-
Авито (2)
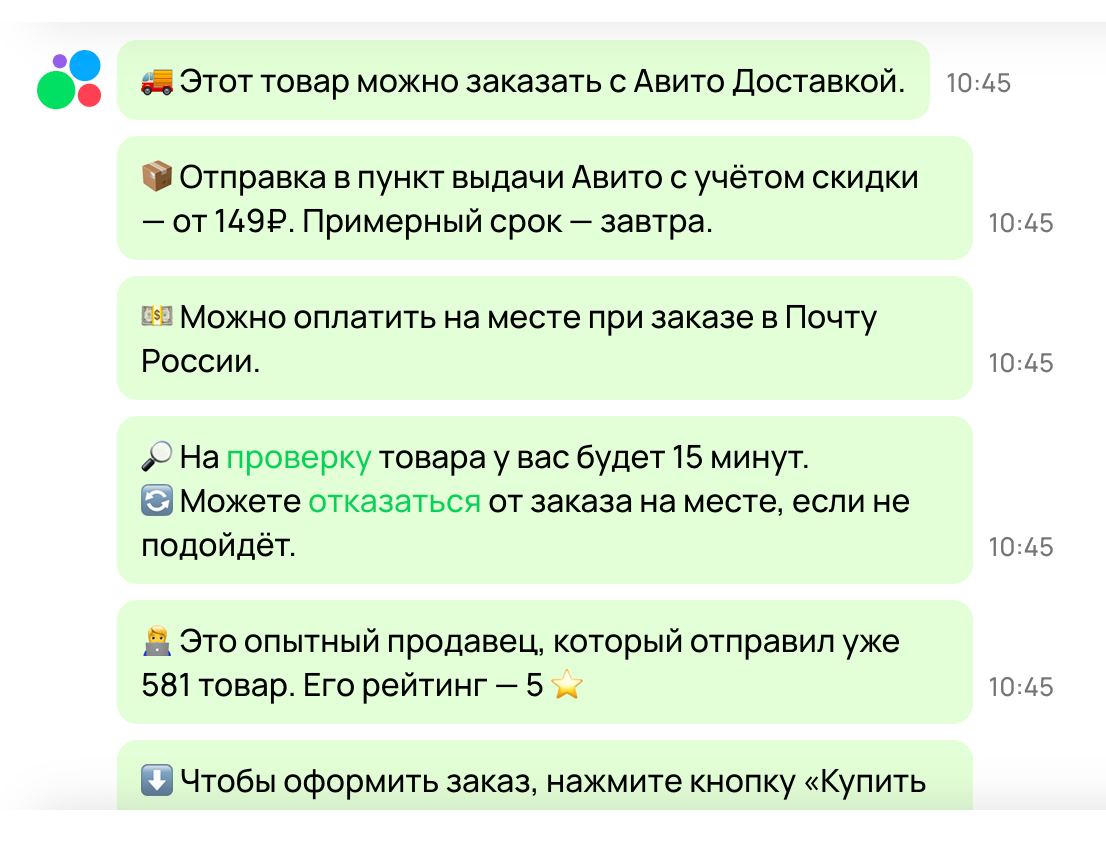
Уж простите за спам про Авито, но я не могу, правда. Это какой-то лол.
Продавец выставил серию книг, и я спрашиваю, есть ли среди них такая. Что делает бот Авито? Он выплевывает 7 сообщений о том, что:
- можно купить с доставкой
- сроки отправки
- сколько занимает проверка товара
- рейтинг продавца
- куда нажать, чтобы купить
И остальное, что не влезло на скриншот, хотя информация есть на странице, и я ее прекрасно вижу. Самую мелочь — есть ли книга или нет — я так и не узнал.
Как же все это душит. Казалось бы, пройдя все авторизации и преграды, можно спросить человека и получить живой ответ. Но Авито не оставляет шансов: и здесь поджидает бот, который засрет переписку бессмыслицей. И не только Авито, конечно.
Все это нежно, мягко, с заботой, но поддушивает.
