-
Educational startups
Today, educational startups are everywhere. The number of them is growing daily. There hardly might be a week when no new HTML/CSS/Javascript educational site appears on the Internet.
Sorry if I offend someone, but I don’t believe in remote education through special sites that offer video lessons. More precisely, there might be some effect of course but quite poorer than standard education with people and books.
About ten years ago, the Internet was full of paid video courses on DVDs. These were home-made lessons made by students where they spoke on basics of PHP+HTML. Today, the startups remind me those DVDs. The only difference is you do not need to order a disk anymore but watch lessons online right after you have paid.
I’m not running an educational site. I also don’t want to reduce someone’s reputation or business. Let’s just discuss some points that seem important to me.
Let’s switch to a browser right now and google for “educational startup” phrase. For me, the first link is “Are Education Startups The New Dot Com?” In that article, there is another link titled “Edtech Is The Next Fintech”. Read them, they highlight my concerns.
Below, there is a bunch of list-like posts titled “N best educational startups”:
- 16 Startups Poised to Disrupt the Education Market
- 10 emerging edtech startups of India - YourStory.com
- 10 Indian Education Startups to Look Out for in 2017
- TechCrunch Disrupt 2016 - 7 EdTech Startups
- 29 edtech startups in Southeast Asia
And so on. It was only the two first pages. Let’s check for Angel List then:
14,615 COMPANIES 2,646 INVESTORS 19,127 FOLLOWERS 2,675 JOBS14615 companies. There are about 250 countries in the world. I’ll take rather 200 due to wars or lack of development in some of them. Dividing a number of educational startups on the number of counties gives 14615 / 200 = 73 per country.
Don’t you think it’s bit more than we need?
Look, we have about 3 search engines to find anything on the Internet. There are probably 2-5 mobile operators in your country. We’ve got one Wikipedia. But there are 14615 educational companies who want to make money on educational market.
I really doubt they are about real education
In fact, there is one goal that a startup tries to reach. It forces users to buy lessons making them think it could really raise their level. Site developers bring challenging factors to manipulate users. These are top-ranked tables, a scale of education decorated as a route with milestones and a crown or a goblet in the end. Any startup brings a chat-room to let users share their success to feel proud.
I’ve seen several educational sites and must confess they don’t bring any revolutionary ideas. Yes, some of them provide smart environment when you have an IDE into a browser. But the truth is there are only two ways of education that really work. These are people and books.
Sometimes, people ask me how to improve their experience. Usually they’ve spent some time solving educational tasks but they cannot start a real project. I always answer the same: join a project where professionals work. Being in a team of high-qualified people, you will grow up in a quite short term.
Reading books helps you to systematize fragments of random knowledge that you’ve got from Twitter, StakOverflow, Wired and so on. Everything that educational sites try to sell you has already been published in books. Really, there are tons of books about PHP, HTML, Java, Python or whatever. You may borrow them for free.
On the internet, you can by any used book for several dollars. A lesson is usually paid for subscription. In a month, you will lose your access unless you pay again. The book will be yours forever.
Yes, reading a book is a bit more difficult than watching a video. It’s hard and boring. You even need to interpret code in mind. There is no widgets and chats. Although, it really works.
A book is really important today since our knowledge is not arranged. We are getting random fragments missing important details. I may compare a book with an asphalt paver that moves slowly but removes any roughness and holes in your mind.
People and books are the only way to learn
Recently, I finished reading “Web-development with Clojure” book. Although I thought I knew Clojure pretty well, the book turned into discovery for me. I’ve got plenty of hints and technics that I’m willing to try in the future.
Education in wide meaning is hard process. Educational startups make you think it has become easy. That is wrong.
Once I finished reading my first Clojure book, I could solve any primitive task like sorting or finding min/max element in a list using recursion. But it took huge effort to write an HTTP server that manages database connection, renders templates, writes logs, calls Twitter API and so on.
The reason was all the lessons and tutorials miss some special knowledge about how to manage with complexity. Hot to connect parts of your application together.
A computer is not a best tool for education. It’s a great tool but also an entertainment center. Ideally, you should turn off all the messagers, close YouTube, Twitter… On your laptop, there a lot of things may interrupt you. Being tired, your brain can always find a pretext to switch on something funny.
IT-education is not about coding, it also includes negotiations. Sometimes, you might be 100% right but would not be able to deliver your ideas. You may offend your customer with non-suitable manner of speaking. Only people who work close to you may correct that mistakes, not online lessons. By the way, I have never seen a lesson that highlights anything from those mentioned above.
Of course, I do not blame startups for spreading across the Internet. The reason it happens is a lack of professionals. This is reaction of market. Did you want more programmers? Here you’ve got them. Young people know that IT companies are interested in hiring more people. Oftenly, watching just several videos enough to get PHP/Wordpress job paid in US dollars.
Universities are not in charge of your further employment. There is a common situation when you’ve just finished the last course but cannot find a job because the industry changes so fast. Nor the government will support you. Education seems to be the last thing they are interested in. Today, my country wages two wars, plays geopolitics and eradicates imported cheese while education level goes down-wise year after year.
Educational sites might be a hope. But they devalue the real meaning of education.
The process of self-education is hard. Only you is interested in it, not startups
OK I’m about to finish and I’ve got a question. I heard, the most powerful language is Lisp. At least Alan Kay said so (a guy who invented OOP). So did Stallman, Dijkstra and other great programmers. Do you know any educational site which offers Lisp lessons?
I googled for a bit to find any. Nothing on Coursera – the most known lesson hub. Nothing on Netology. At least Hexlet has SICP section where they retell it in Russian (see my note on books).
No, they won’t teach you the most powerful language. So what is the final goal then? Do we need more Python or Java programmers? We have already got lots of them but we still suffer from weird interfaces and buggy applications. It won’t work in such a way.
Let me summarize.
- I’m not against someone’s business. I even believe some people who watched those videos really made progress in their career. Maybe, they could not find proper books or their brain feels good with such a way of education.
- But I’d like to name things properly. Educational startups are the business by themselves. The goal of the business is to make money but not to make you cleverer. Instead, the longer you keep your monthly subscription active, the better a startup develops.
- There is definitely overheat on the educational market. It seems to be like a bubble.
- Startups tell you the education is easy and funny. It’s not.
- People and books help a lot. Online lessons – well, yes but quite less.
-
Weekly links #26
-
Good news for those who are afraid of being not employed with Clojure.
-
Clojure In London: Healthunlocked
Originally HealthUnlocked was built on top of .NET, but over the last few years they have migrated to a Microservice based architecture featuring Clojure.
-
Postgres to Datomic on Hacker News
Nice comments there. By the way, thank you everybody who has read my previous post.
-
Russian Internet Pioneer Anton Nosik Dies At 51
Goodbye Anton and thank you. Your contribution is invaluable.
-
-
Migration from Postgres to Datomic
Recently, I migrated my Clojure-driven pet project from PostgreSQL to Datomic. This is Queryfeed, a web application to fetch data from social networks. I’ve been running it for several years considering it as a playground for some experiments. Long ago, it was written in Python, then I ported it to Clojure.
It was a great experience when I just finished reading “Clojure for True and Brave” book and was full of desire to apply new knowledge to something practical rather than solving Euler problems in vain.
This time, I’ve made another effort to switch the database backend to Datomic. Datomic is a modern, fact-driven database developed in Cognitect to be used in conjunction with Clojure. It really differs for classical RDBS such as MySQL or PostgreSQL. For a long time, I’ve been thinking whether I should try it. Meanwhile, more and more Clojure/conj talks have been publishing on YouTube. At my work, we use vast PostgreSQL database and the code base is tied to close to it. There is no an option to perform a switch on weekends. So I decided to port my pet project to Datomic in my spare time.
Surely, before doing this, I googled for a while and was really wondered about how few information I found on the Internet. There were just three posts that did not cover the subject in details. So I decided to share my experience here. Maybe it would help somebody with their migration duties.
Of cause, I cannot guarantee the steps described below will meet your requirements as well. Each database is different, so it’s impossible to develop a final tool that could handle all the cases. But at least you may borrow some of those.
