-
Джон и чат
Предположим, Джон не может сегодня работать. Заболела дочь, и он везет ее по врачам. Джон заходит в рабочий чат и пишет: гайз, заболел ребенок, сегодня работать не смогу.
Через двадцать минут просыпается Майкл, заходит в чат, видит сообщение Джона и отвечает: Джон, желаю твоей дочери поправиться! Еще через полчаса заходит Карл и пишет: скорее поправляйся! Через сорок минут… короче, вы поняли. В час дня выползает как-то тип со сдвинутым графиком и мотает чат. Пролистав десяток пожеланий, что он делает? Правильно — желает выздоровления дочери, а поскольку речь о ребенке, ставит тупую гифку с плюшевым медведем.
Обеим сторонам нужно помнить следующее.
Если вы — Майкл и Карл, то желать выздоровления больше одного раза не нужно. Если прям неймется, поставьте к первому сообщению лайк — в знак того, что вы присоединяетесь к пожеланию. Иначе вы затрахете коллегу и всех, кто в чате.
Если вы — Джон, и коллег не перевоспитать, не пишите о личных проблемах в общий чат. Достаточно написать руководителю и паре людей, с которыми вы плотно работаете. Остальным хватит и статуса в мессаджере.
Формально все эти пожелания вежливы. Но иногда еще вежливей будет помолчать.
-
Репозиторий функций
Где-то я прочел тезис: мол, хорошо бы иметь платформу, где в репозитории лежат не пакеты, а функции. То есть гранулярность библиотек столь мала, насколько это возможно. И вот тогда бы мы зажили.
Не понимаю, зачем об этом мечтать, ведь такая платформа есть — это Node.js и npm. В ней тысячи пакетов, которые состоят из одной-двух функций. Прямо сейчас прошелся по папке
node_modulesодного проекта. Обнаружил там забавные вещи:-
ansi-red— пакет для вывода текста красным, одна функция, пять строк на весь файл; -
expand-range— что-то для диапазона значений, одна функция; -
for-in— синтаксический сахар для цикла, одна функция, 6 строк; -
is-buffer,is-number,isarray,isobject— пакеты-проверки на нужный тип, везде одна функция на 5-6 строк; -
list-item— генерилка списка с буллитами, одна функция; -
markdown-link— рендер ссылки markdown, одна функция; -
randomatic— генератор случайной строки, две функции; -
repeat-element— генератор массива с повтором элемента, одна функция.
Есть и другие однострочники, не хочу утомлять. Просто факт: вот тебе платформа, куда можно заливать функции и делать ссылку на них, и это даже работает.
Имея все это на руках, хочется спросить: помогли тебе твои ляхи? Мы уже переехали в рай Node.js верхом на радуге? И что сегодня сказал бы автор тезиса? Опять чего-то не хватает?
Я очень скептичен к Node.js как платформе и не вижу смысла опять об этом писать. Речь о другом: высказывая тезис, даже самый фантастический, нужно помнить о том, что его легко проверить. Для этого не нужно ждать пять лет. Почти все, о чем мы мечтаем — это лишь слабые навороты к тому, что уже есть.
А истинно новые вещи проверить наперед невозможно.
-
-
Концепция
Итак, вы придумали изящную концепцию, простую и понятную. Но в процессе выяснилось, что ей мешают костыли: надо воткнуть условие здесь, условие там, словом, концепция поползла. Никакая она больше не изящная.
Возможны три варианта. Первый — идти до конца, то есть воткнуть столько костылей, сколько нужно для запуска в проде. Далее отчитаться перед начальством, съездить на конференцию с зажигательным толком, собрать все ништяки и уйти в закат. Позже фирма наймет кого-то другого, чтобы все переделать.
Второй путь — изменить внешние условия так, чтобы концепция не разваливалась. Например, переместить данные в другое место, отказаться от устаревших протоколов, поменять рабочий процесс. Это может быть справедливо, если сохранит изящность концепции.
Третий путь — если концепция, пусть даже изящная, не может жить в текущих условиях, она признается негодной. Вместо нее ищут другую концепцию. На первый взгляд она может быть уродливой, но ее достоинство в том, что она хорошо себя чувствует в тяжелых условиях.
