-
Фотографии на Маке
Моя семейная жизнь течет спокойно и счастливо, однако нет-нет да окажется на грани развода. Всему виной они – фотографии.
Когда у тебя трое детей, часто фотографируешь их по поводу и без, а потом наступает тот самый момент: дорогой, давай я выберу фотографии для фоторамок в кухне. Я оттягиваю его как могу, потому что знаю – будут крики и ругань.
Даю жене яблочный ноут. Не проходит и пяти минут, как слышу: почему файл не открывается по нажатию Enter? Почему, открыв фотографию, нельзя перейти к соседней стрелочками? Почему сочетания кнопок такие неудобные? Почему нет бегунка, чтобы превьюшки стали больше?
Ни на один упрек я не знаю ответа. В этом плане я обычная тряпка, яблочный приспособленец. Я не знаю, почему по нажатию Enter система предлагает переименовать файл, а не открыть его. Возможно, Стив Джобс был под наркотой, когда придумал это. Иначе как объяснить, что вместо Enter нужно либо дважды кликнуть по файлу, либо нажать Command+Down?
Как часто мы открываем файл, а как часто меняем его имя? Что в приоритете? Ничего, что на клавише написано Enter – по-английски “войти”, а не “переименовать”? Сколько ЛСД принял Стив в тот вечер?
То же самое с переходом между фотографиями. Когда человек открыл одно фото, он захочет посмотреть соседнее и нажмет стрелку влево или вправо. Логично же? Эпл предлагает выделить фотографии в Finder, нажать правую кнопку мыши, открыть в Preview. После этого можно просматривать несколько фотографий, – но только те, что выбрал.
Есть быстрый просмотр при помощи пробела, и внезапно в нем работают стрелочки. Однако их поведение зависит от того, в каком виде показаны файлы. Если это список, то работают клавиши вверх и вниз, а влево и вправо бездействуют. Если файлы в режиме значков, перемещение по ним работает во все стороны. Нажав вниз, вы перейдете к такой же позиции следующего ряда, пропустив столько фотографий, сколько их в ряду. Это значит, нельзя просмотерть файлы один за другим, используя одну кнопку. Нужно следить за курсором и нажимать влево, вправо и вниз – другими словами, обходить файлы змейкой.
Файлы в режиме значков не подстраиваются под ширину окна. Если в ряду их десять и вы ужали окно, матрица не перестроится. Появится горизонтальный скроллинг, и часть файлов вы не увидете.
Выбор фотографий превратился в маленький адок, который нужно пережить. Однако и я стал умнее. Зная, что супруга управляется с Виндой, я теперь делаю так. Отбираю фотки, которые ее интересуют, и помещаю в какой-то альбом. Это легко сделать на телефоне: достаточно выделить файлы и пометить тегом.
Далее открываю яблочный ноут, приложение Photos. В нем работает экспорт файлов на диск. Разумеется, можно достучаться до файлов и обычным способом, но это нелегко. Фотографии хранятся в чертовом HEIC – яблочном формате, который совмещает в себе JPEG и HDR. Это добро откроется только на яблочной машине. У файлов машинные имена-уиды, а вся мета о них лежит во внутренней базе данных.
Я думал, Эпл позволит экспортировать только штучные файлы. Но все оказалось проще: можно экспортировать целый альбом, и на диске появятся нормальные джипеги и mp4.
Осталось перетащить их на Винду. Это тоже проблематично, потому что шаринг файлов между Эплом и Виндой максимально костыльный. Есть вариант с флешкой в exFAT. Но еще лучше воткнуть флешку в роутер и поднять на нем FTP- или SMB-сервер. Все просто: на яблоке закинул, на Винде скачал.
И знаете, жить стало намного легче!
Вот так технологии спасают семейную жизнь.
-
Чат вслух
Бывает, пишешь коллеге: дружище, я вызываю такой-то сервис, посылаю мапу:
{:foo 42 :data ["some-type"] :items [:kek :lol :crap]}Сервис возвращает не то. Вот логи, вот ссылки, вот трассировочный заголовок. Все для тебя, мой милый-хороший.
В ответ человек срет сообщениями:
привет :)
надо items передать через точку с запятой :)
вроде так было в последнем коммите
или погоди его не выкатили :)
спроси девопсов выкатили или нет
и еще foo надо не 42 а 41 :)
по ходу да
или не :)
а да
мы так тестировали работало :)
на пре-проде работало помню
и без двоеточий передай
так заработает :)
Я смотрю на это и думаю: ладно, есть люди, которые думают вслух. Им легче писать и проговаривать про себя, чтобы что-то вспомнить. Бывает. С этим можно смириться.
Однако в конце этого выхлопа я ожидаю вердикт: какой запрос все-таки передать. Но этого не происходит: собеседник решил, что уже помог. Приходится идти по списку сообщений и применять каждое утверждение (“по ходу да”), а возможно, откатывать (“или не”).
Что тут сказать? Других мы не исправим, а вот себя исправить можно. Не вываливайте на собеседника поток сознания, а если это имело место, подведите итог. Достаточно смотаться к первому сообщению и коротко на него ответить.
-
Интерфейс музыкальных сервисов
Не знаю, как так вышло, но сегодня ни один — буквально ни один — музыкальный сервис не может сделать хороший интерфейс. Ни Гугл, ни Яндекс, ни кто бы то ни было. Не помогают ни миллионы денег, которые сервисы гребут за подписку, ни дизайнеры за 400 тыщщ долларов в год.
Яндекс-музыка уже давно стала мемом а-ля Medium: хорошее начинание превратилось в музей багов. Без преувеличения можно сказать, что каждый квадратный сантиметр ее дизайна несет бред. Гугл со своей Музыкой не лучше: там все прыгает, переключается, показывает выпадашки.
