-
Совет дня №6
Если вы работаете с Postgres, команда COPY должна стать вашим другом. COPY перемещает данные с сервера на клиент и обратно в потоковом режиме. Она подходит для забора больших данных и вставки. COPY эффективнее, чем массовые INSERT и SELECT с пагинацией.
В режиме чтения COPY забирает данные из таблицы или произвольного запроса. Данные передаются в один из трех пунктов назначения: клиенту, в файл или процессу. Процессом может быть выражение, например
'gzip -9 > output.gzip'.В режиме записи COPY ожидает таблицу. Данные принимаются либо от клиента, либо из файла, либо от процесса.
С помощью COPY можно сделать потоковую обработку. В джаве для этого служит класс
CopyManager, который ожидаетOutputStream. Этот стрим можно обернуть вPipedInputStreamи читать его в другом потоке. Данные могут быть огромны, но вы не израсходуете память – все будет проходить в полете порциями.COPY позволяет забрать таблицу целиком, не выгружая результат в память. Я часто этим пользуюсь: каждое утро запускается задача, которая сбрасывает большие таблицы в файл. Позже я работаю с файлами, не напрягая базу.
Можно вставлять огромные таблицы через COPY параллельно в несколько потоков. Один поток колбасит первую четверть файла, второй – вторую и так далее. Прирост скорости почти линейный.
COPY поддерживает три формата данных: текстовый, CSV и двоичный. Первые два содержат данные в виде текста и отличаются разделителями. Их удобно просматривать, но числа занимают больше места, а многие символы экранируются. Двоичный формат компактный, в нем ничего не экранируется. Его структура довольно простая: фиксированный заголовок, потом набор строк. Каждая строка – набор пар (длина, содержимое). Если значение NULL, то длина равна -1, а содержимого нет.
COPY полезен в тестах: вместо того, чтобы вставлять данные штучно, можно хранить файлы CSV с именами таблиц. Специальная фикстура пробегает папку и копирует CSV в нужные таблицы. Файлы можно редактировать в Экселе.
В консоли psql есть команда \copy. Ее синтаксис в точности повторяет запрос COPY. Разница в том, что \copy связывает удаленный сервер с локальной машиной. Например, если выполнить
copy users (id, email) to '/path/to/file.csv' with (format csv), то файл будет создан на сервере Postgres. Если предварить copy обратной чертой, psql запросит с сервера поток и направит в локальный файл
/path/to/file.csv. По аналогии работает вставка:\copyчитает локальный файл и шлет поток сообщений.Надеюсь, я смог вас заинтересовать.
-
Совет дня №5
Если в запросе одно из условий – константа, это хороший кандидат на оптимизацию.
Предположим, у нас магазин, и нужно выбрать текущие заказы пользователя. Это примерно такой запрос:
select * from orders where user_id = ? and status = 'active'Из прошлого совета мы знаем, что два индекса на
user_idиstatusне работают. Будет использован только один, скорее всего дляuser_id, потому что у него высокая селективность (точность). Можно сделать составной индекс(status, user_id), и он будет быстрее обычногоuser_id.Есть, однако, еще один вариант: условный индекс по
user_idдля активных заказов. У оператораcreate indexна конце выражениеwhere:create index idx_users_user_id_active on orders (user_id) using btree where status = 'active'В чем прелесть такого индекса? Он намного меньше аналогов, потому что охватывает не всю таблицу, а ее подмножество. Если магазин появился не вчера, то большая часть заказов находится в статусе “доставлено”, и лишь малая часть активны. Эту часть и охватит индекс.
По условию
status = 'active'Postgres определит, что нужно взять именно этот индекс. Фактически условие будет отброшено, потому что значения в индексе уже отфильтрованы по нему.Скорость такого индекса ошеломительна: запрос может стать быстрее в 10–100 раз – без преувеличений.
Общее правило такое: всякие статусы, категории, флаг удаления и все прочее, что задается константой – кандидаты на выделенный индекс. Если каждый раз выбираются только активные пользователи, только текущие заказы, только не удаленные заявки – подумайте об условном индексе.
