-
Что почитать №16
Думали, что я забыл?
-
Егор о разработке через тестирование.
-
Эль Мюрид о праве на оружие.
-
Твоя машина – твоя ответственность
Прекрасный пост Варламова на тему автомобилей.
-
Матерый хаскелист занялся Гоу.
Other than that, I will probably never choose to use Go for anything ever again, unless I’m being paid for it.
-
-
Кавычки
Некоторые языки программирования допускают два вида кавычек для оформления строк: одинарные и двойные. Это особенно удобно, когда в строке уже содержатся кавычки. Чтобы избежать экранирования обратным слешем, достаточно инвертировать крайние кавычки.
Например:
message1 = "Object 'foo' does not exist." message2 = 'Object "foo" does not exist.'гораздо удобней, чем
message3 = "Object \"foo\" does not exist."Возникает холивар, какие кавычки использовать по умолчанию?
Правильный ответ – двойные.
Объяснение этому простое: если двойные кавычки работают почти во всех языках, то одинарные – только в некоторых. Согласно Сишному синтаксису, одинарными кавычками обозначается символ (Char), а не строка. Навскидку назову Си, Плюсы, Джаву, Кложу.
Это не такие заурядные языки, чтобы их игнорировать. При копировании строк, например, XPath- или CSS-селекторов, начинается ад с исправлением кавычек. Выражение
'.//div[@id="foo"]'без проблем сработает в Джаваскрипте и Питоне, но не в Джаве или Кложе. Поэтому правильней записать его так:
".//div[@id='foo']"Логично же предположить, что твои селекторы или разметку могут задействовать в другом языке. Поэтому делайте сразу правильно.
Запомните – двойные.
-
Красавица и Чудовище
Сходил на сабж (без детей). Буду краток.
Плюсы:
-
Классическая добрая история со счастливым концом.
-
Качество эффектов запредельное.
-
Невероятно проработаны второстепенные персонажи, например, Подсвечник и Чайник. Они не просто живые и двигаются – в них столько характера и эмоций, что просто не передать. Да, Дисней знает как одушевлять неживое.
Минусы:
-
Очень много поют. Это не фильм, а мюзикл, паузы между песнями порой меньше пяти минут. Песня – это отсутствие действия, поэтому приходится ждать, пока споют и спляшут, и начнется уже что-то интересное.
-
Сцены между песнями скомканы и переданы кое-как. Диалоги порой нелепы, из фраз делают совсем не те выводы.
-
Сами песни по манере исполнения напоминают цыганские романсы: сначала медленно, быстрей, быстрей, БЫСТРО, ГРОМКО, АААААААА!!! Заканчивается все оргией с костюмами, блеском, буйством красок и грохотом труб. В какой-то момент казалось, что меня порвет как тряпку. Из зала вышел контуженный.
-
Если выбросить песни, сюжет получается чрезмерно линейный и банальный. Главные персонажи шаблонны. Считаю, можно было добавить больше неоднозначности в характеры и сюжет.
Нейтральное:
-
Гомосятина есть, но исключительно в виде шуток или намеков. Физического контакта между мужиками тоже нет. Ребенок до подросткового возраста вообще ничего не поймет.
-
Толерастия зашкаливает: каждый второй персонаж негр. Это во Франции-то 17 века?! Да еще при королевском дворе?
-
Любителей ЛГБТ и толерастов опять нае… обманули: персонаж-гей – клоун, трус и вообще не влияет на сюжет. Негры играют слуг. Все ключевые герои по-прежнему белые и гетеросексуальные.
-
В
ГермионеЭмме Уотсон ничего особого нет, но, видимо, роль банальная.
Вывыды:
-
годное семейное кино,
-
детей не берите. Но не из-за гомосятины, а слишком агрессивных песен.
-
-
Что почитать №15
Вот:
-
Эль Мюрид – о проблемах информационного общества.
-
Why I Don’t Talk to Google Recruiters
Проблемы найма, грамотно выраженные Егором.
-
Практика хорошего интервью.
