-
Предзаказ книги
UPD (2021 Mar 20): Принимаю заказы и сейчас, осталась небольшая коробка книжек. А если кончатся, напечатаю.
UPD (2020 Dec 03): Финальная версия книги и вся информация о ней.
Книга выходит на финальный этап: сделал корректуру, внес правки. Прямо сейчас издательство делает договор. Это займет еще неделю, плюс пара дней на переписку и всякие мелочи. Ожидаю публикацию в конце месяца.
Вот некоторые данные, которые уже не поменяются. Книга называется “Сlojure на производстве”, потому что ее цель – показать настоящую сторону разработки, а не сортировать списки. Вышло семь глав и 360 страниц. Печать черно-белая, код с подсветкой (градации серого, полужирный). Обложка цветная, мягкий переплет.
-
Что там с книгой? — 5
-
Ищу помощника
Я ищу помощника для работы над личными проектами. У меня скопились задачи, разгрести которые некогда из-за основной работы, и я готов предложить их вам. Работа платная. Планирую обеспечить задачами на несколько месяцев, дальше — по обстоятельствам. Теперь подробнее.
Требования к вам:
- Знание git: ветки, пулл-реквесты, мердж. Учетка на GitHub;
- Азы bash, make и прочих GNU-утилит;
- Владение текстовым редактором, чтобы выполнять монотонные штуки;
- Базовые знания Сlojure и Python;
- Желательно, чтобы у вас был Мак или Линукс (первое предпочтительней). Возможно, получится и с Виндой, но тогда придется настраивать Докеры/виртуалки и разбираться, почему что-то не работает;
- Будет супер, если вдруг вы знакомы с LaTeX.
Задачи, которые готов предложить (по убыванию важности):
- Адаптировать книгу о Сlojure под устройства с небольшим экраном (Kindle и телефон). Нужно изменить форматирование кода на Сlojure;
- Оформить питонячьи скрипты в пакеты;
- Взяться за issue проекта Etaoin. Я не прикасался к библиотеке почти год, а пользователи что-то пишут;
- Поработать над закрытым проектом на Сlojure.
Работа не для состоявшихся профессионалов, а для человека уровня junior или middle. Одновременно ее можно рассматривать как менторство: если что-то не получается, я готов объяснить, в том числе голосом.
Как будем работать:
- Сначала созваниваемся, я объясняю проект и как что работает;
- Добавляю вас в репозиторий и ставлю задачи. Описываю по шагам, что нужно сделать.
- Вы делаете задачу в отдельной ветке. По ходу дела задаете вопросы в комментариях к задаче, я отвечаю. Если что-то трудное, созваниваемся в Зуме или где-то еще.
- Открываете PR, я смотрю и проверяю локально, если норм — мердж, задача выполнена.
- Каждое утро коротко сообщаете о прогрессе: что сделали вчера, что планируете сегодня.
Все вопросы оплаты (сумма, частота, периодичность) обсуждаем в личной переписке.
Если вам это подходит, напишите мне письмо на адрес
ivan@grishaev.meс темой “Помощник” (или “Помощница”). Расскажите коротко о себе: чем занимаетесь и что умеете из списка требований. Напишите свою часовую зону и желаемую сумму в месяц: мне проще отталкиваться от ваших пожеланий.Спасибо.
-
Что думаю о Swagger
Одна из самых бесполезных вещей в айти — это Swagger. Так называется система, которая отображает REST-апихи в JSON-файле. Идея хорошая, но на практике вымораживает мозг. Давно порывался написать о ее минусах, и вот на днях опять подгорело.
Если вы внедряете в проекте Swagger, то скорее всего, занимаетесь ерундой. За все годы работы мне приходилось внедрять его четыре раза, и каждый раз я не видел от него пользы. Так, болтается какая-то хрень сбоку, отнимает время и ресурсы, никто ее не смотрит. Поставьте скрипт аналитики и убедитесь, что в нем от силы одно посещение в день.
