скопируйте сюдаyoutube.lua, что вы скачали. Перезапустите плеер.Чтобы открыть ютубный видос в VLC, пройдите по пунктам
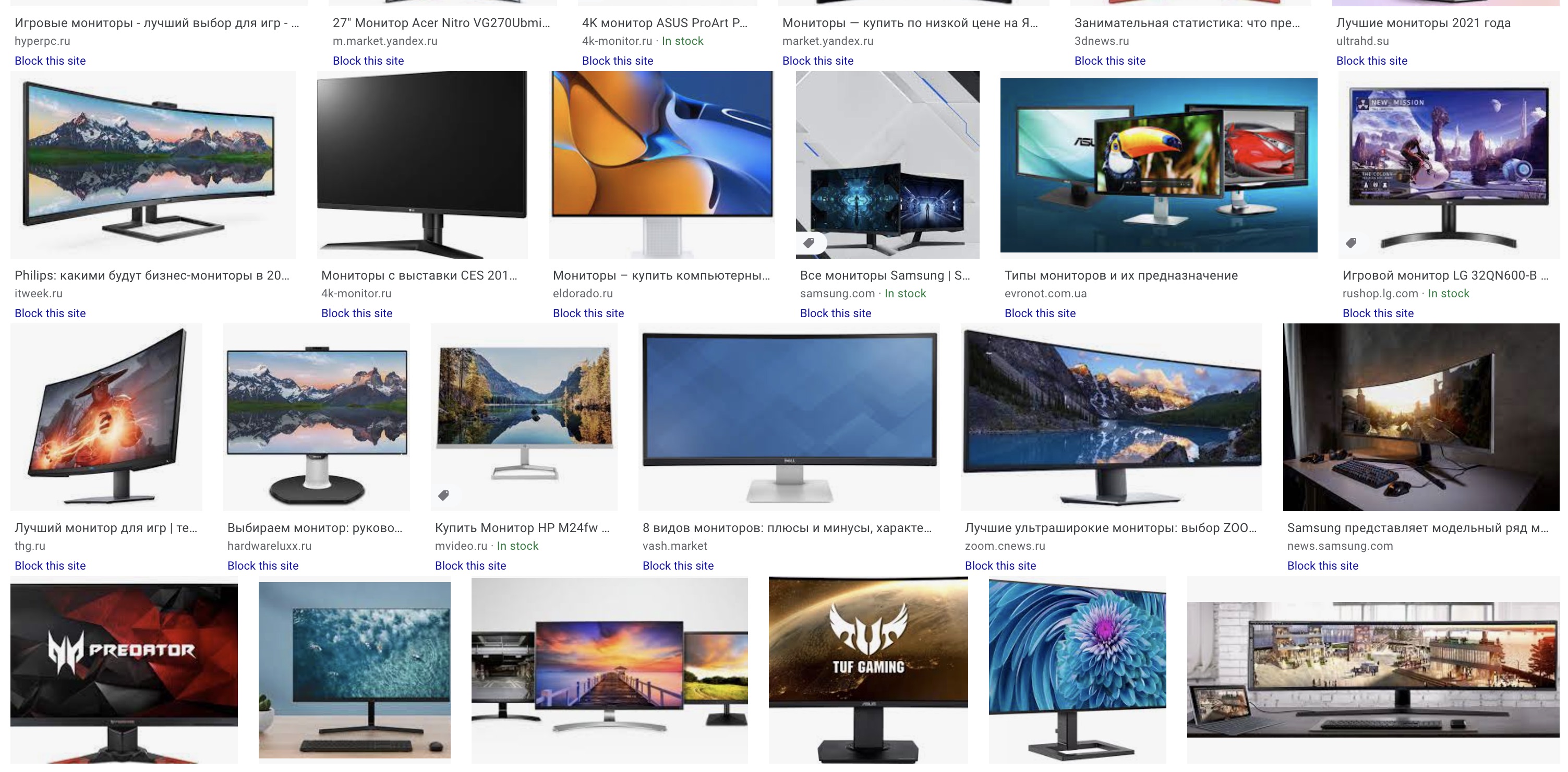
File→Open Networkили нажмитеCommand+N. В окошке введите урл.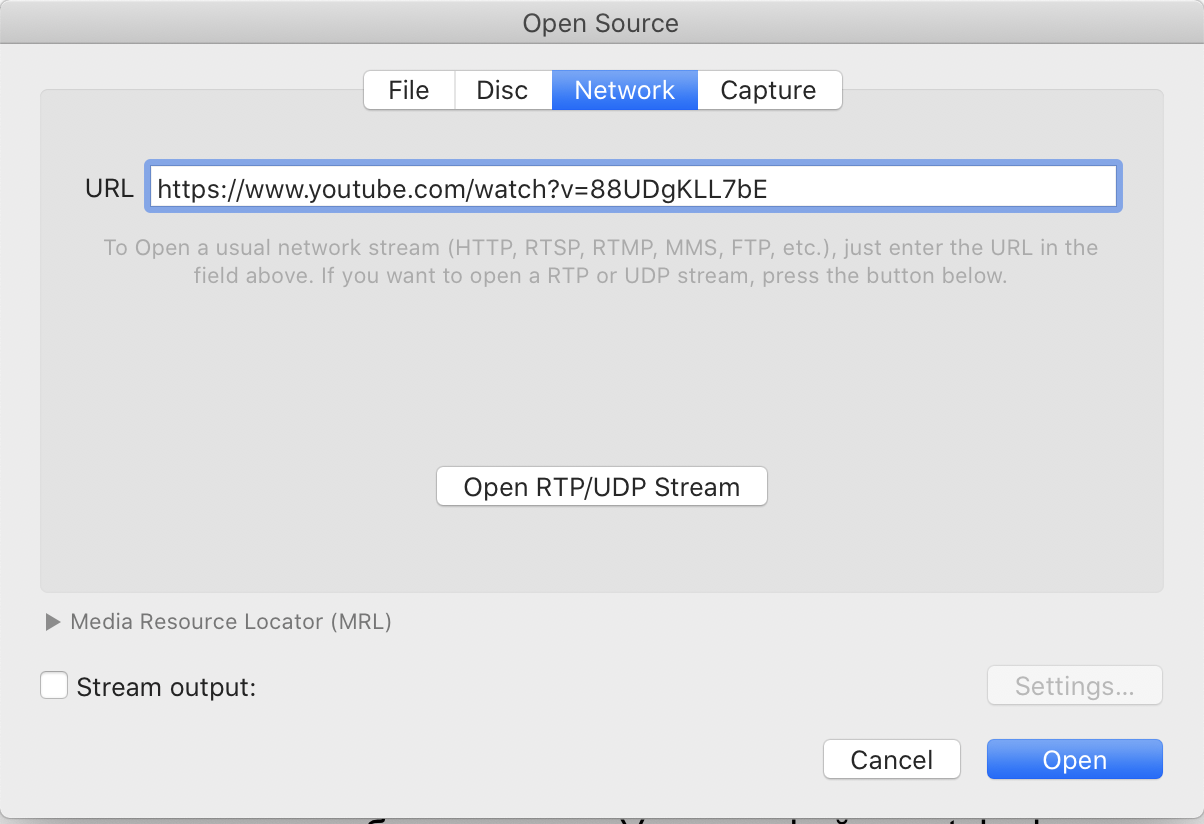
Плеер немного потупит, и появится видео:

Что радует:
- нет рекламы и трекинга;
- нет тормозных скриптов;
- нет оверлеев, по клику на которые улетаешь невесть куда;
- нет комментариев, рекомендуемых видосов и прочего.
Такой просмотр анонимный: он не осядет в истории, не будет преследовать годами на главной. Если видео длинное, плеер можно запаузить и свернуть как обычное окно. Не будет лишней вкладке в Хроме.
Работает перемотка стрелочками, при этом вы сами настраиваете, на сколько секунд. Аналогично с ускорением видео: в выпадающем меню Playback открывается бегунок.
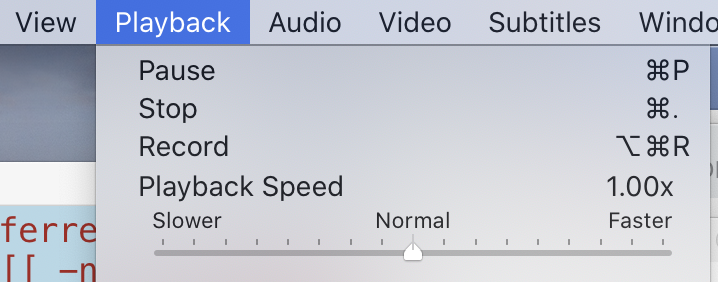
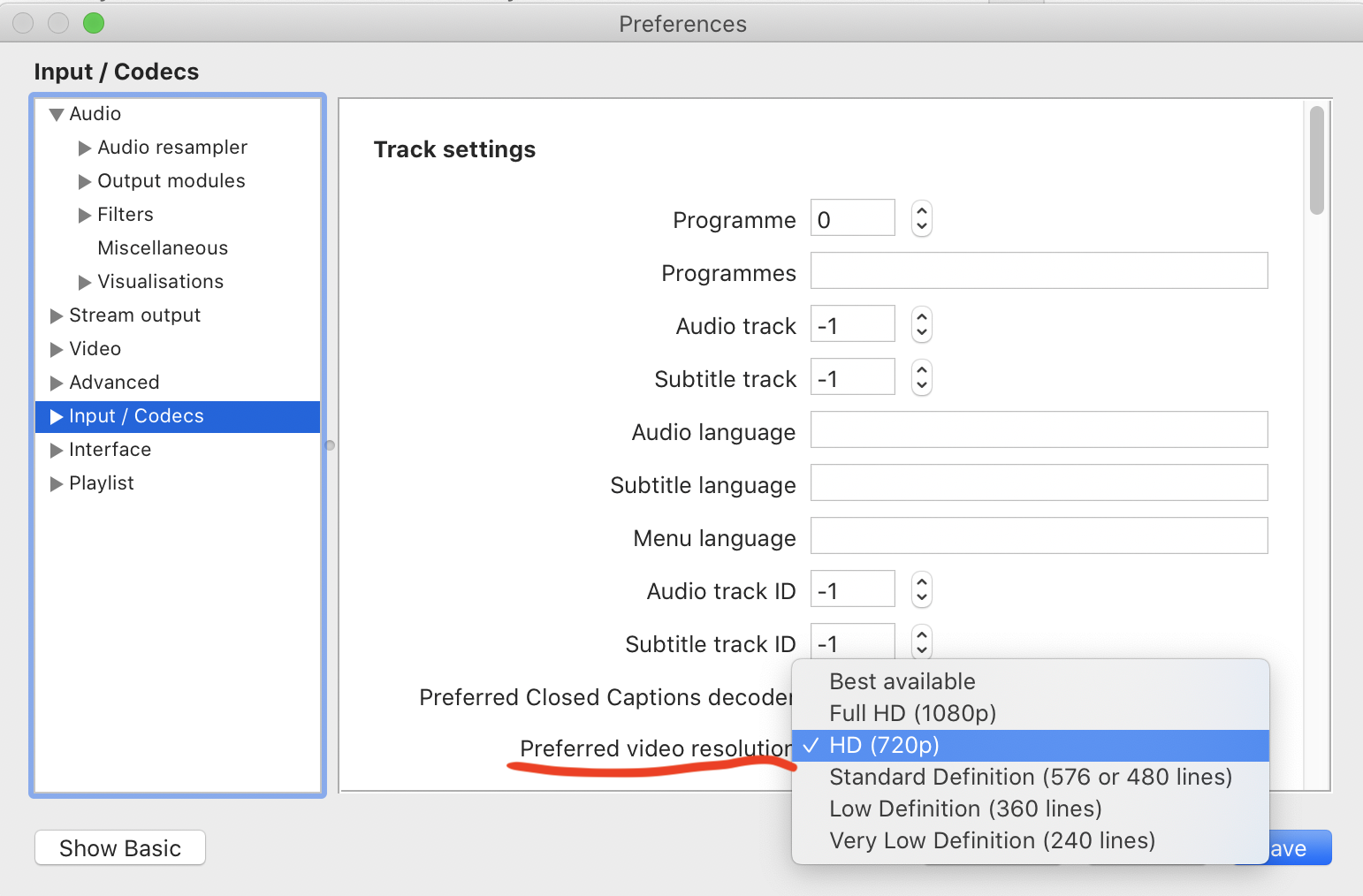
С качеством видео все сложно. Его можно менять, но настройка спрятана так глубоко, что дойдет только сильнейший. Сначал