Table of Contents
- Introduction
- Dump Postgres database
- Adding Datomic into your project
- Loading the data into Datomic
- Update the code
- HTML templates
- Remove JDBC/Postgres
- Update unit test
- Infrastructure (final touches)
- Conclusion
Introduction
Before we begin, let’s talk about what is the reason to switch to Datomic. That question cannot be answered just in one or two points. Before Datomic, I’ve been working with PostgreSQL for several years and reckon it as a great software. There is no such a task that Postgres cannot deal with. Here are just some of them:
- streaming replication, smart sharding;
- geo-spatial data, PostGIS;
- full-text search, trigrams;
- JSON(b) data structures;
- typed arrays;
- recursive queries;
- and tons of other benefits.
So if Postgres is really so great, why switching then? In my point of view, it brings the following benefits into a project:
- Datomic is simple. In fact, it has only two operations: read (querying) and write (transaction).
- It supports joins as well. Once you have a reference, it can be resolved into a nested map. References may be recursive. In PostgreSQL or any other RDBS, you always have a plain result with possibly duplicated rows. The ORM logic that may deal with parsing raw SQL response might be too complicated to understand.
- Datomic was developed in the same terms as Clojure was. These are simplicity, immutability and declarative style. Datomic shares Clojure’s values.
- It accumulates changes through time like Git or any other control version system. With Datomic, you may always roll-back in time to get a history of an order or collect audit logs.
Let’s highlight some general steps we should pass through to complete the migration. These are:
- dump you Postgres data;
- add Datomic into your project;
- load the data into Datomic;
- rewrite the code that operates on data;
- rewrite your HTML templates;
- update or add unit tests;
- remote JDBC/Postgres from your project;
- setup infrastructure (backups, console, etc)
As you see, it is not as simple as it could be thought even for a small project. In my case, migrating Queryfeed took about a week working by nights. It includes:
- two days to read the whole Datomic documentation;
- one day to migrate the data;
- two days to fix the business logic code and templates;
- two days to deploy everything to the server.
Regarding to the documentation, I highly recommend you to read it first before doing anything. Please do not rely on random Stack Overflow snippets. Datomic is completely different than classical SQL databases, so your long-term Postgres or MySQL experience won’t work.
Quick tip here, since it could be difficult to read lots of text from a screen, I just download any page I wish to read into my Kindle using the official Amazon extension for Chrome. The paper appears on my Kindle in a minute and I read it.
Once you’ve finished with the docs, feel free to the next step: dumping your PostgreSQL data.
Dump Postgres database
Exporting you data into a set of files won’t be so difficult I believe. I may guess your project has
projectname.dbmodule that handles the most of database stuff. It should haveclojure.java.jdbcmodule imported and*db*ordb-specvariables declared. Your goal is for every table you have in the database, run a query something likeselect * from <table_name>against it and save the result into a file.What file format to use depends on your own preferences, but I highly recommend the standard
EDNfiles rather than JSON, CSV or whatever. The main point in favor ofEDNis it handles extended data types such as dates and UUIDs. In my case, every table has at least one date field, for examplecreated_atthat is not null and is set with the current time automatically. When using JSON or YAML, the dates will be just strings so you need to write extra code to restore a nativejava.util.Dateclass from a string. So are unique identifiers, UUIDs.In addition, since
EDNfiles represent native Clojure data structures, you don’t need to addorg.clojure/data.jsondependency into your project. Everything can be made with out-from-the-box functions. The next snippet dumps all the users from your Postgres database into ausers.ednfile:(def *db* {... your JDBC spec map...}) (def query (partial jdbc/query db-spec)) (spit "users.edn" (with-out-str (-> "select * from users" query prn)))And that is! With only one line of code, you’ve just dumped the whole table into a file. Repeat it several times substituting a name of an
*.ednfile and a table. If you have many tables, wrap it with a function:(defn dump [table] (spit (format "%s.edn" table) (with-out-str (-> (format "select * from %s" table) query prn))))Then run it against a vector of table names but not a set since an order is important. For example, if you have a user has a foreign key to
orderstable, it should be loaded first.To check whether your dump is correct, try to restore it from a file as follows:
(-> "users.edn" slurp read-string first)Again, it is so simple to perform such things in Clojure. Within one line of code, you have just read the file, restored the Clojure data from it and took the first map from a list. In REPL, you should see something like:
{:id 1 :name "Ivan" :email "test@test.com" ... other fields }That means the dump step was done as well.
Adding Datomic into your project
Here, I won’t discuss on that step so long since it is highlighted as well in the official documentation. Briefly, you need to:
- register on Datomic site, it is free;
- set up your GPG credentials;
- add Datomic repository and the library into your project;
- (optional) if you use Postgres-driven backend for
Datomic, create a new Postgres database using SQL scripts from
sqlfolder. Then run a transactor.
Below, here is a brief example of my setup:
;; project.clj (defproject my-project "0.x.x" ... :repositories {"my.datomic.com" {:url "https://my.datomic.com/repo" :creds :gpg}} :dependencies [... [com.datomic/datomic-pro "0.9.5561.50"] ...] ...)Run
lein depsto download the library. You will be probably prompted to input your GPG key.A quick try in REPL:
(require '[datomic.api :as d]) (def conn (d/connect "datomic:mem://test-db"))Loading the data into Datomic
In this step, we will load the previously dumped data into your Datomic installation.
First, we need to prepare the schema before loading the data. A schema is a collection of attributes. Each attribute by itself is a small piece of information, for example a
:user/nameattribute keeps a string value and indicates a user’s name.An entity is a set of attributes linked together by system identifier. Thinking in RDBS terms, an attribute is a DB column whereas an entity is a row of a table. That really differs Datomic from such schema-less databases as MongoDB for example. In Mongo, every entity may have any structure you wish even across the same collection. In Datomic, you cannot write a string value into a number or a boolean into a date. One note, an entity may own an arbitrary number of attributes.
For example, in Postgres if you did not set default values for a column and it is not null, you just cannot skip it when inserting a row. In Datomic, you may submit as many attributes as you want when performing a transaction. Imagine we have a user model with ten attributes: a name, email, etc. When creating a user, I may pass only a name and there won’t be an error. So pay attention you submit all the required attributes.
Datomic schema is represented by native Clojure data structures: maps, keywords and vectors. That’s why they are stored in EDN files as well. A typical initial schema for fresh Datomic installation may look as follows:
[ ;; Enums {:db/ident :user.gender/male} {:db/ident :user.gender/female} {:db/ident :user.source/twitter} {:db/ident :user.source/facebook} ;; Users {:db/ident :user/pg-id :db/valueType :db.type/long :db/cardinality :db.cardinality/one :db/unique :db.unique/identity} {:db/ident :user/source :db/valueType :db.type/ref :db/cardinality :db.cardinality/one :db/isComponent true} {:db/ident :user/source-id :db/valueType :db.type/string :db/cardinality :db.cardinality/one} ... ]The first four ones are special attributes that are proposed as enum values. I will discuss more on them later.
Again, check for the official documentation that describes schema usage.
Now that we prepared a schema, let add some boilerate code in our
dbnamespace:(ns project.db (:require [clojure.java.io :as io] [datomic.api :as d])) ;; in-memory database for test purposes (def db-uri "datomic:mem://test-db") ;; global Datomic connection wrapped in atom (def *conn (atom nil)) ;; A function to initiate the global state (defn init-db [] (d/create-database db-uri) (reset! *conn (d/connect db-uri))) ;; reads an EDN file located in `resources` folder (defn read-edn [filename] (-> filename io/resource slurp read-string)) ;; reads and loads a schema from EDN file (defn load-schema [filename] @(d/transact @*conn (read-edn filename)))I hope the comments highlight the meaning of the code as well. I just declared a database URL, a global connection, a function to connect to the DB and two helper functions.
The first function just reads a
EDNfile and returns a data structure. Since our files a stored in resources folder, there is aio/resourcewrapper here in the threading chain.The second function also read a file but also performs a Datomic transaction passing data as a schema.
The
db-urivariable is represented with URL-like string. Currently, we use in-memory storage for test purposes. I really doubt you can load the data directly to SQL-driven storage without errors so let’s just practice for a while. Later, when the import step will be ready, we will just switchdb-urivariable to production-ready URL.With the code above, we are ready to load the schema. I put my initial schema into a file
resources/schema/0001-init.ednso I may load it as follows:(init-db) (load-schema "schema/0001-init.edn")Now that we have a schema, let’s load the previously saved Postgres data. We need to add more boilerate code. Unfortunately, there cannot be a common function that may map your Postgres fields into Datomic attributes. The functions to convert your data might look a bit ugly, but they are one-time-purpose only so please don’t mind.
