-
Такой же
Наверное, вы слышали вопрос о корабле, заданный еще до нашей эры. Если постепенно заменить в корабле все детали, будет ли это тот самый корабль?
Проблема в том, что на вопрос отвечают, не разобравшись с определениями. Если не договориться, что значит “тот же самый”, можно спорить весь день, имея в виду не то, о чем думает оппонент.
В программировании эта проблема известна: равенство не означает “то же самость”. В современных языках есть отдельные операторы для сравнения указателей и сравнения значений. Хорошие языки пытаются избежать путаницы и сводят две эти вещи к одной. Например, если коллекции неизменяемы, то их можно сравнить в лоб, не заботясь о ссылках. Кроме того, хеш неизменяемой коллекции рассчитывается один раз при создании. Из-за этого сравнение не делает полный обход, а сводится к равенству двух чисел.
Еще один довод в адрес “то же самости” — это мы сами. Тело человека обновляется постоянно. Скелет меняется за три года, а у кожи, волос и ногтей срок исчисляется днями. Жидкости поступают и выходят.
Мы сегодня и мы три года назад — это разный набор атомов. Тот человек, что изображен в паспорте, уже сотни раз обновил каждую клетку организма. Однако ни у кого нет сомнений, что человек в паспорте и вы — один и тот же. Просто потому что так удобней.
Поэтому и корабль, в котором обновили все доски, тот же самый. Если, конечно, понимать под “тем же самым” то, что удобно большинству.
Забавный эпиграф к библиотеке re-frame8:
This, milord, is my family’s axe. We have owned it for almost nine hundred years, see. Of course, sometimes it needed a new blade. And sometimes it has required a new handle, new designs on the metalwork, a little refreshing of the ornamentation … but is this not the nine hundred-year-old axe of my family? And because it has changed gently over time, it is still a pretty good axe, y’know. Pretty good.
Вкратце: господин, этот топор служит нашей семье девять столетий. Иногда ему меняли рукоять, а иногда клинок. Но поскольку это делали постепенно, это все тот же топор.
В этом и проявляется забавное свойство “той же самости”: если ее размазать по времени, предмет будет тем же самым (менять ручку и клинок раз в сто лет). Если потерять топор и заказать новый, это будет другой топор.
Принцип плавных изменений очень полезен. Например, ничто не бесит так сильно, как внезапное обновление интерфейса. Хорошо, когда его плавно меняют в нужном русле.
Команда может саботировать новые правила, если их слишком много. Внедряйте по одному с интервалом в месяц.
Добавить линтер в огромную кодовую базу кому-то покажется невозможным. А нужно всего ничего: задать список путей, которые подвергаются линтингу, и плавно его наращивать.
В завершение — пазл, который висит у меня на стене (Яцек Йерка):

-
Письма Notion
К сожалению, в компании, где я работаю, пользуются Ноушеном. Это сплошная боль, потому что к Ноушену у меня нулевая терпимость — бесит каждый элемент, каждая кнопка и анимация. Постепенно собираю коллекцию их косяков, чтобы запостить разом, но сегодня не удержался от нового прокола.
Итак, я написал текст в Ноушене и попросил руководство обсудить. На следующий день открываю почту на телефоне и вижу штук 20 уведомлений от Ноушена: пошли комментарии. Тыкаю, чтобы прочитать. А письма, сюрприз, выглядят так:
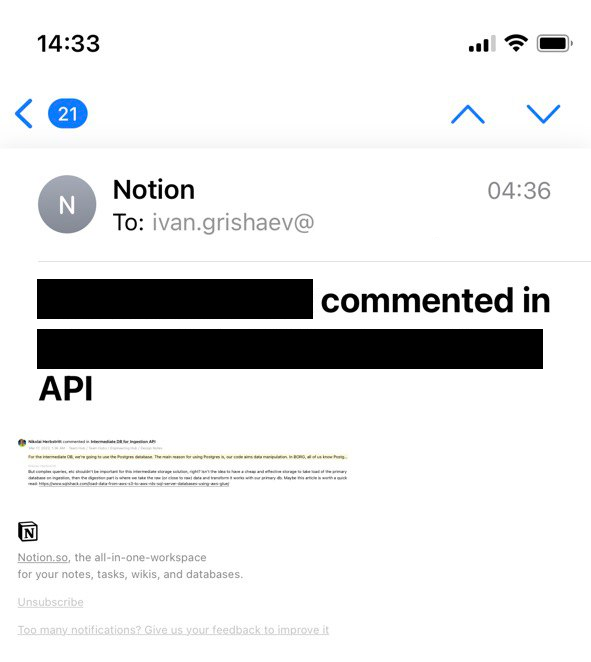
Не знаю какой это кегль — второй или третий — но прочесть эти письма физически невозможно. Нужно зрение орла или увеличительное стекло. Словом, с телефона я ничего не прочел и смог это сделать только когда сел за комп с 4к-монитором.