Что именно выбрать — каждый решает сам. Лично мне нравится второй вариант. Если концепция простая, то есть может быть описана двумя предложениями, она прослужит долго. Ради этого стоит напрячься и передвинуть мебель так, чтобы в будущем ничего не двигать.
-
SOLID (2)
В продолжение прошлой заметки: особого упоминания заслуживает ООП. С ним можно играть в бинго. Если разговор зашел про ООП, кто-то обязательно скажет, что НА САМОМ ДЕЛЕ под ним имеется в виду что-то другое. То ООП, что в джавах и питонах, неправильное! Был божественный замысел, который неверно истолковали.
Дальше пойдет кряхтение о том, что Алан Кей был биологом. По аналогии с клетками он придумал обмен сообщениями, и что верное ООП только в Эрланге из-за модели акторов… все это я слышал много раз. Но скажите, что делать с зоопарком ООП в разных языках? Если это другое ООП, то может и назвать его по-другому? Если оно то же самое, то попуститься и все-таки признать?
И вообще, ничего, что прошло полвека со времен Кея и модели клеток? Ситуация как бы изменилась. Слегка.
Современное ООП — примерно как живопись. Найдено столько стилей и направлений, что их нельзя описать пятью буквами SOLID. Да, когда-то в них помещался весь опыт индустрии, и их возвели в догму. Но сегодня попытки объяснить ООП в Питоне терминами SOLID напоминают попытку заправить шубу в трусы. Не вмещается!
От ООП, кстати, уходят к классическому подходу структура-функция. Тысячи гоферов колбасят код в Гугле и других фирмах. Структура-функция-интерфейс, структура-функция-интерфейс… теперь это тоже ООП называется? Или все-таки можно писать в прод без ООП?
Просто маятник качнулся в обратную сторону. Теперь он удаляется от тех, к кому двигался раньше.
Если сравнивать языки, то в плане ООП мне больше всего нравится Lua. Там концепция ООП умещается в абзац. Объект — это таблица с данными, которой назначена мета-таблица с функциями. Когда вы обращаетесь к таблице, она ищет поле или метод в себе, потом в мета-таблице, потом в мете той таблицы и так далее. Вот и все ООП: инкапсуляция и наследование одим махом. Никаких виртуальных деструкторов, никаких Function.Prototype. И никто не парится.
Конечно, с такими тезисами вы не пройдете собес, если встретится ООП-маньяк. Но и вести себя с ним надо подобающе: не поднимать больные темы, принимать его сторону, если становится буйным. И все получится.
-
SOLID (1)
Когда говорят о REST, SOLID и прочих абстракциях, допускают следующий оборот. Мол, вы не так поняли оригинальный замысел: НА САМОМ ДЕЛЕ имелось в виду другое, просто техническая реализация отличается от задуманного.
Я никогда не мог понять, зачем так говорят. Если реализация REST на базе HTTP + JSON отличается от абстрактного REST, то либо не называйте ее так, либо смиритесь, что она отличается от замысла. Всяко лучше, чем с пеной у рта доказывать, что на самом деле имелось в виду что-то там.
Если идею автора пришлось доработать, чтобы претворить в жизнь, то это проблема автора, а не того, кто пользуется реализацией.
Конечно, есть те, кому нравится унижать людей на собесах. Тут REST и SOLID заходят на ура. Маньяки, ничего не поделаешь. Но мы-то с вами тут при чем?
-
Замеры
Если вы долго поддерживаете код, полезно делать замеры: стал ли он быстрее, медленнее или ничего не изменилось.
Не обязательно замерять каждый коммит. Достаточно делать это каждые N версий. Даже скромных данных будет достаточно, чтобы понять, где вы свернули не туда или наоборот — в проекте все круто.
Ниже — замеры драйвера Postgresql в разрезе версий. Разрыв между версиями 0.1.2 и 0.1.11 вызван тем, что в этот период я исправлял то, что не окажет влияния на производительность. А в 0.1.12 было то, что оказывает, поэтому замер необходим.
Картинка ниже показывает, сколько времени нужно, чтобы забрать данные с сервера без парсинга. С каждой версией эта метрика уменьшается. Вызвано это ленивым парсингом. Данные не разбираются сразу, а оборачиваются в класс, который притворяется словарем. При обращении к ключу происходит разбор поля и сохранение во внутреннем кэше.