Swagger это порождение мира node.js, столь мне отвратного. Это папка node_modules с миллионом микро-файлов, хрупкие сборки и прочие фу. К счастью, появились докер-образы, но и они не без греха. Так, образ swagger-ui нельзя запустить в read-only файловой системе. Если у вас Кубернетис, придется выкручиваться.
Усилия, направленные в русло Swagger, напоминают строительство пирамид. Масштабно, неэффективно и никому не нужно. Верный признак ущербности в том, что со всех сторон плодят еще более не нужные утилиты: убогий онлайн-редактор, CLI и, конечно, ОБЛАЧНУЮ учетную запись. Для утилиты, которая по JSON рисует HTML.
Те, кто топят за Swagger, не понимают, как устроена документация в фирмах. Дело в том, что JSON не может нормально передать текст, он для этого не предназначен. Использовать для документации язык, в котором нет мульти-строк, средств акцента, ссылок и прочего — это прохладная идея.
Нормальная документация — это семейство markdown- или asciidoc-файлов, объединенных в проект. Человек садится за редактор и пишет текст ручками. Расставляет акценты, ссылки, сноски. Это трудная работа, но только так получается достойная документация.
Конечно, я за то, чтобы процесс был автоматизирован. Приложение может сбрасывать JSON-схемы в файлы, которые затем подхватит сборщик документации. Но текст должен писать человек, и обязательно упомянуть все неочевидности, которые найдутся при работе с апихой. А их, как правило, вагон: эту апишку можно вызвать только при таком условии, параметры зависят друг от друга, и так далее. Описание одного только поиска может занять два экрана с примерами. JSON-схема не передаст всех нюансов.
Верный признак того, что Swagger это ущербная технология — им не пользуются самостоятельные компании. За всю карьеру я ни разу не видел, чтобы условный Гугл, Яндекс, Амазон и прочие показывали документацию через Swagger. В фирмах разный подход, но как правило это HTML с написанным человеком текстом. Вот несколько примеров:
Кто там еще? Вконтакт, Dropbox, банки (Тинек, Сбер)… ни одна значимая фирма не пользуется Сваггером. По моим меркам это был бы позор уровня студента.