For each EDN file that contains data of a specific table, we should:
- read a proper file, get a list of maps;
- convert each PostgreSQL map into Datomic map;
- perform Datomic transaction passing a vector of Datomic maps.
Below, here is an example of my
pg-user-to-datomicfunction that accepts a Postgres-driven map and turns it into a set of Datomic attributes:(defn pg-user-to-datomic [{:keys [email first_name timezone source_url locale name access_token access_secret source token status id access_expires last_name gender source_id is_subscribed created_at]}] {:user/pg-id id :user/email (or email "") :user/first-name (or first_name "") :user/timezone (or timezone "") :user/source-url (URI. source_url) :user/locale (or locale "") :user/name (or name "") :user/access-token (or access_token "") :user/access-secret (or access_secret "") :user/source (case source "facebook" :user.source/facebook "twitter" :user.source/twitter) :user/source-id source_id :user/token (UUID/fromString token) :user/status (case status "normal" :user.status/normal "pro" :user.status/pro) :user/access-expires (or access_expires 0) :user/last-name (or last_name "") :user/gender (case gender "male" :user.gender/male "female" :user.gender/female) :user/is-subscribed (or is_subscribed false) :user/created-at (or created_at (Date.))})Yes, it looks ugly a bit annoying, but you have to write something like this for every table your have.
Here is the code to load a table into Datomic:
(->> "users.edn" slurp read-string (map pg-user-to-datomic) transact!)Before we go further, let’s discuss some important notes on importing the data.
Avoid nils
Datomic does not support nil values for attributes. When you do not have a value for an attribute, you should either skip it or pass an empty value: a zero, an empty string, etc. That’s why the most of expressions have
(or "")at the end of threading macro.Shrink your tables
Migrating to the new datastore backend is a good chance to refactor your schema. For those who has spent years working with relational database it is not a secret that typical SQL applications suffer from lots of tables. In SQL, it is not enough to keep just “entities” tables: users, orders, etc. Often, you need to associate a product with colors, a blog post with tags or a user with permissions. That leads to
product_colors,post_tagsand other bridge tables. You join them in a query to “go through” from a user to their orders, for example.Datomic is free from bridge tables. It supports reference attributes that are linked to any other entity. In addition, each attribute may carry multiple values. For example, if we want to link a blog post with a set of tags, we’d rather declare the following schema:
[ ;; Tag {:db/ident :tag/name :db/valueType :db.type/string :db/cardinality :db.cardinality/one :db/unique :db.unique/identity} ;; Post {:db/ident :post/title :db/valueType :db.type/string :db/cardinality :db.cardinality/one} {:db/ident :post/text :db/valueType :db.type/string :db/cardinality :db.cardinality/one} {:db/ident :post/tags :db/valueType :db.type/ref :db/cardinality :db.cardinality/many} ]In Postgres, you will need
post_tagsbridge table withpost_idandtag_idforeign keys. In datomic, you simply pass a vector of IDs in:post/tagsfield when creating a post.Migrating to Datomic is a great chance to get rid of those tables.
Use enums
Both Postgres and Datomic provide support of enum types. A enum type is a set of values. An instance of enum type may have only one of those values.
In Postgres, I use enum types a lot. They are fast, reliable and provide strong consistency of you data. For example, if you have an order with possible “new”, “pending” and “paid” states, please don’t use
varchartype for that. Somehow you may write something wrong there, for example mix up the register or make a misprint. So you’d better to declare the schema as follows:create type order_state as enum ( 'order_state/new', 'order_state/pending', 'order_state/paid' ); create table orders ( id serial primary key, state order_state not null default 'order_state/new'::order_state, ... );Now you cannot submit an unknown state for an order.
Although Postgres enums are great, JDBC library makes our life a bit more difficult by forcing us to wrap enum values into
PGObjectwhen querying or inserting data. For example, to submit a new state for an order, you cannot just pass a string"order_state/paid". You’ll get an error saying you are trying to submit a string fororder_statetype column. So you have to wrap your string into a special object:(defn get-pg-obj [type value] (doto (PGobject.) (.setType type) (.setValue value))) (def get-order-state (partial get-pg-obj "order_state")) ;; now, composing parameters for a query {:order_id 42 :state (get-order-state "order_state/paid")}Another disadvantage here is inconsistency between select and insert queries. When you just read the data, you get the enum value as a string. But when you pass a enum as a parameter, you still need to wrap it with PGObject. That is a bit annoying.
Datomic also has nice support of enums. There is no a special syntax for them. Enums are special attributes that do not have values but only names. Above, I have already highlighted them:
[ {:db/ident :user.gender/male} {:db/ident :user.gender/female} {:db/ident :user.source/twitter} {:db/ident :user.source/facebook} ]Later, you may reference a enum value passing just a keyword
:user.source/twitter. It’s quite simple, fast and keeps your database consistent.JSON data
Personally, I try to avoid using JSON in Postgres as long as it is possible. Adding JSON fields everywhere turns your Postgres installation into MongoDB. It becomes quite easy to make a mistake or corrupt the data and fall into a situation when one half or your JSON data has a particular key and the rest half does not.
Sometimes you really need to keep JSON in your DB. A good example might be Paypal Instant Notifications. These are HTTP requests that Paypal sends to your server when a customer buys something. IPN’s body keeps about 30 fields and its structure may vary depending on transaction type. Splitting that data into separate fields and storing all of them across separate columns will be a mess. A solution will be to fetch only the most sensible ones (date, email, sum, order number) and write the rest data into a
jsonbcolumn. Then, once you need to fetch any additional information from an IPN, for example a tax sum, you may query it as well:select data->'tax_sum'::numeric as tax from ipn where order_number = '123456';In Datomic, there is no JSON type for attributes. I’m not sure I made a proper decision, but I just put those JSON data into a text attribute. Sure, where is no a way to access separate fields in a datalog query or apply roles to them. But at least I can restore the data when selecting a single entity:
;; local handler to parse JSON with keywords in keys (defn parse-json [value] (json/parse-string v true)) (defn get-last-ipn [user-id] (let [query '[:find [(pull ?ipn [*]) ...] :in $ ?user :where [?ipn :ipn/user ?user]] result (d/q query (d/db @*conn) user-id)] (when (not-empty result) (let [item (last (sort-by :ipn/emitted-at result))] (update item :ipn/data parse-json)))))Foreign keys
In RDBS, a typical table has auto-incremental
idfield that marks a unique number of that row. When you need to refer to another table, an order or a user’s profile, you declare a foreign key that just keeps a value for those id. Since they are auto-generated, you should never bother on their real values, but only consistency.In Datomic, you do not have possibility to have auto-incremented values. When you import your data, it’s important to handle foreign keys (or references in terms of Datomic) properly. During the import, we populate
:<entity>/pg-idfield that holds the legacy Postgres value. Once you import a table with foreign keys, you may resolve a reference as follows:{... ;; other order fields :order/user [:user/pg-id user_id]}A reference attribute may be represented as vector of two where the first value is an attribute name and the second is its value.
For new entities created in production after migration to Datomic, you do not need to submit
.../pg-idvalue. You may either delete it (retract) once the migration process has been finished or just keep it in the database as an indicator that marks legacy data.Update the code
This step would be the most boring, I believe. You need to scan the whole project and fix those fragments where you access the data from the database.