-
Авито (1)
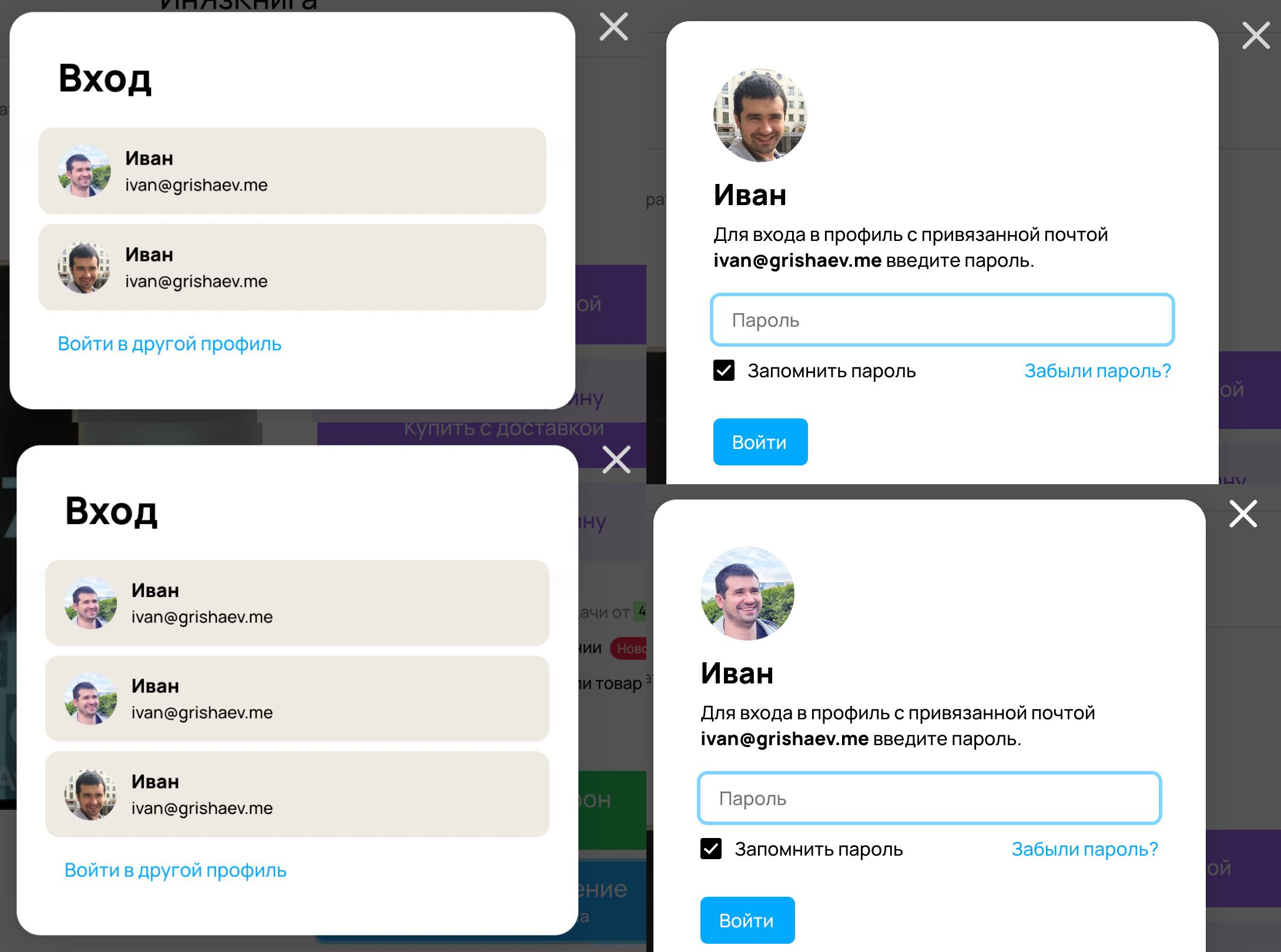
Не знаю, что курят в Авито, но система допускает два профиля с одинаковой почтой, и я должен выбрать один из них. Может, это из-за разных клиентов: десктоп и телефон? Или из кеша пришли левые данные? Это неважно: техническое объяснение всегда найдется. Но так быть не должно.
-
Авторизация оскорбляет
Раньше двойная авторизация работала так: ставишь приложение на телефон, сканируешь QR-код и получаешь генерилку кодов. Сайт запрашивает код, ты вводишь, все довольны.
Теперь сервисы отходят от это схемы. Даже если ты включил двойную авторизацию, сайт предложит зайти в другое приложение той же фирмы. Например, чтобы зайти в Гмейл, открой Ютуб. Или открой наше мобильное приложение (Гитхаб, Яндекс). Вариант с кодом прячут под выпадашку “другие способы”.