И вот опять, смотрите: сапожник без сапог. Как мы помним, Дропбокс, программа для работы с файлами, не умеет показывать файлы. А Ноушен, программа для текста, не может показать текст. Разработчики, вы вообще своим Ноушеном пользуетесь? Если бы я там работал, то в первый же день открыл бы тикет и долбил им каждый спринт — ваши сраные письма не читаются. Поправьте стили. Высылайте plain text вместо HTML, он мне нахрен не сдался. Просто чтобы можно было прочесть текст.
Директор Ноушена без конца гонит какую-то графоманию, которую постят на Хакер-ньюз и Хабре. Подобно Грефу внедряет искусственный интеллект и машинное обучение (которые дают пустую строку). И при этом никто сделает нормальный шрифт в письмах. Просто стыд.
-
Эта удивительная Clojure: что на ней разрабатывают, чем она отличается от других языков и подходит ли для входа в программирование
Эта статья была написана для одного издания, но по ряду причин ее не опубликовали. Размещаю здесь, чтобы материал не пропал. В подготовке статьи участвовали:
- Павел Пеганов и Иван Гришаев, программисты;
- Маша Даровская, редактор.
Мы расспросили разработчиков на Clojure из сообщества clojure_ru. Выясняли, как применяют язык, что на нём пишут, легко ли на нём программировать.
Что программируют на Clojure
Павел: сфера применения Clojure в техническом плане — в основном веб и серверные приложения. На успешно работающий Clojure-код можно посмотреть, например, в продуктах Metabase и Penpot, их исходный код открыт.
Но постепенно язык проникает и в другие области. ClojureScript работает в браузерах и других средах для JavaScript, с помощью проекта Esprit его уже запускают на микроконтроллерах, а сейчас развивают ClojureDart, чтобы захватывать мир Flutter. Конечно, не все эксперименты в итоге «взлетят», но такое разнообразие работающих проектов показывает, что применимость языка ограничена скорее настроениями разработчиков, чем самим языком.
Если говорить о предметных областях, то в вакансиях и проектах с Clojure, о которых слышу я, эмпирически кажется, что финтеха больше, чем прочих. Даже компания, поддерживающая Clojure, Cognitect, принадлежит банку Nubank. Но кроме финтеха областей тоже хватает.
Иван: сфера применения Clojure широка, она решает те же задачи, что Java, Python и другие языки. На ней пишут сетевые сервисы, бэкенд веб- и мобильных приложений. Clojure подходит для обработки данных из разных источников — баз данных, очередей, HTTP API — и часто служит их оркестратором.
Существует ClojureScript — компилятор кода на Clojure в JavaScript. С его помощью создают браузерный фронтенд и мобильные приложения на базе React Native.
Код на Clojure можно скомпилировать при помощи GraalVM и native image, получив бинарный файл. С этим подходом пишут утилиты командной строки, интерпретаторы, AWS Lambda и многое другое.
-
Сбер
Постоянно пользуюсь Сбером, чтобы оплатить что-нибудь по QR-коду. Каждый раз удивляюсь анимации вверху экрана. За каким-то хреном кнопка с QR не зафиксирована, а выезжает справа. Как в рекламных полях, где анимацию делают ради анимации: что-то выехало, покачалось, мигнуло. Типа, управление вниманием.
Зачем? Кто просил эту анимацию? На автомате тычу в левый угол, клик приходится на другой элемент, открывается что-то не то. Ясное дело, все тормозит, потому что параллельно загружаются другие виджеты.
Если функция кнопки известна заранее, а также ее текст и оформление, никакой анимации не нужно. Может, балбесу-дизайнеру из Сбера нравится: у него эмулятор на мощной тачке, запущено одно приложение, все плавно. А потребитель видит слайдшоу и промахивается кнопкой.
Дорогие дизайнеры!
Засуньтеуберите ваши анимации подальше. Они не нужны, вы делаете лишнюю и вредную работу. -
The Mask library for Clojure
(This is a copy of the readme file from the repository.)
Mask is a small library to prevent secrets from being logged, printed or leaked in any similar way. Ships tags for Clojure, EDN and Aero.
Why? Because I’ve been in such a situation three times, namely:
- We don’t mask the secrets.
- Someone logs the entire config.
- Secrets have leaked!
- Rotate all the keys, tokens, etc.
- Change the team and face the same.
This library is an attempt to break this vicious circle.
Installation
Leiningen/Boot:
[com.github.igrishaev/mask "0.1.0"]Clojure CLI/deps.edn:
com.github.igrishaev/mask {:mvn/version "0.1.0"}Usage
The
mask.corenamespace providesmaskandunmaskfunctions. Pass a value tomaskto make it safe for logging or printing in REPL:(in-ns 'mask.core) #namespace[mask.core] (def -m (mask "Secret123")) -m << masked >> (str "The password is " -m) "The password is << masked >>"Masking is idempotent meaning that you can mask the same value multiple times but the result will be one-level masked value:
(-> -m mask mask mask) << masked >>To release a value from a mask,
unmaskit:(unmask -m) "Secret123"Unmasking is idempotent a well:
(-> -m unmask unmask unmask) "Secret123"Note: the library treats
nilas an error value that cannot be masked. You’ll get an exception:(mask nil) Execution error (IllegalArgumentException) at ... (core.clj:34). Cannot mask a nil valueMasking an empty value signals you’re doing something wrong. Most likely you’ve missed a corresponding key or an environment variable. Thus, the further work makes no sense.