-
-
Спать
Чтобы чувствовать себя хорошо и быть продуктивным, нужно высыпаться. Проводить во сне 8 часов, как советуют врачи. Ложиться рано, между 10 и 11 вечера. Вставать тоже рано, часов в 7. Избегать компьютера и мобильного перед сном.
Тогда все будет хорошо.
Особенно круто, когда есть возможность вздремнуть полчасика после обеда. Восстанавливает силы на весь оставшийся день.
Правила простые, но следовать им трудно. Иные разрабатывают целую ментальную систему и пытаются учить ей других. Правда в том, что нужно пересилить себя и начать жить правильно. Другого способа я не знаю.
Варианты с коротким сном и судорожными попытками привестия себя утром в порядок не работают. Вы обманываете себя и окружающих. Даже если очухались с помощью кофе и сигарет утром, вечером будете никакой. Ну или хватит вас на день-два, а потом режим тряпки.
Хроническое недосыпание имеет очень неприятный эффект – становишься раздражительным. Начинает бесить все: не проходят тесты, тупит редактор, очередь на кассе, сын разлил воду. Это накапливается постепенно, поэтому не замечаешь, что проблема в тебе. Кажется, что все плохо, а ты один Д’Артаньян.
В такой период нетрудно испортить отношения с родными и коллегами. Кому интересно, что ты не спал? И кто тебя принуждал?
Особенно умиляет, когда начинают пересказывать мифы о Леонардо Да Винчи или Юлии Цезаре о том, что они спали по полчаса. Во-первых, вы ни тот, ни другой. Может, один из тысячи действительно может спать так мало, но вряд ли это ваш случай.
Во-вторых, нигде не написано, что оба спали так мало всю жизнь. Допускаю, что Цезарь не спал в походах, а Да Винчи – в моменты творчества. В 20 лет я сам мог не спать сутки. Но рано или поздно организм потребует свое.