-
Совет дня №4
Предположим, в запросе условие по двум полям:
select * from items where foo = 1 and bar = 2Разработчик знает про индексы и добавляет их два: один на
foo, второй наbar. Логика такая: с одним индексом быстро, с двумя – еще быстрее.Ан нет: не все так просто. Как правило, Postgres использует только один индекс при обходе, потому что так быстрее. В этом легко убедиться, посмотрев план: там будет индекс либо на
foo, либо наbar, но не оба одновременно.Конечно, бывает, что используются оба индекса. Это возможно, если условия связаны через
ORи Postgres выбрал bitmap index scan, используются подзапросы, джоины. Но конкретно в нашем случае индекс будет один.Если условия соединяются через AND, задайте составной индекс на пару
(foo, bar). Он будет быстрее, чем то и другое поле по отдельности.Порядок полей в составном индексе важен. Желательно располагать их по нарастанию множественности, а кроме того, иметь в виду следующее. Составной индекс может быть использован, если известны его лидирующие компоненты. Например,
(foo, bar)сработает, если условие только наfoo. По аналогии, индекс(foo, bar, baz)сработает, если заданыfooиbar. Однако дляbarиbazон не подхватится.Планируйте составной индекс так, чтобы охватить как можно больше случаев.
-
Совет дня №3
Будьте осторожны с функцией “получить номер недели”. Независимо от языка и платформы, с ней легко прострелить ногу. И когда это случается? Конечно, на стыке годов в предновогоднюю неделю. Лучшее время, чтобы чинить баг.
Дело в том, что номер недели бывает разный. Есть обычный, когда день 2025-12-31 – это неделя 53. А есть ISO-шный, когда 2025-12-31 – это неделя 1. Скажем, в Postgres все способы извлечь неделю являются ISO:
select extract(week from '2025-12-31'::date); -- 1 select to_char('2025-12-31'::date, 'IW'); -- 01В Джаве больше контроля: есть поля
weekOfYearиweekOfWeekBasedYear:(.get (java.time.LocalDate/parse "2025-12-31") (.weekOfWeekBasedYear java.time.temporal.WeekFields/ISO)) ;; 1 (.get (java.time.LocalDate/parse "2025-12-31") (.weekOfYear java.time.temporal.WeekFields/ISO)) ;; 53Разумеется, их легко перепутать, и файлы уйдут не туда.
Кстати, в корпоративной программе учета часов в декабре нет недели 53. Если работал 29 и 30 декабря, добавляй часы вручную к неделе 52. Подозреваю, что дело в ISO-шном номере 1.
Поздравляю вас с еще одним поводом не расслаблять булки перед праздником.
-
Совет дня №2
Новый год, подарки, “запах мандарин”…, а это значит, пришла пора сделать вот что. Откройте свои проекты и убедитесь, что для форматирования дат используете
yyyy-MM-dd, а неYYYY-MM-dd. Буквы года должны быть маленькими!YYYY возвращает week-based year, а yyyy – обычный календарный. Прелесть в том, стреляет на границе годов. Примеры:
(format-date (LocalDate/now) "YYYY-MM-dd") "2026-12-30" (format-date (LocalDate/now) "yyyy-MM-dd") "2025-12-30"Если этого не учесть – мой случай – то за день до нового года файлы уедут в папку с 2026 годом. С чем вас и поздравляю.
-
Совет дня №1
Следите за тем, какие индексы используются, а какие нет. Для этого время от времени проверяйте представление
pg_stat_user_indexes. Оно накапливает случаи обращения к индексу. Сохраняются имя схемы, таблицы, индекса, дата последнего обращения, общее число обращений, число прочитанных элементов, число прочитанных строк. Пример:select * from pg_stat_user_indexes where relname = 'users' order by last_idx_scan desc nulls lastУдалите индексы с малым показателем
idx_scan. Сделайте такую проверку регулярной, например раз в месяц. -
Щели в интерфейсе
Если вы дизайните интерфейс, помните о следующем правиле: в интерфейсе не должно быть щелей. Всякие панели, сайдбары, палитры должны быть прижаты плотно. Между не должно быть зазора.