Spec
The
mask.specmodule provides the::maskspec that checks if a value is really masked. An example from the tests:(let [config {:username "Ivan" :password #mask "secret"}] (is (s/valid? ::config config))) ;; trueClojure tag
The built-in
#masktag wraps any value with a mask:=> {:token #mask "abc123" :password "SecretABC"} {:token << masked >>, :password "SecretABC"}EDN tag
There is a
reader-ednfunction that acts like an EDN reader for the same tag:(let [source (-> "{:foo #mask 42}")] (edn/read-string {:readers {'mask reader-edn}} source)) ;; {:foo << masked >>}Aero tag
To extend Aero with the
#masktag, import themask.aeronamespace:(require 'mask.aero)Then read a config with the tag:
;; config.edn {:foo #mask #env "SOME_PASSWORD"} ;; code (aero/read-config (io/resource "config.edn")) ;; {:foo << masked >>}The Aero dependency is not included. You’ve got to provide it by your own.
Ivan Grishaev, 2023
-
Эй
Почему-то большие компании не могут нормально составить письмо на русском. Будут ошибки или нелепые обороты. Сегодня получил письмо от Дискорда, где ко мне обращаются на “эй”:
Сам ты эй! Понятно, это дурацкая калька с английского hey. Почему не нашли русского чувака, чтобы показать ему перевод перед отправкой? В больших фирмах всегда найдется русский, украинец, поляк или венгр. Даже если он кодер, пусть посмотрит. Он скажет, что обращение на эй в русском не только неестественно, но даже грубо.
Жаль, не сохранил скриншоты Гугла и Godaddy. Иной раз такую дичь присылают, что хватаешься за волосы. Сейчас реже, но все равно.
-
Silent Hill 2
Появился трейлер переиздания Silent Hill 2 — одной из главных игр моего детства. Наверняка вы его смотрели, но вот на всякий случай:
Графика выше всяких похвал, сказать нечего. Однако у меня вопрос — что не так с этим трейлером? Не проматывая вниз, постарайтесь подумать.
-
Праздники
Не люблю праздники посреди недели. Скажем, по четвергам я хожу в зал, но завтра он не работает. Что мешает администратору прийти и открыть дверь, непонятно. И вообще — чем этот четверг отличается от других четвергов? Ничем, кроме дурацкого обычая, что в какой-то день вместо работы валяют дурака.
Хотел переставить на среду, но оказывается, что у жены на работе поменяли смены из-за предпраздничного дня. У старших детей укороченные уроки, и нужно ехать за ними раньше обычного.
Вот и думаешь: стоило ли переставлять кучу дел из-за одного праздника? Кому вообще всрались эти 23 Февраля, 8 Марта, Дни единства и все такое? Кто эти люди, что их празднуют? И как?
Выгоду от праздников получают только дети, потому что не надо идти в школу. Взрослые, даже если они бюджетники, должны что-то переставлять и отрабатывать, что еще то мучение и нарушение ритма.
Считаю, любой праздник должен автоматом переноситься на ближайший выходной — празднуй сколько хочешь, а другим не мешай работать. Исключение из этого правило одно — Новый год, его празднуют строго по календарю. Но это и так очевидно.
-
The DynamoDB library for Clojure
(This is a copy of the readme file from the repository.)
This library is a driver for DynamoDB written in pure Clojure. No AWS SDK, lightweight dependencies, GraalVM-friendly.
Benefits
- Free from AWS SDK. Everything is implemented with pure JSON + HTTP.
- Quite narrow dependencies: just HTTP Kit and Cheshire.
- Compatible with Native Image! Thus, easy to use as a binary file in AWS Lambda.
- Clojure-friendly: supports fully qualified keyword attributes and handles properly them in SQL expressions.
- Both encoding & decoding are extendable with protocols & multimethods.
- Raw API access for special cases.
- Specs for better input validation.
- Compatible with Yandex DB.
-
Удалил
Как и многие, я храню всякий хлам в канале Saved Messages в Телеграме: ссылки, идеи, напоминалки. Иногда перебрасываю креды к сервисам, если лень это делать через гист или менеджер паролей.
Только что случилась забавная вещь. Удаляя сообщение из Saved Messages, не заметил, как кликнул по каналу и удалил его. Нажимая на подтверждение, подумал, что диалог какой-то странный, но палец было не остановить. Вжух — и канала не стало со всеми сообщениями.
Writing on programming, education, books and negotiations.