Меня оскорбляет такой подход. Я заморачивался, ставил эти коды и считаю их безопасней, чем вход в другое приложение. Тем не менее, сервис понизил приоритет у кодов и предлагает способ для домохозяек. Не надо так.
-
ИИ-ревью
Верьте аль не верьте, но в одном проекте у нас было ИИ-ревью. Слушайте.
Фирма назначила нового технического директора. Уже первый разговор с ним посеял тревогу. Его технический стек не имел отношения к тому, что был у нас. Он сходу предложил перейти на MongoDB — оставив за кадром факт, что переезд с гигантской базы Постгреса занял бы несколько лет. Он много говорил о Chat GPT и о том, как ИИ-ревью изменит наши процессы.
Начальство дало добро, и техдир провел три месяца, настраивая ИИ-ревью. Если вкратце, оно работало так.
Нашелся бот на Node.js, который парсит дифф и выдирает изменения. Бот крутится в CI и запускается на каждом коммите.
Выдрав изменения и собрав контекст, бот отправлял все добро в Chat GPT и составлял отчет.
Этот отчет добавлялся в комментарий к пулл-реквесту.
Звучит круто, а что было на самом деле? Это выглядело так. По каждому файлу бот писал: добавлена такая-то функция, переименован такой-то параметр, функция foo-bar теперь принимает три аргумента, а не два. И все таком духе: человекоподобное описание изменений. Ниже он писал вердикт — хороши ли изменения или требуют доработки.
Постарайтесь это представить: в пул-реквесте пятнадцать файлов, и по каждому бот пишет абзац текста. Получается портянка на два экрана, совершенно тупая и бесполезная. Что с того, что написано “добавлена новая функция”? Я из без бота вижу, что она добавлена. Вполне может быть, что похожая функция уже есть, либо это могло быть inline-выражение, либо есть лучшая версия этой функции в библиотеке? Бот ничего об этом не знал.
Открывая PR, ты первым делом видел выхлоп ИИ на два экрана. Нужно было проматывать эту фигню, чтобы добраться до кода.
Получилась своего рода версия PR для менеджеров. Ну, знаете, бывает версия для слабовидящих, а есть версия для менеджеров. Менеджер не может прочесть код, и система генерит ему описание: добавилось то, убавилось это. Читая выхлоп, менеджер думает, что понимает код, хотя это не так. Он понимает действие, но не понимает причины, не понимает смысла, который стоит за этим кодом.
Чтобы портянка на два экрана не мешала, я стал удалять ее из PR. В том числе не только из своих PR, но и коллег, если меня просили сделать ревью. Открывая PR, я рассчитываю увидеть код, а не машинный выхлоп, пусть даже его произвел ИИ. И знаете, никто не жаловался на удаление. Скоро я заметил, что коллеги молча удаляют этот комментарий без моего вмешательства.
Стоит ли говорить, что бот ничего не знал о безопасности и хороших практиках. Он спокойно пропускал места, где SQL-параметр подставлялся склейкой строк. Он ничего не знал о reflection warning, о кривых запросах, неэффективных циклах, запросах мимо индекса.
Удивлял его вердикт: бот мог написать “все отлично” к файлу, к которому у меня было три претензии. Мог написать “требует доработки” к файлу, где все гладко. Само собой, без каких-либо объяснений, что именно требует доработок и каких.
Получался молчаливый бойкот: разработчики не обращали внимания на бота, техдир ничего в Кложе не понимал, а бот не давал ответа на вопрос, хороший мы пишем код или нет.
Добавлю, что еще раньше техдир хотел подключить в CI сторонний говносервис, который делает то же самое. К счастью, в списке поддерживаемых языков не было Кложи.
И вот однажды бота отключили. Я не стал спрашивать о причинах: они были очевидны. ИИ-ревью не оправдало себя, а директор потратил три месяца на его настройку. Ничего не изменилось в лучшую сторону, стало только хуже, потому что добавился новый компонент, усложнился CI, были потрачены деньги. Позже директора уволили.
В чем была его ошибка? В том, что он не мог четко объяснить, какую проблему он решал с помощью ИИ. Я уже писал про это: принимаясь за задачу, спрашивай себя, какую проблему ты решаешь. В том проекте у нас было хорошее ревью: никто не затягивал процесс, сложные диффы смотрели несколько человек. В команде была компетенция в плане Кложи и SQL. Словом, ревью было последним местом, куда бы я внедрил ИИ.