Контроль сна требует воли. Статьи с Лайфхакера не помогут.
-
Что почитать №14
Сегодня в номере:
-
Согласен, класс с пятью миксинами напоминает мне Abomination из Варкрафта. Сшитое из кусков мертых тел нечто. Ходит и разговаривает так же.
-
Плющат резиновых людей, у них мученические гримасы.
-
Не мог не поделиться, очень хорошо написано.
-
-
Алгоритмы
В интернете новый мем: оказывается, алгоритмы не нужны. Все началось с того, что некий DHH, создатель Рельс, выступил с каминг-аутом:
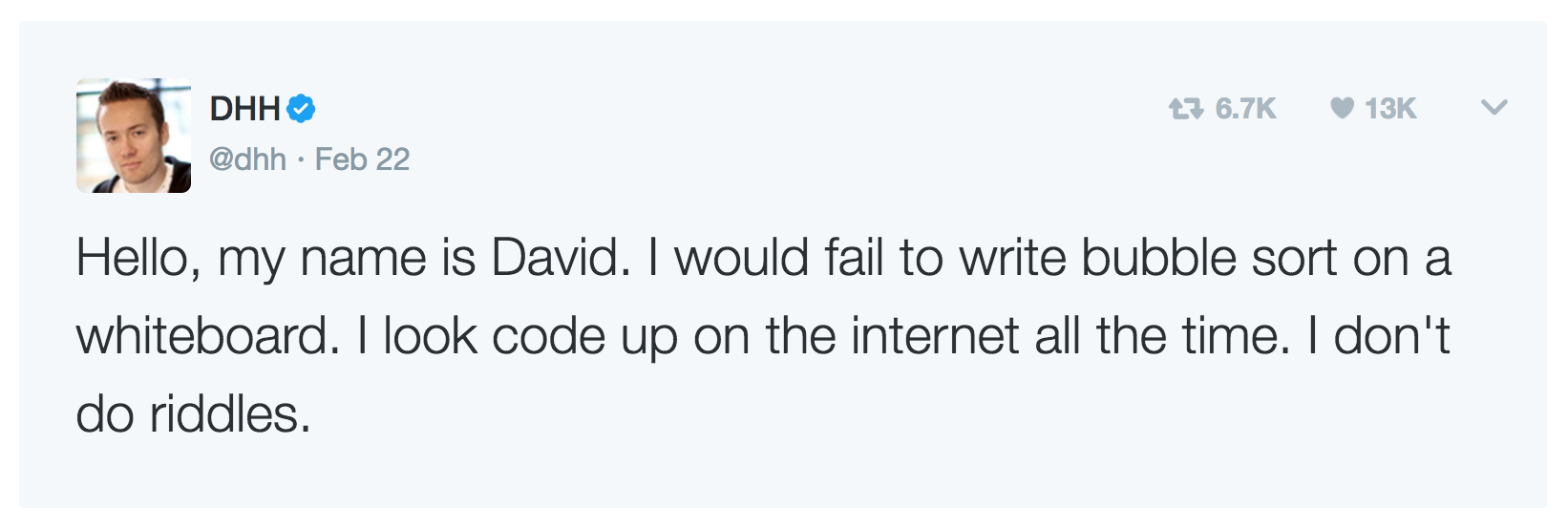
Я
убежденный гейне знаю сортировку пузырьком и не боюсь об этом заявлять. Эстафету подхватил всякий сброд. Каждый считает долгом похвастаться тем, что не знает нужный класс, метод или синтаксис: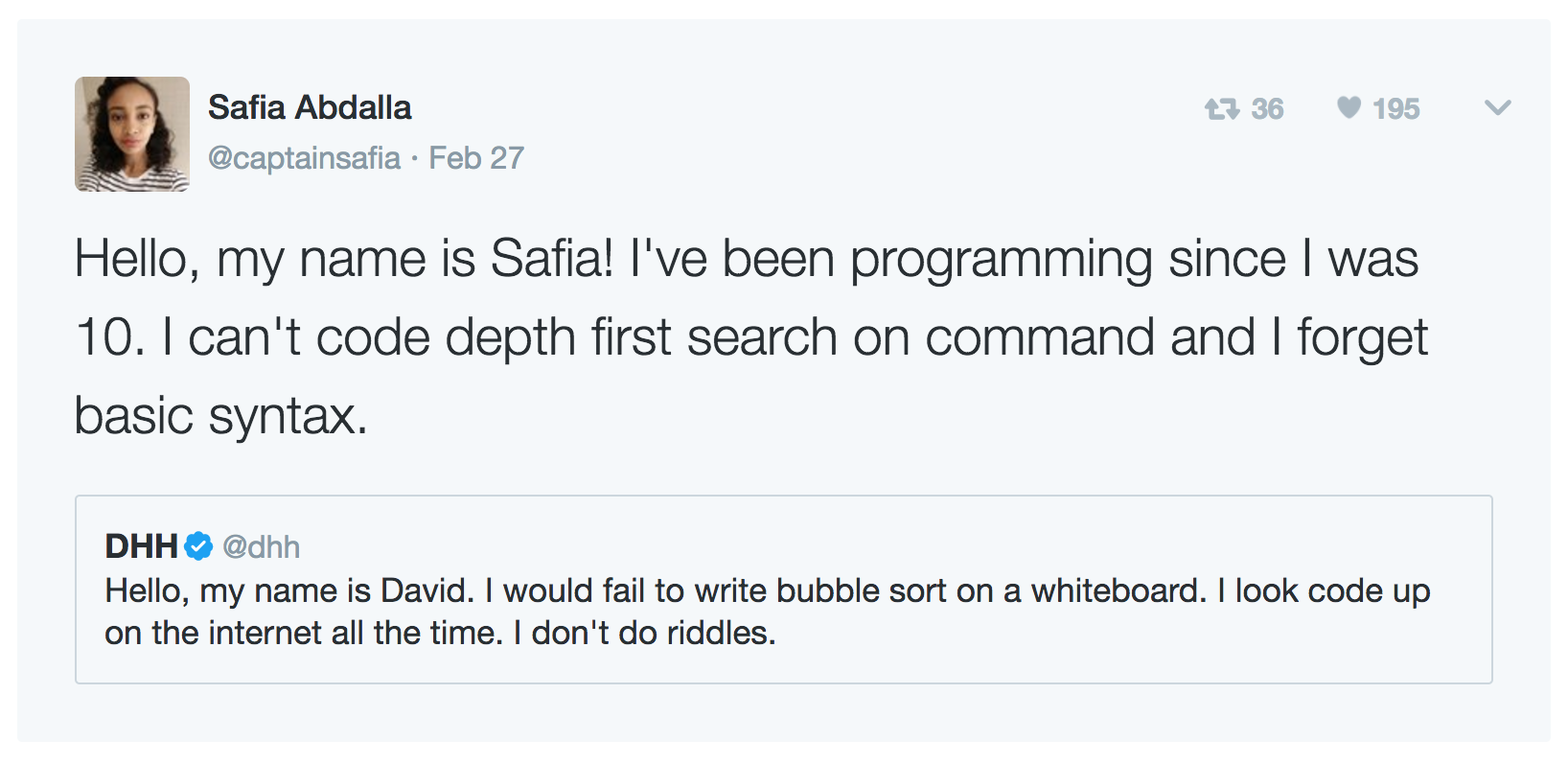
Попадаются лиды из Гугла:
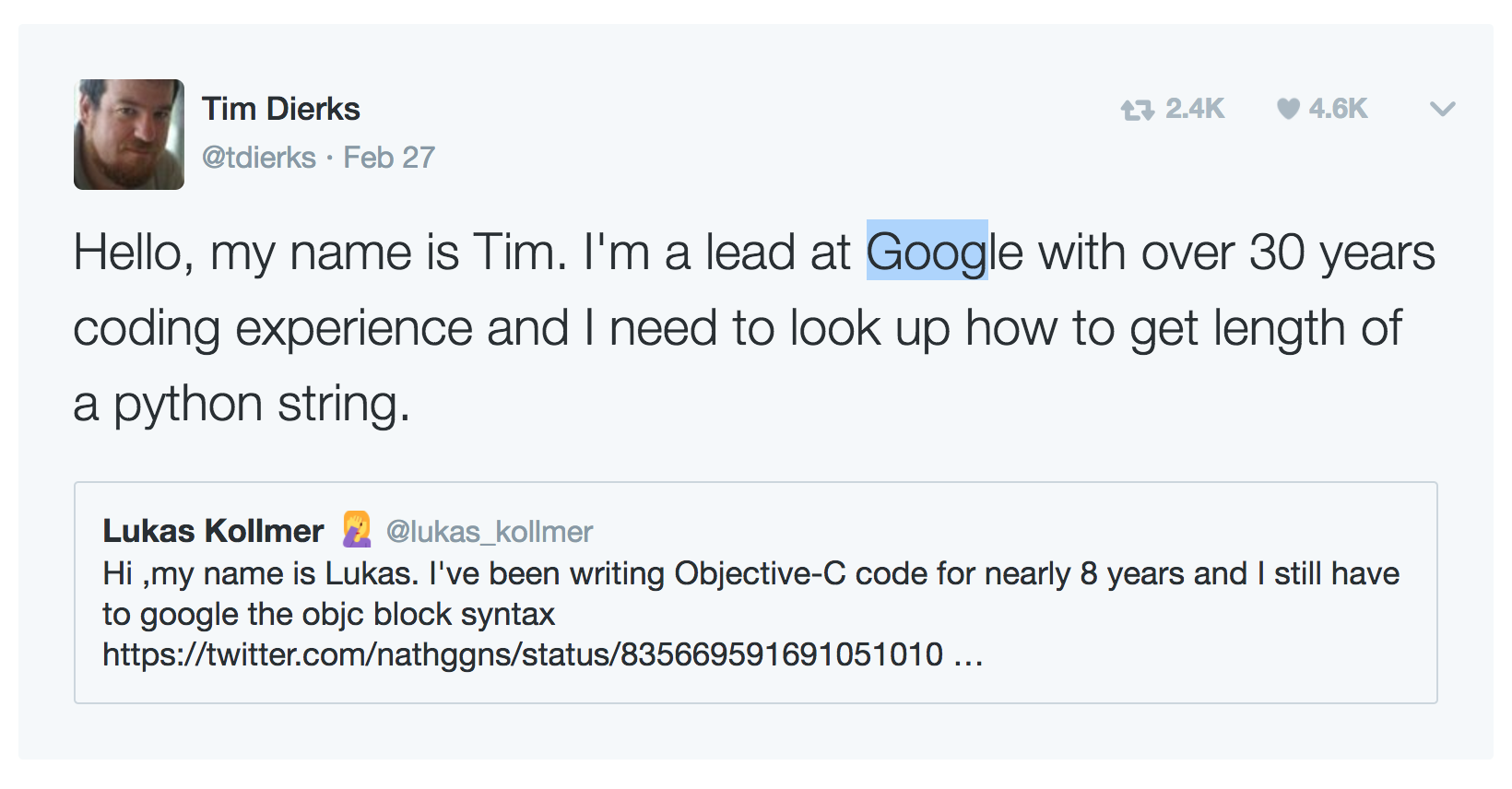
Полная подборка перлов по ссылке.
