-
Табы
Иногда нам все-таки везет с дизайнерами.
В Firefox у вкладок есть особенность: когда их больше определенного числа, они перестают сжиматься и превращаются в прокрутку. Это прекрасно, потому что часть заголовка видна, и можно понять, где что.
А в Хроме и его форках наоборот: вкладки будут бесконечно уменьшаться, пока не останется крестик. Полный фейл: непонятно, что за вкладка, пока не тыкнешь на нее. Порой как дурак кликаешь методом перебора. Легко попасть на крестик и закрыть.
Ясно, что табы нужно прореживать, чтобы не было открыто лишнее. Но в пиковые моменты, например, при лихорадочном поиске решения, их бывает много, хочешь того или нет.
Мораль в том, что табы хороши, но бесконечно сжимать их не нужно. В определенный момент их нужно прокручивать.
-
Soft delete
Многие знают о технике мягкого удаления. Это когда записи не удаляются физически из базы, а помечаются флажком
is_deletedили выставляется времяdeleted_at. Удобно, что ничего не удаляется, не нужно воевать с внешними ключами и ограничением целостности. Самое главное — если что-то пошло не так, то снял флажок, и данные на месте.Все это хорошо, и я тоже так думал, пока не поработал в одном проекте. Там была огромная база с кучей таблиц и техникой мягкого удаления. Только тогда я понял, что это билет в ад.
Начнем с того, что удаленные записи отнимают место на диске. За несколько лет их набегает порядочное количество. Удаленные записи по-прежнему участвуют в индексах, и они тоже занимают место, замедляют обход. В Постгресе есть функциональные индексы когда запись попадает только при условии
NOT is_deletedилиdeleted_at IS NULL. Но чаще всего этим не заморачиваются, и в индекс валится все.Бывает, удаленная запись мешает критерию уникальности, и тогда ее выключают из уникального индекса. Например, поле
emailуникально только среди не удаленных пользователей. Поэтому записи как в примере нижеemail | is_deleted -----------------|------- ivan@grishaev.me | false ivan@grishaev.me | trueмогут спокойно сосуществовать. Но восстановить вторую запись нельзя, потому что она вступит в конфликт с первой. Спрашивается: зачем мы ее храним? Что с ней можно сделать? Ничего. Это просто балласт.
Что касается запросов, то разработчики часто забывают условие
WHERE NOT is_deleted, и в выборке оказываются удаленные данные.А в другом проекте было по-другому: проблему удаления решали переносом в другие таблицы. Например, для таблицы messages создается ее аналог
messages_deleted. Запись переносится атомарно таким запросом:with deleted as (delete from messages where id = 42 returning *) insert into messages_deleted select * from deletedПеренос обратно:
with deleted as (delete from messages_deleted where id = 42 returning *) insert into messages select * from deletedЕсть и другой вариант этого запроса без выражения
WITH; можно сделать это триггером, хоть я и не люблю их. Важно, что запрос выполняется атомарно даже если не заключен в транзакцию. При этом запись переходит между таблицами на стороне сервера. Она даже не приходит клиенту.На первый взгляд это неудобно, потому что нужны лишние таблицы. Но как замечательно это оказалось на практике! В основной таблице только актуальные данные, никаких флажков и предикатов. Выбирая что-то из messages, ты на 100% уверен, что нет риска выбрать что-то не то. Данные всегда в чистоте. Если однажды мы решим, что удаленные сообщения не нужны, мы грохнем таблицу messages_deleted без риска задеть живые данные.
С тех пор я придерживаюсь переноса, если это возможно.
Принцип “я ничего не удаляю” аналогичен принципу “я ничего не выбрасываю”. С ним база, простите меня, засирается. И хотя перенос данных не значит их удаление, он очищает рабочую область — а это крайне важно.
-
Чтение
Когда говорят о пользе чтения, забывают еще кое-что: оно отлично снимает стресс.
