-
Postgres №39
Поговорим про пулы и проблемы соединений.
При всех достоинствах Постгреса нужно знать его недостатки. Один из них следующий: Постгрес плохо справляется с большим числом подключений. Это следует из того, как устроена его серверная часть.
При запуске сервера запускается мастер-процесс. Когда к нему кто-то подключается, процесс клонирует себя системным вызовом
fork. Получаются два процесса: мастер занимается общими задачами, а второй — слушает и отвечает на сообщения клиента. Когда подключается кто-то еще, мастер снова клонирует себя и так далее.Для обмена информацией служит общий участок памяти — shared memory. Такой участок можно создать в Unix-подобных системах. Если один процесс что-то изменит в этой памяти, друге получат изменения мгновенно.
Разработчики давно обсуждают как уйти от модели “новый процесс на соединение”. Предлагаются нативные треды, но когда они будут — я не знаю.
Нужно понимать, что системный вызов
fork— очень дорогой. Он копирует всю информацию о процессе, а именно: регистры процессора, стек, номера потоков и открытых файлов. Поэтому каждое новое соединение — это вызовforkи ожидание, пока операционная система клонирует процесс.Даже если предположить, что вместо fork Постгрес использует треды, помните: запуск нового потока — это тоже системный вызов и конкуренция за время планировщика. А кроме того, частые сетевые подключения — это тоже системные вызовы.
Настройка, которая определяет максимальное число соединений, называется
max_connections. Увидеть ее можно командойSHOW:SHOW max_connections;У себя я вижу число 100. Это весьма адекватная цифра: число соединений не должно превышать нескольких десятков и уж тем более — сотен. Ситуация, когда вам не хватает 300 соединений, говорит об одном из двух. Либо у вас биллинг федерального значения и супер-пупер хайлоад. Либо приложение неправильно работает с соединениями: не закрывает их, теряет, удерживает без всякой нужды. Гораздо вероятней второе, а не первое.
Соединениями управляют на двух уровнях: сетевом (прокси) и в приложении. Во втором случае это пул соединений. Это объект, который имитирует обычное соединение, но на самом деле открывает их несколько. Когда мы выполняем запрос, пул помечает одно из них занятым и передает сообщения через него. Когда мы закрываем соединение, этого не происходит — оно помечается свободным и доступно другим потокам приложения.
Самый известный пул в Джаве называется HikariCP (от слова “харакири”). Он очень быстрый: разработчики писали, что анализировали байт-код и путем экспериментов уменьшили его минимума. В пуле нет блокирующих операций вроде
synchronized: все сделано через CAS-примитивы. Написаны свои версии классовListи подобных, которые не проверяют выход за границы — это гарантируется в коде.У HikariCP множество характеристик и шаблонов поведения. Например, сколько соединений открывать на старте; до какого предела расти; если предел достигнут, а кому-то нужно соединение, то сколько ждать; как долго клиент может удерживать соединение; как определять потерянное соединение, которое взяли и не вернули; как проверять, что соединение живое и так далее.
Хорошая практика в том, чтобы использовать пул всегда независимо от типа приложения. Этим вы гарантируете минимальную гигиену в работе с базой. Даже если у вас одно соединение, пул все равно необходим: он откроет его и будет держать открытым. Приложение не будет без конца стучаться в сокет, проходить авторизацию и клонировать серверный процесс.
Последнее — частая ошибка ребят, пришедших их PHP. В их мире не принято следить за ресурсами. Открыл файл, соединение, сокет и работай с ними, а закрывать на надо. Зачем, если скрипт отработает, и все закроется само? В системах, отличных от скриптовых, состояние не исчезает. Если открыли соединение, его нужно закрыть, но при этом следить, чтобы “открыл-закрыл” это не повторялось постоянно.
Пул решает эту проблему — берет на себя заботу об открытии и закрытии. Если одного соединения перестанет хватать, это дело настройки: увеличьте предел с 1 до 2. Стратегия может быть разной, например не открывать при запуске ничего, а делать это по требованию. Либо наоборот — открыть столько, сколько указано в лимите, чтобы каждый запрос выполнятся с уже открытым соединением.
Сколько выделить соединений пулу — вопрос сложный и решается банальным подбором. Начните с адекватной цифры вроде четырех и посмотрите на результат: как быстро приложение отвечает на запросы в многопоточном режиме. Собирайте метрики пула через JMX или обычные логи. Особенна важна метрика ожидания: как долго очередной поток ждет, пока пул выдаст ему соединение.
Другой важный показатель — сколько в пуле свободных соединений. Если их много, очевидно вы задрали лимит. Скорее всего, в этом соединении нуждается другой экземпляр приложения.