Since it is a good practice to prepend attributes with a namespace, the most common change would be attribute renaming I believe:
;; before (println (:name user)) ;; after (println (:user/name user))You will face less problems by organizing special functions that wraps the underlying logic. A good example might be to add
get-user-by-id,get-orders-by-user-idand so on.If you use HugSQL or YeSQL Clojure libraries than you already have such functions created dynamically from
*.sqlfiles. That is quite better than having naked SQL everywhere. Porting such a project to Datomic will be much easier.HTML templates
Another dull step that cannot be automated is to scan your Selmer templates (if you have them in your project, of course) and to update those fragments where you touch entities’ attributes. For example:
;; before <p>{{ user.first_name}} {{ user.last_name}}</p> ;; after <p>{{ user.user/first-name}} {{ user.user/last-name}}</p>You may access nested entities as well. Imagine a user has a reference to their social profile:
<p>{{ user.user/profile.profile/name }}</p> ;; "twitter", "facebook" etcDatomic encourages us to use enums which values are just keywords. Sometimes, you need to implement
case...thenpattern in your Selmer template and render any content depending on enum value. This may be a bit tricky since Selmer does not support keyword literals. In the example above, a user has:user/sourceattribute that references a enum with possible values:user.source/twitteror:user.source/facebook. Here is how I figured out switching on them:{% ifequal request.user.user/source.db/ident|str ":user.source/twitter" %} <a href="https://twitter.com/{{ user.user/username }}">Twitter page</a> {% endifequal %} {% ifequal request.user.user/source.db/ident|str ":user.source/facebook" %} <a href="{{ user.user/profile-url }}">Facebook page</a> {% endifequal %}In the example above, we have to turn a keyword into a string using
|strfilter to compare both values as strings.To find all the Selmer variables or operators in Selmer, just grep your templates folder by
{{or{%literals.Remove JDBC/Postgres
Now that your project is Datomic-powered and does not need JDBC drivers anymore, you may either remove them from the project or at least decrease them to the
devdependencies needed only for development purposes.Scan you project grepping it with
jdbc,postgresterms to find those namespaces that still use legacy DB backend. Remove any that still present. Open your rootproject.cljfile, removejdbcandpostgresqlpackages from:dependenciesvector. Ensure you may run and build the application and unit tests as well.Update unit test
Datomic is a great tool in those aspect you may use in-memory backend when running tests. That makes them pass quite faster and without needing setting up Postgres installation on you machine.
I believe your project is able to detect whether it is in
dev,testorprodmode. If it’s not, take a look at Luminus framework. It’s done quite well in that meaning. For each type of environment, you specify its own database URL. For test, it will be in-memory storage.Using the standard
clojure.testnamespace, you wrap each test with a fixture that does the following steps:- creates a new database in memory and connects to it;
- runs all the schemas against it (migrations);
- populates it with predefined test data (users, orders etc; also know as “fixtures”);
- runs the test itself
- drops the database and closes and disconnects from it.
These steps should be run for each test. In that case, we can guarantee what every test has its own environment and does not depend on other tests. It’s a good practice when a test accepts a fresh installation not being touched by previous tests.
Some preparation steps are:
(ns your-project.test.users (:require [clojure.test :refer :all] [your-project.db :as db])) (defn migrate [] "Loads all the migrations" (doseq [file ["schema/0001-init.edn" "schema/0002-user-updated.edn"]] (db/load-schema file)) (defn load-fixtures [] "Loads all the fixtures" (db/load-schema "fixtures/test-data.edn")) (defn test-fixture [f] (db/init) ;; this function reads the config, ;; creates the DB and populates ;; the global Datomic connection (migrate) (load-fixtures) (f) ;; the test is run here (db/delete) ;; deletes a database (db/stop)) ;; stops the connection (use-fixtures :each test-fixture)Now you may write your tests as well:
(deftest user-may-login ...) (deftest user-proceed-checkout ...)For every test, you will have a database running with all the migrations and test data loaded.
If you still do not have any tests in your project, I urge you to add them soon. Without tests, you cannot be sure you do not break anything when changing the code.
Infrastructure (final touches)
In the final section, I will highlight several important points that relate to the server management.
Setting up production Postgres-driven backend
Running in-memory Datomic database is fun since it really costs nothing. In production, you would better set up more reliable backend. Datomic supports Postgres storage system out from the box. To prepare the database, run the following SQL scripts:
sudo su postgres # switch to postgres user cd /path/to/datomic/bin/sql psql < postgres-user.sql psql < postgres-db.sql psql datomic < postgres-table.sqlThe scripts above create a user
datomicwith the passworddatomic, then the databasedatomicwith the ownerdatomic. The last script creates a special table to keep Datomic blocks.Please do not forget to change the standard
datomicpassword to something more complicated.Running the transactor
The following page describes how to run a transactor needed by peer library when you use non-memory data storage. I’m not going to retell it here. Instead, I will share a bit of config to run it automatically using the standard
init.dLinux daemon.Create a file named
datomic.confin yourmy-project/confdirectory. Put a symlink to/etc/init.d/folder that references that file. Add the following lines into it:description "Datomic transactor" start on runlevel startup stop on runlevel shutdown respawn setuid <your user here> setgid <your group here> chdir /path/to/datomic script exec bin/transactor sql-project.properties end scriptThere,
/path/to/datomicis a directory where unzipped Datomic installation is located.sql-project.propertiesis a transactor configuration file where you should specify your Datomic key sent to your email.Now that you have put a symlink, try the following commands:
sudo start datomic status datomic # datomic start/running, process 5281 sudo stop datomicConsole
Most of RDBS have UI applications to manage the data. Datomic comes with built-in console that is run as web application. Within those console, you can examine the schema, perform queries and transactions.
The following template runs a console:
/path/to/datomic/bin/console -p 8088 <some-alias> <datomic-url-without-db>In my example, the command is:
$(DATOMIC_HOME)/bin/console -p 8888 datomic \ "datomic:sql://?jdbc:postgresql://localhost:5432/datomic?user=xxxxx&password=xxxxx"Opening a browser at
http://your-domain:8888/browserwill show you a dashboard.Some security issues may be mentioned here. The console does not support any login/password authentication, so it is quite unsafe to run the console on production server as-is. Implement at least some of the following steps:
- Proxy the console with Nginx. It must not be reachable by itself.
- Limit access by a list of IPs. These may be your office or your home only.
- There should be only secure SSL connection allowed, no plain HTTP. Let’s encrypt would be a great choice (see my recent post).
- Add basic/digest authentication to your Nginx config.
To run a console as a service, create another
console.conffile in/etc/init.d/directory. Use thedatomic.conffile as template. Substitute the primary command with those one shown above. Now you can run the console only when you really need it:sudo start consoleBackups
Making backups regularly is highly important. Datomic installation carries a special utility to take care of it. You won’t need to make your backups manually by running
pgdumpagainst Postgres backend. Datomic provides a high-level backing up algorithm that performs in several threads. In addition, it supports AWS S3 service as a destination point.A typical backup command looks as follows:
/path/to/datomic/bin/datomic -Xmx4g -Xms4g backup-db <datomic-url> <destination>To access AWS servers, you need to export both
AWS_ACCESS_KEY_IDandAWS_SECRET_KEYvariables first or prepend a command with them. In my case, the full command looks something like:AWS_ACCESS_KEY_ID=xxxxxx AWS_SECRET_KEY=xxxxxxx \ /path/to/datomic/bin/datomic -Xmx4g -Xms4g backup-db \ datomic:sql://xxxxxxxx?jdbc:postgresql://localhost:5432/datomic?user=xxxxxx&password=xxxxxxx" \ s3://secret-bucket/datomic/2017/07/04The date part in the end is substituted automatically using
$(shell date +\%Y/\%m/\%d)expression in Makefile or the following in bash:date_path=`date +\%Y/\%m/\%d` # 2017/07/04Add that command into your crontab file to make backups regularly.
Backups as a way to deploy the data
The good news are backup’s structure does not depend on the backend type. No matter you dump in-memory storage or Postgres cluster, the backup can be restored everywhere as well. It gives us possibility to migrate the data on our local machine, make a backup and then restore it into production database.
Once you finished migrating you data, launch the backup command described above. The backup should go to S3. On the server, run the
restorecommand:AWS_ACCESS_KEY_ID=xxxxx AWS_SECRET_KEY=xxxxx /path/to/datomic/bin/datomic -Xmx4g -Xms4g restore-db \ s3://secret-bucket/datomic/2017/07/04 \ "datomic:sql://xxxxxxx?jdbc:postgresql://localhost:5432/datomic?user=xxxx&password=xxxxx"When everything is done without mistakes, the server will catch the new data.
Conclusion
After spending about a week on moving from Postgres to Datomic I can say it really worths it. Although Datomic does not support most of the Postgres smart features like geo-spatial data or JSON structures, it is much closer to Clojue after all. Since it was made by the same authors, Datomic looks like as a continuation of Clojure. And that is a huge benefit that may overweight disadvantages mentioned above.
Surfing the Internet, I found the next links that may also be helpful:
- A Minor Victory with Datomic
- Datomic Setup
- Using Datomic? Here’s How to Move from PostgreSQL to DynamoDB Local
I hope you enjoyed reading this material. You are welcome to share your thoughts in the commentary section.
-
Let's encrypt
I’ve just tried Let’s encrypt service and may say it works like a charm! I am really impressed by it’s simplicity and robustness. It really works as it’s promised within several lines in shell. That’s how a good software should be made.