Неважно, что вы читаете — классику и техническую вещь — но эффект чтения потрясен. Мир словно останавливается, и все проблемы ждут, пока ты читаешь. Отрываясь наконец от книги, не испытываешь сожаления о потраченном времени, как это часто бывает с телефоном.
Разумеется, речь идет о чтении с бумаги, а не с экрана, поэтому телефоны, читалки и планшеты идут мимо кассы. Они по-своему полезны, но того эффекта, что дает бумага, с ними достичь нельзя.
В интернете полно экспертов, которые советуют: технические книги надо читать на английском, а если классику, то именно то, а не другое. На самом деле только один человек знает, что нужно читать, и это вы. Пробуешь разные жанры и языки и что понравилось — то и читаешь, неважно что советуют псевдо-эксперты.
Я спокойно читаю технические книги на русском, если, конечно, перевод не совсем уж плохой. Все больше книг пишутся русскими авторами. Книги “Postgres изнутри” Егора Рогова и “Postgres: основы SQL” Моргунова — просто отпад. Они написаны на русском, а первую уже перевели на английский. Попадались хорошие книги русских авторов и по другим технологиям.
Классику, наоборот, пытаюсь осилить на английском, и это полно открытий. Другая грамматика, устаревшие слова и их порядок — казалось бы, английский, но не то, что читаешь в интернете. Старая книжка на английском — это прям квест. Даже Оруэлл сильно отличается от современного американского, хотя прошло-то чуть больше полувека.
Из классиков люблю Гоголя: беру наугад любой том и залипаю на полчаса. Булгаков тоже хорош, в том числе его раннее творчество. Люблю Дон Кихота, Остров сокровищ, Оруэлла. Имена не имеют значения, важно то, что в принципе есть что почитать.
Чтение дает мозгу отдых. Когда очередной погорелец заводит песню о том, что выгорел, я мысленно спрашиваю: когда ты в последний раз читал? Не Хакер-ньюз с телефона, а бумажную книжку? У тебя вообще книги есть или только телефон с ноутом?
При этом я не считаю себя Д’Артаньяном: я читаю мало, и лишь недавно очнулся после года тупняка. Это заметка — скорее напоминалка себе: меньше тупить в экран и больше читать.
-
Наедине
Разговаривая с кем-то, помните: разговор один на один и при свидетелях — это разные вещи.
Беседа с ребенком наедине — совершенно не то, что получится, если рядом брат или сестра, не говоря уж о приятеле.
Разговор с близким человеком, когда рядом другие родственники, становится сценой из “Уральских пельменей”.
Разговор с коллегой, если рядом начальник, бесполезен. Разговор с начальником, если рядом коллега, тоже лишен смысла. Почему?
Потому что при свидетелях собеседник занят одной мыслью: как бы прикрыть свой зад и не потерять репутацию. Даже если он неправ или накосячил, то с упорством барана будет стоять на своем. Будет обвинять других, обстоятельства, травмы детства, что угодно, но не свой промах.
При свидетелях человек, до того как ответить, продумывает, чем обернется для него ответ. Никакого смысла в таком разговоре нет, потому что нет искренности.
Вот почему, чтобы выяснить истинную природу вещей, с людьми нужно разговаривать по одному и потом соединять данные в общую картину.
По этой же причине я не пойму одержимость групповыми звонками. Собираются десять человек в зуме и обсуждают, как идут дела. Разумеется, ни один не скажет неудобную правду, все на позитиве. Менеджер уверен, что в курсе дела, в то время как у каждого целый список того, чем он недоволен.
Так и живут большие фирмы: постоянное двоемыслие. Будь менеджер умнее, он бы назначил регулярный разговор с глазу на глаз с каждым членом команды минут на 15. Но нет, у него дейли по два часа, планнинг, пост-мортем и другие коллективные штучки.
Не совершайте эту ошибку: говорите с людьми только наедине.