Поэтому — гадать не нужно, все сводится к метрикам.
Это была первая часть темы о пулах и соединениях. В следующих выпусках продолжим.
-
Postgres №38
Иногда бизнес-логику проще выразить на SQL – нравится вам это или нет. При этом окружающие теряют лицо: кричат “боже, хранимки!” и ведут себя недостойно. Бояться тут нечего, а истерика — от незнания.
Я не говорю, что нужно писать хранимки. Речь о том, чтобы поручить базе ту работу, что делает ваш Питон или Джава. Часто SQL выигрывает: он короче, точнее, не требует многих обращений к базе.
Нюанс в том, что меняется парадигма мышления. Когда вы пишете на SQL, то должны думать реляционно. Если писать хранимки императивно как на Питоне, это будет ужасно.
Давайте вспомним пример, который я описывал в статье про рейтинг пользователей. Постановка такая: у пользователей есть история начисления баллов. Также есть глобальный рейтинг. Как только пользователю начисляются баллы, он видит их в истории. Одновременно меняется его позиция в рейтинге.
На какой-нибудь питонячей ORM это выглядит так:
user_id = 51315 points = 100 points_entry = UserPoints.create(user_id=user_id, points=points) points_entry.save() rating_entry = UserRating.get_or_create(user_id=user_id) rating_entry.points += points rating_entry.save()Сперва мы добавили запись в историю баллов. Затем выбрали или создали запись в глобальном рейтинге. Прибавили баллы, записали. Все это нужно делать в транзакции, иначе есть риск потерять баллы (по аналогии с задачей про семейную пару и терминал).
Предположим, руководитель сказал: “ребят, переносим логику в БД”, но не удосужился объяснить, что это значит. Окей, программист пишет процедуру на
plpgsql:create procedure add_points(int user_id, int points) begin create_points_history(user_id, points); rating_entry = get_user_rating_by_user_id(user_id); if (rating_entry is NULL) then insert_user_rating(user_id, points); else update_user_rating(user_id, points); endif; end;Эта процедура – построчная калька с Питона. Далее пишутся функции
get_user_rating_by_user_id,get_user_rating_by_user_idи другие. Получается два экрана SQL, который трудно понять и поддерживать. Запросов по-прежнему много. Один раз увидев такое, разработчик получает душевную травму. При слове “хранимки” у него начинается истерика.Проблема в том, что автор процедуры использует SQL не по назначению. Он пишет на нем императивно, а SQL создан для операций над отношениями. Прочитайте еще раз: SQL создан для операций над отношениями. Единица операции — таблица. Если ваш SQL полон функций
get_user_by_id,get_profile_by_id, то это ошибка. Копаешь граблями – получишь заведомо плохой результат. Нельзя пересаживать программиста с императивного Питона на SQL. Пока мозги не перестроились, хорошего результата не ждите.Достойное решение на SQL выглядит примерно так:
with update_history as ( insert into user_history (user_id, points) values ($1, $2) ) insert into user_rating(user_id, points) values ($1, $2) on conflict user_id do update set points += excluded.points returning user_id, pointsЗдесь все просто: часть
update_historyдобавляет запись в историю баллов. Основная часть пытается вставить пользователя и баллы в рейтинг, а если пользователь уже есть в нем, прибавляет баллы. Запрос возвращает пользователя и новую сумму баллов.Этот запрос выполняется транзакционно, обе части видят один снимок данных. Подчеркну: совершенно незачем выносить его в хранимку. Достаточно хранить запрос в проекте и вызывать его. Хранимки нет, но работа делегируется базе.
Итого: не пишите хранимки только затем, чтобы они были. Думайте о том, как делегировать работу базе, а не писать бороду SQL-функций. Если вы работаете с базой, мыслите реляционно. Экраны императивного SQL говорят о том, что вы делаете что-то не так.
-
Postgres №37
Совет №36 оканчивался фразой:
Мне известны для случая, когда от внешних ключей отказываются добровольно.
О них и поговорим.
Первый случай, когда ослабление ключей допустимо – это GDPR и схожие требования. Например, пользователь оставил заявку на удаление учетки и связанных данных. Удалять их в лоб долго и трудно: пользователь – это центральная сущность, на которую завязано все. Каскадный DELETE, во-первых, крайне медленный, а во-вторых, может задеть данные, которые нужно оставить.