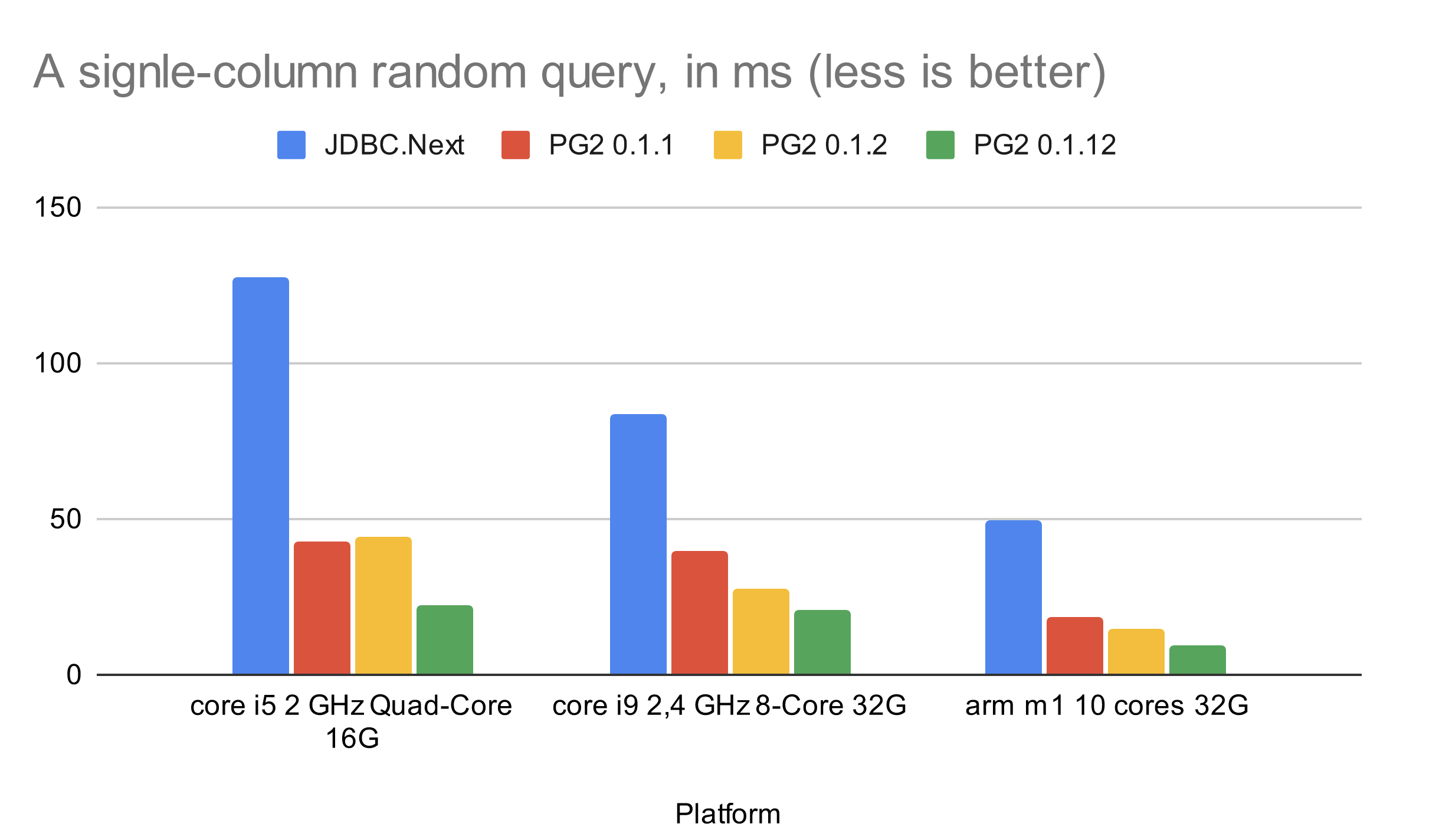
То же самое, но для сложного запроса с полями разных типов:
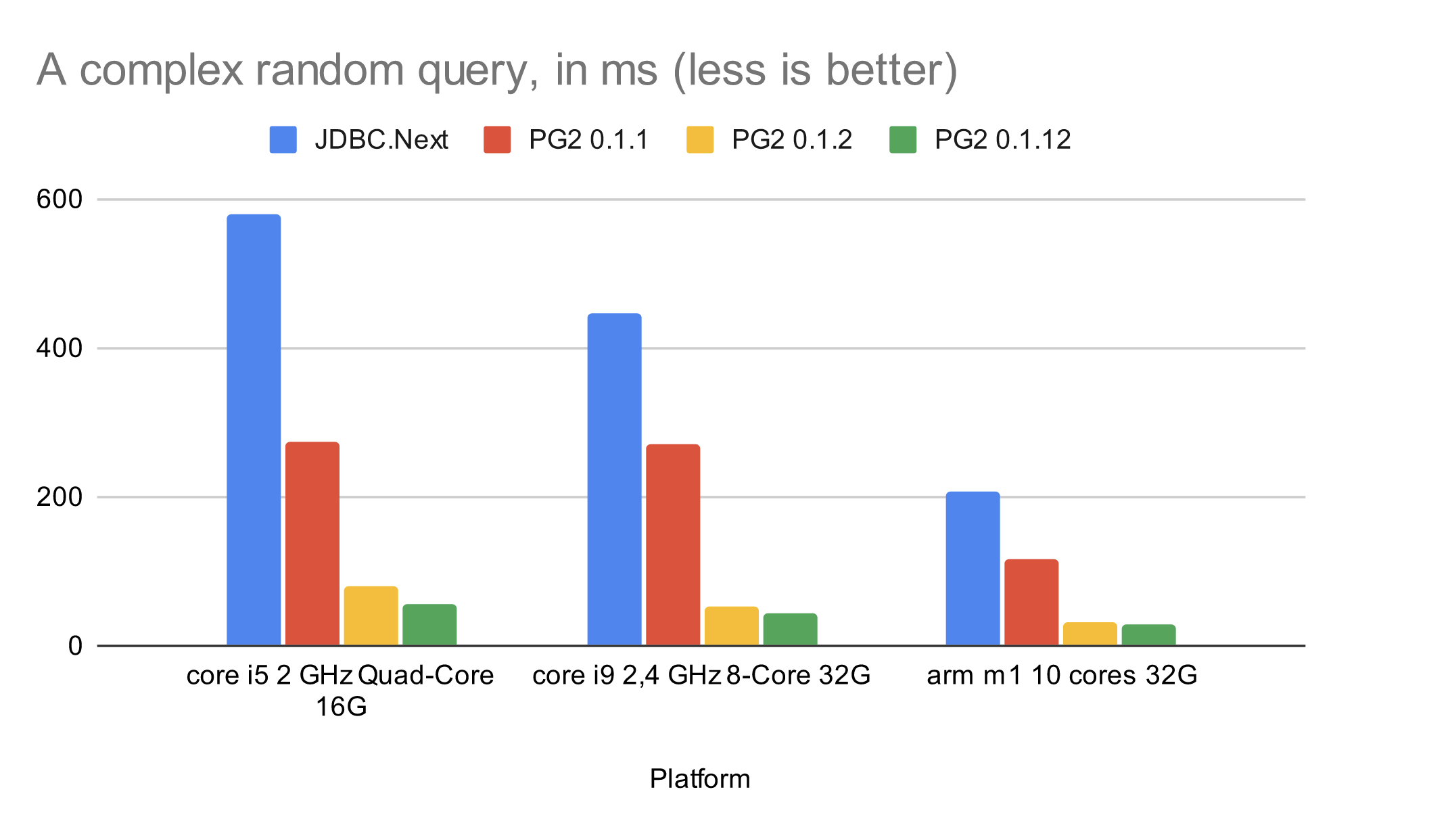
Последняя версия выигрывает у конкурента на порядок: 59 против 590 милисекунд. Разве не круто, когда оцениваешь разницу визуально?
Другая метрика: число запросов в секунду HTTP сервера, который вынимает из базы случайные данные и отдает в JSON. Здесь видно, что хотя прирост есть, но на некоторых платформах число RPS слабо, но проседает. Это потому, что при сбросе данных в JSON срабатывает тот самый ленивый парсинг, а он отнимает время.

Есть еще одна метрика: очень сложный запрос с принудительным парсингом. Здесь видно, что он дает о себе знать: с каждой версией цифра повышается.