-
Эмодзи
Чего я не могу понять, так это эмодзи.
Скажем, человек пишет в объявлении, что продает щенка. И ставит морду щенка. Зачем? Речь о щенке, и после него морда щенка. Масло масляное. То же самое с автомобилем, ноутбуком и прочим: за словом следует иконка того, о чем написано. Зачем? Я уже понял, что речь о щенке или ноутбуке, зачем ставить то же самое?
Или списки. У нас были цифры, буллиты, тире — но нет, этого мало. Теперь канцелярские кнопки и желтые пальчики, которые указывают, где читать.
Или молнии: каждый клоун ставит молнию к новому сообщению в телеграме.
Иногда с эмодзи пытаются в пассивную агрессию: что-то пишут и ставят фейспалм или блюющий рот. Слабоватый прием, честно скажем.
Программисты тоже деградируют: в консоли все больше эмодзи. В основном этим страдает Node.js. Наверное, нет такого пакета, который бы не вывел единорога, искорки и прочего хлама.
Иные люди тратят дни и месяцы, чтобы затащить эмодзи туда, где их раньше не было. Даже не знаю, что им сказать. К счастью, эмодзи до сих пор плохо дружат с печатью. В мире InDesign и LaTeX их либо избегают, либо вставляют вручную. Это один их тех бастионов, что еще держатся.
С тем же непонимание я отношусь к лигатурам: какой смысл в завитушках в коде? У меня есть роскошное издание Дон Кихота, и там лигатуры очень кстати. И то не везде, а только в иллюстрациях и подписях к ним. Почему-то сорок лет назад понимали, что лигатуры отвлекают от чтения. А сегодня это знание утеряно.
Делают шрифты, где лигатуры охватывают три, четыре и больше символов. Написал TODO и вжух — оно стало неделимым блоком, по-дурацки выделятся на общем фоне. Всякие стрелочки и скобки слипаются в неожиданных местах. Мне хватило минуты, чтобы понять — никогда не поставлю лигатурный шрифт.
Напоминает проблему современных мессаджеров. Хочешь отправить текстовый смайлик — и он становится желтым колобком. Я не хочу колобок, я хочу текст. Раньше я добавлял ему нос из тире :—) и алгоритм пропускал его. Но технологии не стоят на месте: теперь и этот паттерн превращается в колобка.
Я не понимаю, почему никто не скажет — вы, программисты, которые затащили все это, молодцы. Умеете, могете. Но это лишнее. Оставьте эмодзи для тупых чатов с одноклассниками в ватсаппе. Оставьте лигатуры для иллюстраций и подарочных изданий. Не тащите это дерьмо во все щели. Не надо, правда.
Желаю вам больше эмодзи, пальчиков, смайликов, щеночков и лигатур.
-
AWS, история четвертая. Когда null не совсем null
Все статьи из цикла AWS
- Амазон
- AWS, история первая. Внезапный мегабайт
- AWS, история вторая. Афина прекрасная
- AWS, история третья. Разрывы
- AWS, история четвертая. Когда null не совсем null
Еще одна история о том, как Амазон может попить крови.
Напомню особенности нашей архитектуры. Сервисы записывают в S3 сущности разных типов. Их может быть много, например, полтора миллиона такого-то типа. Чтобы выгрести сущности разом, мы используем чудо-оружие Амазона — сервис Athena. Он собирает файлы из бакета и склеивает в один CSV.
Среди сущностей встречаются выбракованные, и при обходе CSV их нужно игнорировать. Один из признаков брака — вложенное поле
attrs, которое равноnull. Не проблема: получаю ленивую коллекцию сущностей и накладываю на нее фильтр:(->> csv (get-lazy-seq ...) (filter (fn [entity] (-> entity :attrs nil?))))На проде, по различным логам и эксепшенам, вижу, что битые сущности просочились в обработку. Как так?