Вот что бывает, когда за дело берутся менеджеры. Их стремление автоматизировать понятно: вдруг человек уйдет, а мы такие внедрили ИИ, и ладушки: он с нами навсегда. Увы, это не работает: есть процессы, которые должен выполнять человек. Всякие ИИ могут быть страховкой, но не более того.
-
1Password все
Вот и все, что нужно знать про менеджеры паролей. Однажды тебе скажут: создавай облачную учетку или иди лесом. 1Password упорно шел в этом направлении, так что не удивлен. Я и раньше знал, что восьмая версия не работает без облака и сидел на шестой. Теперь она насильно обновилась.
К счастью, уже два года переехал на Unix Pass и планирую об этом написать.
-
PG2 release 0.1.4: HoneySQL API and shortcuts
Table of Content
PG2 version 0.1.4 is out. In this release, the main feature is improvements made to the
pg-honeypackage which is a wrapper on top of HoneySQL.HoneySQL Integration & Shortcuts
The
pg-honeypackage allows you to callqueryandexecutefunctions using maps rather than string SQL expressions. Internally, maps are transformed into SQL using the great HoneySQL library. With HoneySQL, you don’t need to format strings to build a SQL, which is clumsy and dangerous in terms of injections.The package also provides several shortcuts for such common dutiles as get a single row by id, get a bunch of rows by their ids, insert a row having a map of values, update by a map and so on.
For a demo, let’s import the package, declare a config map and create a table with some rows as follows:
(require '[pg.honey :as pgh]) (def config {:host "127.0.0.1" :port 10140 :user "test" :password "test" :dbname "test"}) (def conn (pg/connect config)) (pg/query conn "create table test003 ( id integer not null, name text not null, active boolean not null default true )") (pg/query conn "insert into test003 (id, name, active) values (1, 'Ivan', true), (2, 'Huan', false), (3, 'Juan', true)")Get by id(s)
The
get-by-idfunction fetches a single row by a primary key which is:idby default:(pgh/get-by-id conn :test003 1) ;; {:name "Ivan", :active true, :id 1}With options, you can specify the name of the primary key and the column names you’re interested in:
(pgh/get-by-id conn :test003 1 {:pk [:raw "test003.id"] :fields [:id :name]}) ;; {:name "Ivan", :id 1} ;; SELECT id, name FROM test003 WHERE test003.id = $1 LIMIT $2 ;; parameters: $1 = '1', $2 = '1'The
get-by-idsfunction accepts a collection of primary keys and fetches them using theINoperator. In additon to options thatget-by-idhas, you can specify the ordering:(pgh/get-by-ids conn :test003 [1 3 999] {:pk [:raw "test003.id"] :fields [:id :name] :order-by [[:id :desc]]}) [{:name "Juan", :id 3} {:name "Ivan", :id 1}] ;; SELECT id, name FROM test003 WHERE test003.id IN ($1, $2, $3) ORDER BY id DESC ;; parameters: $1 = '1', $2 = '3', $3 = '999'Passing many IDs at once is not recommended. Either pass them by chunks or create a temporary table,
COPY INids into it andINNER JOINwith the main table.Delete
The
deletefunction removes rows from a table. By default, all the rows are deleted with no filtering, and the deleted rows are returned:(pgh/delete conn :test003) [{:name "Ivan", :active true, :id 1} {:name "Huan", :active false, :id 2} {:name "Juan", :active true, :id 3}]You can specify the
WHEREclause and the column names of the result:(pgh/delete conn :test003 {:where [:and [:= :id 3] [:= :active true]] :returning [:*]}) [{:name "Juan", :active true, :id 3}]When the
:returningoption set tonil, no rows are returned.Insert (one)
To observe all the features of the
insertfunction, let’s create a separate table:(pg/query conn "create table test004 ( id serial primary key, name text not null, active boolean not null default true )")The