На Хабрахабре вышла скандальная статья “Программисты не могут написать алгоритмы без помощи”. Автор, начитавшись твитов, аппелирует к тому, что спрашивать алгоритмы на собеседованиях не нужно.
Парни, к сожалению, это все буллшыт. Может, кто-то начал надеяться на карьеру без трудозатрат, но я должен разочаровать. Твиты выше – позерство. Алгоритмы нужны. Без фундаментальных знаний не сделать карьеру. Работа останется тяжелой. И вообще чудес не бывает.
Теперь более подробно.
Не всегда в нашем мире бывает так, что если что-то написано, то именно это имеется в виду. В случае с DHH, создателем Рельс, очевидна вся постановка этого наглого заявления. Предположим, он действительно забыл алгорим пузырька. И решил написать твит. Для этого нужно открыть сайт или мобильное приложение, ввести текст, несколько раз опечаться, исправить и, наконец, спустить опус в сеть.
За это время можно было бы перейти с первой ссылки в Википедию и прочитать алгоритм. Он там очень ясно описан, даже гифка есть с наглядной анимацией. Но вместо этого DHH пишет твит.
Люди поступают так по простой причине. В какой-то момент им хочется показать себя со слабой стороны. Вызывать умиление и сочувствие. Это называется “быть не в порядке”. Феномен очень подробно описан у Джима Кемпа, прочтите обязательно.
Идея в том, что человек, признавшийся в собстенном несовершенсве, вероятней всего снискает расположение окружающих, потому что никто не любит непогрешимых и идеальных. Этим можно и злоупотреблять – пожаловаться, вместо того чтобы лишний раз напрячься. Или привлечь внимание.
Лид из Гугла пишет, что не знает какой-то алгоритм. Ирония в том, что он лид именно по той причине, что знает алгоритмы лучше других! Вы думаете, Гугл держит его за красивые глаза? Обычных кодеров в самом Гугле, я догадываюсь, хватает сверх нормы. В гору идут те, кто знает, как грамотно составить алгортим, чтобы показывать рекламу точнее, продавать трафика больше, управлять автопилотом безопасней.
Может, этот лид и забыл сортировку пузырьком, зато у него в голове каскадная нейронная сеть из текущего проекта и полное понимание того, в каком состоянии она пребывает в каждый момент времени.
Незнаение сортировки не поднимет вас до уровня DHH. За незнание нужного класса или метода не воьзмут в Гугл. Заявлять подобное может лишь тот, что добился успеха именно знанием методов и алгоритмов. Тем, кто пошел на поводу: вот устройтесь сначала в Гугл, а потом жмите лайки этим твитам.
Коллеги, я боюсь, что подобные заявления очень навредят индустрии в самое ближайшее время. Если регулярно вбрасывать идеи, что алгоритмы и банальная память не нужны (все можно нагуглить), то в какой-то момент мы банально столкнемся с дефицитом сознательных людей, способных хоть как-то шевелить мозгами.
Уже сегодня бывает, что разработчики пасуют перед задачами, где нужно проявить смекалку. Все, что не входит в стандартную поставку фреймфорка, становится рокет-сайнс. Или программист впадает в транс, выдумывая немыслимые решения вместо простых и очевидных, давно описанных в академических книгах.