Прикладываю картинки. Слушаю музыку из мультика, вроде бы все в порядке. Но что-то нажал — открылось то же самое, но в другом лейауте. Почему? Без понятия. Как вернуться обратно? Тоже без понятия.
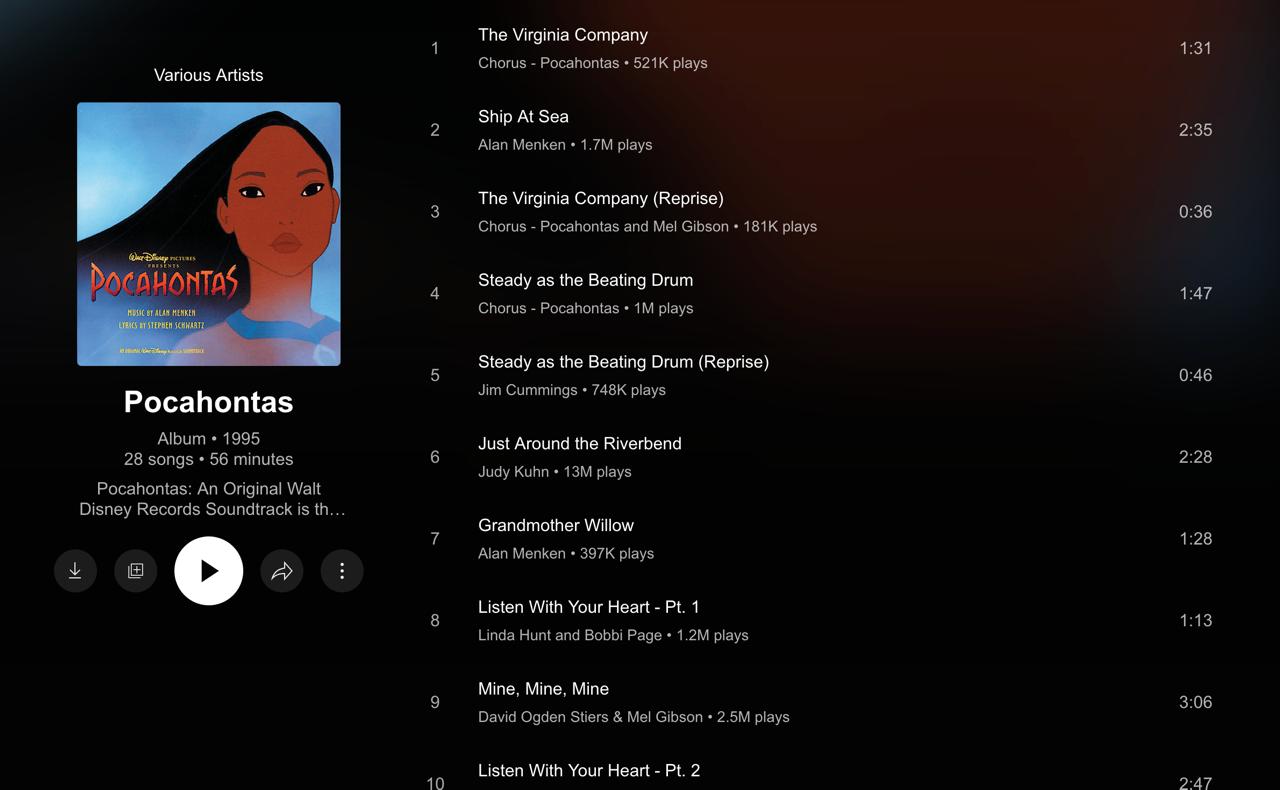
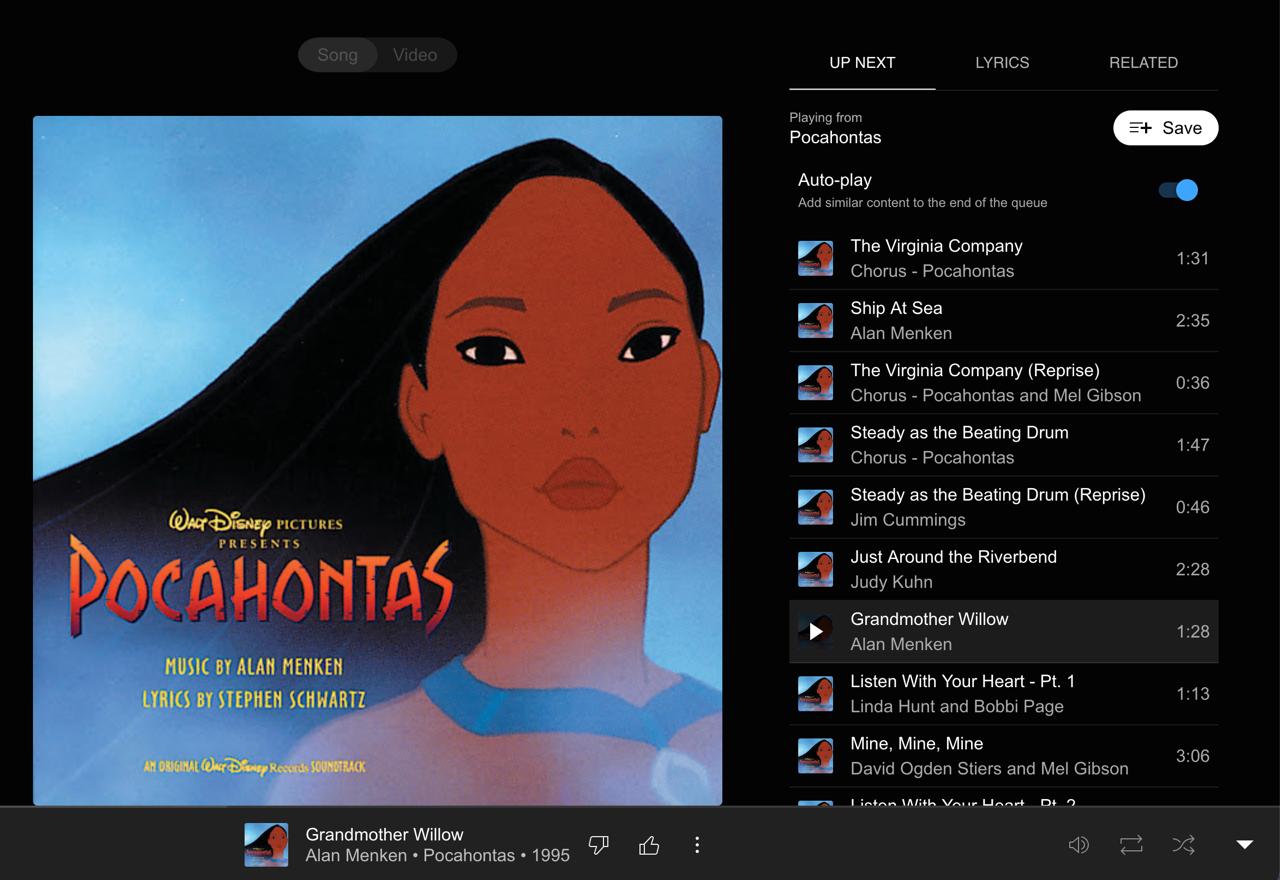
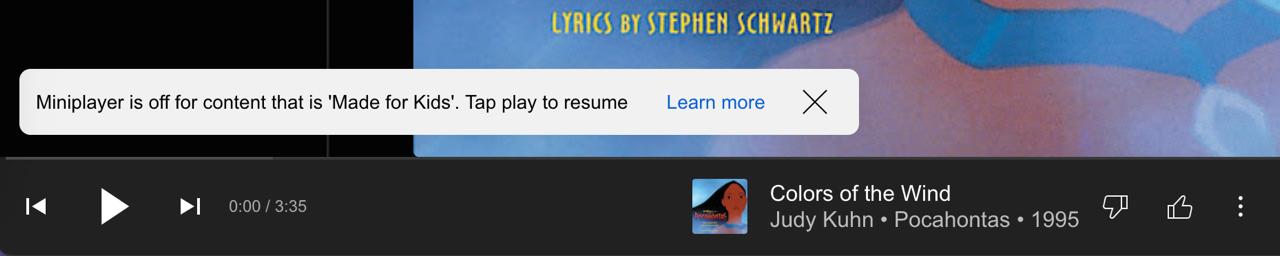
Снизу без конца вылазит нотификашка, что контент для детей не доступен в мини-плеере. Предлагает куда-то тапнуть, чтобы вернуться. О чем речь вообще?
И разумеется, сервису не хватает места. Даже на 4к-мониторе дизайнер не может все уместить. Треки приходят с сервера пачками по 20 штук, нужно проматывать страницу, чтобы они подгрузились, иначе поиск на странице не работает.