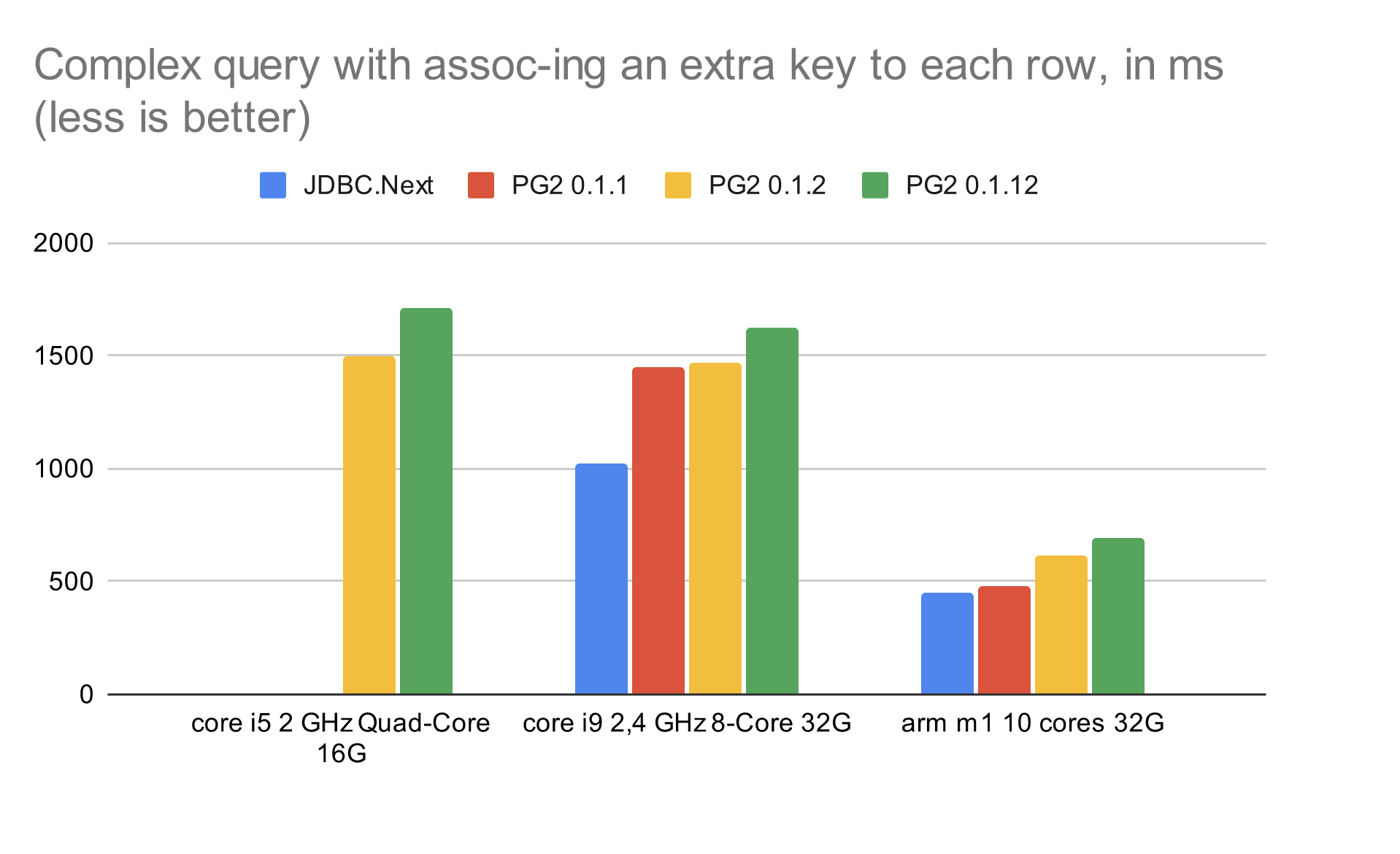
Из этих картинок можно извлечь пользу, например оценить, где мы выиграли и потеряли и насколько. В моем случае я считаю, что главное — как можно скорее забрать данные с сервера и освободить соединение. За это мы платим чуть менее быстрым парсингом, но ничего — это осознанный выбор.