У зазоров две проблемы: первая – интерфейс занимает больше места. Если уж хочется отступа, добавь его внутри прямоугольника. Хотя и этот прием спорный: отступы – бич современности. Из-за пухлых кнопок и сайдбаров ничего не помещается на экран.
Вторая беда щелей в том, что они “сквозят”. Так я называю эффект, когда перематываешь контент, и сквозь щель что-то мелькает. Через три пикселя ты все равно ничего не разглядишь, но мельтешение отвлекает.
Кажется, в каком-то обновлении Фигмы сделали боковые панели, парящие в воздухе. Это было так плохо, что их вернули на место. Скриншота я не сохранил.
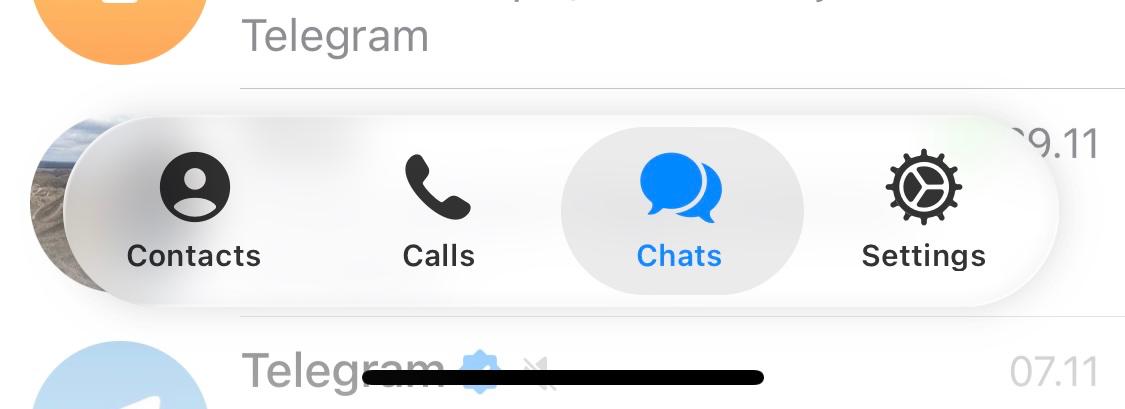
А вот другой пример. Обновил Телеграм на телефоне, и пожалуйста – дизайнер решил поиграться с жидким стеклом. Нижний бар стал пилюлей, которая висит в воздухе.
Что в ней плохого? Хотя бы то, что теперь она занимает больше места. Щель снизу бесполезна: ты же не будешь читать сообщение сквозь нее? (Хотя технически это возможно – настолько она большая.) Нормальный человек промотает вверх.
Какая-то загадка: почему новый интерфейс требует на один-два сантиметра больше? Откуда это? Я не понимаю.
-
Рейтинг пользователей на чистом SQL
Решил написать небольшой мануальчик по SQL. В нем рассматривается задача, которую я подсмотрел у Кирилла Мокевнина. Возможно, кому-то из вас ее дадут на собеседовании.
Задача следующая: сделать на сайте систему рейтинга. Пользователям начисляют баллы за разные достижения, и нужно вывести топ-100 пользователей. Позиция в рейтинге должна изменяться мгновенно. Например, кто-то получил 200 баллов и сразу оказался на вершине таблицы. Предполагается, что имеется только реляционная база данных, все остальное – по желанию.
Эта задача мне очень понравилась. Она лаконичная, но ее можно наращивать очень долго. Удивился тому, в комментариях – а у Кирилла довольно большая аудитория – почти никто не решил ее силами SQL. Большинство предлагали какие-то кэши, редисы-кафки, Firebase и прочую ахинею. Дело не в том, что это плохие инструменты. Наоборот, в нужных местах Редис и Кафка изумительны. Просто в данном случае их выбор ничем не обоснован.