Кроме пользователя, бывают и другие сущности, которые нужно экстренно удалить, но мешают внешние связи. В этом случае сперва удаляют внешние ключи при помощи
drop constraint. Например, ниже удаляется внешний ключuser_idв профилях:alter table profiles drop constraint fk_user_idДалее удаляется целевая сущность — пользователь. В дальнейших запросах используется внутреннее соединение, чтобы отсечь записи, которые ссылаются в никуда. Например, если мы выбрали профили по особому критерию, то пользователи цепляются не LEFT, а обычным JOIN. Это гарантирует, что в выборке не будет “висюков”:
select * from profiles p where p.open_to_work join users u on p.user_id = u.idПозже “висюки” подчищаются запросом по расписанию. Заметим, что внутренний JOIN в целом работает лучше, чем левый и правый аналоги. Он быстрее и отсекает больше данных. Как правило, LEFT JOIN означает, что в базе что-то не так.
Сказанное выше звучит костыльно, но увы — это жизнь. Так было в одном стартапе: он выходил на очередной раунд инвестирования, и сказали: по такому-то закону нужно удалить учетку пользователя по запросу в короткое время. Таких пользователей было немного, буквально пять или шесть, но обилие внешних ссылок все усложняло. Получалось огромное дерево таблиц, которое нужно было очистить в особом порядке. Руководители стартапа не хотели тратить время и деньги на такую ерунду. Поэтому внешние ключи удалили и снесли записи обычным DELETE. Схема базы пострадала, зато с задачей справились быстро.
Внешние ключи нужны – без них легко испортить данные. Но в редких случаях выгодно их ослабить – только никому об этом не говорить.
-
Postgres №36
Перечитав прошлый совет, я понял, что он нуждается в технической демке. Быстренько покажу, на что влияет индекс внешнего ключа.
Уточнение: будет много планов. Поскольку они длинные, их трудно записать в Телеграме в понятном виде. Здесь только фрагменты, а в конце – ссылка на гист.
Итак, делаем две таблицы, пользователей и профили:
create table users ( id serial primary key ); create table profiles ( id serial primary key, user_id integer not null references users(id) );Вставим миллион пользователей:
insert into users select x from generate_series(1, 999999) as seq(x);Профилей тоже миллион, но есть нюанс. Я не хочу, чтобы n-ая строка профиля ссылалась на n-ую строку пользователя. Это слишком хорошо и не отражает действительности. Поэтому первый профиль ссылается на последнего пользователя, второй – на предпоследнего и так далее. Другими словами, максимально усложним базе жизнь в плане соединений:
insert into profiles select x, 1000000 - x from generate_series(1, 999999) as seq(x);Проверим, что в таблицах:
table users limit 100;┌─────┐ │ id │ ├─────┤ │ 1 │ │ 2 │ │ 3 │ │ 4 │ │ 5 │ │ 6 │ │ 7 │ │ 8 │ │ 9 │ │ 10 │table profiles limit 100;┌─────┬─────────┐ │ id │ user_id │ ├─────┼─────────┤ │ 1 │ 999999 │ │ 2 │ 999998 │ │ 3 │ 999997 │ │ 4 │ 999996 │ │ 5 │ 999995 │ │ 6 │ 999994 │ │ 7 │ 999993 │ │ 8 │ 999992 │ │ 9 │ 999991 │Индекса на
user_idпока что нет. Что будет, если выбрать профили ста определенных пользователей? Посмотрим план:explain select * from profiles where user_id between 450000 and 450100;Gather (cost=1000.00..11684.39 rows=94 width=8) Workers Planned: 2 Parallel Seq Scan on profiles (cost=0.00..10674.99 rows=39 width=8) Filter: ((user_id >= 450000) AND (user_id <= 450100))Видим, что было полное сканирование профилей. При этом Postgres сделал это параллельно в два процесса (Parallel Seq Scan, Workers =2), а потом объединил результат (шаг Gather). Итоговая стоимость довольно высокая (11684).