VLC→Preferences→Input / Codecs, кнопкаShow All.
Затем прокрутить до Preferred video resolution. По умолчанию там Best available, что слишком жирно. 1080 или 720 хватит за глаза.
Автоматизация
Чтобы быстро открыть видос, напишем функцию на bash. Добавьте в ваш
~./bashrcили~./zshrcследующее:function play(){ /Applications/VLC.app/Contents/MacOS/VLC -v $1 & }Амперсанд на конце запустит процесс в фоне, чтобы можно было закрыть терминал, не прибив плеер. Теперь достаточно вызвать в консоли
play https://www.youtube.com/watch?v=88UDgKLL7bE— и появится плеер с видосом:

Минус — VLC не сохраняет прогресс просмотра. На длинных видосах, которые смотришь урывками по нескольку дней, можно случайно потерять прогресс.
Схема не работает с плейлистами: при попытке его открыть запускается только первый видос. Однако VLC поддерживает свои плейлисты. С его точки зрения ютубное видео — один из элементов плейлиста. Откройте по очереди несколько видосов и сохраните в файл m3u. Получается локальный плейлист, не привязанный к учетке гугла. Положите его в Дропбокс или где вы храните файлы.
Можно вести несколько плейлистов: избранное, посмотреть позже, музыка и так далее.
В итоге получается полностью анонимный просмотр Ютуба, без рекламы и с поддержкой плейлистов. Пока что я тестирую такой подход, и в целом ощущения приятные — как будто глоток свежего воздуха. Конечно, ощущения другие: здесь программа реагирует медленнее, а здесь быстрее. Неизвестно, к чему приду, но попробовать стоит.
Если вы знаете аналоги, расскажите в комментах.
-
Advent of Code
Наступил декабрь, и программисты всего мира бросились решать Advent of code. Кто не знает, это цикл задач на алгоритмы. Каждый день появляется новая задача, а их сложность постепенно нарастает. Задачи обсуждают в интернете, сравнивают решения, спорят… словом, этакий сериал для программистов.
Пару лет назад я тоже брался за AoC. Мне хватило часа, чтобы понять — никогда не буду этим заниматься, и вот почему.