Let’s encrypt is an SSL authority service that issues short-term SSL certificates for you. A typical certificate expires in 90 days and then you request for a new one.
What’s the point to use exactly Let’s encrypt? There are some other SSL providers who also offer free certificates, just google for “free SSL cert”. The main reason is Let’s encrypt is totally automated. You don’t even need to open their site. The whole setup might be done in bash session in 5 minutes.
Here is a quick example of setting up a SSL certificate on outdated Ubuntu 12.04 LTS:
-
Download
certbotscript. Certbot is an open source software to communicate with Let’s encrypt service via secure ACME protocol:wget https://dl.eff.org/certbot-auto chmod a+x certbot-auto -
Backup your Nginx config by copying your
*.conffiles from/etc/nginx/conf.d/somewhere. Then run:sudo /path/to/certbot-auto --nginxThis command will ask you several questions. In most cases, the default choice would be enough. It scans your current Nginx config and makes required changes. Finally, you will be prompted for submitting your email. Please enter an existing one since it requires confirmation. In a minute, check your inbox and follow the secret link to submit your account.
-
Reload Nginx service with something like
sudo service nginx restartOpen your site in Chrome, go to Developer console, “Security” tab, “View certificate” below the green label:
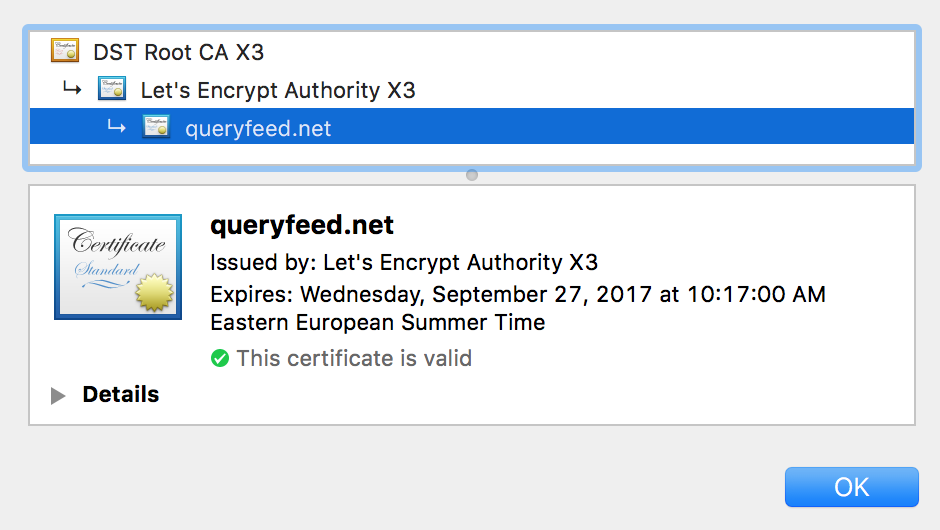
First, all the labels should be green but not red or orange. Second, “Let’s encrypt” authority should be noticed in the certificate’s details:
-
You have gone through the main steps so far, although it would be great to setup automatic update for your certificate. Add the following into
crontabconfig:0 */12 * * * /path/to/certbot-auto renew --no-self-upgradeThis job tries to update the certificate twice a day as the official guide recommends.
To find out more, please examine the Certbot documentation. It has nice setup wizard with step-by-step algorithms for all the operation systems. You may also automate Let’s encrypt not with bash script but within your favorite language. See the “Client options” page to observe existing libraries.
Finally, I urge you to enable SSL for your project right now if you haven’t done this yet. Nowadays, there cannot be an excuse for sending your client’s data as-is without encryption. Please respect your visitors. Setting up SSL has never been so easy as it is with Let’s encrypt nowadays.
-
-
Weekly links #25
Пишу вам из Турции. Держитесь, всего одно платье осталось!
-
Object-Oriented Declarative Input/Output in Cactoos
Instead of calling static procedures we want to use objects, the way they are supposed to be used.
-
Принципиальный недостаток Git CLI
Эмоциональный обзор недостатоков Гита.
-
«Медленный» секс — это как бы не горячо. Поэтому большинство людей и пытается оторвать своим любовникам пенис или клитор — им кажется, что это очень страстно, даже если их партнерам это не слишком приятно.
-
…ты будешь бедной лет до тридцати самое меньшее. Гарвард? Никого не волнует. Работы нет.
-
Инвестиции на бирже: популярные заблуждения
Азы инвестирования. Горячо рекомендую к прочтению.
-
-
On Clojure arguments
Sometimes, a function that we are working on needs to take lots of parameters. Not just one or two but a decade or even more. I used to face with such a problem many times. I’m not sure solutions made by me were always good enough.
You might be brave enough to say you will never face such an error. It’s probably a weird architecture. A function should accept at least five arguments. You will refactor such a code for sure.
But look at this:
def __init__(self, verbose_name=None, name=None, primary_key=False, max_length=None, unique=False, blank=False, null=False, db_index=False, rel=None, default=NOT_PROVIDED, editable=True, serialize=True, unique_for_date=None, unique_for_month=None, unique_for_year=None, choices=None, help_text='', db_column=None, db_tablespace=None, auto_created=False, validators=(), error_messages=None):It is from Django, the world-wide spreaded framework to build robust web applications. Except
self, the constructor takes 22 optional arguments. Saying more, it is just a basic abstract class. Its descendants require their own arguments in addition to default ones.Common languages such as Python, Ruby or Java give only one standard way to deal with lots of parameters. In fact, using them you cannot be mistaken since you have no other choice. The question here is how to make you code less ugly than it is now.
People who are new in Clojure, especially if they came from classical Python/Puby/PHP, face troubles when passing lots of arguments into a function. Since it’s Clojure, there are several ways to do that. This article highlights some on them, their benefits and disadvantages.
Multi-arity
Any function in Clojure may have more than one body with its own signature. That’s normal for any functional language, but sounds surprisingly to former Python/Ruby adepts. An interpreter dispatches that bodies by a form of arguments. The first found body is called. When no body is found, an exception is raised.
For example, the same function could be called with either two or three arguments if we declare it in such way:
(defn foo ([x y] (println "two arguments") (+ x y)) ([x y z] (println "three arguments!") (+ x y z))) (foo 1 2) 3 ;; prints `two arguments` (foo 1 2 3) 6 ;; prints `three arguments!`Calling a function with zero, one or ten arguments will raise an exception. Depending on your application’s logic, it could be both good or bad behaviour.
To fallback to default body that deals with any set of arguments, add one more implementation:
(defn foo ([x y] ... ) ([x y z] ... ) ([& args] (reduce + 0 args)))Now, you may add any arguments set together:
(foo 1 2 3 4) 10 (foo) 0The order of bodies is important. If you put
[& args]clause on the top, it will cover all the possible function calls. So you will never reach[x y]or[x y z]implementations.One interesting feature is you may redirect function call inside a body just calling the same function with another argument set. For example:
(defn test ([x y] (test x y nil)) ;; redirects to the second body ([x y z] (do-some-stuff x y z)))Clojure dispatches a proper body quite fast. It is a key feature of Clojure’s runtime. There are lots of core functions that declare two, three or even five bodies regarding to performance issues. It’s much faster then having a single body with multiple
ifs,caseorcondclauses.A quick copy-paste from Clojure sources:
(defn juxt "..." ([f] ...) ([f g] ...) ([f g h] ...) ([f g h & fs] ...))Multi-arity is great when you already have a function that takes a couple of scalar parameters and then you need to add some extra one ASAP. Usually, the most needed function is called in thousand places so adding an extra parameter everywhere would be a mess.
In Java or Python world, it is named “refactoring”. You need a robust commercial IDE to scan the project and change each call of a function. In Clojure, you just do:
;; old (defn test [x y] (do-old-stuff x y)) ;; new (defn test ([x y] (do-old-stuff x y)) ([x y z] (do-new-stuff z) (do-old-stuff x y)))Now you can keep the old calls without changing your code. And pass the new argument only where you need.
Maps
Your function may need lots of additional arguments. For example, boolean flags, extra options for HTTP connection, timeouts, headers, error messages.