Предположим, я делаю отчет по всем пользователям и профилям: тупо соединяю две таблицы джоином:
explain select * from users u, profiles p where u.id = p.user_id;Hash Join (cost=30831.98..59602.98 rows=999999 width=12) Hash Cond: (p.user_id = u.id) Seq Scan on profiles p (cost=0.00..14424.99 rows=999999 width=8) Hash (cost=14424.99..14424.99 rows=999999 width=4) Seq Scan on users u (cost=0.00..14424.99 rows=999999 width=4)То, что был seq scan по таблице users, это нормально – мы выбираем все записи. Однако по таблице profiles тоже был full scan, при этом стоимость хэширования огромна (cost=14424.99..14424.99). Финальный обход хэшей тоже дорогой: 59602.98
Другой пример: предположим, мы выбрали малую часть пользователей и нужно присоединить им профили. Для этого рассмотрим запрос:
explain with some_users as ( select * from users where id between 450000 and 450100 ) select * from some_users sm join profiles p on sm.id = p.user_id;Считаем, что выборка
some_usersдаст всего 100 пользователей. В реальности мы бы фильтровали по городу или другому признаку, но поскольку у нас только id, остается по нему.Gather (cost=1007.61..10702.82 rows=98 width=12) Workers Planned: 2 Hash Join (cost=7.61..9693.02 rows=41 width=12) Hash Cond: (p.user_id = users.id) Parallel Seq Scan on profiles p (cost=0.00..8591.66 rows=416666 width=8) Hash (cost=6.39..6.39 rows=98 width=4) Index Only Scan using users_pkey on users (cost=0.42..6.39 rows=98 width=4) Index Cond: ((id >= 450000) AND (id <= 450100))Этот план говорит о следующем: выборка
some_usersсработала моментально, но дальше все плохо. Чтобы найти профили, Postgres опять зарядил два параллельных потока с объединением. Итоговая стоимость (10702.82) высокая.Добавим индекс на поле
user_idи посмотрим, как все изменится:create unique index idx_profiles_user_id_u on profiles using btree (user_id); analyze profiles;Простой пример: найти профили по диапазону пользователей:
explain select * from profiles where user_id between 450000 and 450100;Index Scan using idx_profiles_user_id_u on profiles (cost=0.42..10.37 rows=97 width=8) Index Cond: ((user_id >= 450000) AND (user_id <= 450100))Очевидно, стоимость копеечная.
Далее: имея узкую выборку пользователей (например, по городу), присоединить им профили:
explain with some_users as ( select * from users where id between 450000 and 450100 ) select * from some_users sm join profiles p on sm.id = p.user_id;Nested Loop (cost=0.85..825.75 rows=98 width=12) Index Only Scan using users_pkey on users (cost=0.42..6.39 rows=98 width=4) Index Cond: ((id >= 450000) AND (id <= 450100)) Index Scan using idx_profiles_user_id_u on profiles p (cost=0.42..8.36 rows=1 width=8) Index Cond: (user_id = users.id)Было два прохода по индексам, итоговые данные соединены вложенным циклом (Nested Loop). Сложность такого соединения квадратична, но на малых объемах выигрывает. Стоимость 825 – низкая.
И наконец, узрите истинную мощь Merge Join – соединения слиянием. Повторим запрос, в котором мы соединяем две таблицы без каких-либо фильтров:
explain select * from users u, profiles p where u.id = p.user_id;Вы, наверное, думаете, что все полетит? Нет, план останется таким же, то есть очень медленным:
Hash Join (cost=30831.98..59602.98 rows=999999 width=12) ...Будет два seq scan-а по обеим таблицам и ручное хеширование. Напомню, я специально создал худший сценарий, когда порядок профилей обратный: первый профиль ссылается на последнего пользователя и так далее. Это делает хэширование дорогим. Стоимость первой строки равна 30831 – это значит, что перед получением данных база будет тупить – считать хэши.
Сделаем вот что: в запросе выше заменим
profilesна подзапрос, отсортированный поuser_id:explain select * from users u, (select * from profiles order by user_id) p where u.id = p.user_id order by u.id;План:
Merge Join (cost=5.14..81384.50 rows=999999 width=12) Merge Cond: (profiles.user_id = u.id) Index Scan using idx_profiles_user_id_u on profiles (cost=0.42..30408.41 rows=999999 width=8) Index Only Scan using users_pkey on users u (cost=0.42..25980.41 rows=999999 width=4)Оба набора упорядочены по тем полям, по которым их соединяют, поэтому сработает соединение слиянием. Стоимость его гораздо ниже, чем у хеширования. Первая строка доступна уже через 5.14 единиц стоимости – а было 30831.98. Четыре порядка! Когда я вижу в плане Merge Join, все мои железы активируются и выделяют жидкости.
Планы – полезная вещь. Читайте их, экспериментируйте, пытайтесь понять, почему план именно такой, а не другой.
-
Postgres №35
В прошлый раз мы говорили об уникальных ограничениях, а еще есть внешние. Это когда значение поля обязано быть первичным ключом другой таблицы. Например, в профиле колонка
user_idссылается на пользователя: таблицуusersи ее первичный ключid.create table users ( id serial primary key... ); create table profiles( id serial primary key, user_id integer not null references users(id) );Ключевое слово
referencesсоздает это ограничение автоматом. Можно задать его явно таким выражением:alter table profiles add constraint fk_profile_user_id foreign key (user_id) references users (id);Первичные ключи бывают составными, и тогда внешний ключ тоже составной.