insertfunction accepts a collection of maps each represents a row:(pgh/insert conn :test004 [{:name "Foo" :active false} {:name "Bar" :active true}] {:returning [:id :name]}) [{:name "Foo", :id 1} {:name "Bar", :id 2}]It also accepts options to produce the
ON CONFLICT ... DO ...clause known asUPSERT. The following query tries to insert two rows with existing primary keys. Should they exist, the query updates the names of the corresponding rows:(pgh/insert conn :test004 [{:id 1 :name "Snip"} {:id 2 :name "Snap"}] {:on-conflict [:id] :do-update-set [:name] :returning [:id :name]})The resulting query looks like this:
INSERT INTO test004 (id, name) VALUES ($1, $2), ($3, $4) ON CONFLICT (id) DO UPDATE SET name = EXCLUDED.name RETURNING id, name parameters: $1 = '1', $2 = 'Snip', $3 = '2', $4 = 'Snap'The
insert-onefunction acts likeinsertbut accepts and returns a single map. It supports:returningandON CONFLICT ...clauses as well:(pgh/insert-one conn :test004 {:id 2 :name "Alter Ego" :active true} {:on-conflict [:id] :do-update-set [:name :active] :returning [:*]}) {:name "Alter Ego", :active true, :id 2}The logs:
INSERT INTO test004 (id, name, active) VALUES ($1, $2, TRUE) ON CONFLICT (id) DO UPDATE SET name = EXCLUDED.name, active = EXCLUDED.active RETURNING * parameters: $1 = '2', $2 = 'Alter Ego'Update
The
updatefunction alters rows in a table. By default, it doesn’t do any filtering and returns all the rows affected. The following query sets the booleanactivevalue for all rows:(pgh/update conn :test003 {:active true}) [{:name "Ivan", :active true, :id 1} {:name "Huan", :active true, :id 2} {:name "Juan", :active true, :id 3}]The
:whereclause determines conditions for update. You can also specify columns to return:(pgh/update conn :test003 {:active false} {:where [:= :name "Ivan"] :returning [:id]}) [{:id 1}]What is great about
updateis, you can use such complex expressions as increasing counters, negation and so on. Below, we alter the primary key by adding 100 to it, negate theactivecolumn, and change thenamecolumn with dull concatenation:(pgh/update conn :test003 {:id [:+ :id 100] :active [:not :active] :name [:raw "name || name"]} {:where [:= :name "Ivan"] :returning [:id :active]}) [{:active true, :id 101}]Which produces the following query:
UPDATE test003 SET id = id + $1, active = NOT active, name = name || name WHERE name = $2 RETURNING id, active parameters: $1 = '100', $2 = 'Ivan'Find (first)
The
findfunction makes a lookup in a table by column-value pairs. All the pairs are joined using theANDoperator:(pgh/find conn :test003 {:active true}) [{:name "Ivan", :active true, :id 1} {:name "Juan", :active true, :id 3}]Find by two conditions:
(pgh/find conn :test003 {:active true :name "Juan"}) [{:name "Juan", :active true, :id 3}] ;; SELECT * FROM test003 WHERE (active = TRUE) AND (name = $1) ;; parameters: $1 = 'Juan'The function accepts additional options for
LIMIT,OFFSET, andORDER BYclauses:(pgh/find conn :test003 {:active true} {:fields [:id :name] :limit 10 :offset 1 :order-by [[:id :desc]] :fn-key identity}) [{"id" 1, "name" "Ivan"}] ;; SELECT id, name FROM test003 ;; WHERE (active = TRUE) ;; ORDER BY id DESC ;; LIMIT $1 ;; OFFSET $2 ;; parameters: $1 = '10', $2 = '1'The
find-firstfunction acts the same but returns a single row ornil. Internally, it adds theLIMIT 1clause to the query:(pgh/find-first conn :test003 {:active true} {:fields [:id :name] :offset 1 :order-by [[:id :desc]] :fn-key identity}) {"id" 1, "name" "Ivan"}Prepare
The
preparefunction makes a prepared statement from a HoneySQL map:(def stmt (pgh/prepare conn {:select [:*] :from :test003 :where [:= :id 0]})) ;; <Prepared statement, name: s37, param(s): 1, OIDs: [INT8], SQL: SELECT * FROM test003 WHERE id = $1>Above, the zero value is a placeholder for an integer parameter.