Ради интереса сравните с Винампом: на ЭЛТ-мониторе в разрешении 800x600 он занимал только часть экрана. Там было все: кнопки, перемотка, плейлист, эквалайзер. Можно было поставить рядом Total Commander, и места хватало на две программы.
Умели же люди делать плеер для монитора 800x600! А сегодня это сродни навыку писать на ассемблере.
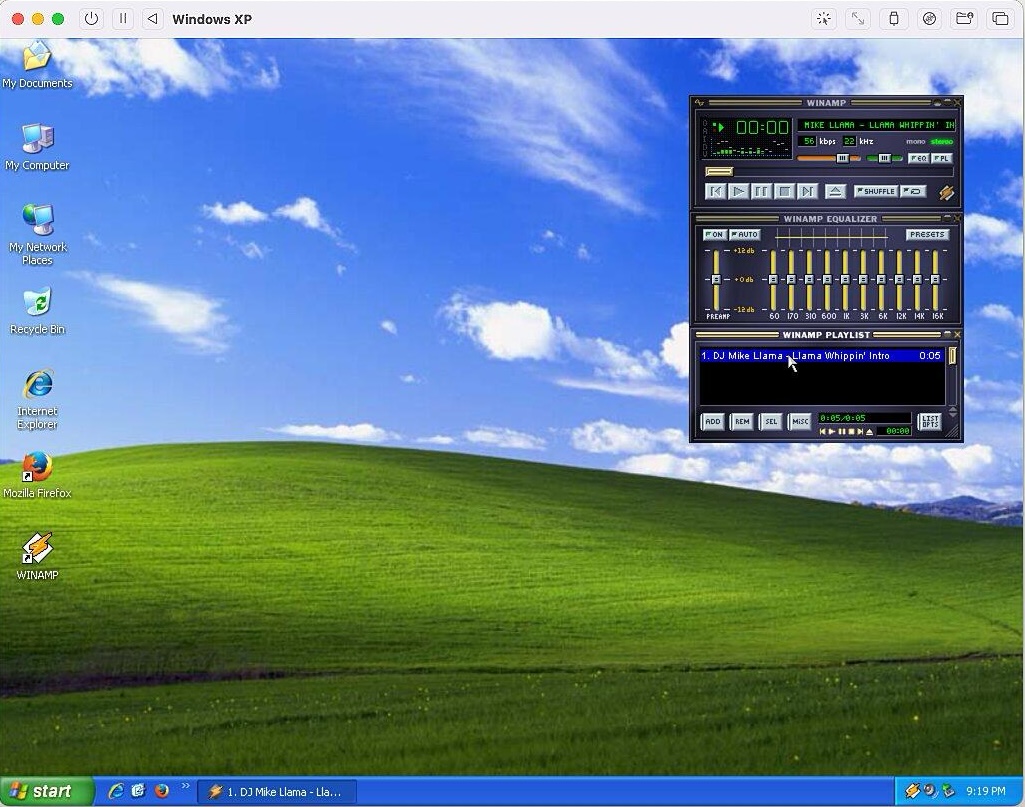
Секрет-то на самом деле простой. Я бы выдал дизайнерам ЭЛТ-мониторы и сказал: все должно помещаться на экране. За каждую выпадашку этим монитором тебя будут бить по голове. И тогда бы все наладилось — я гарантирую это (с).