Когда создано подобное ограничение, профиль не может ссылаться на пользователя, которого не существует. При этом значения NULL допускаются, потому что он не равен другим нуллам. Если поле не должно содержать нуллы, это задается свойством NOT NULL.
Поскольку первичный ключ всегда индексирован, проверка внешнего ключа работает быстро. Например, мы добавляем профиль с полем user_id 100500. Проверка аналогична запросу ниже (обратите внимание, что из него ничего не выбирается):
select from users where id = 100500Под капотом Postgres проверяет только индекс – нет смысла дергать таблицу — поэтому запроса в логах вы не увидите.
Некоторое разработчики считают, что внешние ключи тоже индексируются. Например, зная пользователя, мы хотим взять его профиль (технику часто называют backref, обратной ссылкой):
select * from profiles where user_id = 100500Увы, это не так. По умолчанию внешний ключ не индексируется, и запрос выше даст full scan. Повесьте на него btree:
create index idx_profile_user_id on profiles using btree (user_id);Теперь обратная ссылка индексирована, и зная родительскую сущность, легко найти дочерние.
Пример с профилем можно сделать еще строже: мы допускаем только один профиль на пользователя, поэтому повесим на
user_idуникальный индекс:create UNIQUE index ...Индексы на внешние ключи обязательны, если используется join. Скажем, вы строите отчет по всем пользователям системы:
select * from users u left join profiles p on u.id = p.user_idБез индекса на
profiles.user_idзапрос будет очень тяжелым. Зато если поле индексировано и вдобавок обе таблицы отсортированы по коду пользователя, возможно, сработает Merge Join – соединение слиянием. Это самый быстрый алгоритм соединения. Принцип у него такой же, как и у сортировки слиянием.Внешние ключи вносят в базу ограничения, и желательно следовать им. В противном случае вы рискуете создать “висяки” – ссылки, ведущие в никуда. Как и в случае с дублями, их тяжело расследовать и удалять.
Мне известны для случая, когда от внешних ключей отказываются добровольно. Я рассмотрю их в следующих советах.
-
Libpq и Java
На днях я ввязался в одну авантюру, а она оказалась смоляной ямой. Увяз по самые уши и не знаю, продолжать или бросить. Авантюра, кстати, тоже связана с Postgres.
Я хотел проверить: будет ли драйвер для Postgres быстрее, если переписать его с чистой Джавы на Libpq. Кто не знает, Libpq – это библиотека на Си для работы с базой. Идея в том, чтобы поручить большую часть работы коду на Си, а самому только дергать функции через JNI.
Такую сишную обертку я написал; тесты показали, что Libpq как минимум не хуже, а порой и быстрее Джавы. Взаимодействие Джавы с сишным рантаймом – мутная история, в ней много специфики. Ошибся указателем – Джава вылетает. Но это не идет ни в какое сравнение с тем, где я увяз – сборкой.
Я хотел собрать сишный код под три платформы (винда, мак, линукс) и две архитектуры (x86-64, arm64). Их произведение дает шесть комбинаций. Вопрос: где и как собирать? Допустим, у меня есть Мак на арме; докер на нем дает Линукс на арме. Нужна винда на арме, а где ее взять? То же самое с интелом: у меня есть старый Мак на core i3, но по сегодняшним меркам он такой медленный, что лишний раз трогать его не хочется. Есть игровой комп с Виндой на интеле, но не будешь же носить его с собой? В итоге я поручил сборку Github actions: в нем доступны все шесть видов машин, а сценарий пишется на yaml.
По наивности я думал, что напишу один Makefile, который вызову с разными переменными – и дело в шляпе. Идея провалилась из-за адского разнообразия сред и платформ. Сборка простого кода на C++ отличается даже не в рамках ОС, а дистрибутива. Везде спонтанные отличия, условности, разные названия папок, путей и так далее.
Несколько примеров. На винде x64 компилятор MSYS2 ставится в папку
c:\temp\a\msys64, а на арме – вd:\temp\a\msys64(другой диск). Почему былC, а сталD? И почему он ставится не в корень, а куда-то в temp? Уверен, что есть объяснение, но неудобно.Мак и его Homebrew тоже хорош. На интеле пакет
libpqвключает утилитуpg_config– она показывает, где лежат заголовочные файлы и другое барахло. На M1 в таком же пакете утилиты нет. Почему?Плохи дела и на этом вашем Линуксе. В той Убунте, что идет на Гитхабе, пакет
postgres-client– 16 версии, а мне нужна 18. Нужно подключать частный репозиторий Postgres. У него тоже особенности: на интеле пакетpostgres-client-18включает заголовочные файлы, а на арме – нет. Нужно качать dev-барахло.И таких вещей очень много. Разные пути, переменные среды; здесь есть файл, а тут нет и так далее. Смейтесь или нет, но мне понадобилось 166 (сто шестьдесят шесть) попыток, чтобы прошли все билды. Я убил на это вагон времени, забивая на работу и даже личные обязанности. При этом та удачная 166-я попытка – грубый черновик, который еще доводить и доводить до ума.