А вот как: в оригинальном JSON поле attrs было
null, все верно. Но при агрегации в CSV Амазон экранируетnullкавычками и получается\"null\". При этом его не волнует, чтоnullнаходится в середине JSON-строки, которая уже экранирована. Какой-то парсер доходит доnullи пишет его с кавычками.В результате при чтении JSON получается
{"attrs": "null"}, то есть строка с буквами n, u, l, l. Чтобы выкинуть эту запись, я переписал фильтр так:(or (-> aggregate :attrs nil?) (-> aggregate :attrs (= "null")))Спрашивается, зачем я оставил первый вариант с чистым
nil?Потому что, если однажды мы перейдем на другое хранилище, поле опять станет null вместо"null", и фикс придется откатывать. А так оба случая покрыты: и нормальный, и кривой.Разумеется, прикол с
nullнигде не описан, в Гугле ничего нет. Счастливой отладки, уважаемые коллеги!Вот так я потерял еще один день. Каждый раз, распутав новый квест от Амазона, откидываюсь в кресле и тихо матерюсь. А затем иду дальше.
-
Весенняя чистка
Несколько лет назад я удалился из всех соцсетей — всех без исключения. Ни разу не пожалел: было лишь два раза, когда нужно было догнать человека в условном ВК. В таких случаях я пишу с телефона жены, прошу почту и дальше общаюсь по почте. Если у человека нет почты, а только ВК, то скорее всего, нас ничего не связывает.
То же самое делаю с Телеграмом: выхожу из всех каналов и чатов. Покинул кложурный чатик, джавный, LaTeX, местное айти-комьюнити, в создании которого участвовал, и многое другое.
Остались: человек не про айти, человек про айти и канал банка. Из последнего тоже думаю выйти: важной информации мало, сплошные вебинары и графомания а-ля “открываем кофейню”. Важную информацию так или иначе дублируют в приложении.
Спрашивается, зачем выходить? Нельзя что ли спрятать каналы в архив? Я и сам не знаю: просто хочется сократить информационный шум. Заметил, что все эти чаты и каналы приносят мало пользы, но потребляют внимание. Они развивают потребность без конца открывать телефон и проверять, что новенького. На это легко подсесть, а отучиться сложно.
Мне возражают: да, информации много, но как тогда находить что-то новое? Ответ прост: случайно. Просто раз в две недели просматривать популярные ресурсы, и если там было что-то стоящее, скорее всего оно будет на главной. А если нет — что ж, не повезло, вы об этом не узнаете.
Не вижу повода расстраиваться. В мире полно хороших статей и видео, но мы о них не знаем. На условном Хабрахабре примерно одна из ста публикаций полезна, но ради нее нужно пролистать 99 других, полных рекламы, написанных копирайтерами за 100 рублей, или вообще сделанных Гугло-переводчиком. У меня такого желания нет.
Наконец, на любой канал можно подписаться опять и даже прочесть все, что вы пропустили. Но пока что сожаления нет, и надеюсь, не будет и в будущем.
-
В консоле
Забавляет, когда пишут “посмотри в консоле”. Получается, что консоль — существительное мужского рода? В пенале, в профиле, в консоле.
Часто ошибаются с постелью. Я еще в постеле. Опоздал на звонок, потому что в постеле. Опять мужской род.
Из комментариев: я живу в Рязане. А я в Казане! А я на Кубане!
Самые невезучие слова — это исключения “бреет” и “стелет”. У рэперов есть выражение “стелить”, то есть удачно складывать рифмы. В комментариях на Ютубе частенько встречается: классно стелишь, бро.
Интересно, есть ли хоть один рэпер, который пишет “стелешь” правильно? Сомневаюсь.
-
PG2 release 0.1.11: HugSQL support
The latest 0.1.11 release of PG2 introduces HugSQL support.