-
Пробел и пауза
Как-то давно я писал об ошибке в интерфейсе Ютуба. В нем клавиша “пробел” означает не паузу, а действие по умолчанию для текущего виджета. По умолчанию текущий виджет – экран, но если кликнуть по кнопке субтитров или громкости, текущим станет другой виджет, и пробел тоже будет делать что-то другое.
Сценарии я тоже описывал: посадил ребенка смотреть мультик, объяснил, что пробел – это пауза. Но в последний момент поправил звук, и фокус остался на виджете громкости. Ребенок жмет пробел – пропадает звук. То же самое с субтитрами: усадил пожилого родственника, все объяснил и перед уходом отключил субтитры, чтобы не загораживали экран. Родственник хочет паузу, жмет пробел и в результате включает субчики.
Ту же самую херню затащил Яндекс в свою Музыку. Играет трек, мне нравится, жму сердечко. Потом хочу поставить паузу, жму пробел – трек играет, и написано “удалено из избранного”. Оказалось, сердечко – это отдельный виджет, и теперь когда фокус на нем, он добавляет и удаляет из избранного. То же самое с другими кнопками и панелями.
В общем-то, критиковать тут не за что: ребята стащили чужой подход вместе с багами. В больших компаниях это безопасная стратегия: повторяй за гигантом, и вопросов к тебе не будет. Касается не только менеджеров, но и разработчиков: фраза “как в Гугле” всегда спасет твою задницу.
И все-таки: если кто-то из читателей связан с Яндексом, будьте добры, передайте им, что у пробела должна быть строго одна функция.
-
Зависимости S3
Число для справки: сколько зависимостей нужно, чтобы сделать запрос к S3? Вот:
software/amazon/awssdk/s3/2.33.1/s3-2.33.1.pom software/amazon/awssdk/services/2.33.1/services-2.33.1.pom software/amazon/awssdk/aws-sdk-java-pom/2.33.1/aws-sdk-java-pom-2.33.1.pom software/amazon/awssdk/bom-internal/2.33.1/bom-internal-2.33.1.pom software/amazon/awssdk/aws-xml-protocol/2.33.1/aws-xml-protocol-2.33.1.pom software/amazon/awssdk/http-auth/2.33.1/http-auth-2.33.1.pom software/amazon/awssdk/http-auth-aws/2.33.1/http-auth-aws-2.33.1.pom software/amazon/awssdk/profiles/2.33.1/profiles-2.33.1.pom software/amazon/awssdk/protocol-core/2.33.1/protocol-core-2.33.1.pom software/amazon/awssdk/arns/2.33.1/arns-2.33.1.pom software/amazon/awssdk/retries-spi/2.33.1/retries-spi-2.33.1.pom software/amazon/awssdk/checksums/2.33.1/checksums-2.33.1.pom software/amazon/awssdk/checksums-spi/2.33.1/checksums-spi-2.33.1.pom software/amazon/awssdk/identity-spi/2.33.1/identity-spi-2.33.1.pom software/amazon/awssdk/http-auth-spi/2.33.1/http-auth-spi-2.33.1.pom software/amazon/awssdk/crt-core/2.33.1/crt-core-2.33.1.pom software/amazon/awssdk/protocols/2.33.1/protocols-2.33.1.pom software/amazon/awssdk/core/2.33.1/core-2.33.1.pom software/amazon/awssdk/regions/2.33.1/regions-2.33.1.pom software/amazon/awssdk/netty-nio-client/2.33.1/netty-nio-client-2.33.1.pom software/amazon/awssdk/annotations/2.33.1/annotations-2.33.1.pom software/amazon/awssdk/apache-client/2.33.1/apache-client-2.33.1.pom software/amazon/awssdk/endpoints-spi/2.33.1/endpoints-spi-2.33.1.pom software/amazon/awssdk/json-utils/2.33.1/json-utils-2.33.1.pom software/amazon/awssdk/utils/2.33.1/utils-2.33.1.pom software/amazon/awssdk/aws-core/2.33.1/aws-core-2.33.1.pom software/amazon/awssdk/auth/2.33.1/auth-2.33.1.pom software/amazon/awssdk/metrics-spi/2.33.1/metrics-spi-2.33.1.pom software/amazon/awssdk/http-client-spi/2.33.1/http-client-spi-2.33.1.pom software/amazon/awssdk/sdk-core/2.33.1/sdk-core-2.33.1.pom software/amazon/awssdk/http-clients/2.33.1/http-clients-2.33.1.pom io/netty/netty-codec/4.1.124.Final/netty-codec-4.1.124.Final.pom io/netty/netty-transport/4.1.124.Final/netty-transport-4.1.124.Final.pom io/netty/netty-codec-http/4.1.124.Final/netty-codec-http-4.1.124.Final.pom io/netty/netty-codec-http2/4.1.124.Final/netty-codec-http2-4.1.124.Final.pom io/netty/netty-buffer/4.1.124.Final/netty-buffer-4.1.124.Final.pom io/netty/netty-handler/4.1.124.Final/netty-handler-4.1.124.Final.pom io/netty/netty-common/4.1.124.Final/netty-common-4.1.124.Final.pom io/netty/netty-parent/4.1.124.Final/netty-parent-4.1.124.Final.pom software/amazon/awssdk/aws-query-protocol/2.33.1/aws-query-protocol-2.33.1.pom