A good way to solve the problem is to join them into a single map. Thus, your function accepts only a couple of required parameters and the rest are put into an optional map. Say, you pass a hostname and a method name and a map with
:timeout,:headerskeys on so on.Inside a function, you either take optional arguments one by one:
(defn foo [hostname port & [opt]] (let [timeout (:timeout opt) headers (:headers opt] (http-request hostname port timeout headers) ...)or decompose a map on separated variables at once:
(defn foo [hostname port & [opt]] (let [{:keys [timeout headers]} opt] (http-request hostname port timeout headers) ...))Decomposition works as well on the signature level. I do not like this method though since it brings some noise in the code:
(defn foo [hostname port & [{timeout :timeout headers :headers}]] (http-request hostname port timeout headers) ...)A good point there is you may keep a default map somewhere and merge it with the passed ones to fallback to default values:
(def foo-defaults {:timeout 5 :headers {:user-agent "Internet Explorer 6.0"}}) (defn foo [hostname port & [opt]] (let [{:keys [timeout headers]} (merge foo-defaults opt)] ;; now timeout is always 5 when not passed ... ))This way of passing a map is widely-spreaded across Clojure libraries. It even considered as the standard one because of its simplicity and transparency. If you have just started with Clojure and need a function with multiple arguments, use a map.
Rest arguments as a map
There is another way to deal with multiple arguments. Do you remember the
restarguments prepended with&in a function signature? Something like that:(defn foo [& args] ;; args is a list) (foo 1 2 3 4) ;; args is (1 2 3 4)Starting with Clojure 1.5 (or 1.6, I don’t remember exactly) you may turn the rest arguments into a map. The syntax is:
(defn foo [& {:as args}] ;; now, args is a map! args) (foo :foo 1 :bar 42) {:bar 42, :foo 1}Pass extra arguments remembering some simple rules:
- there must be even number of rest arguments, otherwise you will get an error;
- each odd argument (usually a keyword) is a key;
- each even argument is a value;
- you cannot duplicate key items.
Turning rest arguments into a map is also used oftenly in Clojure. You may choose that method over a map as well when developing with Clojure.
Pure map vs rest args
Each of two method described above has its own benefits and disadvantages. Let’s highlight some of them:
-
Using a map is good when you don’t know exactly what arguments you will pass into a function. It’s a common situation when the final set of options is unknown for the last moment. It might depend on user input, environment variables or any conditions. Usually, you compose a map step by step, validate it with somehow and pass into a function. With sequences, it’s more difficult to compose a set of arguments.
-
Passing a map into a function with the
& restsignature requires some additional steps. You should flatten you map into a vector or sequence and then apply it to a function:(def opt {:foo 42 :bar [1 2 3]}) ;; your options map (defn foo [& {:as args}] ...) ;; but the function accepts rest arguments ;; turns opt to a seq of (key1 val1 key2 val2) ;; then apply it to the function (apply foo (mapcat identity opt))Note how long is the code. Probably, you’d better to modify the function to accept just map.
-
With the rest arguments,
partialworks like a charm. Say, we have a function that returns a set of rows from the database. The first argument is a table name, and the rest are a sequence with each odd argument as a column name and even argument as a value:(db-query :users :active true :staff true :name "Ivan") ;; performs a query like: ;; select * ;; from "users" ;; where ;; active ;; and staff ;; and name = "Ivan"Some of our users could be blocked. We may forget passing
:active falseclause every time you query for users. To prevent returning blocked ones to the frontend, it’s better to have a special function for that:(def active-users (partial db-query :users :active true))In addition to this constraint, we might be interested in only staff users. Let’s extend our function with another partial application:
(def staff-active-users (partial active-users :staff true))Finally, we may select all the non-blocked staff users whose name is Ivan:
(staff-active-users :name "Ivan") ;; [{:id 1 :name "Ivan" :surname "Petrov"} ;; {:id 1 :name "Ivan" :surname "Sidorov"}] -
Instead, with maps you cannot declare a partial function. You need to invent your own
partial-mapimplementation:;; let `foo` is a function that accepts a map (defn foo [opt] opt) ;; our own `partial` (defn partial-map [f defaults] (fn [opt] (f (merge defaults opt)))) ;; example: (def foo-timeout (partial-map foo {:timeout 5})) (foo-timeout {:bar 42}) {:bar 42 :timeout 5}
Conclusion
The examples above show there are more then one way to deal with multiple arguments in Clojure. These are multi-arity, maps and rest arguments. All of them cover you common requirements as well.
Remember, you are not limited with the only three those ones. With macroses, you can implement you own arguments system: Common Lisp-wise or any other. The only limit there is your imagination.
-
Нелюбовь

Посмотрел Звягинцева.
Переполняют чувства, но писать рецензии как Носик я не умею, поэтому буду краток.
Великое кино. Шедевр от вступительных титров до последнего кадра.
Поражает невероятная точность, натуральность сцен, поведения, реплик. Кажется, ни одна деталь реальности не ушла от режиссера, в том числе интимные подробности. Но они не перетягивают на себя лишнее внимание. Напротив, еще сильнее утверждают правдивость происходящего.
Очень реалистичны персонажи, фразы, поведение. Приемы, к которым они прибегают, чтобы обманывать себя и окружающих. Ощущение, что смотришь в микроскоп, только вместо капли воды – московская семья, средневзвешенный элемент российского общества.
Бывает, мы говорим: это было как в кино. То есть волшебно, непонятно, не так как мы привыкли. А у Звягинцева – как в жизни. И это пугает, потому что понимаешь, что все происходящее может завтра случиться с тобой.
Так же столкнешься с бездействием ментов, произволом на всех уровнях, офисным рабством, пасьянсом “косынка” в ожидании обеда. Православным начальстом, греющим руки на строительстве храма.
И конечно, недостатком внимания к тем, кто рядом и заслуживает этого.
Каждую сцену можно просматривать бесконечно: включается латентный вуайерист. Словно подглядываешь за чьей-то жизнью, и все фейлы, измены видны, как день.
Сцена с Киселевым и Украиной следует за сценой с моргом. Обе они дают декартово произведение ужаса и тоски. В тот момент в кинотеатре я почуствовал, будто в сердце что-то воткнули.
После просмотра я точно понял, чего хочу в широком смысле. Быть счастливым. В нелюбви и в несчастье нет дна.
-
What to read #24
-
Interesting notes on how to improve your Clojure code.
-
I never write when I get a good idea. I only try to write when I find suitable resource to illustrate that idea.
-
Self Publishing for the Creative Coder
So, you have an idea for a fiction book. First, let me tell you that it’s a good idea and it’s a great thing that you are a coder.
-
Фотографии гонконгских квартир-клеток.
-
Сергей Король о гендере и пр.
Ну и вообще готовьтесь. Кажется, общество скоро будет прилично штормить из-за этой фигни.
-
Noize MC - Чайлдфри (feat. монеточка)
Прекрасный клип.
-
-
Does any program really have an unlimited number of bugs?
I really enjoy reading Yegor’s blog. He brings quite interesting ideas regarding programming and business. But sometimes, the thoughts he shares there look a bit strange to me. I’m talking about one of the latest posts titled “Any Program Has an Unlimited Number of Bugs”.
I’m writing this in reply to Yegor’s points mentioned there. Please read them first. To focus on the key notes, let me quote the most sensitive part:
Let’s take this simple Java method that calculates a sum of two integers as an example:
int sum(int a, int b) { return a + b; }How about these bugs:
- It doesn’t handle overflows
- It doesn’t have any user documentation
- Its design is not object-oriented
- It doesn’t sum three or more numbers
- It doesn’t sum double numbers
- It doesn’t cast long to int automatically
- It doesn’t skip execution if one argument is zero
- It doesn’t cache results of previous calculations
- There is no logging
- Checkstyle would complain since arguments are not final
Well, the points highlighted above make me really uncertain about what really Yegor meant. And since he didn’t answer me in the commentary section, I will put my thoughts on that in my own blog.
Let’s look closer at some of them.
It doesn’t have any user documentation
The question is, do you really think we need documentation for
sumfunction? What will you put there? I cannot guess nothing other thanIt adds two integers. So what the reason for having it in our code?In a previous project, I had a teammate who was a fan of docstrings. Every module, a class or a method should have a docstring, he said. The code he wrote looked like a school composition. You could not ship your code without his comments something like “add docs here and there plz”.
Since our product was developing rapidly, we had to change the code all the time. Surely, we used to forget to update those docstrings because it took extra time. It was even worse because the docstrings didn’t tell the truth anymore. Nobody believed them as a result.