The
pg2-hugsqlpackage brings integration with the HugSQL library. It creates functions out from SQL files like HugSQL does but these functions use the PG2 client instead of JDBC. Under the hood, there is a special database adapter as well as a slight override of protocols to make inner HugSQL stuff compatible with PG2.Since the package already depends on core HugSQL functionality, there is no need to add the latter to dependencies: having
pg2-hugsqlby itself will be enough (see Installation).Basic Usage
Let’s go through a short demo. Imagine we have a
demo.sqlfile with the following queries:-- :name create-demo-table :! create table :i:table (id serial primary key, title text not null); -- :name insert-into-table :! :n insert into :i:table (title) values (:title); -- :name insert-into-table-returning :<! insert into :i:table (title) values (:title) returning *; -- :name select-from-table :? :* select * from :i:table order by id; -- :name get-by-id :? :1 select * from :i:table where id = :id limit 1; -- :name get-by-ids :? :* select * from :i:table where id in (:v*:ids) order by id; -- :name insert-rows :<! insert into :i:table (id, title) values :t*:rows returning *; -- :name update-title-by-id :<! update :i:table set title = :title where id = :id returning *; -- :name delete-from-tablee :n delete from :i:table;Prepare a namespace with all the imports:
(ns pg.demo (:require [clojure.java.io :as io] [pg.hugsql :as hug] [pg.core :as pg]))To inject functions from the file, pass it into the
pg.hugsql/def-db-fnsfunction:(hug/def-db-fns (io/file "test/demo.sql"))It accepts either a string path to a file, a resource, or a
Fileobject. Should there were no exceptions, and the file was correct, the current namespace will get new functions declared in the file. Let’s examine them and their metadata:create-demo-table #function[pg.demo...] (-> create-demo-table var meta) {:doc "" :command :! :result :raw :file "test/demo.sql" :line 2 :arglists ([db] [db params] [db params opt]) :name create-demo-table :ns #namespace[pg.demo]}Each newborn function has at most three bodies:
[db][db params][db params opt],
where:
dbis a source of a connection. It might either aConnectionobject, a plain Clojure config map, or aPoolobject.paramsis a map of HugSQL parameters like{:id 42};optis a map ofpg/executeparameters that affect processing the current query.
Now that we have functions, let’s call them. Establish a connection first:
(def config {:host "127.0.0.1" :port 10140 :user "test" :password "test" :dbname "test"}) (def conn (jdbc/get-connection config))Let’s create a table using the
create-demo-tablefunction:(def TABLE "demo123") (create-demo-table conn {:table TABLE}) {:command "CREATE TABLE"}Insert something into the table:
(insert-into-table conn {:table TABLE :title "hello"}) 1The
insert-into-tablefunction has the:nflag in the source SQL file. Thus, it returns the number of rows affected by the command. Above, there was a single record inserted.Let’s try an expression that inserts something and returns the data:
(insert-into-table-returning conn {:table TABLE :title "test"}) [{:title "test", :id 2}]Now that the table is not empty any longer, let’s select from it:
(select-from-table conn {:table TABLE}) [{:title "hello", :id 1} {:title "test", :id 2}]The
get-by-idshortcut fetches a single row by its primary key. It retursnilfor a missing key:(get-by-id conn {:table TABLE :id 1}) {:title "hello", :id 1} (get-by-id conn {:table TABLE :id 123}) nilIts bulk version called
get-by-idsrelies on thein (:v*:ids)HugSQL syntax. It expands into the following SQL vector:["... where id in ($1, $2, ... )" 1 2 ...]-- :name get-by-ids :? :* select * from :i:table where id in (:v*:ids) order by id;(get-by-ids conn {:table TABLE :ids [1 2 3]}) ;; 3 is missing [{:title "hello", :id 1} {:title "test", :id 2}]To insert multiple rows at once, use the