Стандартный шаблон Сваггера ужасен. Взгляните на официальное демо:
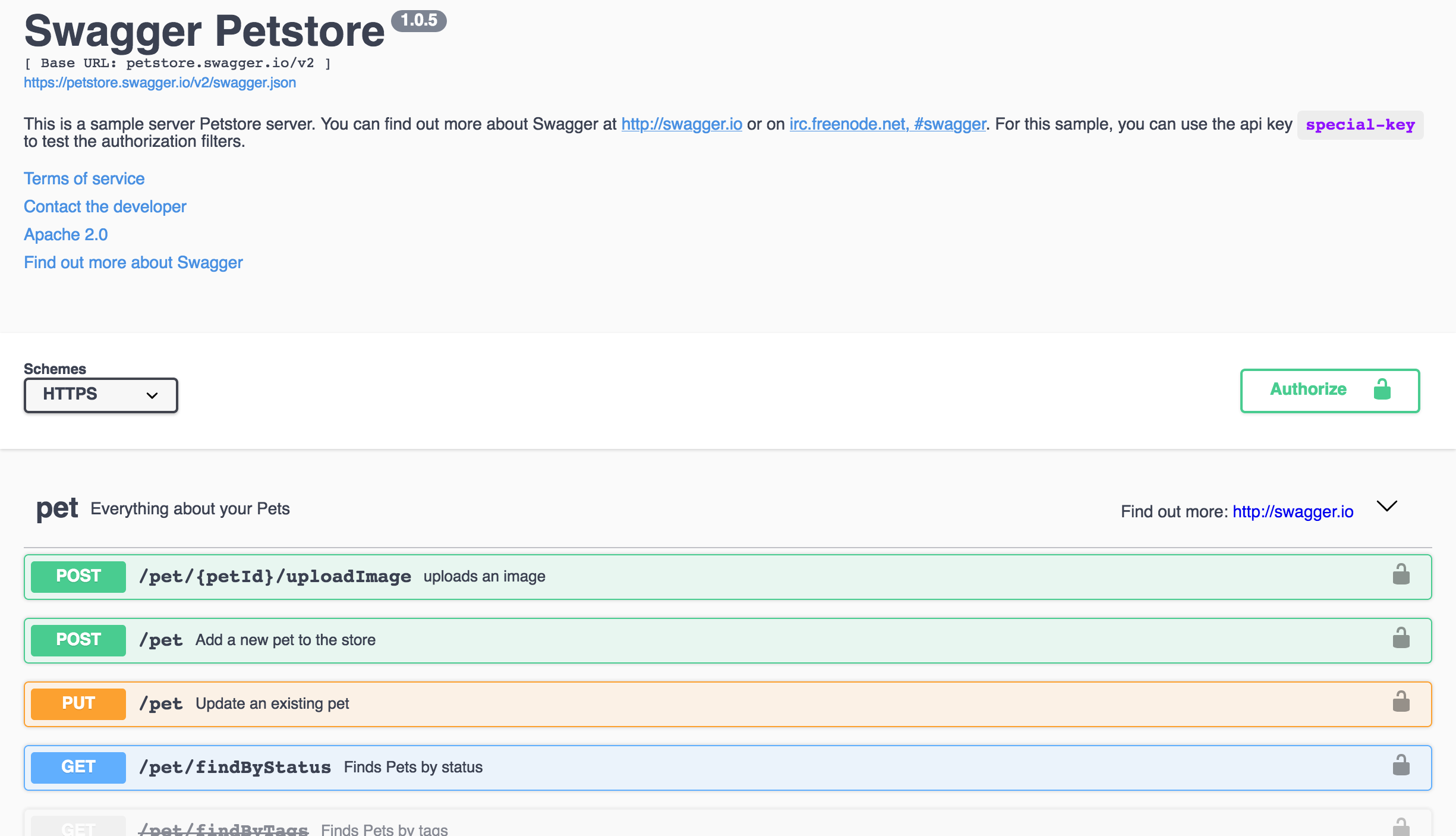
Тут красненький, тут желтенький, зеленый, выпадашечки, блин, цирк. Школьное поделие, а не документация. Этот шаблон не вписывается ни в один дизайн, каждый элемент чужероден. Нужно несколько дней на то, чтобы сверстать свой шаблон. Предлагать клиентам Сваггер — значит заведомо не уважать их.
Кроме убогого шаблона, Swagger предлагает утилиту для генерации кода приложения. Давайте честно: кто захочет строить проект на базе кодогенерации, написанной неизвестно кем? Этот код однозначно уйдет в урну. Конечно, генерация пригодится студентам для курсовой работы по предмету “введение в веб-разработку”, но и только.
В общем, прекратите страдать фигней. Хотите нормальную документацию — поднимайте проект на Asciidoc, Wiki, GitBook, что угодно. Это трудно и требует навыков выражать свои мысли понятно. Может, пока апиха в разработке и меняется каждые два дня, нет смысла писать документацию. Но не вываливайте на клиентов интерфейс Сваггера. В нем отчетливо слышна машинная природа, и по всем признакам ясно, что эта страница не для людей.
-
Dictionary-like Specs in Clojure
TLDR: this post is a copy of readme file from the GitHub repo.
Maps are quite common in Clojure, and thus
s/keysspecs too. Here is a common example:(s/def :profile/url string?) (s/def :profile/rating int?) (s/def ::profile (s/keys :req-un [:profile/url :profile/rating])) (s/def :user/name string?) (s/def :user/age int?) (s/def :user/profile ::profile) (s/def ::user (s/keys :req-un [:user/name :user/age :user/profile]))What’s wrong with it? Namely:
- each key requires its own spec, which is verbose;
- keys without a namespace still need it to declare a spec;
- for the top level map you use the current namespace, but for children you have
to specify it manually, which leads to spec overriding (not only you have
declared
:user/name); - keys are only keywords which is fine in 99%, but still;
- there is no a strict version of
s/keyswhich fails when extra keys were passed. Doing it manually looks messy.