io/netty/netty-resolver/4.1.124.Final/netty-resolver-4.1.124.Final.pom io/netty/netty-transport-classes-epoll/4.1.124.Final/netty-transport-classes-epoll-4.1.124.Final.pom software/amazon/awssdk/third-party-jackson-core/2.33.1/third-party-jackson-core-2.33.1.pom software/amazon/awssdk/http-auth-aws-eventstream/2.33.1/http-auth-aws-eventstream-2.33.1.pom software/amazon/awssdk/retries/2.33.1/retries-2.33.1.pom software/amazon/awssdk/third-party/2.33.1/third-party-2.33.1.pom io/netty/netty-transport-native-unix-common/4.1.124.Final/netty-transport-native-unix-common-4.1.124.Final.pom io/netty/netty-codec/4.1.124.Final/netty-codec-4.1.124.Final.jar io/netty/netty-common/4.1.124.Final/netty-common-4.1.124.Final.jar io/netty/netty-transport-classes-epoll/4.1.124.Final/netty-transport-classes-epoll-4.1.124.Final.jar io/netty/netty-codec-http2/4.1.124.Final/netty-codec-http2-4.1.124.Final.jar io/netty/netty-buffer/4.1.124.Final/netty-buffer-4.1.124.Final.jar io/netty/netty-handler/4.1.124.Final/netty-handler-4.1.124.Final.jar software/amazon/awssdk/checksums-spi/2.33.1/checksums-spi-2.33.1.jar software/amazon/awssdk/profiles/2.33.1/profiles-2.33.1.jar software/amazon/awssdk/aws-xml-protocol/2.33.1/aws-xml-protocol-2.33.1.jar software/amazon/awssdk/aws-query-protocol/2.33.1/aws-query-protocol-2.33.1.jar software/amazon/awssdk/third-party-jackson-core/2.33.1/third-party-jackson-core-2.33.1.jar software/amazon/awssdk/http-auth/2.33.1/http-auth-2.33.1.jar software/amazon/awssdk/apache-client/2.33.1/apache-client-2.33.1.jar software/amazon/awssdk/retries-spi/2.33.1/retries-spi-2.33.1.jar io/netty/netty-transport/4.1.124.Final/netty-transport-4.1.124.Final.jar software/amazon/awssdk/endpoints-spi/2.33.1/endpoints-spi-2.33.1.jar io/netty/netty-transport-native-unix-common/4.1.124.Final/netty-transport-native-unix-common-4.1.124.Final.jar software/amazon/awssdk/crt-core/2.33.1/crt-core-2.33.1.jar io/netty/netty-codec-http/4.1.124.Final/netty-codec-http-4.1.124.Final.jar software/amazon/awssdk/http-auth-aws-eventstream/2.33.1/http-auth-aws-eventstream-2.33.1.jar software/amazon/awssdk/auth/2.33.1/auth-2.33.1.jar software/amazon/awssdk/http-client-spi/2.33.1/http-client-spi-2.33.1.jar io/netty/netty-resolver/4.1.124.Final/netty-resolver-4.1.124.Final.jar software/amazon/awssdk/metrics-spi/2.33.1/metrics-spi-2.33.1.jar software/amazon/awssdk/arns/2.33.1/arns-2.33.1.jar software/amazon/awssdk/json-utils/2.33.1/json-utils-2.33.1.jar software/amazon/awssdk/identity-spi/2.33.1/identity-spi-2.33.1.jar software/amazon/awssdk/regions/2.33.1/regions-2.33.1.jar software/amazon/awssdk/aws-core/2.33.1/aws-core-2.33.1.jar software/amazon/awssdk/sdk-core/2.33.1/sdk-core-2.33.1.jar software/amazon/awssdk/protocol-core/2.33.1/protocol-core-2.33.1.jar software/amazon/awssdk/checksums/2.33.1/checksums-2.33.1.jar software/amazon/awssdk/http-auth-aws/2.33.1/http-auth-aws-2.33.1.jar software/amazon/awssdk/retries/2.33.1/retries-2.33.1.jar software/amazon/awssdk/http-auth-spi/2.33.1/http-auth-spi-2.33.1.jar software/amazon/awssdk/netty-nio-client/2.33.1/netty-nio-client-2.33.1.jar software/amazon/awssdk/annotations/2.33.1/annotations-2.33.1.jar software/amazon/awssdk/s3/2.33.1/s3-2.33.1.jar software/amazon/awssdk/utils/2.33.1/utils-2.33.1.jar -
New library: PG.bin
PG.bin is a library to parse Postgres COPY dumps made in binary format.
Postgres has a great API to transfer data into and out from a database called COPY. What is special about it is that it supports three different formats: CSV, text and binary. Both CSV and text are trivial: values are passed using their text representation. Only quoting rules and separating characters differ.
Binary format is special in that direction that values are not text. They’re passed exactly how they’re stored in Postgres. Thus, binary format is more compact: it’s 30% less in size than CSV or text. The same applies to performance: COPY-ing a binary data back and forth takes about 15-25% less time.
To parse a binary dump, one must know its structure. This is what the library does: it knows how to parse such dumps. It supports most of the built-in Postgres types including JSON(b). The API is simple an extensible.