Итак, давайте решим задачу силами ванильного Postgres. Чтобы разогреться, сначала сделаем небольшое послабление – предположим, что рейтинг нужно обновлять не мгновенно, а раз в час. Позже мы сделаем все как надо.
Подготовим таблицу пользователей:
create table users( id serial primary key, name text not null );Вставим в нее 100 тысяч случайных людей:
insert into users select n, format('User %s', n) from generate_series(1, 100000) as seq(n);Создадим таблицу для начислений баллов. Она хранит код пользователя, баллы и поле reason – опциональный комментарий за что эти баллы.
create table user_points( user_id integer not null, points integer not null dеfault 0, reason text );Начислим каждому пользователю десять раз случайное число баллов:
insert into user_points(user_id, points, reason) select n / 10 + 1, (random() * n)::int % 100, format('iteration %s', n) from generate_series(1, 1000000) as seq(n);Объявим материализованную вьюху. Ее запрос выбирает сумму баллов с группировкой по коду пользователя:
create materialized view mv_user_rating as select user_id, sum(points) as total_points from user_points group by user_id;Обновим ее:
refresh materialized view mv_user_rating;Добавим индекс по убыванию общего числа баллов и обновим его:
create index idx_mv_total_points on mv_user_rating using btree (total_points desc); analyze mv_user_rating;Теперь к сути: выберем топ-100 записей из вьюхи по убыванию суммы баллов. Подцепим джоином пользователей, выберем их имена. Запрос:
select u.id as user_id, u.name as user_name, mv.total_points as total_points from mv_user_rating mv, users u where mv.user_id = u.id order by mv.total_points desc limit 100;Частичный результат:
┌─────────┬────────────┬────────┐ │ user_id │ user_name │ points │ ├─────────┼────────────┼────────┤ │ 96 │ User 96 │ 1225 │ │ 45 │ User 45 │ 1185 │ │ 85 │ User 85 │ 1169 │ │ 10 │ User 10 │ 1140 │ │ 33 │ User 33 │ 1138 │ │ 80 │ User 80 │ 1135 │ │ 48 │ User 48 │ 1133 │ │ 53 │ User 53 │ 1121 │ │ 11 │ User 11 │ 1119 │ │ 91 │ User 91 │ 1099 │ │ 79 │ User 79 │ 1096 │ │ 56 │ User 56 │ 1090 │ │ 72 │ User 72 │ 1089 │ │ 31 │ User 31 │ 1088 │ │ 40 │ User 40 │ 1072 │ │ 97 │ User 97 │ 1070 │ │ 65 │ User 65 │ 1068 │ │ 42 │ User 42 │ 1058 │ │ 43 │ User 43 │ 1057 │ │ 78 │ User 78 │ 1054 │ │ 63 │ User 63 │ 1053 │ │ 54 │ User 54 │ 1049 │ │ 93 │ User 93 │ 1031 │ │ 29 │ User 29 │ 1029 │ │ 51 │ User 51 │ 1028 │ │ 100 │ User 100 │ 1027 │ │ 98 │ User 98 │ 1021 │ │ 69 │ User 69 │ 1014 │ │ 28 │ User 28 │ 1003 │ │ 67 │ User 67 │ 994 │ │ 60 │ User 60 │ 990 │ │ 21 │ User 21 │ 987 │ │ 58 │ User 58 │ 986 │ │ 26 │ User 26 │ 984 │Будет ли он тормозить? Посмотрим план:
explain analyze select u.id as user_id, u.name as user_name, mv.total_points as total_points from mv_user_rating mv, users u where mv.user_id = u.id order by mv.total_points desc limit 100; ├──────────────────────────────────────── │ Limit (cost=0.58..38.88 rows=100 width │ -> Nested Loop (cost=0.58..38292.36 │ -> Index Scan using idx_mv_tot │ -> Index Scan using users_pkey │ Index Cond: (id = mv.user │ Planning Time: 0.286 ms │ Execution Time: 0.368 ms └────────────────────────────────────────Обе таблицы попадают в индексы, стоимость – копейки. Поэтому ответ – не будет.