Now imagine if it would have been like this:
(s/def ::user {:name string? :age int? :profile {:url? string? :rating int?}})or this (full keys):
(s/def ::user #:user{:name string? :age int? :profile #:profile{:url? string? :rating int?}})This library is it to fix everything said above. Add it:
;; deps [spec-dict "0.1.0"] (require '[spec-dict :refer [dict dict*]]) -
Никогда
Предположим, к вам пришел коллега и говорит: ты использовал в коде X, а Уважаемый Авторитет сказал так не делать. И даже ссылку прикладывает на блог или твит. Как поступить?
Самое желанное в этом случае — повестись и вспомнить другого Уважаемого Гуру, нагуглить его цитаты, набросать ссылок на Википедию. Словом, знатно посраться и разойтись ни с чем. Можно просто заигнорить коллегу и сэкономить время. Это все круто, но нас интересует самый сложный вариант — разобраться, что происходит на самом деле и почему так.
Дело в том, что коллега не правильно понимает правило “никогда не используй X”. Я полагаю, очевидно, что если в язык добавили X, им будут пользоваться. Можно долго сотрясать воздух, но единственный способ изгнать X из кода — выпилить его из языка. В крайнем случае — добавить ворнинги на уровне стандартной библиотеки, чтобы было не повадно.
Когда Уважаемый Мастер говорит “никогда”, он намеренно усиливает формулировку, чтобы она звучала громче. Это нормально — чтобы дошло до масс, разошлось по Твиттеру, породило срач. Другое дело, что обсуждать чей-то запрос это удел непрофессионалов. Если команде удобно работать так, а не иначе, она может положить на заветы Гуру.
“Никогда не используй X” на самом деле читается как “вообще, X не подходит для общих случаев, и пользоваться им нужно осторожно, поэтому начинающим советуем от него отказаться”. Это звучит как жевание тряпки: ни конкретики, ни призыва. Нужны еще две страницы текста, чтобы объяснить семантику X и когда он нужен. Но это долго, и нужно думать. А так — “никогда не используй”, коротко и ясно.
Короче, коллега не понимает смысл запрета. Он нужен даже не для того, чтобы нарушать его и быть этаким бунтарем. Запрет это предупреждение, точка, где нужно сделать паузу и подумать. Есть ли доводы в пользу нарушения? Если да и вы можете их объяснить, то поздравляю — вы профессионал.
Теперь поставьте себя на место коллеги: вы увидели подозрительный трюк в коде. Не подкатывайе с цитатам Фаулера или Кнута: это балобольство. Вы же сами следуете им только выборочно, кого вы обманываете. Надо вежливо спросить, в чем тут умысел и что мы выигрываем. Потому что иногда трюк действительно удачный, но нет комментария о том, в чем выгода. Дальше смотрим на реакцию: если в ответ прилетает грамотное объяснение, то норм. Если цитаты Торвальдса, коллегу надо учить, а в особо тяжких случаях снимать с проекта.
На цитаты надейся, а сам не плошай.
-
Бы
Чтобы жить счастливо и не страдать от выгораний и подгораний, надо делать вот что. Следите за мыслями и эмоциями и соотносите их с реальным положением дел. Тренируйте внутреннюю нейросеть — ты подумал одно, а на самом деле причина в другом. Со временем это избавит вас от пласта проблем, которые обычно называют кризисом среднего возраста, депрессией, выгоранием и прочей мурой.
В каком-то смысле память человека не лучше, чем у рыбки Дори. Первыми в голову приходят очевидные, примитивные мысли. Это касается и эмоций — наша первая реакция примитивна и не отличается от реакции ребенка. Нахамили — мы хамим в ответ, разозлили — злимся. За обычной просьбой видим претензию и начинаем защищаться.
Эмоции тесно связаны с планами на работу. Часто мы виним окружающих в том, что не успеваем делать личные проекты. Я бы давно дописал книгу, если бы не дети. Уже запустил бы свой Фейсбук, если бы не работодатель. Уехал за границу, если бы не родственники. Бы да кабы.