Installation
Add this to your project:
;; lein [com.github.igrishaev/pg-bin "0.1.0"] ;; deps com.github.igrishaev/pg-bin {:mvn/version "0.1.0"}Usage
Let’s prepare a binary dump as follows:
create temp table test( f_01 int2, f_02 int4, f_03 int8, f_04 boolean, f_05 float4, f_06 float8, f_07 text, f_08 varchar(12), f_09 time, f_10 timetz, f_11 date, f_12 timestamp, f_13 timestamptz, f_14 bytea, f_15 json, f_16 jsonb, f_17 uuid, f_18 numeric(12,3), f_19 text null, f_20 decimal ); insert into test values ( 1, 2, 3, true, 123.456, 654.321, 'hello', 'world', '10:42:35', '10:42:35+0030', '2025-11-30', '2025-11-30 10:42:35', '2025-11-30 10:42:35.123567+0030', '\xDEADBEEF', '{"foo": [1, 2, 3, {"kek": [true, false, null]}]}', '{"foo": [1, 2, 3, {"kek": [true, false, null]}]}', '4bda6037-1c37-4051-9898-13b82f1bd712', '123456.123456', null, '123999.999100500' ); \copy test to '/Users/ivan/dump.bin' with (format binary);Let’s peek what’s inside:
xxd -d /Users/ivan/dump.bin 00000000: 5047 434f 5059 0aff 0d0a 0000 0000 0000 PGCOPY.......... 00000016: 0000 0000 1400 0000 0200 0100 0000 0400 ................ 00000032: 0000 0200 0000 0800 0000 0000 0000 0300 ................ 00000048: 0000 0101 0000 0004 42f6 e979 0000 0008 ........B..y.... 00000064: 4084 7291 6872 b021 0000 0005 6865 6c6c @.r.hr.!....hell 00000080: 6f00 0000 0577 6f72 6c64 0000 0008 0000 o....world...... 00000096: 0008 fa0e 9cc0 0000 000c 0000 0008 fa0e ................ 00000112: 9cc0 ffff f8f8 0000 0004 0000 24f9 0000 ............$... 00000128: 0008 0002 e7cc 4a0a fcc0 0000 0008 0002 ......J......... 00000144: e7cb dec3 0d6f 0000 0004 dead beef 0000 .....o.......... 00000160: 0030 7b22 666f 6f22 3a20 5b31 2c20 322c .0{"foo": [1, 2, 00000176: 2033 2c20 7b22 6b65 6b22 3a20 5b74 7275 3, {"kek": [tru 00000192: 652c 2066 616c 7365 2c20 6e75 6c6c 5d7d e, false, null]} 00000208: 5d7d 0000 0031 017b 2266 6f6f 223a 205b ]}...1.{"foo": [ 00000224: 312c 2032 2c20 332c 207b 226b 656b 223a 1, 2, 3, {"kek": 00000240: 205b 7472 7565 2c20 6661 6c73 652c 206e [true, false, n 00000256: 756c 6c5d 7d5d 7d00 0000 104b da60 371c ull]}]}....K.`7. 00000272: 3740 5198 9813 b82f 1bd7 1200 0000 0e00 7@Q..../........ 00000288: 0300 0100 0000 0300 0c0d 8004 ceff ffff ................ 00000304: ff00 0000 1000 0400 0100 0000 0900 0c0f ................ 00000320: 9f27 0700 32ff ff .'..2..Now the library comes into play:
(ns some.ns (:require [clojure.java.io :as io] [pg-bin.core :as copy] taggie.core)) (def FIELDS [:int2 :int4 :int8 :boolean :float4 :float8 :text :varchar :time :timetz :date :timestamp :timestamptz :bytea :json :jsonb :uuid :numeric :text :decimal]) (copy/parse "/Users/ivan/dump.bin" FIELDS) [[1 2 3 true (float 123.456) 654.321 "hello" "world" #LocalTime "10:42:35" #OffsetTime "10:42:35+00:30" #LocalDate "2025-11-30" #LocalDateTime "2025-11-30T10:42:35" #OffsetDateTime "2025-11-30T10:12:35.123567Z" (=bytes [-34, -83, -66, -17]) "{\"foo\": [1, 2, 3, {\"kek\": [true, false, null]}]}" "{\"foo\": [1, 2, 3, {\"kek\": [true, false, null]}]}" #uuid "4bda6037-1c37-4051-9898-13b82f1bd712" 123456.123M nil 123999.999100500M]]Here and below: I use Taggie to render complex values like date & time, byte arrays and so on. Really useful!
This is what is going on here: we parse a source pointing to a dump using the
parsefunction. A source might be a file, a byte array, an input stream and so on – anything that can be coerced to an input stream using theclojure.java.io/input-streamfunction.Binary files produced by Postgres don’t know their structure. Unfortunately, there is no information about types, only data. One should help the library traverse a binary dump by specifying a vector of types. The
FIELDSvariable declares the structure of the file. See below what types are supported.API
There are two functions to parse, namely:
-
pg-bin.core/parseaccepts any source and returns a vector of parsed lines. This function is eager meaning it consumes the whole source and accumulates lines in a vector. -
pg-bin.core/parse-seqaccepts anInputStreamand returns a lazy sequence of parsed lines. It must be called under thewith-openmacro as follows:
(with-open [in (io/input-stream "/Users/ivan/dump.bin")] (let [lines (copy/parse-seq in FIELDS)] (doseq [line lines] ...)))Both functions accept a list of fields as the second argument.
Skipping fields
When parsing, it’s likely that you don’t need all fields to be parsed. You may keep only the leading ones:
(copy/parse DUMP_PATH [:int2 :int4 :int8]) [[1 2 3]]To skip fields located in the middle, use either
:skipor an underscore:(copy/parse DUMP_PATH [:int2 :skip :_ :boolean]) [[1 true]]Raw fields
If, for any reason, you have a type in your dump that the library is not aware about, or you’d like to examine its binary representation, specify
:rawor:bytes. Each value will be a byte array then. It’s up to you how to deal with those bytes:(copy/parse DUMP_PATH [:raw :raw :bytes]) [[#bytes [0, 1] #bytes [0, 0, 0, 2] #bytes [0, 0, 0, 0, 0, 0, 0, 3]]]Handling JSON
Postgres is well-known for its vast JSON capabilities, and sometimes tables that we dump have json(b) columns. Above, you saw that by default, they’re parsed as plain strings. This is because there is no a built-in JSON parser in Java and I don’t want to tie this library to a certain JSON implementation.