:t*syntax which is short for “tuple list”. Such a parameter expects a sequence of sequences:-- :name insert-rows :<! insert into :i:table (id, title) values :t*:rows returning *;(insert-rows conn {:table TABLE :rows [[10 "test10"] [11 "test11"] [12 "test12"]]}) [{:title "test10", :id 10} {:title "test11", :id 11} {:title "test12", :id 12}]Let’s update a single row by its id:
(update-title-by-id conn {:table TABLE :id 1 :title "NEW TITLE"}) [{:title "NEW TITLE", :id 1}]Finally, clean up the table:
(delete-from-table conn {:table TABLE})Passing the Source of a Connection
Above, we’ve been passing a
Connectionobject calledconnto all functions. But it can be something else as well: a config map or a pool object. Here is an example with a map:(insert-rows {:host "..." :port ... :user "..."} {:table TABLE :rows [[10 "test10"] [11 "test11"] [12 "test12"]]})Pay attention that, when the first argument is a config map, a Connection object is established from it, and then it gets closed afterward before exiting a function. This might break a pipeline if you rely on a state stored in a connection. A temporary table is a good example. Once you close a connection, all the temporary tables created within this connection get wiped. Thus, if you create a temp table in the first function, and select from it using the second function passing a config map, that won’t work: the second function won’t know anything about that table.
The first argument might be a Pool instsance as well:
(pool/with-pool [pool config] (let [item1 (get-by-id pool {:table TABLE :id 10}) item2 (get-by-id pool {:table TABLE :id 11})] {:item1 item1 :item2 item2})) {:item1 {:title "test10", :id 10}, :item2 {:title "test11", :id 11}}When the source a pool, each function call borrows a connection from it and returns it back afterwards. But you cannot be sure that both
get-by-idcalls share the same connection. A parallel thread may interfere and borrow a connection used in the firstget-by-idbefore the secondget-by-idcall acquires it. As a result, any pipeline that relies on a shared state across two subsequent function calls might break.To ensure the functions share the same connection, use either
pg/with-connectionorpool/with-connectionmacros:(pool/with-pool [pool config] (pool/with-connection [conn pool] (pg/with-tx [conn] (insert-into-table conn {:table TABLE :title "AAA"}) (insert-into-table conn {:table TABLE :title "BBB"}))))Above, there is 100% guarantee that both
insert-into-tablecalls share the sameconnobject borrowed from the pool. It is also wrapped into transaction which produces the following session:BEGIN insert into demo123 (title) values ($1); parameters: $1 = 'AAA' insert into demo123 (title) values ($1); parameters: $1 = 'BBB' COMMITPassing Options
PG2 supports a lot of options when processing a query. To use them, pass a map into the third parameter of any function. Above, we override a function that processes column names. Let it be not the default
keywordbutclojure.string/upper-case:(get-by-id conn {:table TABLE :id 1} {:fn-key str/upper-case}) {"TITLE" "AAA", "ID" 1}If you need such keys everywhere, submitting a map into each call might be inconvenient. The
def-db-fnsfunction accepts a map of predefined overrides:(hug/def-db-fns (io/file "test/demo.sql") {:fn-key str/upper-case})Now, all the generated functions return string column names in upper case by default:
(get-by-id config {:table TABLE :id 1}) {"TITLE" "AAA", "ID" 1}For more details, refer to the official HugSQL documentation.