Реальность же такова, что временем распоряжаемся только мы, и все эти “бы” — жалкие отговорки. Много раз со мной было так, что родные уехали, у заказчика выходной, и впереди три свободных часа. Я сажусь на ноут и проверяю почту, читаю Медузу и Википедию. Когда остается час, делаю малую часть от того, что было задумано, и так по кругу. Виноваты все, кроме меня.
Со временем я заметил этот паттерн и выработал иммунитет. Каждый раз, когда в голову лезет мысль, мол, остался бы дома и писал книгу, я говорю сам себе: дружок, в прошлый раз у тебя было три часа, и на полезные вещи ты потратил от силы полтора. Давай-ка не будем проходить все с нуля. Ты же не рыбка Дори. Тебя хватает на час продуктивного труда, дальше ты сливаешься. Сегодня еще будет такой час, сядь и сделай, что хотел. Главное, не тупи в интернет.
Это работает. Теперь я не ищу оправданий, не обижаюсь на близких, заказчика и весь мир, который не дает мне заниматься тем, что я хочу. В тайне от других я называю такую модель двоемыслием. Суть в том, что ты придерживаешься одновременно двух позиций и работаешь с ними. Да, я испытываю негативные эмоции. В то же время понимаю, что они примитивны и не отражают сути. И спокойно делаю так, как надо.
Еще раз: недостаточно слушать свои эмоции. Нужно следить за тем, как они ложатся на реальность. Если видишь, что раз за разом думал одно, а получается другое, поставь галочку — в следующий раз выбрать другой сценарий. Тогда не будет выгораний, подгораний, превозможений, и все вообще все изменится.
-
Что там с книгой? — 4
-
Текст
Пишу книгу, и внезапно открыл редактирование текста. Не написание, а именно редактирование, исправление. Это необычно, изнуряюще, и в итоге — клево.
Текст похож на мрамор. Когда вы написали текст, это кусок камня, заготовка. Первый текст всегда кривой: в нем полно междометий и разговорных оборотов. Предложения плохо связаны: здесь топчитесь на месте, тут рванули без штанов.
Смотришь на это поделие и понимаешь, что шансов нет. Однако даже плохой текст выражает какую-то мысль. Одно это дает тексту миллион очков. Если вы пишете важную вещь, пусть и кривым языком, это лучше, чем не писать ничего. Даже не лучше, а вообще ништяк, потому что текст можно улучшить.
Подобно мрамору, с текста снимают слой за слоем. Первый — убрать очевидный шлак типа разговорных слов и лишних местоимений. Второй — двигать слова внутри предложения, искать цепочки из длинных слов вроде “является необходимым в повседневном использовании”. С опытом глаз видит такие места на уровне рисунка текста. Я называю это колбасой — глаз скользит по строчке, и вдруг жырнота, редкие пробелы. Надо исправлять.
Когда мусор убрали, встают проблемы со смыслом. Понимаешь, что в первом чтении лишние словечки выполняли роль завесы. Мысль слаба, доказательств нет, но из-за обилия слов казалось, что все норм. Приходится проверять то, во что верил полгода назад, а иногда просто сносить абзац.
Перечитываешь текст и видишь, что не объективен. Мысленно с кем-то споришь и словно продавливашь точку зрения, хотя должен быть нейтральным. Об этом говорят пафосные обороты, слова-усилители (конечно, естественно).
У текста есть ритм, звуковая палитра и визуальный рисунок. Все это редактируется в отдельном проходе. Наверное, мастера совмещают несколько задач за один проход, но я так не могу.
Любой текст станет офигенным, если почистить и сократить его. Удивительно, что каждый проход вскрывает косяки и возможности, которых раньше не видел. Это как с мрамором — представьте, глыба уже содержит идеальную скульптуру, нужно только отрезать лишнее. Но нельзя увидеть лишнее сразу, только по слоям.
Что я сделал перед публикацией? Правильно, почистил мусор. Было много дряни, а теперь хоть читать можно. Этот абзац тоже можно улучшить, ну да бог с ним.
-
Что там с книгой? — 3
Writing on programming, education, books and negotiations.