Начитавшись подобных заявлений, джуниоры начнут открыто отказываться от фундаментальных знаний. Станут дерзить на собеседованиях – зачем вы это спрашиваете, разве в вашем проекте это есть?
Уважаемый DHH должен был подумать, что он – ключевая фигура в мире Руби и Рельс. И прежде чем делать столь громкие заявление, предположить, как это скажется на сообществе.
Забавно, что мысль “алгоритмы не нужны” прозвучала из уст именно Глав-Рубиста. Создателя продукта для программистов с минимальными требованиями к квалификации. Именно благодаря рельсам в индустрию ворвались люди, которые до этого овообще не имели опыта с ай-ти. Которые возомнили себя рок-звездами Кремниевой долины, раз твой стартапчик завелся после серии копипаст со Стека. Рельсы стали ПХП второго порядка.
Почему-то ни Рич Хикки, ни Гвидо ван Россум, ни Линус Торвальдс, ни Джо Армстронг подобного не заявляли. И я не нашел их высказываний в этом апофеозе бреда.
Кто здесь пишет на Руби? Ребят, вам не стыдно, что ваше первое лицо заявляет подобное?
Не знать чего-то не стыдно. Стыдно хвастаться незнанием и превращать его в фарс.
Наконец, чем же все-таки полезны алгоритмы. Хотя бы тем, что приводят в порядок мышление, учат абстрактно мыслить. Почему быстрая сортировка действительно быстрая? Почему поиск в словаре быстрее поиска в списке? Куда добавлять элемент – в голову или хвост? Каждый ответ, добытый самостоятельно из книг, повышает вашу квалификацию как специалиста. И косвенно влияет на вашу зарплату.
Я знал человека, который на собеседованиях спрашивал алгоритмы, а его коллеги – нет. Он теперь архитектор, один их нескольких на огромную фирму. Картинка с Киселевым: “совпадение? не думаю!”
Я всегда спрашиваю на собеседованиях основы алгоритмов. Это не решающий фактор, главное, чтобы человек знал ту область, на которую претендует. Нужно джейсоны в базу перекладывать – кто лучше знает, того и возьмем. Но при прочих равных из двух кандидатов я выберу того, что ответит про О-большое, хеш-таблицы и остальное, описанное выше.
Так что не надейтесь на расслабон. Работать и работать.
-
Что почитать №13
Предлагаю к прочтению:
-
Почему советское образование нельзя считать лучшим в мире
Интересная точка зрения на систему образования в разные периоды России. Стоит ознакомиться.
-
The 4-letter-word word that makes my blood boil
У меня тоже горит, когда говорят “просто добавим эту фичу”.
-
На какие не может говорить большинство россиян. Позор-печаль.
-
В новом фильме “Красавица и чудовище” будет гей-сцена
Практически полное отсутствие ЛГБТ-персонажей и любовных линий в кинолентах “Диснея” становилось поводом для критики со стороны активистов гей-движения.
Никогда бы не подумал, что у Диснея будет гомосятина. А ведь такие надежды были на фильм.
-
-
Додо-пица
Позавчера я получил письмо от Додо-пиццы с предложением работать у них. Письмо составлено ужасно и является в своем роде квинтэссенцией всего того, что я ненавижу в найме. Привожу полный текст письма:
Добрый день!
Меня зовут Екатерина, я HR-менеджер компании “Додо Пицца”.
“Додо Пицца” - это сеть пиццерий, которая насчитывает более 170 пиццерий в России, США, Китае, Эстонии, Литве, Румынии, Кыргызстане, Узбекистане и Казахстане.
Додо Пицца - это IT компания, занимающаяся разработкой большой информационной системы Dodo IS, автоматизирующей все процессы управления сетью пиццерий.
Однако мы не просто автоматизируем производство, готовясь к масштабированию российской сети пиццерий на рынки США, Китая и других стран. Мы намерены задать новую высоту в уровне проникновения облачных технологий в управление производством. Все в онлайне - касса, доставка, учет и прочее. Через пять лет директор любого производства будет требовать от своего CEO: ‘Мне нужен уровень автоматизации Додо!’