But the library provides a number of macros to extend undelrying multi-methods. With a line of code, you can enable parsing json(b) types with Chesire, Jsonista, Clojure.data.json, Charred, and JSam. This is how to do it:
(ns some.ns (:require [pg-bin.core :as copy] [pg-bin.json :as json])) (json/set-cheshire keyword) ;; overrides multimethods (copy/parse DUMP_PATH FIELDS) [[... {:foo [1 2 3 {:kek [true false nil]}]} {:foo [1 2 3 {:kek [true false nil]}]} ...]]The
set-cheshiremacro extends multimethods assuming you have Cheshire installed. Now theparsefunction, when facing json(b) types, will decode them properly.The
pg-bin.jsonnamespace provides the following macros:set-string: parse json(b) types as strings again;set-cheshire: parse using Cheshire;set-data-json: parse using clojure.data.json;set-jsonista: parse using Jsonista;set-charred: parse using Charred;set-jsam: parse using JSam.
All of them accept optional parameters that are passed into the underlying parsing function.
PG.Bin doesn’t introduce any JSON-related dependencies. Each macro assumes you have added a required library into the classpath.
Metadata
Each parsed line tracks its length in bytes, offset from the beginning of a file (or a stream) and a unique index:
(-> (copy/parse DUMP_PATH FIELDS) first meta) #:pg{:length 306, :index 0, :offset 19}Knowing these values might help reading a dump by chunks.
Supported types
:raw :bytea :bytesfor raw access andbytea:skip :_ nilto skip a certain field:uuidto parse UUIDs:int2 :short :smallint :smallserial2-byte integer (short):int4 :int :integer :oid :serial4-byte integer (integer):int8 :bigint :long :bigserial8-byte integer (long):numeric :decimalnumeric type (becomesBigDecimal):float4 :float :real4-byte float (float):float8 :double :double-precision8-byte float (double):boolean :boolboolean:text :varchar :enum :name :stringtext values:datebecomesjava.time.LocalDate:time :time-without-time-zonebecomesjava.time.LocalTime:timetz :time-with-time-zonebecomesjava.time.OffsetTime:timestamp :timestamp-without-time-zonebecomesjava.time.LocalDateTime:timestamptz :timestamp-with-time-zonebecomesjava.time.OffsetDateTime
Ping me for more types, if needed.
On Writing
At the moment, the library only parses binary dumps. Writing them is possible yet requires extra work. Ping me if you really need writing binary files.
Scenarios
Why using this library ever? Imagine you have to fetch a mas-s-s-ive chunk of rows from a database, say 2-3 million to build a report. That might be an issue: you don’t want to saturate memory, neither you want to paginate using LIMIT/OFFSET as it’s slow. A simple solution would be to dump the data you need into a file and process it. You won’t keep the database constantly busy as you’re working with a dump! Here is a small demo:
(ns some.ns (:require [pg-bin.core :as copy] [pg-bin.json :as json])) (defn make-copy-manager " Build an instance of CopyManager from a connection. " ^CopyManager [^Connection conn] (new CopyManager (.unwrap conn BaseConnection))) (let [conn (jdbc/get-connection data-source) mgr (make-copy-manager conn) sql "copy table_name(col1, col2...) to stdout with (format binary)" ;; you can use a query without parameters as well sql "copy (select... from... where...) to stdout with (format binary)" ] (with-open [out (io/output-stream "/path/to/dump.bin")] (.copyOut mgr sql out))) (with-open [in (io/input-stream "/path/to/dump.bin")] (let [lines (copy/parse-seq in [:int2 :text ...])] (doseq [line lines] ...)))Above, we dump the data into a file and then process it. There is a way to process lines on the fly using another thread. The second demo:
(let [conn (jdbc/get-connection data-source) mgr (make-copy-manager conn) sql "copy table_name(col1, col2...) to stdout with (format binary)" in (new PipedInputStream) started? (promise) fut ;; a future to process the output (future (with-open [_ in] ;; must close it afterward (deliver started? true) ;; must report we have started (let [lines (copy/parse-seq in [:int2 :text ...])] (doseq [line lines] ;; process on the fly ;; without touching the disk ...))))] ;; ensure the future has started @started? ;; drain down to the piped output stream (with-open [out (new PipedOutputStream in)] (.copyOut mgr sql out)) @fut ;; wait for the future to complete ) -
-
Место работы
Я, кстати, придумал вот что: прошелся по всем профилям и убрал текущее место работы. Оставил только vast fintech с описанием технологий — и довольно.
Почему? Считаю, рекрутерам не нужно знать, где я работаю. Прошлые места смотрите ради бога, а текущее вас не касается. Буду искать работу — созвонимся, и я все расскажу. А пока держите от меня фигу с маслом.
Есть и моральный аспект. Когда ведешь бложик, работа часто подкидывает темы — в том числе основанные на противоречии, когда не согласен и хочешь выговориться. Чтобы не бросать на кого-то тень, считаю правильным не раскрывать, где работаешь.
Когда-то я волновался о том, как выгляжу на Линкед-ине. Но когда в пятый раз находишь работу по знакомству, это становится неважно.
В целом я считаю излишним, когда о тебе знает каждый угол интернета. Еще давно я удалился из всех соцсетей и ни разу не пожалел. Оставил только Гитхаб и Линкед-ин: этих двух хватает, чтобы найти работу где угодно — однако им необязательно знать все.
-
Евреи в СССР
Я не застал толком советский союз, но запомнил некоторые его рудименты. Один из них заключался в том, чтобы, увидев еврейскую фамилию, обязательно это подчеркнуть.
Например, идут титры, и написано: композитор А. Шпильман. Взрослые такие с легкой улыбкой – еврей! Как будто раскрыли агента, который тщательно скрывался.
Я, маленький, долго не понимал, что это за еврей такой и почему он появляется во всех титрах. Я думал, это конкретный человек и удивлялся его продуктивности.