Во-первых, формулировка заданий. Когда я читаю про гномов, эльфов и магические камни, то хочется кричать. Неужели нельзя подобрать нормальные термины? У меня уходит сорок минут на то, чтобы понять, что от меня хотят. Мне грех жаловаться на английский, но порой я копирую задачу в гугло-переводчик, чтобы разгрести эту ахинею. Не хочу тратить столько времени на работу — сделать текст понятным, — которую должен был сделать автор.
Далее, предположим, у вас и вправду зачесались руки что-то покодить. Неужели нет ничего под рукой? Написать библиотеку, какой-нибудь плагин, документацию? Это гораздо полезней, потому что послужит людям. А какая польза в решении задачи с волшебными камнями? Это одноразовый код, страшный и понятный только автору. Он пойдет на помойку.
Хуже всего тот шум, что производит Advent of Code каждый декабрь. Напоминает бегунов в парке или веганов: они не могут бегать и веганить молча, нужно всем об этом рассказать. Блоги, твиттеры и другие площадки наводняются унылыми постами на тему “AoС day 5 in Rust”. Для меня это красный флаг: если вижу, что автор будет тридцать дней кормить меня “интересными задачками”, отписываюсь без раздумий.
Advent of Code — это турнир, в котором вам никогда не выиграть. Как правило, все одиннадцать месяцев мы делаем рутину: читаем базу, Кафку и перекладываем данные туда-сюда. Дай бог раз в квартал обходим дерево. Но ни с того ни с сего в двенадцатый месяц надеемся преуспеть в решении нетривиальных задач. С какой стати? Это как новичку пойти в спортзал и каждый день заниматься по два часа. Чем это кончится? Организм не вынесет внезапной нагрузки, плюс добавьте духовное поражение. Так почему вы уверены, что быстренько решите этот бред с гномами и эльфами?
Advent of Code построил специфическую тусовку. Ее завсегдатаи решают подобные задачи за три минуты. Вступить с ними в соревнование — гарантировано обречь себя на проигрыш. Это чужая среда, чужая повестка, и обычному, заурядному программисту (как мне, например) там делать нечего.
Сказанное выше не значит, что я против Advent of Code. Ради бога, решайте, если вам нравится. Важно понимать: AoC не сделает вас лучше, если вы им занимаетесь. Ровно так же вы не станете хуже, если вам наплевать. Вы можете быть отличным программистом даже без репозитория
advent_of_code_2021на Гитхабе. А новогодний шум легко и перетерпеть. -
FAANG не предлагать
Не понимаю, почему люди так стремятся FAANG. В последнее время пена пошла через край: каждую неделю появляются статьи на тему “Как за полгода я устроился в условный Фейсбук/Гугл”, и конца этому не видно. Истерия достигла такого масштаба, что появились фирмы-нахлебники, которые за скромную сумму готовят к FAANG-у: переписывают резюме, разбирают задачки.
Я бы не стал писать этот пост, если бы не видел похожие мысли у окружающих. Всем нужен Фаанг; взрослые люди на полном серьезе зубрят по ночам красно-черные деревья, обход графов и прочую муть, которая понадобится им раз в жизни.
Для меня это своего рода унижение. С какой стати я должен готовиться к собеседованию? Вот он я, что умею, то умею. Расскажу то, что делаю регулярно. Если не знаю, как обойти граф, то быстро нагуглю. В чем проблема-то? Представьте, что программист условного Гугла забыл обход графа. Его что, сразу увольняют? Нет, он как и мы открывает Гугл и находит то, что нужно.
Но поскольку очередь в гуглы-фейсбуки расписана на пару лет вперед, фирмы позволяют любое измывательство над соискателем. Не развернул связный список – гуляй, нам не нужны неудачники. Постепенно эта модель приходит в Россию. Условные яндексы-тиньковы переняли ту же дрочь на алгоритмы, которую должен выдержать новичок, как в худших традициях студенческих братств.
Одержимость алгоритмами на собеседованиях переходит все границы. Как ни почитаешь статью какого-нибудь бедняги, которого пять часов мурыжили алгоритмами, так становится не по себе от этой лжи и лицемерия. Алё там: сложные алгоритмы нужны лишь изредка, а основное время программист проводит за рутиной: читает данные из файлов и сети и перекладывает в другое место.
Зацикленность на алгоритмах говорит о том, что в фирме не понимают, как нанимать людей. Неважно, умеет ли соискатель обходить дерево. Важно, умеет ли он доводить задачу до конца, задавать вопросы, писать письма, общаться с руководством и начальством. Графы и деревья настолько незначительны по сравнению с этими навыками, что просто смешно говорить. Поищите людей, которые обещали к пятнице и сделали к пятнице. То есть не написали код, не открыли pull request, а выкатили, сто раз проверили, и в пятницу фича в бою. Найдёте в лучшем случае пару из ста.