Напомню, все это лишь для того, чтобы:
- получить последнюю версию libpq под нужные ОС и архитектуру;
- собрать динамическую библиотеку из кода на C++;
- сохранить libpq и библиотеку в артефакты.
Допускаю, что плохо знаю тонкости кроссплатформенной сборки; возможно, есть инструменты, которые щелкают эту проблему как дважды два. Почему их нет в поисковой выдаче? Я безвылазно сидел в Гугле и StackOverflow, повидал сотню разных ошибок – и ни разу не было ответа, мол, поставь программу X, и она все тебе соберет.
Если такая программа есть или вы решали похожую проблему, расскажите, пожалуйста.
-
Хорошо или быстро
Иногда говорят: я делаю хорошо, а нужно быстро. То есть противопоставляют эти две характеристики: либо одна, либо другая, но не одновременно.
Я никогда не любил этот подход. На мой взгляд, скорость и качество неотделимы. Примерно как пространство и время образуют континуум, у специалиста скорость и качество идут рука об руку.
Если кто-то делает хорошо и медленно, возможны варианты: искать удачные подходы, набивать руку. Планировать работу, договариваться: возможно, какое-то требование было избыточным или исказилось, пройдя конфлюэнсы и джиры. Иногда можно срезать углы, аккуратно нарушить правила.
Часто скорость снижает не качество, а нелепые требования. Например, написать код, используя кривую библиотеку – взять нормальную запрещено. Или хочется обратиться к базе, но нельзя – вызывай сервис, который ходит в базу и выдает то же самое, только на два порядка медленней.
На проверку оказывается, что главный враг качества – внутренние заморочки, и объяснение у них следующее: мы делаем так, потому что мы так делаем.
Хорошая практика в том, чтобы следить за ощущениями и спрашивать себя: что мешает сделать работу быстро и качественно? При этом ни в коем случае не врать: если это коллега, руководитель или предубеждение, то не пытаться это скрыть. Честно сказать: если выбор решения за мной, я сделаю за X дней, если как говорят – за 3X дней.
Качеству и скорости нужен третий компонент – свобода действий. Он – тот самый ингредиент, с которым все удается и прогресс идет. Нет свободы – и начинаются торги: долго, но качественно. Быстро, но тяп-ляп.
Если вы заметили, что коллега тормозит, возможно, ему поможет капелька свободы. Какое-то самостоятельное решение и ответственность за него. Если тормозите вы — самое время попросить свободы.
-
Глава 2. Базовые возможности JSON
Главы
- Введение в документы
- Базовые возможности JSON
- JSON в таблицах
- Индексирование JSON
- Ограничения в документах
- Язык путей JSONPath
- Отчеты, функции, расписание
- Функции на языке Python
- Версионирование и архивация документов
- Релевантный поиск
Содержание
- Главы
- Установка и подключение
- Знакомство с json и jsonb
- Решения до JSON
- Подробнее о JSONb
- Операторы доступа
- Квадратные скобки
- Другие операторы
- Функции json(b)
- JSON как таблица
В этой главе мы перейдем к техническим вещам: познакомимся с типом JSON в Postgres. Мы рассмотрим основные операции над ним и ряд функций, которые облегчат работу. Покажем неочевидные трюки, когда JSON полезен: как прочитать его по частям, как передать с его помощью таблицу и многое другое.
Установка и подключение
Прежде чем начать работу, убедитесь, что у вас установлен сервер Postgres. На момент написания книги его последняя версия – 18.1, но ранние тоже подойдут. Случаи, когда та или иная техника требуют особой версии, оговариваются особо.
Если у вас нет Postgres, то вот как установить его в разных системах. Прежде всего это официальный сайт проекта. Посетите страницу загрузок и укажите операционную систему. Вас направят на другую страницу с ссылкой на установщик.
Компания PostgresPro предлагает графический инсталлятор для Windows. Postgres Pro – это расширенная база данных со своими расширениями и функциями. Наша книга опирается на стандартный Postgres, поэтому Pro-версия тоже подойдет.