What we need
sumdocumentation for? How should it look like? Who will read this documentation? A user? I doubt it. A programmer? Even programmers need not a machinery-generated HTML made of docstrings, but human-written manuals with examples and snippets.When you open a particular GitHub project, what do you do first? Reading the code? No, you scroll down for
READMEor click onWikilink. Digging the source code is the last thing you would make if something works not well.Let’s recall what does one say on DOOM III source code and ID Software code standards in general:
Code should be self-documenting. Comments should be avoided whenever possible. Comments duplicate work when both writing and reading code. If you need to comment something to make it understandable it should probably be rewritten.
Its design is not object-oriented
We all know Yegor is passionate by OOP. But really, naming a function buggy just because it’s non-OOP designed is not fair.
What would happen if we had an OOP version of
sumfunction? I can imagine something messy like this:Adder adder = new Adder(); adder.setA(1); adder.setB(2); Integer result = adder.getResult() // 3We’ve got lot more problems here. The number of lines grew up from 1 to 4 (compare to
add(1, 2)). In addition, nowadderobject also keeps it’s own state. How may I track whether.setAwas called or not? What will happen if I forget to put.setBin my code? Will it get aNullvalue or an exception raised?What will happen if I share
adderobject across multiple threads so they callsetA,setBandgetResultsimultaneously? Nobody would predict the result.Functional programming teaches us to avoid having state and keep the things simple. Having a small function without any state rather than manipulating with objects will pay off for sure.
It doesn’t sum three or more numbers
Surely, if you a Java programmer, you’ve got a problem. Because there is nothing you can do without rewriting the code. But if you are aware of FP-style and you have your
addfunction, you simply do:(reduce #'add (list 1 2 3) :initial-value 0) ;; common lisp (reduce add 0 [1 2 3]) ;; clojureor, in Python:
reduce(add, [1, 2, 3], 0)This is definitely the right way with
reducealso known asfold. You don’t need to write a function that adds million of integers. Instead, you add just two! Andreducewill care of how to spread it across a sequence of data.That’s normal to focus on simplest cases and primitive operations first. Then you build abstractions with high-order functions based on primitives. It makes the code easier to understand and debug.
It doesn’t sum double numbers and It doesn’t cast long to int automatically
I don’t know if it is really a bug. On the one hand, it would be great to have a function that adds everything. Again, within any Lisp dialect or Python I may have it easily. Instead, with static typing you have to write more code.
But on the other hand, having exact
integertypes might be some kind of specific requirement made by design. It could be an utility function that adds to years or any numbers that do not exceed a couple of thousands. So it’s difficult to judge without a full context (I’ll say more on that below).It doesn’t skip execution if one argument is zero
I really doubt it will increase the performance. Adding zero to an integer costs really nothing on modern hardware. The compilers are smart enough to deal with such cases. But putting an extra
ifclause will definitely increase the number of instructions because now your program makes a comparison step.This is exactly what did Knuth say about preliminary optimization. You don’t even have any metrics about what runs faster: adding zero of extra
ifstatement. You even don’t now how frequently your function will be called with zero argument. I might be 1 time per 100k calls so your trick is made in vain in that case.It does not worth it, after all.
It doesn’t cache results of previous calculations
I’m sure any cache system brings as many problems as it solves. First, where would you store that cache? In application’s memory? In Memcache? User’s cookies?
Then, you program could sum million of numbers per second. Every cache call needs al least
O(C)orO(logN)time to lookup a value. You will slow down your program dramatically with such approach when caching small functions.There is no logging
The same claims are here: what exactly are you going to log? Who will read that logs and how often? For what purpose you want to store such kind of logs? Where would you store such amount of logs? Did you estimate the slowdown that you will bring to your system by adding logging? What if some of Ops team would misconfigure logging system and add email handler to that logger? Or sending SMS message?
Finally, this function is taken completely out of the scope so it’s impossible to judge on its quality. We should never examine a single function but only their composition instead. Every function has its own weaknesses and strengths. Linked together properly they build a system. In such a system, weakness of any specific function is supported by another function that validates data, filters input params, cleans up system symbols and so forth.
What I want exactly to say is there is nothing criminal in such a function that adds to integers. If it’s surrounded with another function that ensures that both numbers are really integers, there is no need to do all that validations again when adding them. In our projects, we usually separate our application on several levels. On the top level of the application, threre is one that validates the input data. If they are fine, functions on the next level operate on them as well.
In conclusion, please avoid using word “bug” when you talk about lack of logging or caching. Probably you don’t need that stuff. Keep functions free of having state and producing side effects. When you afraid of the data you use may be incorrect (Nulls, overflows), don’t rush into adding nested
ifs. You’d rather update your validation logic first. -
Об авторском праве
Коллеги заспорили о проблемах копирайта: можно ли качать торренты или нельзя, воруешь ли ты при этом или нет и так далее. А я решил сесть и записать все, что думаю по этому поводу.
Главная проблема авторского права состоит в том, что до недавнего времени люди мерили собственность и богатство материальными единицами. Долларами, квадратными метрами, тоннами. В классическом предствалении богач – это тот, у кого чего-то много. Это самое “много” легко представить или изобразить. У богатого человека большой дом, огромная фабрика, мощный параход.
В материальном мире одна и та же вещь не может существовать дважды. Поэтому у каждой вещи только один владелец. Если у человека забрать что-то материальное, это сразу станет заметно. Так ввели понятие кражи, определили институты закона и суда. Человек додумался до этого еще несколько тысяч лет назад. Базовые нормы общества вроде “не укради” опираются на аналоги, разработанные в Древнем Риме.
Цифровые технологии изменили восприятие собственности. Впервые человек столкнулся с тем, что определенный тип материи может быть скопирован практически бесплатно. Это вкорне противоречит привычной модели материальных благ. Чтобы скопировать устройство, например, зарубежный фотоаппарат, подводную лодку или атомную бомбу, нужны ресурсы, намного превышающие затраты на постройку оригинала.
Индустрия не была готова к такому феномену и до сих пор пребывает в фазе медленного перехода к чему-то осмысленному. Этим объясняются случаи нарушения прав человека, баснословные штрафы, судебные тяжбы.
Мысль о бесплатном копировании чего угодно пугает неопределенностью. Мы привыкли, что любой ресурс конечен. Среднестатический человек тратит четверть жизни на обучение, чтобы устроиться на работу и поддерживать материальное состояние. Тысячи людей по всему миру живут только затем, чтобы к вечеру заработать на еду.
Идея неограниченного копирования сродни идеи о бессмертии или полете. Никто не знает, что станет с человечеством, если подобное случится. Но нетрудно предположить, что мир кардинально изменится, причем не в лучшую сторону для тех, кто сейчас в выигрышном положении.
Рассуждая об объектах авторского права, стоит признать, что принцип дешевого копирования заложен в них изначально. Примерно как метод половинного деления заложен в живой клетке, но не автомобиле. В рассуждениях об авторском праве нельзя ссылаться или приводить аналогии на материальные ценности: колбасу, золото и т.д.
Регулярно возникают случаи нарушения авторских прав, и я хотел бы поговорить об этом подробней. Некоторые аспекты копирайтинга мне кажутся спорными. Да, они утверждены законом, но только одно это не мотивирует их соблюдать, поскольку закон относителен. Одно и то же может быть нормой в одной стране и преступлением в другой. Скажем, ловля покемонов в храме или съемка порнографии.
Прежде всего, я ставлю под сомнение законность передачи авторского права по наследству или в дар. Оно не должно автоматически переходить в собственность родственников: детей, внуков. Это вредит всем участникам. Наследник получает актив, к которому он не прикладывал ни малейших усилий. Отношение к нему соответствующее: пусть лежит и приносит деньги. Поскольку юридические владельцы не наследуют таланты первичного автора, развитием продукта они не занимаются.
Что касается игр, здесь ситуация однозначно меняется к лучшему. Еще 10 лет назад было нормально качать торренты, переписывать игры на болванки, искать кряки и серийные номера. А сегодня есть Стим, который свел пиратство игр на нет. Благодаря Стиму среди моих знакомых не осталось никого, кто бы ставил игры из неофицальных источников.
К сожалению, ситуация с фильмами не развивается столь же положительно. В киноиндустрии бытует ошибочное мнение, что если фильм утечет в сеть, зрители посмотрят его дома и не пойдут в кинотеатры. Это не отвечает реальности. Поход в кинотеатр отличается от домашнего просмотра атмосферой. Впечатления от большого экрана мощнее, а поход в кино – отдельное событие. Хороший повод разнообразить отдых, сходить на свидание, собраться друзьями – да мало ли что еще.