Фаанги — это инфантильная мечта, которой надо переболеть, вроде как сняться в порно или создать социальную сеть. Или как молодежная группа и толкинизм. В какой-то момент надо повзрослеть и взяться за что-то полезное.
Удивляюсь, что кто-то питает романтические надежды в адрес этих огромных фирм. Все они давно прошли фазы стартапов и стали машинами по заколачиванию денег. Фейсбук отвратителен до тошноты: от одного вида хочется закрыть браузер. Сотрудникам, которые пилят его каждый день, я бы доплачивал за вредность. Гугл хорош только как поисковик, у других сервисов адский интерфейс. Обе фирмы живут за счет рекламы, которую показывают на базе собранных данных. Собранных самым лживым и обманным способом, с нарушением всех соглашений и норм.
Загонять себя в FAANG — все равно что добровольно надевать кандалы. Первые несколько лет нужно рвать зад ради репутации. Затем будет трудно уйти, потому что высокая зарплата действует как наркотик.
Интересно, что все, кого я спрашивал, идут в FAANG ради денег. Так и отвечают: там много платят, x2 по рынку. Это самый пошлый и банальный ответ, и мне даже стыдно его слышать. Но почему — расскажу отдельно, потому что это уже новая мысль.
-
Meet Soothe: a small Clojure library for better Spec error messages
Note: this post is an adjusted copy of the Readme file from the GitHub repo.
Soothe provides better error messages for Clojure.spec. It’s extremely simple and robust.
- Installation
- Concepts
- TL;DR: Code Samples
- The API
- Pre-defined messages & Localization
- ClojureScript
- Best practices & Known cases
Installation
- Leiningen/Boot
[com.github.igrishaev/soothe "0.1.0"]- clojure CLI/deps.edn
com.github.igrishaev/soothe {:mvn/version "0.1.0"}Concepts
Clojure.spec is a piece of art yet misses some bits when dealing with error messages. The standard
s/explain-datagives a raw machinery output that bearly can be shown to the end-user. This library is going to fix this.The idea of Soothe is extremely simple. The library keeps its private registry of spec/pred => message pairs. The key is either a keyword referencing a spec or a fully-qualified symbol meaning a predicate. The value of this map is either a plain string or a function that takes the problem map of the raw explain spec data.
-
Не смешивать языки
Пришел к выводу из заголовка: не следует смешивать языки. Не должно быть такого, что эта часть на одном языке, а та на другой. Бек на Питоне, фронт на JS — отстой. Бек на Кложе, CLI на Golang — отстой. Сервис логики на Джаве, сервис авторизации на Расте — отстой.
Этот языковой цирк усложняет и без того сложную реальность. Раньше я думал, что протоколы и схемы решают проблемы. Не все ли равно, что на том конце провода, если данные в JSON? Оказалось, не все равно.
Даже если данные в JSON, некоторые языки не могут работать с ними так, как это делают другие. Например, Гоферы и прочие ребята со статической типизацией не могут просто распарсить JSON. Они объявляют три экрана вложенных структур и натягивают на них JSON. Малейшее расхождение, какое-то поле nil — и все упало. Опять созвон и новая задача.
Когда читал исходники проекта на Golang, который забирает JSON от Кложи, сто раз удивился, зачем добровольно садиться на кактус. Совершенно разные языки и идиомы, подход к коллекциям и обработке данных. На ровном месте впендюрили проблему: случись беда, я не смогу поправить у гоферов, а они у меня.
Два и более языков — это постоянное переключение контекста. Это свои погремушки: пакетные менеджеры, зависимости, подводные камни. Это разные идиомы. Это неполное погружение в каждую область. Это удел “фулстек-разработчика” — посредственности, который одинаково плохо знает обе среды.
Стоит ли говорить, что с одним языком проще управлять командами? Удобней перекидывать людей, наполнять общую базу знаний. Вести библиотеки с контрибом.
На стыке языков всегда будут трения. Вечно будут задачи в духе “этот словарь мы не распарсим, наши убер-классы не позволят, переделай”.
Команда не может Кложу? Научите их. Несколько дней мастер-классов. Подсадной человек, который поведет за собой начинающих. Заготовка проекта, который будут дорабатывать. Учиться не так уж сложно, если знать как обучать, и в перспективе выгодней.
Всячески сокращайте языковое многообразие.
-
Оружие
Этот пост касается сложной темы: оружия и массовых расстрелов в школах. Я специально публикую его не по следам очередной трагедии, потому что считаю подобные вещи гнусной спекуляцией. Такого рода текст лучше писать в отрыве от истерии и информационной волны.
В разное время мое отношение к оружию менялось. Если бы я писал этот пост лет пять назад, то залепил бы что-то в духе: оружие помогает защититься, вот случай А, вот случай Б, а кто не согласен, тот идиот. Именно так и протекают дискуссии на тему оружия (или сводятся к этому). К счастью, я уже отошел от подобной точки зрения.
Написать этот пост меня побудило эссе Стивена Кинга “Оружие”. Да, тот самый Кинг, который про ужасы и зомби. После очередной стрельбы он написал текст страниц на двадцать, где затронул проблемы оружия и американского общества в целом.