-
Postgres №34
Банально, но все же: если какой-то атрибут уникален, нужно повесить на него уникальное ограничение. С ним физически невозможно добавить в базу дубликат. Многие разработчики проверяют уникальность вручную: если нет, то вставить, если есть, то ругнуться. Однажды запрос приходит от потребителя, который не в курсе этих заморочек, и получается дубль. Со временем на него ссылаются другие сущности, он обрастает связями. Когда дубль вскрывается, и все чешут голову — как же так получилось?
Удаление дубликата, обросшего связями — очень напряжная вещь. Нужно построить дерево ссылок, спланировать перенос, всех предупредить. Раздражает, что это тупая работа, которая не двигает вперед ни тебя, ни фирму. Просто слив времени из-за чужого косяка.
Похожая история случилась недавно на работе. Есть таблица с важными сущностями на двести штук. Кроме ключей, у них уникальные коды, которые производит внешняя система. Какой-то скрипт не проверил код на уникальность и добавил такую же. Долгое время использовались обе, и как теперь быть — непонятно.
Опытный разработчик знает, как исправить дубль; более опытный знает, как его не допустить.
При создании таблицы поле можно пометить словом
unique. При этом Postgres создаст уникальный btree-индекс на это поле. Заметим, что уникальность допускает значения NULL, потому что они не равны друг другу. Если нулы запрещены, добавьте в поле NOT NULL.Можно задать свой уникальный индекс, при этом использовать не колонку, а выражение. Например, уникальность кода или почты нужно проверять без учета регистра и отбрасывая пустые символы по краям. Индекс может быть таким:
create unique index idx_user_email_u_btree on users using btree (trim(lower(email)))После этого в базе не может быть емейлов
"Ivan@test.com"и" iVan@TEST.com "одновременно.Уникальность можно повесить на поле JSON-документа. Если код находится где-то в глубине, индекс выглядит так:
create unique index idx_item_code_u_btree on users using btree (lower(data #>> '{attrs,path,to,code}'))Следите за уникальностью. Добавить ее — дело пяти минут, исправлять последствия — пять дней.
-
Postgres №33
Разберем еще один случай, когда нужен срез строк – геохэш (geohash). Это быстрый и дешевый способ кодировать положение объектов, а также искать их.
Представим себе карту мира. Точки отсчета – Лондон и экватор. Это квадрат. Разделим его пополам по вертикали. Если человек живет западней Лондона, запишем 0, если восточнее – то 1. Теперь разделим область по горизонтали. Если человек находится северней, добавим 0, если южнее – 1. Продолжаем дробить область по горизонтали и вертикали и накапливать нули и единицы. В результате мы достигнем квадрата, достаточного малого, чтобы остановиться. Скажем, если речь о здании, квадрат может быть 25x25 метров. Если стадион, деревня или город, то еще больше.
Нули и единицы образуют цепочку бит. Переводим их в байты и кодируем base53 или похожим алгоритмом. Получаем строку вида
hsGHrgga3ysg6, которая указывает на квадрат определенной точности.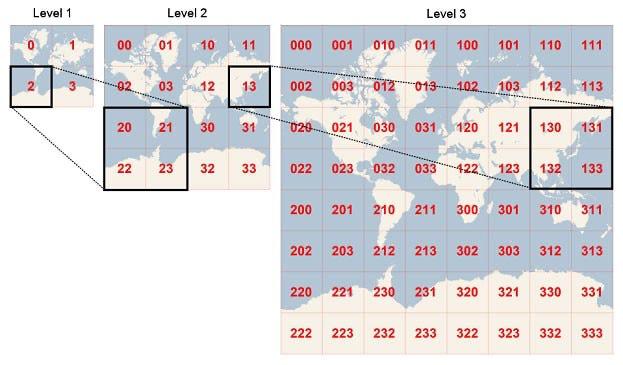
Прелесть вот в чем: есть взять какой-то квадрат, то хэши всех точек в нем имеют общую часть. Например, есть квадрат
hsGHrgga. В нем будут точкиhsGHrgga3ysg6,hsGHrgga3ysgS,hsGHrgga6sgи так далее. Это значит, для их поиска нужно выбрать строки, которые начинаются сhsGHrgga. С индексом btree, что мы рассмотрели в прошлом совете, это крайне эффективно.Похоже устроен поиск ближних объектов. Скажем, точка
hsGHrgga3ysg6указывает на кинотеатр и нужно показать ближайшие. Отломаем у хэша последний символ и таким образом поднимемся на квадрат выше:hsGHrgga3ysg. Найдем по нему все кинотеатры и покажем. Что-то лишнее можно почистить в приложении, так дешевле. Вопрос лишь в том, насколько “отъезжать” при поиске: на один символ, два и так далее.Недостаток геохеша в том, что один символ означает сразу восемь операций разбиения (потому что восемь битов). Если это критично, рассмотрите тип bit в Postgres. Это битовая маска заданной длины, при этом поддерживаются наложение другой маски, сравнение, вхождение и так далее.