Другое дело, когда замеров нет в принципе и остается гадать — может, станет быстрее, а может быть, медленнее. Компьютеры у всех мощные, телефоны меняют каждый год, поэтому выкатывай, там разберемся. Кажется, большинство программ обновляют именно так.
-
Никнейм в JetBrains
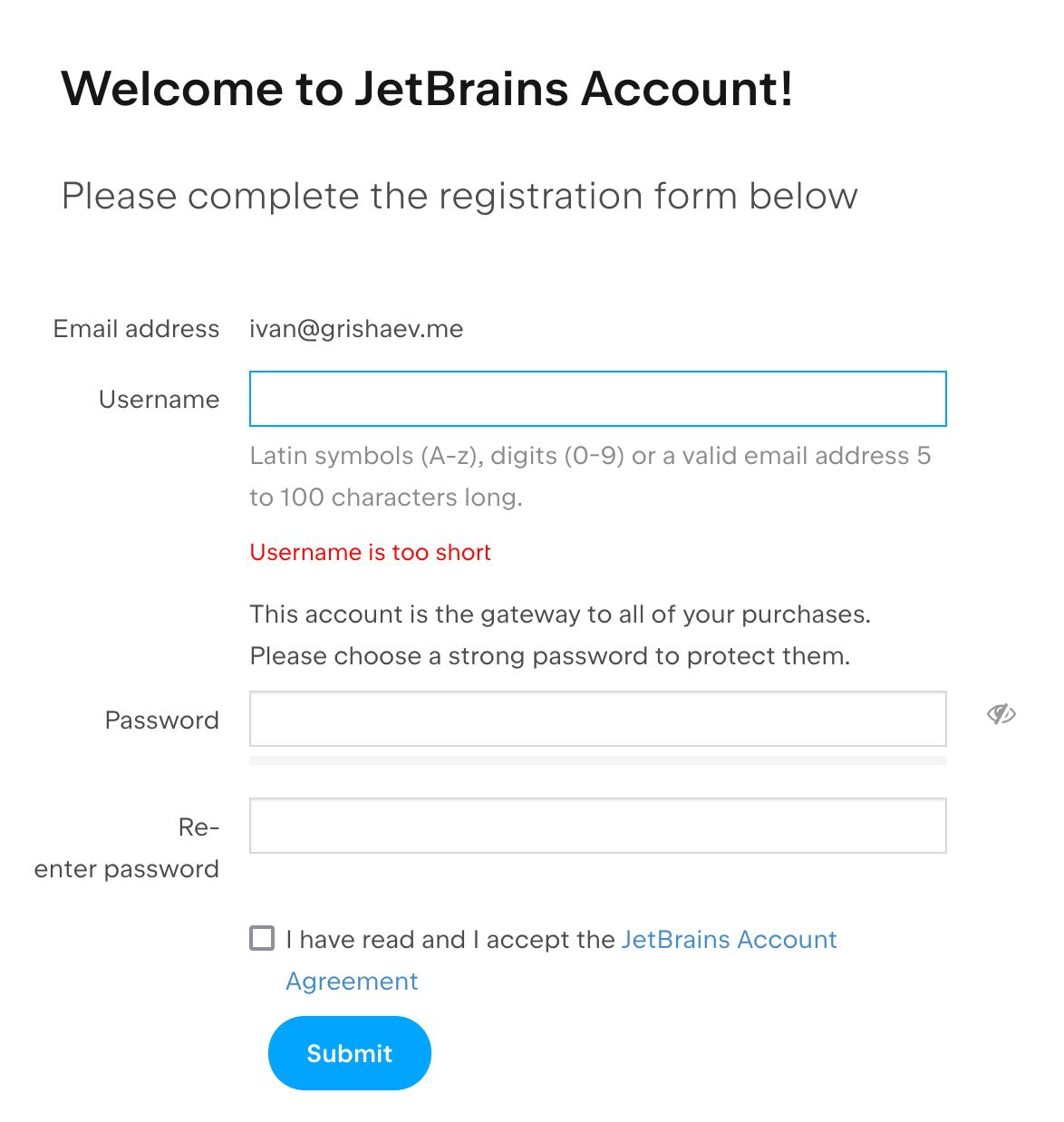
Смешно: регистрация в JetBrains запрашивает никнейм.