Now that the statement is prepared, execute it with the right id:
(pg/execute-statement conn stmt {:params [3] :first? true}) {:name "Juan", :active true, :id 3}Alternately, use the
[:raw ...]syntax to specify a parameter with a dollar sign:(def stmt (pgh/prepare conn {:select [:*] :from :test003 :where [:raw "id = $1"]})) (pg/execute-statement conn stmt {:params [1] :first? true}) {:name "Ivan", :active true, :id 1}Query and Execute
There are two general functions called
queryandexecute. Each of them accepts an arbitrary HoneySQL map and performs eitherQueryorExecuterequest to the server.Pay attention that, when using
query, a HoneySQL map cannot have parameters. This is a limitation of theQuerycommand. The following query will lead to an error response from the server:(pgh/query conn {:select [:id] :from :test003 :where [:= :name "Ivan"] :order-by [:id]}) ;; Execution error (PGErrorResponse) at org.pg.Accum/maybeThrowError (Accum.java:207). ;; Server error response: {severity=ERROR, ... message=there is no parameter $1, verbosity=ERROR}Instead, use either
[:raw ...]syntax or{:inline true}option:(pgh/query conn {:select [:id] :from :test003 :where [:raw "name = 'Ivan'"] ;; raw (as is) :order-by [:id]}) [{:id 1}] ;; OR (pgh/query conn {:select [:id] :from :test003 :where [:= :name "Ivan"] :order-by [:id]} {:honey {:inline true}}) ;; inline values [{:id 1}] ;; SELECT id FROM test003 WHERE name = 'Ivan' ORDER BY id ASCThe
executefunction acceps a HoneySQL map with parameters:(pgh/execute conn {:select [:id :name] :from :test003 :where [:= :name "Ivan"] :order-by [:id]}) [{:name "Ivan", :id 1}]Both
queryandexecuteaccept notSELECTonly but literally everything: inserting, updating, creating a table, an index, and more. You can build combinations likeINSERT ... FROM SELECTorUPDATE ... FROM DELETEto perform complex logic in a single atomic query.HoneySQL options
Any HoneySQL-specific parameter might be passed through the
:honeysubmap in options. Below, we pass the:paramsmap to use the[:param ...]syntax. Also, we produce a pretty-formatted SQL for better logs:(pgh/execute conn {:select [:id :name] :from :test003 :where [:= :name [:param :name]] :order-by [:id]} {:honey {:pretty true :params {:name "Ivan"}}}) ;; SELECT id, name ;; FROM test003 ;; WHERE name = $1 ;; ORDER BY id ASC ;; parameters: $1 = 'Ivan'For more options, please refer to the official HoneySQL documentation.
-
PG2 release 0.1.3: Next.JDBC-compatible API
Table of Content
PG2 version 0.1.3 is out. One of its new features is a module which mimics Next.JDBC API. Of course, it doesn’t cover 100% of Next.JDBC features yet most of the functions and macros are there. It will help you to introduce PG2 into the project without rewriting all the database-related code from scratch.
Obtaining a Connection
In Next.JDBC, all the functions and macros accept something that implements the
Connectableprotocol. It might be a plain Clojure map, an existing connection, or a connection pool. The PG2 wrapper follows this design. It works with either a map, a connection, or a pool.Import the namespace and declare a config:
(require '[pg.jdbc :as jdbc]) (def config {:host "127.0.0.1" :port 10140 :user "test" :password "test" :dbname "test"})Having a config map, obtain a connection by passing it into the
get-connectionfunction:(def conn (jdbc/get-connection config))This approach, although is a part of the Next.JDBC design, is not recommended to use. Once you’ve established a connection, you must either close it or, if it was borrowed from a pool, return it to the pool. There is a special macro
on-connectionthat covers this logic:(jdbc/on-connection [bind source] ...)If the
sourcewas a map, a new connection is spawned and gets closed afterwards. If thesourceis a pool, the connection gets returned to the pool. When thesourceis a connection, nothing happens when exiting the macro.(jdbc/on-connection [conn config] (println conn))A brief example with a connection pool and a couple of futures. Each future borrows a connection from a pool, and returns it afterwards.
(pool/with-pool [pool config] (let [f1 (future (jdbc/on-connection [conn1 pool] (println (jdbc/execute-one! conn1 ["select 'hoho' as message"])))) f2 (future (jdbc/on-connection [conn2 pool] (println (jdbc/execute-one! conn2 ["select 'haha' as message"]))))] @f1 @f2)) ;; {:message hoho} ;; {:message haha}Executing Queries
Two functions
execute!andexecute-one!send queries to the database. Each of them takes a source, a SQL vector, and a map of options. The SQL vector is a sequence where the first item is either a string or a prepared statement, and the rest values are parameters.(jdbc/on-connection [conn config] (jdbc/execute! conn ["select $1 as num" 42])) ;; [{:num 42}]Pay attention that parameters use a dollar sign with a number but not a question mark.