Теперь дело за тем, как обновлять вьюху. У материализованных вьюх особенность: во время обновления она недоступна. Можно обновлять их параллельно при помощи
refresh materialized view concurrently. Это медленней, зато не блокирует чтение. Попытаемся:refresh materialized view concurrently mv_user_rating; ERROR: cannot refresh materialized view "public.mv_user_rating" concurrently HINT: Create a unique index with no WHERE clause on one or more columns of the materialized view.Что такое? Дело в том, что для concurrently нужен хотя бы один уникальный индекс. По нему обновление вьюхи отслеживает свой прогресс. Добавим такой индекс:
create unique index idx_uq_mv_user_rating_user_id on mv_user_rating(user_id);Теперь параллельное обновление работает:
refresh materialized view concurrently mv_user_rating;Как сделать обновление регулярным? Поможет стороннее расширение
pg_cron. Из коробки его нет, но оно доступно во всех пакетах и установлено почти у всех облачных провайдеров. После установки включите его:create extension pg_cron;Добавьте задачу на расписание:
SELECT cron.schedule( 'cron_job_refresh_user_rating', 'refresh materialized view concurrently mv_user_rating;' );В результате каждый час вьюха будет обновляться параллельно. Для проверки регулярных задач и их истории служат специальные таблицы.
Это был прогрев. Напомню, что мы сделали послабление: обновляем рейтинг каждый час, а не мгновенно. Пора это исправить.
Вьюха становится не нужна, ее можно удалить. Вместо нее создайте таблицу аналогичной структуры:
create table user_total_points( user_id integer primary key, total_points integer not null dеfault 0 );Чтобы начислить пользователю баллы и одновременно изменить его рейтинг, нужно сделать два действия. Первое – записать баллы в таблицу
user_pointsкак мы делали это раньше. Второе – если в итоговой таблице есть пользователь, прибавить баллы к тем, что есть. Если нет – вписать туда пользователя и начальные баллы.На этом месте говорят “триггеры”, и зря. Триггеры – слишком сложный инструмент. Они слишком строгие, и порой это неудобно, например в разработке, в тестах, в моделировании ситуаций. Ниже мы решим задачу без триггеров.
Предположим, пользователю 999 начислено 100 баллов. Первый запрос будет таким:
insert into user_points(user_id, points) values (999, 100);Второй – посложнее. Это UPSERT в таблицу рейтинга, который либо вставляет данные, либо обновляет их:
insert into user_total_points(user_id, total_points) values (999, 100) on conflict(user_id) do update set total_points = user_total_points.total_points + excluded.total_points;Все это делается в транзакции, чтобы не допустить частичных изменений.
begin; -- query 1; -- query 2; commit;Выполним транзакцию два раза. В истории баллов будет две записи по 100, а в таблице рейтинга – их сумма 200.
select * from user_points; ┌─────────┬────────┬────────┐ │ user_id │ points │ reason │ ├─────────┼────────┼────────┤ │ 999 │ 100 │ <null> │ │ 999 │ 100 │ <null> │ └─────────┴────────┴────────┘ select * from user_total_points; ┌─────────┬──────────────┐ │ user_id │ total_points │ ├─────────┼──────────────┤ │ 999 │ 200 │ └─────────┴──────────────┘Транзакцию можно опустить, если переписать запрос на CTE. У таких запросов особенность – все они видят один снимок данных и выполняются атомарно. Это удобно, потому что транзакцию begin/end легко потерять, а в случае CTE это невозможно.