Вот у меня есть имя и фамилия. У меня есть электронная почта. У меня есть телефон. А никнейма нет. Где взять никнейм? Где его выдают?
Считается, что я должен его придумать. Но зачем? Какую пользу дает никнейм? Вы там что, не можете сгенерить UUID, а в сообщении писать имя и фамилию?
Согласен, что на форуме майнеров или имиджборде без ника никуда. Не будешь же ты подписываться полным ФИО. Но у JetBrains не форум анонимных программистов. У них продукт, и какую роль в нем играет никнейм — неясно.
Никнейм — это либо рудимент нулевых, машинное имя пользователя, удобное на бекенде. Либо это способ анонимности, чтобы постить сомнительный контент без разоблачения.
Оба случая проходят мимо JetBrains, что и желаю им понять.
Ну и классика: еще ничего не написал, а форма кричит ошибками.
-
Ковид
Вопрос между делом: как дела с ковидом? Он уже прошел? Все выздоровели? Повальная вакцинация сделала свое дело? Все приобрели иммунитет?
Где мы находимся: уже перешагнули катастрофу? Ковида больше не будет?
Может быть теперь, когда ковидная истерия сходит на нет, не мешало бы провести ретро, а именно:
- надо ли было запирать людей в четырех стенах на год?
- надо было ставить прививки всем поголовно, в том числе беременным и детям?
- нормально ли было пускать в магазин за едой по QR-коду?
- хорошо ли было отказывать в помощи тем, у кого не ковид, а сердце, например?
В целом, отношение к ковиду у меня ровно то же, что и к Титанику и Чернобылю. Во всех случаях было что-то из ряда вон, но в основном людей угробили из-за паники и суетливых мер.
Искренне надеюсь, что лет через сто, когда виновники будут в могиле, кто-то выпустит нормальный обзор ковидной истерии. И там будет ровно то, что в Титанике и Чернобыле: эти бедняги могли все сделать правильно, но увы.
-
Краткие ответы на большие вопросы
Закончил читать “Краткие ответы на большие вопросы” Стивена Хокинга. Того самого ученого в инвалидном кресле, который недавно умер.
Это второй раз, когда я читаю его книгу. В первый раз это была “Краткая история времени”. Скажу честно, не пошло — она слишком научна. Можно сделать вид, что разбираешься в материале, но не вижу причины себя обманывать, поэтому дочитывать не стал. Напротив, “Краткие ответы…” менее научная, поэтому решил попробовать еще раз.
Хокинг начал писать книгу незадолго до смерти. Ее закончили коллеги Хокинга на базе его архива и выступлений. Книга получилась компиляцией его идей. Я с сомнением отношусь к такого рода книгам — чаще всего это попытка выжать денег за счет известного имени — но в нашем случае получилось хорошо. Видно, что над книгой проделали большую работу, чтобы вышло что-то целостное, а не обрывки. Русский перевод отличный с привлечением научных редакторов.
Книгу предваряет вступительное слово коллег Хокинга с интересными фактами из его жизни. Перед первой главой напечатана фотография Хокинга, где ему лет пятнадцать, и он хитровато смотрит в камеру. На последней странице — фото незадолго до смерти в кресле.
В книге десять глав с рассуждениями на “большие” вопросы — есть ли бог, откуда мы взялись, можно ли путешествовать во времени, как быть с искусственным интеллектом и другие. По мере того как я читал, впечатления от книги менялись интересным образом.
Первые несколько глав посвящены науке и черным дырам — области, в которой Хокинг был топ один. Читать про Вселенную и дыры интересно, особенно в изложении Хокинга. Постепенно научные темы сменяются социальными, и наступает некий интеллектуальный уклон. Суждения Хокинга становятся откровенно плоскими. Начинаются пугалки про глобальное потепление, Трампа, Брексит, мировой голод и прочие штучки. Ощущение, будто открыл Твиттер демократической партии США.
Высказывания Хокинга по социальным темам очень размыты. Он без конца повторяет, что технологии могут как принести пользу, так и навредить, но нужно придерживаться оптимизма. В тексте нет развития, в нем сплошное топтание на месте. Например, он много пишет о том, как ИИ спасет людей от голода, войн и болезней. Как именно спасет?