-
Preview и текст
Обнаружил, что программа Preview на Маке распознает текст на картинках. Выглядит так. Исходник:

и процесс копирования:
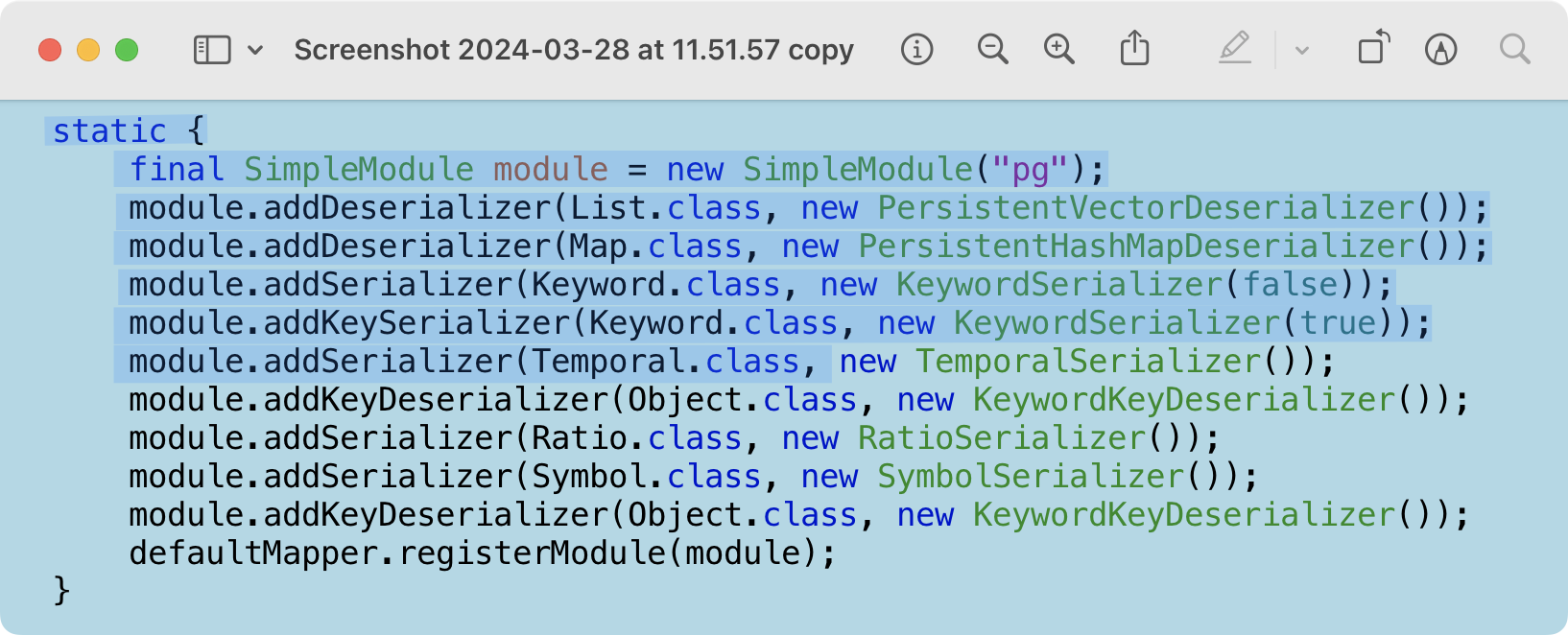
Озарение пришло после того, как я привычно выделил текст, думая, что работаю с PDF. И только потом заметил, что это PNG.
Распознавание работает неплохо, разве что слетают лидирующие пробелы. Но это ничего: достаточно вставить в редактор, выделить и нажать TAB — и все починится.
Это еще один довод в пользу Preview. Я уже писал об этой программе и повторю — это произведение искусства. Она умеет невероятно много для работы с картинками и PDF. Доступна из коробки, бесплатна.
Больше всего я ценю ее за скромность. Preview не требует обновлений, не показывает Tip of the day, не открывает попапы “смотри что я могу”. Она одна стоит того, чтобы купить Мак.
Возможно, она поможет вам скопировать код из скриншота. Об этом я, кстати, тоже давненько писал: иногда, чтобы месаджер не испортил код, его проще переслать картинкой. А с помощью Preview — восстановить обратно.
Или скачал ноты для дочки в PDF, а там в подвале реклама. Не беда, накрыл белым прямоугольником — и нет рекламы. Красота же. Где еще так можно?
Writing on programming, education, books and negotiations.