with step_1 as ( insert into user_points(user_id, points) values (999, 100) ) insert into user_total_points(user_id, total_points) values (999, 100) on conflict(user_id) do update set total_points = user_total_points.total_points + excluded.total_points;Выполним его три раза, и в таблице рейтинга окажется значение 500:
┌─────────┬────────┬────────┐ │ user_id │ points │ reason │ ├─────────┼────────┼────────┤ │ 999 │ 100 │ <null> │ │ 999 │ 100 │ <null> │ │ 999 │ 100 │ <null> │ │ 999 │ 100 │ <null> │ │ 999 │ 100 │ <null> │ └─────────┴────────┴────────┘ select * from user_total_points; ┌─────────┬──────────────┐ │ user_id │ total_points │ ├─────────┼──────────────┤ │ 999 │ 500 │ └─────────┴──────────────┘Если в базу пишут клиенты из разных систем, им будет неудобно таскать за собой этот запрос. Сделаем так: напишем функцию, которая принимает код пользователя и сколько баллов добавить. Функция возвращает суммарные баллы после всех изменений. Вот она:
create or replace function func_add_points (user_id integer, points integer) returns integer as $$ with step_1 as ( insert into user_points(user_id, points) values (user_id, points) ) insert into user_total_points(user_id, total_points) values (user_id, points) on conflict(user_id) do update set total_points = user_total_points.total_points + excluded.total_points returning total_points $$ language sql strict parallel safe;Теперь клиенты вызывают функцию select
func_add_points(1234, 500), а что внутри – их не касается. Функцию удобно вызывать из psql, если это баш-скрипт.Вот как накинуть баллы – и одновременно изменить рейтинг – некоторым пользователям из диапазона:
select n as user_id, func_add_points(n, n * 5) as total from generate_series(25, 50) seq(n); ┌─────────┬───────┐ │ user_id │ total │ ├─────────┼───────┤ │ 25 │ 125 │ │ 26 │ 130 │ │ 27 │ 135 │ │ 28 │ 140 │ │ 29 │ 145 │ │ 30 │ 150 │ │ 31 │ 155 │ │ 32 │ 160 │ │ 33 │ 165 │ │ 34 │ 170 │ │ 35 │ 175 │ │ 36 │ 180 │ │ 37 │ 185 │ │ 38 │ 190 │ │ 39 │ 195 │ │ 40 │ 200 │ │ 41 │ 205 │ │ 42 │ 210 │ │ 43 │ 215 │ │ 44 │ 220 │ │ 45 │ 225 │ │ 46 │ 230 │ │ 47 │ 235 │ │ 48 │ 240 │ │ 49 │ 245 │ │ 50 │ 250 │ └─────────┴───────┘Функцию можно вызывать параллельно. Давайте накинем баллов пользователю 1003 и посмотрим на результат:
select user_id, points, func_add_points(user_id, points) as total from (values (1003, 3), (1003, 2), (1003, 1), (1003, 5), (1003, 7)) as vals(user_id, points); ┌─────────┬────────┬────────┐ │ user_id │ points │ total │ ├─────────┼────────┼────────┤ │ 1003 │ 3 │ 3 │ │ 1003 │ 2 │ 5 │ │ 1003 │ 1 │ 6 │ │ 1003 │ 5 │ 11 │ │ 1003 │ 7 │ 18 │ └─────────┴────────┴────────┘Видим, что итоговая сумма приращивалась каждый раз правильно.