Подробнее о нашей компании и Dodo IS здесь: https://docs.google.com/document/d/1cOi7oWpDCMzVuULWfSfwsNit1jr6FGc7JEGwUZ1ineY/edit.
И для этого мы ищем:
- старших разработчиков и разработчиков, которые будут вместе с нами работать над созданием облачной информационной системы по управлению предприятием, производством, сетью франчайзи - Dodo IS;
- людей, которые фокусируется на решении бизнес проблем, а не на технологиях;
- тех, кто любит пиццу. Или хотя бы любят ее готовить.
Мы предлагаем вам:
- работу в московском центре разработки компании “Додо Пицца” (метро Автозаводская);
- возможность удаленного сотрудничества, если вы не готовы к переезду;
- настоящий Agile и экстремальное программирование;
- бескрайние возможности роста и работа с актуальными технологиями (ReactJS, Angular, ASP.NET Core, Azure);
- упор на инженерные практики UnitTesting, TDD, Refactoring, CI, DevOps;
- библиотеку книг, в том числе с Amazon;
- участие в конференциях и помощь в подготовке к выступлению (AgileDays, DotNext и др);
- возможность участия в опционной программе компании.
Мы ожидаем, что вы:
- отлично знаете одну из платформ (.NET, Java, Python, NodeJS, Ruby);
- хотите работать с C# и ASP.NET Core (если вы не знакомы с .NET, мы готовы сотрудничать с вами, если вы будете его учить);
- отлично знаете СУБД MySQL, MS SQL Server или PostgreSQL (мы используем MySQL);
- знаете веб-технологии (HTML, CSS, JavaScript, jQuery);
- отличаете git commit от git push;
- будете тесно взаимодействовать с бизнесом, владельцем продукта, командой аналитиков.
Чтобы узнать, насколько вам подходит эта вакансия, заполните, пожалуйста, следующую анкету: https://docs.google.com/a/dodopizza.com/forms/d/e/1FAIpQLScbcvrvzo3u37HTCvC-46FZjTxeQUJnjVYJXDcvMRcCKAkJFg/viewform
Заранее спасибо, успехов вам и всего доброго!
Давайте рассмотрим, что не так в этим письме.
Прежде всего, это не личное предложение, а спам-рассылка. Я ни разу в жизни не покупал у Додо, нигде не регистрировался, не оставлял телефон или емейл. Я получил это письмо с разницей в 5 минут с коллегой, которому тоже выпала такая честь. В письме нет обращения по имени, текст специально составлен так, чтобы можно было массово заслать разным людям независимо от их возраста и пола.
Вполне возможно (но это только догадка), что эйчары продают данные уволившихся сотрудников другим фирмам. Иначе как объяснить, что два бывших сотрудника фирмы N, которые не светили Додо свой емейл, одновременно получили спам?
Дорогая Екатерина! Если вы пишете письмо, но знаете только емейл, потрудитесь потратить 5 минут чтобы узнать что-то об адресате. Иногда вам даже не потребудется прибегать к Гуглу. Например, если адрес почты составлен грамотно, как у меня –
ivan@grishaev.me– то не составит труда догадаться, что адресата зовут Иван Гришаев, а ссылки на Гитхаб и Линкед Ин будут первыми.В личном обращении считается нормой указывать, как вы вышли на меня. Я хочу знать, кто дал ссылку на мой профиль. Если реферрер достойный человек, скорее всего, из нашего общения что-то получится. У вас этого нет.
Я понимаю, что вам лень заморачиваться. Скорее, вас интересуют премиальные, а кого вы нанимаете – не ваших интересов дело. Но уже первым абзацем вы отсекли хороших разработчиков, которые привыкли к грамотной и вежливой переписке и не реагируют на спам.
Далее, после неумелого приветствия идут четыре абзаца с корпоративной шизой и неумелым пафосом. Господи, они пиццу продают, а СЕО будет требовать! В моем понимании, пицца – это что-то вроде Русского Аппетита, сигарет и презервативов. Случайный перекус, расходный материал. Все делают пиццу, и везде она одинаковая. СЕО будет требовать, насмешили.