The
execute-one!function acts likeexecute!but returns the first row only. Internaly, this is done by passing the{:first? true}parameter that enables theFirstreducer.(jdbc/on-connection [conn config] (jdbc/execute-one! conn ["select $1 as num" 42])) ;; {:num 42}To prepare a statement, pass a SQL-vector into the
preparefunction. The result will be an instance of thePreparedStatementclass. To execute a statement, put it into a SQL-vector followed by the parameters:(jdbc/on-connection [conn config] (let [stmt (jdbc/prepare conn ["select $1::int4 + 1 as num"]) res1 (jdbc/execute-one! conn [stmt 1]) res2 (jdbc/execute-one! conn [stmt 2])] [res1 res2])) ;; [{:num 2} {:num 3}]Above, the same
stmtstatement is executed twice with different parameters.More realistic example with inserting data into a table. Let’s prepare the table first:
(jdbc/execute! config ["create table test2 (id serial primary key, name text not null)"])Insert a couple of rows returning the result:
(jdbc/on-connection [conn config] (let [stmt (jdbc/prepare conn ["insert into test2 (name) values ($1) returning *"]) res1 (jdbc/execute-one! conn [stmt "Ivan"]) res2 (jdbc/execute-one! conn [stmt "Huan"])] [res1 res2])) ;; [{:name "Ivan", :id 1} {:name "Huan", :id 2}]As it was mentioned above, in Postgres, a prepared statement is always bound to a certain connection. Thus, use the
preparefunction only inside theon-connectionmacro to ensure that all the underlying database interaction is made within the same connection.Transactions
The
with-transactionmacro wraps a block of code into a transaction. Before entering the block, the macro emits theBEGINexpression, andCOMMITafterwards, if there was no an exception. Should an exception pop up, the transaction gets rolled back withROLLBACK, and the exception is re-thrown.The macro takes a binding symbol which a connection is bound to, a source, an a map of options. The standard Next.JDBC transaction options are supported, namely:
:isolation:read-only:rollback-only
Here is an example of inserting a couple of rows in a transaction:
(jdbc/on-connection [conn config] (let [stmt (jdbc/prepare conn ["insert into test2 (name) values ($1) returning *"])] (jdbc/with-transaction [TX conn {:isolation :serializable :read-only false :rollback-only false}] (let [res1 (jdbc/execute-one! conn [stmt "Snip"]) res2 (jdbc/execute-one! conn [stmt "Snap"])] [res1 res2])))) ;; [{:name "Snip", :id 3} {:name "Snap", :id 4}]The Postgres log:
BEGIN SET TRANSACTION ISOLATION LEVEL SERIALIZABLE insert into test2 (name) values ($1) returning * $1 = 'Snip' insert into test2 (name) values ($1) returning * $1 = 'Snap' COMMITThe
:isolationparameter might be one of the following::read-uncommitted:read-committed:repeatable-read:serializable
To know more about transaction isolation, refer to the official [Postgres documentation][transaction-iso].
When
read-onlyis true, any mutable query will trigger an error response from Postgres:(jdbc/with-transaction [TX config {:read-only true}] (jdbc/execute! TX ["delete from test2"])) ;; Execution error (PGErrorResponse) at org.pg.Accum/maybeThrowError (Accum.java:207). ;; Server error response: {severity=ERROR, message=cannot execute DELETE in a read-only transaction, verbosity=ERROR}When
:rollback-onlyis true, the transaction gets rolled back even there was no an exception. This is useful for tests and experiments:(jdbc/with-transaction [TX config {:rollback-only true}] (jdbc/execute! TX ["delete from test2"]))The logs:
statement: BEGIN execute s1/p2: delete from test2 statement: ROLLBACKThe table still has its data:
(jdbc/execute! config ["select * from test2"]) ;; [{:name "Ivan", :id 1} ...]The function
active-tx?helps to determine if you’re in the middle of a transaction:(jdbc/on-connection [conn config] (let [res1 (jdbc/active-tx? conn)] (jdbc/with-transaction [TX conn] (let [res2 (jdbc/active-tx? TX)] [res1 res2])))) ;; [false true]It returns
truefor transactions tha are in the error state as well.Keys and Namespaces
The
pg.jdbcwrapper tries to mimic Next.JDBC and thus useskebab-case-keyswhen building maps:(jdbc/on-connection [conn config] (jdbc/execute-one! conn ["select 42 as the_answer"])) ;; {:the-answer 42}To change that behaviour and use
snake_case_keys, pass the{:kebab-keys? false}option map:(jdbc/on-connection [conn config] (jdbc/execute-one! conn ["select 42 as the_answer"] {:kebab-keys? false})) ;; {:the_answer 42}By default, Next.JDBC returns full-qualified keys where namespaces are table names, for example
:user/profile-idor:order/created-at. At the moment, namespaces are not supported by the wrapper.For more information, please refer to the official README file.