С момента изобретения кино некоторые эксперты пророчили смерть театрам. Зачем ехать в вечернее время в центр города, наряжаться, соблюдать этикет? С изобретением телевидения даже потребность в кино отпадает, утверждали эксперты. Все можно посмотреть дома. И тем не менее, театры востребованы. У кого есть дети, знают, что брать билеты на спектакли нужно за месяц вперед: раскупают мгновенно.
Аналогично с концертами и фестивалями. Если предложить фанату вернуть билет на выступление любимой группы с предложением посмотреть на экране, он просто покрутит пальцем у виска.
Невозможно сейчас вспомнить фильм, чей кассовый сбор значительно бы пострадал от утечки в сеть. Сразу же после премьер в кинотеатрах торрент-трекеры наводняют кам-рипы – снятые на скрытые камеры копии. Опять же, нет никаких показателей, как это влияет на прибыльность фильма. По моему опыту, камрип – это вынужденная мера, когда достать более достойную версию физически невозможно. Но в наше время это уже не актуально.
Поиск фильма по фразе “смотреть онайн бесплатно” перебрасывает человека на сайты, увешанные баннерами и виджетами. Экран застилают предложения что-то увеличить. Подобным сайтам, в общем-то, все равно, что пользователь уходит. Главное – скормить ему максимум рекламного трафика. В следующий раз пользователь все равно прилетит из Гугла на этот же сайт или его зеркало в поисках другого фильма.
Как бы ни был безграмотен в компьютерном плане пользователь, он догадывается, что такое положение дел неправильно. Это как будто закрылись магазины, и ты ходишь по барыгам.
Вопрос, почему полулегальные сайты стоят в выдаче поисковика выше официальных? Неужели у поборников авторских прав нет денег на раскрутку?
Да, некоторые фильмы можно легально просмотреть на Ютубе, купить в магазинах Эппла и Гугла. Но опять же, новинки попадают туда с опозданием. Другой минус состоит в том, что покупая там, пользователь очень стеснен в выборе и правах.
В онлайн-магазине вы не можете выбрать языковую дорожку. Ваш аккаунт намертво привязан к стране и правовым нормам, которые запрещают купить фильм в оригинальной озвучке, если вы, например, из России. Только дубляж. Никому не интересно, что ты учишь английский или французский. Я помню, лет 15 назал покупатели массово требовали русский язык в пиратских релизах. Сегодня, наоборот, чтобы скачать английскую версию, пользовтель вынужден серфить торренты.
Я в корне не согласен с тем, что нельзя выбирать локализацию продукта.
Защитники авторских прав утверждают, что терпят колоссальные убытки от пиратства и торрентов. Называют колоссальные цифры, рассказывают, кто из музыкантов сколько недополучил. Подвох кроется в том, что ни в одном отчете не сказано, как именно считались убыки и как они структурированы в принципе.
Помните, как считали потери в Микрософте? Брали число школьников, у которых дома пиратская Винда’98 и умножали на стоимость лицензии. Получали дутые суммы, в то время как никаких убытков не было. Напротив, именно пиратские версии заполонили компьютеры пользователей. Со временем пользователи легализировались. Люди взрослеют, у них заводятся деньги, и с какого-то момента человеку становится проще купить коробку и вбить номер с нее, чем лазить по левым сайтам в поисках ключа.
Статисты с маниакальной тщательностью подсчитывают убытки от нелегальных копий, но игнорируют вопрос: купил ли бы продукт пользователь, если бы действительно не имел доступа к пиратскому контенту? Вспоминая детство, однозначно отвечаю нет.
Не учитывается факт, что сегодня, при наличии быстрого интернета и свободного места на дисках, много фильмов, музыки и игр скачивается просто так. Синдром Плюшкина: скачаю, а потом, может быть, послушаю-посмотрю. У каждого из нас есть на компьютере папочка с пиратскими книгами и фильмами, до которых мы никогда не доберемся из-за нехватки времени. Книга качается 10 секунд, а читать ее нужно месяц. Игра установлена, но некогда даже посмотреть вступительный ролик. Поэтому умножать стоимость фильма на число скачиваний просто нелепо.
Поборники авторских прав проникли в современные облачные технологии. Поскольку каждое устройство подключено к сети и непрерывно держит связь с сервером, любой купленный продукт может быть отозван, а устрйство – заблокировано. Описаны случаи, когда при пересечении границы Гугл удалял с планшетов электронные книги. Вам нельзя читать их на территории этой страны. Извините, лицензионное соглашение. Вот вернетесь – скачаются заново.
Идея о том, что нельзя что-то читать, слушать или смотреть при перемещении на несколько сотен киломентров, кажется мне сошедшей со страниц 1984.
В какой-то момент Айтюнс удалил с моего телефона честно купленный альбом. Не было ни писем, ни смс. Эппл не посчитал нужным сообщать о причинах проишествия. Ссылки на альбом ведут в никуда. Конечно, через 15 минут я скачал торрент.
Игроки-пользователи Стима и Близзарда отмечают схожее поведение компаний при переезде в другие страны. Как только россиянин входит в Стим из США, аккаунт блокируется. Начинается долгая тяжба по его восстановлению. Формально это объясняется проверками на взлом, но, по неофициальным данным, реальная причина связана с правовыми нормами и лицензионными соглашениями.
Права на игру, выпущенные в одном регионе, не тождественны правам на ту же игру в другом регионе. В теории, они могу быть равны, но чтобы точно убедиться, нужны человеческие ресурсы, помощь юристов. Чем больше игр купил пользователь, тем сложней ситуация. В случае ошибки засудят на крупные суммы. Поэтому фирмы затягивают восстановление аккаунта и неформально подталкивают пользователя к регистрации нового с повторной покупкой тех же игр, но уже изданных в США.
Нужно понимать, что любой продукт, даже самый коммерческий, со сременем становится частью культуры, в рамках которой он создается. Любая человеческая мысль, сюжет или персонаж является компиляцией чужих идей и образов. Например, писатель находит вдохновение в прогулках по парку. Обязан ли он платить фирме, занимающейся содержанием парка? Или автор написал интересную книгу. Как быть с тем фактом, что другие люди прочли ее, сформировали мнение, поделились эмоциями, посоветовали друзьям ее купить?
Эти процессы невозможно отследить, посчитать и выразить в национальной валюте. Правообладателям выгодней о них забыть. Использовать их в дискуссии невозможно.
Представьте себе, что внезапно ожили древние римляне и потребовали выплат за использование имен богов в названиях космических кораблей и студий красоты. Кирилл и Мефодий запросли авторские отчисления за кириллицу. А чтобы выплатить гонорар изобретателю колеса за каждый факт его применения, у человечества не хватило бы суммарных денег.
Поскольку широкая аудитория есть главный потребитель фильмов, игр, книг, с ней нужно считаться. В этом смысле толпа ведет себя как жидкость: если сжимать в одном месте, давление передастся в другое. Иначе говоря, систематически расстраивая потребителя ограничениями и штрафами, поборники авторских прав подталкиваю его к пиратскому контенту.
Копирайтеры, возможно, видят мир немного иным, где каждый озадачен проблемой легальности. Перед просмотром фильма или кликом по ссылке пользователь взвешивает: не нарушаю ли я права, а если да, то чьи и на какую сумму. В реальности потребитель бесхитростен и совершенно безграмотен в этом вопросе. Если браузер показывает, значит, смотреть можно – вот его аргументы.
Возможно, кто-то догадывается, что качать фильмы с сайтов с рекламой казино нелегально. Но обычно у людей нет на это времени. У них работа, дети, вечный завал. Проблемы нарушения авторских прав не в их мире. В онлайн магазине форма регистрации занимает два экрана, а тут бесплатно.
Задача индустрии в том, чтобы сделать качественные сервисы с удобной навигацией и оплатой. Чтобы они всплывали в поисковиках раньше полулегальных сайтов. В идеале, последние вообще должны исчезнуть с первых страниц выдачи Гугла и Яндекса и стать уделом маргиналов.
Легко видеть, что проблема не имеет однозначного решения. Даже на то, чтобы связно выразить точку зрения, ушло несколько дней. Не называйте ворами тех, кто качает торренты, умерьте пыл. Возможно, прямо сейчас вы нарушаете дюжину лицензионных соглашений, которые промотали в момент установки, а там было анальное рабство.
Правильное решение придет со временем.
Writing on programming, education, books and negotiations.