Эссе, что называется, зашло в массы, и теперь после каждой стрельбы на него кидают ссылку изо всех углов. Феномен дошел и до России: после недавних событий все чаты вскипели, и “Оружие” приводят по поводу и без.
Я не поленился прочитал это эссе. Прочитайте и вы: вот ссылка на хороший русский перевод. Прочитали? Давайте обсудим.
Первая часть описывает типичную и беспощадную информационную волну. Новостные источники наполняются дрожащими кадрами с бегущими людьми. Никто ничего не знает, начинаются спекуляции на тему числа убитых. Как только ясны события, высказываются политики обеих партий, используя стрельбу как повод пнуть друг друга. Несколько дней дебатов кончаются тем, что тема уходит с повестки, и все выдыхают.
Далее Кинг опровергает миф о пристрастии американцев к насилию. Приводит аргументы, что несмотря на жестокие игры и фильмы, топ-чарты занимают симуляторы, гонки и сериалы про отношения. Доказательства длятся несколько страниц, и до конца не ясно, с чем спорит Кинг. Очевидно, что американцы — такие же люди как и все: любят айфоны, гаджеты, сериалы, никакого насилия в них нет.
Ближе к середине Кинг подходит с сути проблемы: оружию и причинам, по которым оно оказалось в руках нападавшего. Он упоминает травлю и роман, что написал еще в старшей школе, где ученик творит резню. Роман называется “Ярость”, и он идет красной линией сквозь все эссе. Кинг постоянно возвращается к теме того, что добровольно изъял его из продажи, и это отвлекает от главной мысли.
Вывод, к которому склоняется Кинг, показался мне крайне скудным. Если коротко, он умещается в тезис “запретить автоматическое оружие”. Кинг долго описывает, сколько людей способен убить человек, вооруженный автоматической винтовкой, и насколько труднее сделать это пистолетом. Сравнивает числа жертв, погибших от разных видов оружия; приводит случаи, когда ученик с автоматом убил тридцать человек, а с револьвером — двух или трех.
Соглашусь, автоматическое оружие гораздо смертоносней обычного. Да, вооруженный им человек убьет больше людей. Очень странно, что столь мощное оружие можно купить для “самообороны” или коллекционирования. То, что оно должно быть запрещено в гражданском обществе, не вызывает вопросов.
И на этом месте Кинг останавливается. Дальше идет лирика, опять роман “Ярость”, сатира над американскими политиками и шоу, понятная только американцам (кое-что разъясняют сноски в русском переводе). Эссе заканчивается, и в этот моменты вы должны над ним подумать.
Но я не хочу над ним думать. Меня интересует другое.
Когда очередной подросток стреляет в школе, нам сообщают, скольких людей он убил, были у него сообщники или нет и другие стандартные вещи. Я бы хотел бы узнать тот пусть, что привел его в школу с оружием в рюкзаке. Что именно побудило его стрелять в своих.
Надо понимать, что даже без жертв стрельба — это событие из ряда вон. Такого быть не должно. Если убили двух человек из пистолета, мы не должны радоваться тому, что это был не автомат Калашникова и не тридцать жертв. Смерть даже одного человека — трагедия, и она вызывает такой же по силе стресс, что и гибель тридцати человек. Смертей должно быть ноль.
Для примера сравните Бостонский марафон, где погибло три человека, и события 11 сентября. Число погибших отличаются тремя порядками, но информационный шлейф и всплеск стресса соизмеримы. Это естественно, потому что в мирное время люди не терпят смерть своих, хоть трех человек, хоть трех тысяч.
Выражаясь айтишными терминами, стрельба в школе — это критичный баг в проде. В дрянных фирмах за это наказывают конкретного человека: админа, программиста, менеджера. Выговор и лишение премии, чтобы другим было неповадно. В правильных фирмах проводят то, что называется “постмортем”. Это когда досконально разбирают хронологию событий и их причины. При этом ставят цель не наказать человека, а организовать такой регламент, при котором ошибку допустить в принципе невозможно.
Примеры громких постмортемов вы знаете. Когда взорвался тот самый шаттл, причину расследовали годами. Привлекали лучшие умы планеты — того же Фейнмана, вторая книга которого посвящена инциденту с шаттлом. Все документы по этому делу открыты, их может прочесть каждый.
Надеюсь, вы поняли, куда я клоню. Вместо того, чтобы обсуждать вид оружия, из которого стрелял нападавший, надо выяснить, что вынудило его стрелять. Намеренное убийство своих — это очень серьезный рубеж в психике, и если он пройден, причины были столь же серьезны. Подобно случаю с шаттлом, каждую стрельбу и ее виновника нужно изучать годами. Собрать лучших экспертов, написать полки документов. И самое главное — сделать расследование достоянием общественности.