Теперь делаем то же самое, что и со вьюхой. Добавим индекс по убыванию баллов:
create index idx_total_points on user_total_points using btree (total_points desc);Выберем из таблицы рейтинга топ-100 записей, приклеим пользователей и готово:
select u.id as user_id, u.name as user_name, total.total_points as total_points from user_total_points total, users u where total.user_id = u.id order by total.total_points desc limit 100; ┌─────────┬───────────┬───────┐ │ user_id │ user_name │ total │ ├─────────┼───────────┼───────┤ │ 999 │ User 999 │ 1500 │ │ 50 │ User 50 │ 250 │ │ 49 │ User 49 │ 245 │ │ 48 │ User 48 │ 240 │ │ 47 │ User 47 │ 235 │ │ 46 │ User 46 │ 230 │ │ 45 │ User 45 │ 225 │ │ 44 │ User 44 │ 220 │ │ 43 │ User 43 │ 215 │ │ 42 │ User 42 │ 210 │ │ 41 │ User 41 │ 205 │ │ 40 │ User 40 │ 200 │ │ 39 │ User 39 │ 195 │ │ 38 │ User 38 │ 190 │ │ 37 │ User 37 │ 185 │ │ 36 │ User 36 │ 180 │ │ 35 │ User 35 │ 175 │ │ 34 │ User 34 │ 170 │ │ 33 │ User 33 │ 165 │ │ 32 │ User 32 │ 160 │ │ 31 │ User 31 │ 155 │ │ 30 │ User 30 │ 150 │ │ 29 │ User 29 │ 145 │ │ 28 │ User 28 │ 140 │ │ 27 │ User 27 │ 135 │ │ 26 │ User 26 │ 130 │ │ 25 │ User 25 │ 125 │ └─────────┴───────────┴───────┘Одно из улучшений вот в чем. Выше у каждого пользователя разное число баллов, и нет случаев, когда двое участников делят одно место. Давайте добавим пользователю 49 пять баллов, чтобы уравнять его с пользователем 50:
select func_add_points(49, 5); ┌─────────────────┐ │ func_add_points │ ├─────────────────┤ │ 250 │ └─────────────────┘Их место будет неоднозначно: мы сортируем по убыванию суммы баллов, но если значения равны, порядок записей не гарантируется. Чтобы участники не спорили, кто на втором, а кто на третьем месте, вычислим плотный ранг. Это оконная функция, которая учитывает поля с одинаковым значением. Обычный ранг нумерует записи подряд, а плотный – с учетом повторов. Запрос:
select u.id as user_id, u.name as user_name, total.total_points as total_points, dense_rank() over w as rank from user_total_points total, users u where total.user_id = u.id window w as (order by total_points desc) order by total_points desc limit 100;Результат:
┌─────────┬───────────┬───────┬──────┐ │ user_id │ user_name │ total │ rank │ ├─────────┼───────────┼───────┼──────┤ │ 999 │ User 999 │ 1500 │ 1 │ │ 50 │ User 50 │ 250 │ 2 │ │ 49 │ User 49 │ 250 │ 2 │ │ 48 │ User 48 │ 240 │ 3 │ │ 47 │ User 47 │ 235 │ 4 │ │ 46 │ User 46 │ 230 │ 5 │ │ 45 │ User 45 │ 225 │ 6 │ │ 44 │ User 44 │ 220 │ 7 │ │ 43 │ User 43 │ 215 │ 8 │ │ 42 │ User 42 │ 210 │ 9 │ │ 41 │ User 41 │ 205 │ 10 │ │ 40 │ User 40 │ 200 │ 11 │ │ 39 │ User 39 │ 195 │ 12 │ │ 38 │ User 38 │ 190 │ 13 │ │ 37 │ User 37 │ 185 │ 14 │ │ 36 │ User 36 │ 180 │ 15 │ │ 35 │ User 35 │ 175 │ 16 │ │ 34 │ User 34 │ 170 │ 17 │Теперь участники 49 и 50 делят второе место, и неоднозначность ушла.
Собственно, вот как решить эту задачу силами SQL. Не понадобились кафки, распределенные кэши и все остальное. Схема простая и быстрая, ее легко объяснить.
Любите Постгрес! Учите Пострес! Всем любви и добра.
-
На чем писать
Существует расхожее мнение о том, что на чем писать. Так, почему-то многие уверены, что банк должен быть написан на Джаве. Потому что банк должен быть надежным, а Джава – надежная. При этом в чем именно надежность, не уточняется.
Ну да, статический анализ. Только как он спасет от деления на ноль? От ошибки подключения к базе? От троттлинга в сетевых сервисах? От того, что файла нет? От коллеги, который не выкатил фикс? Это для меня загадка.