Мне кажется, Хокинг был бы разочарован современным ИИ, который используется в основном для мусора. Тысячи сгенерированных книг на Амазоне, тысячи сгенерированных отзывов к ним, тысячи ИИ-стартапов, которым лишь бы пройти на следующий раунд инвестиций — вот плоды нашего псевдо-ИИ. И если он используется в войнах, то разве что для лучшего поражения целей, а не их предотвращения.
Возможно, часть книги с социальными темами Хокинг не успел написать, и ее высосали из пальца его коллеги на базе его случайных цитат.
В любом случае я лишний раз понял: даже великий человек хорош в чем-то одном. В плане Вселенной и черных дыр Хокингу нет равных. Но его мысли на социальные темы напоминают главную страницу западных сайтов: шаблонный набор пугалок. Мы, слушатели, в сотый раз повторяем ошибку: считаем, что если человек разбирается X, то автоматом разбирается в Y. А это не так.
Вот такая противоречивая книжка. Горячо советую ее первую половину, остальное — по настроению.
Эту и другие книжки см. на книжной полке.
-
PG2 release 0.1.12
PG2 version 0.1.12 is out. Aside from internal refactoring, there are several features I’d like to highlight.
First, the library is still getting faster. The latest benchmarks prove 15-30% performance gain when consuming
SELECTresults. Actual numbers depend on the nature of a query. Simple queries with 1-2 columns work faster than before:
Metrics:
Platform JDBC.Next PG2 0.1.1 PG2 0.1.2 PG2 0.1.12 core i5 2 GHz Quad-Core 16G 127.677926 43.026307 44.36297 21.941113 core i9 2,4 GHz 8-Core 32G 83.932103 39.551719 27.672117 20.957904 arm m1 10 cores 32G 49.340986 18.517718 14.670815 9.468902 Although queries with many columns are less sensitive to the new parsing algorithm, they’re still fast. Here is a chart for a complex query:

Metrics:
Platform JDBC.Next PG2 0.1.1 PG2 0.1.2 PG2 0.1.12 core i5 2 GHz Quad-Core 16G 579.59995 273.866142 80.352246 55.835803 core i9 2,4 GHz 8-Core 32G 447.326861 270.262248 54.34384 42.815123 arm m1 10 cores 32G 206.371502 117.241426 30.444798 29.92079 PG2 has become a bit faster with HTTP. The chart below measures a number of RPS of a Jetty server that fetches random data from a database and responds with JSON:

The tests were made using
abas follows:ab -n 1000 -c 16 -l http://127.0.0.1:18080/Timings:
Platform JDBC.Next PG2 0.1.1 PG2 0.1.2 PG2 0.1.12 core i5 2 GHz Quad-Core 16G 555.55 968.51 915.93 890.62 core i9 2,4 GHz 8-Core 32G 1304 1909.19 1688.72 1794.75 arm m1 10 cores 32G 1902.31 2999.06 3026 3363.36 The second feature is the
:read-only?connection flag. When it’s set to true, the connection is run inREAD ONLYmode, and every transaction opens being READ ONLY as well. This is useful for reading from replicas. A small example where an attempt to delete something leads to a negative response:(pg/with-connection [conn {... :read-only? true}] (pg/query conn "delete from students")) ;; PGErrorResponse: cannot execute DROP TABLE in a read-only transactionWhen set globally for connection, the flag overrides the same flag passed into the
with-txmacro. Below, the transaction is READ ONLY anyway because the config flag is prioritized.(pg/with-connection [conn {... :read-only? true}] (pg/with-tx [conn {:read-only? false}] ;; override won't do (pg/query conn "create table foo(id serial)"))) ;; PGErrorResponse: cannot execute CREATE TABLE in a read-only transactionFinally, there is a new reducer called “column” which fetches a single column as a vector. We often select IDs only, but the result is a vector of maps with a single
:idfield:[{:id 100} {:id 101}, ...]To get the ids, either you pass the result into
(map :id ...)or, which is better, specify the:columnkey as follows:(pg/with-connection [conn {...}] (pg/query conn "select id from users" {:column :id})) ;; [100, 101, 102, ...]Internally, the reducer fetches the field from each row on the fly as they come from the network. It’s more effective than passing the result into
mapas it takes only one passage.For more details, you’re welcome to the readme file of the repo.
Writing on programming, education, books and negotiations.