-
PG2 release 0.1.2: more performance, benchmarks, part 3
Table of Content
- Introduction
- Test1. Reading a single-column random query
- Test2. Reading a multi-column, complex random query
- Test3. Reading random JSON
- Test 4. Connection pools
- Test 5. Forcibly evaluate each row after reading
- Test 6. Benchmarking the HTTP server with various -c values
- Summary
Introduction
The PG2 library version 0.1.2 is out. One of its features is a significant performance boost when processing SELECT queries. The more fields and rows you have in a result, the faster is the processing. Here is a chart that measures a query with a single column:

No difference between the previous release of PG and the new one. But with nine fields, the average execution time is less now:

Briefly, PG2 0.1.2 allows you to fetch the data 7-8 times faster than Next.JDBC does. But before we proceed with other charts and numbers, let me explain how the new processing algorithm works.
-
Gzip
Коллеги, используйте gzip! Это простой способ уменьшить трафик в разы, если не на порядок. Буквально двумя строчками можно превратить гигабайты CSV в 200-300 мегабайтов. Разве не чудо? И делается это парой строк.
Теперь подробней. Gzip — старый алгоритм потокового сжатия. Ключевое слово “потоковый”. Это значит, алгоритму не нужен файл целиком; он читает окно байтов и выдает сжатое окно. За счет этого можно пережать любой поток, в том числе бесконечный.
В джаве потоки байтов используют часто. В ней легко втиснуть
GzipInputStreamилиGzipOutputStream, чтобы закодировать или декодировать поток. Например, если источник сжат Gzip, то обернем его так:(-> "some.file.gzip" (io/file) (io/input-stream) (GzipInputStream.))При чтении получим нормальный текст. А чтобы закодировать поток, делаем иначе: навесим на выходной поток
GzipOutputStreamи колбасим в него. Только в конце надо вызвать.finish, чтобы добить незавершенное окно.(let [out (-> "myfile.out.gzip" io/file io/input-stream) gzip (new GzipOutputStream out)] (while ... (.write gzip <bytes>)) (.finish gzip))Удивляет, что при всей банальности gzip используют мало. А ведь он отлично подходит для текстовых данных: HTML, JSON, CSS, JS, CSV. В текущем проекте сервисы гоняют гигабайты CSV и JSON, и хоть кто-нибудь подумал о сжатии…
Простой эксперимент: несжатый CSV — 146 мегабайтов, сжатый — 26. Почти в шесть раз. Даже если закодировать результат в base64, это даст +30% от 26 мегабайтов, то есть всего 35. Выгода все равно 4 раза. В том же Nginx сжатие gzip включается одной строкой в конфиге.
Еще больше мою веру укрепил крит на проде. Один из сервисов выплюнул 6 мегабайтов JSON, что не помещается в квоту AWS Lambda. Пришлось в спешке прикручивать сжатие, чтобы сообщенька пролезла.
Соответственно, бесят HTTP-клиенты, которые ничего не знают о Gzip. Работа с ними превращается в ад: сам проверь заголовки, сам закодируй-раскодируй… и в проекте используется именно такой! Он читает ответ как строку, не проверяя Content-Encoding, и если там gzip, получается чешуя. Авторам — большой ай-ай за игнор веб-стандартов.
Чем раньше вы возьмете gzip в проект, тем лучше. Потом все равно придется, но будет больно.
-
Женские истории
Когда читаю женские истории — Твиттер, блоги, журналистику, — вижу один и тот же паттерн:
- он мне не нравился, но я осталась на свидании;
- он мне не нравился, но мы целовались;
- он мне не нравился, но мы поехали к нему;
- он мне не нравился, но у нас был секс.
То есть он всю дорогу не нравился, но программа шла по плану — от кафе до постели.
Тут два момента: либо женщина и правда не знает, что если человек не нравится, то и секс с ним будет плохим. Надеюсь, теперь она это знает.
Либо женщина все знает, но понимает, что в данный момент на мужчину лучше она рассчитывать не может. Поэтому все, что случилось, выставляется как одолжение с ее стороны.
Чем раньше женщина прервет эту цепочку, тем лучше.
Writing on programming, education, books and negotiations.