Я работаю в крупном финтехе. Таком большом, что подобно муравью, вижу лишь крохотную его часть. При этом у нас Кложа, все динамическое – и работает. Не припомню, когда в последний раз я ожидал число, а пришла строка. Может, и было такое пару лет назад, это не важно. Гораздо больше других проблем: потоки данных и зависимости сервисов. Что нужно кому, кто откуда что получает и куда складывает. В какое время данные появляются и до какого момента нужно записать новые, чтобы другие службы подхватили.
Проблему можно описать так: миллион зависимостей. Между файлами, сервисами, людьми, отделами. Она не решается языком программирования. Если точнее, проблему можно облегчить, взяв тот язык, который снижает когнитивную нагрузку. Просто ради того, чтобы, победив очередную организационную проблему, у тебя остались силы на код.
Рассуждения о том, что какие-то вещи нужно писать на конкретном языке – пустые слова. Правильно брать ту технологию, с которой легче двигаться и которая быстро дает результат. Если у вас армия джавистов, то это одно. Если отряд питонистов, которых силой переучивают на Джаву, это другое – и хуже.
Скажем, Postgres написан на Си, и это одна их стабильнейших вещей на свете. А недавно чудаки в Cloudflare написали конфиг-парсер на Расте и уронили половину интернета. Вот она, ваша пресловутая надежность.
Так что писать можно что угодно на чем угодно. Не уподобляйтесь деревенскому гопнику, который знает, какой прикид правильный, а какой нет и в каком ухе должна быть серьга.
-
Впечатления от читалки Kindle десять лет спустя
Почти десять лет назад я купил читалку Kindle Paperwhite. О ней я писал первую заметку, через два года — вторую.
Иногда я про нее забывал, и она месяцами лежала разряженная. Недавно я снова достал ее с полки, протер, зарядил. Закинул серию статей на тему, которую давно хотел освоить. Теперь почитываю в фоне, ожидая детей на секциях и кружках.
Интересно взглянуть на читалку современным взглядом. Первое, что бросается в глаза — устройство крайне молчаливо. Оно просто работает! Закинул — прочил, закинул — прочитал. Никаких нотификаций, попапов, выпадашек. Читалка ничего не спрашивает — никогда и ни при каких условиях.
Уже стало нормой, что, открывая мобильное приложение, первым делом закрываешь баннеры. У читалки этого нет, хотя технически ничто не мешает это сделать. Открыл читалку — пройди опрос! Открыл еще раз — участвуй в розыгрыше призов! Открыл в третий раз — получи бесплатную книгу-нейрослоп! Я прямо возмущен — куда смотрят маркетологи? На ровном месте пропадает столько показов рекламы.
Далее обновления. За эти десять лет устройство обновило прошивку только раз, примерно через месяц после покупки. Остальное время оно работает как есть. Видимо, инженеры спроектировали его столь удачно, что добавить сверху нечего. Тоже удивительно.
Еще один интересный факт: за десять лет меня ни разу не разлогинило. Как ввел учетную запись при первом запуске, так она и работает. Напомню, иной раз читалка лежала разряженная в ноль месяцами, и ничего — при запуске всякие токены-шмокены подхватились.
Устройство удобно в плане коммуникации. Воткнул в комп и видишь файловую систему. Но еще удобней слать статьи на почту: отправил письмо с документами на
username@kindle.com— и через минуту они на устройстве.Для отправки веб-страниц служит расширение Push to Kindle (сервис Five Filters). Оно очень качественное и выдает красивую верстку. Формально действует ограничение: не более 10 статей в месяц, но при переходе в анонимный режим счетчик сбрасывается.
Единственная претензия — после десяти лет немного просела батарея. Раньше заряда хватало без преувеличения на месяц, а теперь — максимум на неделю. Впрочем, и это хороший показатель. В иных устройствах аккумуляторы деградируют за год.
По сегодняшним меркам Kindle Paperwhite — это устройство из другого мира. Оно слишком качественное, простое, функциональное. Пользуешься — и буквально чувствуешь его простоту и бесхитростность. В его дизайне на первое место ставили интерес пользователя — бывает же!
Изумительная вещь.
Writing on programming, education, books and negotiations.