Происходит ли что-либо подобное в России? Сомневаюсь, да и насчет других стран тоже. Как только новость уходит с главной, то же происходит и с расследованием. Допускаю, что с нападавшим работают следователь и психолог, но до широкой публики результаты их трудов не доходят. А значит, все зря.
В расследовании стрельбищ кроется неприятный факт. Если изучить последние пару лет из жизни нападавшего, выяснится, что он отчаянно подавал знаки, которые общество отказалось слышать. В социальной сети были радикальные картинки, но их никто не заметил. Провайдер купил оборудование на миллион по закону Яровой; в соцсети тысяча модераторов, чтобы банить адептов Навального, а наш герой успешно миновал все это. Одноклассники не заступились в момент травли. Учитель предпочел не заметить конфликта. Участковый занят с наркоманами и алкашами. У родителей ипотека и кредиты, день и ночь на работе. Подростка никто не слышит.
Другими словами, косвенно виноваты все. Это тяжело признать, и гораздо легче цепляться за жестокие игры и интернет. В широком плане стрельба не выгодна никому: ни обывателю, ни полиции, ни политиками всех партий. Полноценное расследование займет столько сил и вскроет столько проблем, что лучше не открывать этот ящик Пандоры.
Популярные ток-шоу сводятся к популизму, крикам и оскорблениям. Сегодня в российском эфире нет тем кроме Украины, газа, и коронавируса. Любая стрельба быстро сходит на нет. Не пройдет и двух дней, как пьяный актер устроит ДТП или у чиновника найдут виллу в Альпах. Тема уйдет с новостных сайтов, и стрельбу забудут до следующего раза.
Что касается “Оружия” Кинга, то оно оставило неприятный осадок. Кинг — мастер слова, замечательный писатель, это слышно даже в переводе. Его описания точны, текст бросает читателя то в одно чувство, то в другое. Кинг — плоть от плоти американского общества и понимает его как никто другой. Но он именно художественный писатель, а не ученый или психолог, вот что нужно помнить при чтении его эссе.
Непонятно, как его главный его тезис — запретить автоматическое оружие — скажется на числе трагедий. И не только их числе, но и здоровье общества. В этом плане Кинг напоминает селебрити, которая выпускает миллионным тиражом книгу о том, как красить ногти. Эссе читают не потому, что он досконально понимает проблему, а потому что на обложке известное имя. В таком важном деле мы должны видеть разницу между красивыми словами и смыслом.
Какие выводы можно сделать?
Я считаю, частая стрельба говорит о неблагополучном фоне в обществе. Задача власти — искоренить этот фон. Это очень размытый тезис без четких контуров. Неясно, сколько времени займет этот процесс и будет ли на выходе польза. С точки зрения денег это однозначно убыток, поэтому вряд ли кто-то возьмется планомерно искоренять негативный фон.
У населения должен быть образ будущего. Сейчас этого образа нет. В прошлом веке образы происходили от конкуренции СССР и США. Эти государства производили не только продукцию, но и образы будущего. Люди намеренно ехали и бежали из США в СССР и наоборот лишь потому, что считали те социальные принципы более правильными.
Если говорить о России, то никакого образа будущего у подростков нет. Есть иностранные гаджеты и социальные сети, из которых льется сомнительный контент с рекламой. Приоритет нашей власти — геополитика, недружественный страны, газовый шантаж. По телевизору — Украина, короновирус, иностранные агенты.
В муниципальных школах в лучшем случае один психолог, а чаще всего их нет. Их должно быть по числу классов и больше. Должно быть больше занятий, когда ученики свободно общаются с учителем и задают ему вопросы через записки. Должно быть больше наставничества. Но расписание забито религией, двумя историями (отечества и мира), дети перегружены: в лучшем случае шесть уроков, а иногда и семь.
Продолжать можно долго, но я не вижу в этом смысла. Ясно одно: в масштабном плане никто не будет ничего делать. Все зависит от нас: как мы живем, на что обращаем внимание, насколько принципе мы считаем себя ответственными за происходящее.
Мне ясно: запрет какого-то вида оружия, будь то автоматическое, нарезное или с красной рукояткой, не сделает нашу жизнь лучше. Ровно как и повсеместное его разрешение. Каждый резонансный случай должен быть рассмотрен так досконально, как только это возможно. Решение придет оттуда.
-
Тетрадь
Иногда меня охватывают приступы продуктивности: я записываю задачи, ставлю помидоры и пишу в блог об эффективности.
Это временно. Потом меня отпускает, и я веду дела как все: урывисто и ситуативно.
Только одну вещь удалось сделать привычкой: вести тетрадь. Пишу в нее список дел, мелкие заметки, схемы. Одно время даже вел дневник. И должен сказать, тетрадь — великая вещь.
Переключение с гаджета на бумагу работает так же, как и прогулка во время трудной задачи. Физически чувствуешь, как включается другой отдел мозга. С бумаги воспринимаешь по-другому. Мысль, записанная рукой, дольше остается в памяти. Раньше я считал это бредом, но оказалось правдой.