Геохэш работает не только для плоскости, но и кубов. Пространство – это куб, который делится на 8 под-кубов, те – еще на 8 и так далее. Чтобы продвинуться на шаг, нужны три бита – по числу измерений. Такая структура называется октодеревом. По аналогии можно работать с многомерным пространством.
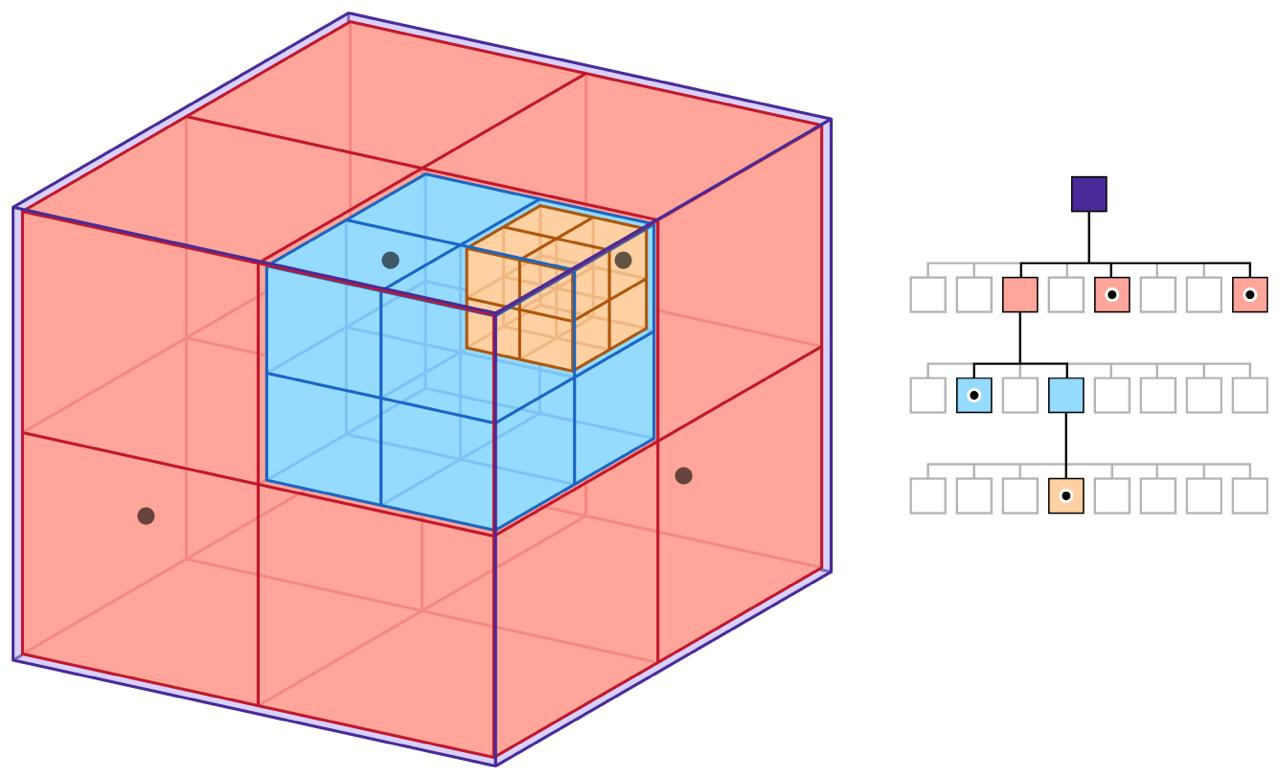
И не только многомерным – одномерным! Представим, на отрезке множество точек. Делим отрезок пополам: слева – 0, справа – 1. Переходим на нужный под-отрезок, делим пополам и так далее, пока не достигнем нужной точности. Накопленные нули и единицы кодируем в строку. Потом, чтобы получить точки в нужном отрезке, делаем срез по префиксу.
Все эти алгоритмы есть в PostGis и других гео-системах. Но знать их полезно, и порой они оказываются очень в тему. Однажды я писал свое дерево квадрантов, и оно заменило тяжелое решение.
Writing on programming, education, books and negotiations.