Помню как прочел фантастический рассказ “Песок” о космонавтах, которые потерпели бедствие на планете-пустыне. Одного из них звали Шапиро. Когда я пересказывал рассказ пожилому родственнику, это звучало так: Шапиро сказал своему другу (“Шапиро? Это еврейская фамилия!”), что они падают, потом Шапиро вышел из корабля (“Шапиро – это еврей!”) и увидел пустыню, затем Шапиро пошел (“Тот самый еврей?”)…
Короче, то, что Шапиро – еврей, я услышал раз десять, но так и не понял, что это значит. По сюжету он был нормальным чуваком, так что я не нашел связи между тегом и поведением. И вообще, в эпоху межпланетных путешествий мало кого волновало, кем он был: русским, мексиканцем, французом.
Еще одна кулстори на тему евреев случилась в школе. Урок истории, тема – приход к власти фашистов и преследование евреев. Историк – маленький неженатый мужчина, который делал сомнительные комплименты девочкам и просил их фотографии. И вот он объясняет, за что преследовали евреев: вы понимаете, у них нет своей страны, они везде образуют диаспоры, строят заговоры И ВООБЩЕ — они же Иисуса распяли!
Как вы думаете, что́ мы, дети, запомнили из этой тирады?
Следующий урок замещает другая учительница, спрашивает – за что преследовали евреев? Весь класс хором – потому что они Иисуса распяли! У учительницы глаза из орбит, она тихим голосом спрашивает: кто вам это сказал? Отвечаем — Константин Батькович. Она: понятно, я с ним поговорю.
А потом прошли годы, и гнилая привычка выявлять евреев как-то выветрилась. Сегодня это считается моветоном, и очень хорошо. На этом примере мы видим, что еще 30 лет назад люди не знали кое-что из элементарной этики. Поэтому брать пример с прошлого поколения нужно очень осмотрительно.
-
Настройка uBlock Origin
Заметка самому себе как настроить uBlock Origin.
-
На закладке Filters отметить все галочки кроме “Block Outsider Intrusion into LAN”. С ней отваливаются картинки на Ютубе и в других музыкальных сервисах. Почему – пока не разобрался.
-
Во вкладке My filters добавить такую строку:
||accounts.google.com/gsi/*$xhr,script,3pОна отключает выпадашку с авторизацией Гугла. Эта выпадашка – вселенское зло: закрывается буквально на день и завтра вылезает снова. Ее добавили на все сайты семейства StackExchange. Неважно чем ты интересуешься – базой данных, редактором, версткой – она липнет как навязчивая муха.
Поражает, сколько фильтров нужно ставить, чтобы просто смотреть интернет. Пользуясь случаем, шлю Гуглу лучи добра за то, что запретили uBlock в последнем Хроме. Я так понимаю, кроме форков Файерфокса вариантов нет?
Еще одна мысль: обидно, когда в консоли написано “Blocked by uBlock”, но нет информации о том, какой фильтр сработал. Имя фильтра и номер строки были бы спасением. Эти данные по-любому есть в контексте и нужно только добавить их в сообщение. Или я плохо смотрел?
На закладке Settings включить “Block media elements larger than” и задать свой размер. Полезно, чтобы отключать большие обложки к статьям. Все равно они сгенерены нейронкой.
Там же: опция “Block remote fonts”. Полезно для сайтов, чьи дизайнеры любят поиграть со шрифтами.
-
-
Метод Сократа
В комментариях упомянули диалог методом Сократа. Вспомнил, что хотел написать на эту тему.
Что такое метод Сократа? Это когда собеседник не возражает напрямую, а задает серию вопросов, чтобы направить другого к истине. “Истина”, “направить” – как благородно звучит!
К счастью, сегодня есть точное и емкое слово, чтобы описать метод Сократа — это троллинг. В античные времена такого слова не было — как, к примеру, не было термина “пассивная агрессия”. Но явление было, а Сократ стал его мастером.
Тролль — это человек, который не вступает в конфликт прямо, а старается поссорить других. Либо, если собеседник один, строит разговор так, чтобы собеседник противоречил сам себе. В результате тролль разводит руками: дружище, ты противоречишь, сначала разберись, потом поговорим. И с видом победителя уходит в закат.
Схема работает по простой причине. На вопросы можно ответить без ошибок только если готовился к ним. Когда отвечаешь вживую, так или иначе будет нескладно. Не на пятой, так на десятой итерации ты скажешь то, что противоречит чему-то сказанному ранее. Это абсолютно точно и неоспоримо, буквально аксиома: чем больше говоришь, тем больше нестыковок можно найти.
Примерно как в любом фильме можно найти ляпы, когда кружка стоит слева, а в следующем кадре — справа. Или детектив только что прикурил, а через пять секунд тушит окурок. И находятся же говноеды, которые разбирают фильм на кадры и смотрят, что где стояло и на сколько сантиметров сдвинулось! Однако на успех фильма это никак не влияет.
Я давно научился узнавать троллей, косящих под Сократа. Высказал какую-то мысль, и подобно мухе к тебе пристал человек. Задает наводящие вопросы: что ты имел в виду, а что ты скажешь на то, на се… Как будто не очевидно: тролль собирает базу высказываний, чтобы сказать: ага, сначала ты заявил X, а потом Y! Ты противоречишь, иди разберись.
Поэтому если от человека следует поток вопросов, я быстро его прерываю. Либо проходи мимо, либо пиши у себя опровержение. Я даже дам ссылку, мне не жалко.
Про Стива Джобса была замечательная цитата. В Стиве было две половины: засранца и гения. Из-за гения ему прощали засранца. Сегодня многие подражают Джобсу, но пока что у них выходит засранец, а не гений.
То же самое применимо к Сократу. Он был гением и абсолютным троллем. Но подражая Сократу, пожалуйста, держите курс на гения. Троллей и без вас хватает.
Writing on programming, education, books and negotiations.