С тетрадью можно отлично поработать в самолете, поезде или такси. Ей не нужна зарядка. Классно пролистать тетрадь назад: это своего рода ретроспектива.
Особо важные страницы я фотографирую, но снимки до сих не пригодились. На обложке тетради пишу телефон и просьбу вернуть в случае утраты.
В тетради можно записать список дел на месяц вперед, сделать одно и забить. А через месяц вернуться и продолжить, и дела рано или поздно будут сделаны. Прямо сейчас пролистал на двадцать страниц назад. Весь лист А4 занят списком дел в две колонки. Когда-то он казался мне адом, а сегодня в нем осталось два не зачеркнутых пункта. И таких страниц хватает.
Не так уж много нужно для того, чтобы доводить дела до конца. Но обязательно — честность с собой и окружающими.
-
Книга в ДМК-Пресс
Моя книга про Кложу выходит в издательстве ДМК-Пресс. Ожидаемая дата — середина ноября. Твердый переплет, формат B5 (165x235 мм).
Внимание: на время предзаказа цена 799 рублей (вместо 999 рублей). С промокодом
Grishaev_Clojure20она станет еще меньше. Если вы бываете в книжных магазинах, то знаете, что компьютерных книг дешевле тысячи почти не бывает. А тут такое предложение! Надо брать.
Книга почти ничем не отличается от второго издания, что вышло в Ридеро. Исправил опечатки и неточности в коде, на которые указали читатели. Особая благодарность Алексею Иванцову, который не просто нашел ошибки, но и оформил их в виде PR к репозиторию книги. Мне оставалось только нажать кнопку, чтобы их принять.
Кроме того, собрал и залил исправленные PDF на Gumroad. Если вы уже покупали там, зайдите и скачайте новые файлы. Если нет — самое время купить, цена всего пять долларов.
Для меня выход книги в ДМК-Пресс — это событие. Во-первых, издание вышло на меня само. Когда заинтересован не ты, а в тебе, это меняет дело: значит, книга действительно кому-то нужна.
Во-вторых, приятно, что ДМК-Пресс — издание с долгой историей и богатым списком выпущенных книг. Именно в ДМК девять лет назад вышло “Программирование на Clojure” — тот самый альманах на 800 страниц. Он кстати, почти не устарел, советую прочитать. Вдвойне приятно, что моя книга займет место рядом с ним.
Что это значит для читателя? Главное — книгу в твердой обложке теперь можно купить не только у меня, а на сайте ДМК или в магазине. Это главная проблема Ридеро: у них нет массовой печати в твердой обложке, только разовый (и потому дорогой) тираж. Так что теперь не обязательно слать мне Яндекс.Деньги: заказывайте на сайте ДМК. Однако я всегда рад подписать книжку и отправить в любую страну.
-
Реляционные базы данных в Clojure
Содержание
- Реляционные базы данных
Реляционные базы данных
В этой главе мы поговорим о том, как работать с реляционными базами данных в Clojure. Бóльшую часть описания займет библиотека clojure.java.jdbc и дополнения к ней. Вы узнаете, какие проблемы встречаются в этой области и как их решают в Clojure.
В бекенд-разработке базы данных занимают центральное место. Если говорить упрощенно, то любая программа сводится к обработке данных. Конечно, они поступают не только из баз, но и сети и файлов. Однако в целом за доступ к информации отвечают именно базы данных — специальные программы, сложные, но с богатыми возможностями.
Базы данных, или сокращенно БД, бывают разных видов. Они различаются в архитектуре, способе хранения информации, типом связи с клиентом. Некоторые базы работают только на клиенте, то есть в рамках одного компьютера. Другие хранят только текст и оставляют типы на усмотрение клиента. Встречаются базы, где данные хранятся в оперативной памяти и пропадают после выключения.
Мы не ставим цель охватить как можно больше баз и способов работы с ними. Наоборот, сфокусируем внимание на том, что встретит вас в реальном проекте. Скорей всего это будет классическая реляционная база данных вроде PostgreSQL или MySQL. О них мы и будем говорить.
Реляционные базы данных называют так из за модели реляционной алгебры. Это изящная математическая модель с набором операций, например выборкой, проекцией, декартовым произведением и другими. Из модели следуют строгие правила о том, как работает та или иная операция. Поэтому базы данных работают не спонтанно, а по четким алгебраическим правилам. Из этих правил следуют нормальные формы (первая, вторая и третья), доказать которые можно аналитически, а не на глаз.
Мы будем учить реляционную алгебру с самых азов. Обратитесь к статье в Википедии или книгам, где она описана без привязки к конкретной БД.
Перейдем к понятиям, более привычным программисту. Базы хранят содержимое в таблицах. Запись в таблице называется кортежем и состоит из отдельных полей. Поля могут быть разного типа. Состав полей и их порядок одинаков в рамках таблицы. Не может быть так, что в первой записи два поля, а во второй три. Если нужно указать, что в поле нет значения, в него пишут специальное пустое, чаще всего NULL.
Writing on programming, education, books and negotiations.