Ладно, техническая часть.
Настоящий Agile и экстремальное программирование. Я очень не хочу настоящего аджайла и такого программирования в русской команде. Скорее всего, это будет гремучая смесь эффективного менеджмента, промывания мозгов, релизы по ночам, тим-лид, одержимый паттернами с Хабра. Микросервисы, Реакт и все это ваше говно, когда форма заказа весит 2Мб и падает на каждом чихе. Спасибо, я этого говна наелся.
Отлично знаете одну из платформ (.NET, Java, Python, NodeJS, Ruby) / хотите работать с C# и ASP.NET Core. Взаимоисключающие параграфы. Ребят, вы определитесь, кого ищете – Дот-нетчика или питонистов? Скажем, я знаю ваши “Java, Python, NodeJS, Ruby”, а посадят меня за Дот-нет? На Виндоуз 10? IIS, повер-шелл, реестр?
Я много слышал, чтобы из Дот-нета уходили на Линукс-стек, но чтобы добровольно от Линукса вернуться в Винду – это профессиональное самоубийство. В моем Линкед-Ине нет вообще ничего, что как-то могло бы связывать меня с Дот-нетом и Виндой. Екатерина, вы хоть смотрите, кому пишете? Риторический вопрос.
бескрайние возможности роста и работа с актуальными технологиями Это ASP.NET Core актуальная технология?
Отличаете git commit от git push. Не знаю, по мне шутка не зашла.
Чтобы узнать, насколько вам подходит эта вакансия, заполните, пожалуйста, следующую анкету. Идиотская формулировка. Получается, я заполню форму, чтобы узнать, подходит ли вакансия мне или нет? По-моему, заинтересованность на вашей стороне, а текст составлен так, словно это мне нужно.
Откроем Гугло-форму.
Имеете ли Вы опыт оптимизации запросов к БД? Какие инструменты и техники оптимизации Вы применяли? Это очень абстрактный вопрос, и чем опытней разработчик, тем дольше на него отвечать. Я бы мог на эту тему устроить доклад на час, но писать простыню текста мне лень. Такое нужно срашивать на собеседовании лично.
Как повысить скорость отдачи веб-страницы с сервера? Как повысить скорость рендера веб-страницы в браузере? Аналогично, здесь может быть тысяча ситуаций и столько же выходов из нее. Вариант “поставить кешик” я не рассматриваю. Но опять же, все писать долго, не много ль чести?
Какие новинки в вашем языке программирования (C#, Java, JS, Python, Ruby,…) вам нравятся. Что бы вы добавили еще? Прекрасный вопрос к аудитирии ЛОРа или Хабра. С помощью языка я решаю задачи бизнеса, у меня нет времени на мечты о волшебных свистелках, которые сделают работу за меня.
Какие книги по программированию Вы прочли за последние полгода? Перечислите не менее трех. Прекрасный, божественный вопрос! Не менее трех, Карл! Иначе говоря, если вы:
- прочитали 2 книги;
- прочитали 1 том Кнута;
- написали свою книгу;
- прочли серию технических статей на английском;
- слушали подкасты,
то вы лох и неудачник и вам не место в Додо пицце, потому что какой-то пидорас решил, что за полгода надо прочесть не менее трех книг. Что, всего две книги? Мы вам перезвоним.
Я искренне надеюсь, что до кого-то дойдет, что нельзя писать такие письма. И что в кадровом отделе полное непонимание того, как проводить найм.
-
Четырнадцатая встреча
С опозданием отчитываюсь о прошедшем митапе.
С необычным докладом выступила Наталья Смирных. Речь шла о работе в эмиграции на Южно-Африканском континенте. Наталья – учитель английского, но интересно послушать и айтишникам.
Павел Райн рассказал о маркетинге в соцсетях. Я в этом мало понимаю, но схемы обмана Павел объяснил хорошо.
Совсем скоро анонс пятнадцатой встречи. Хотите выступить – пишите в личку, чат Телеграма или создайте ишью в нашем Гитхабе.
Writing on programming, education, books and negotiations.