-
Глобальное потепление
Уже год я преподаю английский: одному человеку и бесплатно. Первые полгода занимались по моей программе, которую я составил по книге Мерфи. Затем перешли на учебник Language Leader, по которому я учился когда-то сам.
Он хорошо составлен: он интересен взрослому, потому что авторы добавили много фактов из реальной жизни. Из него буквально фонит то, что было в мире на момент его составления. В том числе поэтому проходить некоторые темы забавно.
Одна из таких тем — погода. Лет 10-15 назад весь мир стоял на ушах из-за так называемого “глобального потепления”. Ему приписывались любые природные явления: шторм, торнадо — потепление, озоновая дыра — потепление, ядовитые испарения в тундре — потепление.
Забавно, как в учебнике повторяется то же самое. Упражнения самых разных форматов — текст, диалоги, грамматика, — и везде потепление, потепление, потепление. Других причин не бывает. А если и есть причина, то какая у нее первопричина? Угадайте.
Поэтому я воспринимаю учебник как исторический документ. Читая его, видно, как штырило людей на эту тему в прошлом. Гринпис и прочие радикальные группировки штурмовали платформы Шелл, а их отгоняли водометами. Население “прикладывало линейку” — если сегодня потеплело на градус, а завтра на два, то через месяц потеплеет на тридцать.
Сегодня, когда глобальное потепление уже выдохлось, повестка изменилась. Теперь у нас “борьба с изменением климата”. Это более гибкая конструкция, потому что нигде не говориться, как долго нужно бороться. Горизонт работ заложен уже в постановке задачи.
Грета куда-то пропала, а у меня смешной стикер-пак с ней. Пропадает без дела.
Хороших выходных!
-
PG2 release 0.1.15
PG2 version 0.1.15 is out. This version mostly ships improvements to connection pool and folders (reducers) of a database result. There are two new sections in the documentation that describe each part. I reproduce them below.
Connection Pool
Problem: every time you connect to the database, it takes time to open a socket, pass authentication pipeline and receive initial data from the server. From the server’s prospective, a new connection spawns a new process which is also an expensive operation. If you open a connection per a query, your application is about ten times slower than it could be.
Connection pools solve that problem. A pool holds a set of connections opened in advance, and you borrow them from a pool. When borrowed, a connection cannot be shared with somebody else any longer. Once you’ve done with your work, you return the connection to the pool, and it’s available for other consumers.
PG2 ships a simple and robust connection pool out from the box. This section covers how to use it.
A Simple Example
Import both core and pool namespaces as follows:
(ns demo (:require [pg.core :as pg] [pg.pool :as pool]))Here is how you use the pool:
(def config {:host "127.0.0.1" :port 5432 :user "test" :password "test" :database "test"}) (pool/with-pool [pool config] (pool/with-connection [conn pool] (pg/execute conn "select 1 as one")))The
pool/with-poolmacro creates a pool object from theconfigmap and binds it to thepoolsymbol. Once you exit the macro, the pool gets closed.The
with-poolmacro can be easily replaced with thewith-openmacro and thepoolfunction that creates a pool instance. By exit, the macro calls the.closemethod of an opened object, which closes the pool.(with-open [pool (pool/pool config)] (pool/with-conn [conn pool] (pg/execute conn "select 1 as one")))Having a pool object, use it with the
pool/with-connectionmacro (there is a shorter versionpool/with-connas well). This macro borrows a connection from the pool and binds it to theconnsymbol. Now you pass the connection topg/execute,pg/queryand so on. By exiting thewith-connectionmacro, the connection is returned to the pool.And this is briefly everything you need to know about the pool! Sections below describe more about its inner state and behavior.
Configuration
The pool object accepts the same config the
Connectionobject does section for the table of parameters). In addition to these, the fillowing options are accepted:Field Type Default Comment :pool-min-sizeinteger 2 Minimum number of open connections when initialized. :pool-max-sizeinteger 8 Maximum number of open connections. Cannot be exceeded. :pool-expire-threshold-msinteger 300.000 (5 mins) How soon a connection is treated as expired and will be forcibly closed. :pool-borrow-conn-timeout-msinteger 15.000 (15 secs) How long to wait when borrowing a connection while all the connections are busy. By timeout, an exception is thrown. The first option
:pool-min-sizespecifies how many connection are opened at the beginning. Setting too many is not necessary because you never know if you application will really use all of them. It’s better to start with a small number and let the pool to grow in time, if needed.The next option
:pool-max-sizedetermines the total number of open connections. When set, it cannot be overridden. If all the connections are busy and there is still a gap, the pool spawns a new connection and adds it to the internal queue. But if the:pool-max-sizevalue is reached, an exception is thrown.The option
:pool-expire-threshold-msspecifies the number of milliseconds. When a certain amount of time has passed since the connection’s initialization, it is considered expired and will be closed by the pool. This is used to rotate connections and prevent them from living for too long.The option
:pool-borrow-conn-timeout-msprescribes how long to wait when borrowing a connection from an exhausted pool: a pool where all the connections are busy and the:pool-max-sizevalue is reached. At this case, the only hope that other clients complete their work and return theri connection before timeout bangs. Should there still haven’t been any free connections during the:pool-borrow-conn-timeout-mstime window, an exception pops up.Pool Methods
The
statsfunction returns info about free and used connections:(pool/with-pool [pool config] (pool/stats pool) ;; {:free 1 :used 0} (pool/with-connection [conn pool] (pool/stats pool) ;; {:free 0 :used 1} ))It might be used to send metrics to Grafana, CloudWatch, etc.
Manual Pool Management
The following functions help you manage a connection pool manually, for example when it’s wrapped into a component (see Component and Integrant libraries).
The
poolfunction creates a pool:(def POOL (pool/pool config))The
used-countandfree-countfunctions return total numbers of busy and free connections, respectively:(pool/free-count POOL) ;; 2 (pool/used-count POOL) ;; 0The
pool?predicate ensures it’s aPoolinstance indeed:(pool/pool? POOL) ;; trueClosing
The
closemethod shuts down a pool instance. On shutdown, first, all the free connections get closed. Then the pool closes busy connections that were borrowed. This might lead to failures in other threads, so it’s worth waiting until the pool has zero busy connections.(pool/close POOL) ;; nilThe
closed?predicate ensures the pool has already been closed:(pool/closed? POOL) ;; trueBorrow Logic in Detail
When getting a connection from a pool, the following conditions are taken into account:
- if the pool is closed, an exception is thrown;
- if there are free connections available, the pool takes one of them;
- if a connection is expired (was created long ago), it’s closed and the pool performs another attempt;
- if there aren’t free connections, but the max number of used connection has not been reached yet, the pool spawns a new connection;
- if the number of used connections is reached, the pool waits for
:pool-borrow-conn-timeout-msamount of milliseconds hoping that someone releases a connection in the background; - by timeout (when nobody did), the pool throws an exception.
Returning Logic in Detail
When you return a connection to a pool, the following cases might come into play:
- if the connection is an error state, then transaction is rolled back, and the connection is closed;
- if the connection is in transaction mode, it is rolled back, and the connection is marked as free again;
- if it was already closed, the pool just removes it from used connections. It won’t be added into the free queue;
- if the pool is closed, the connection is removed from used connections;
- when none of above conditions is met, the connection is removed from used and becomes available for other consumers again.
This was the Connecton Pool section, and now we proceed with Folders.
Folders (Reducers)
Folders (which are also known as reducers) are objects that transform rows from network into something else. A typical folder consists from an initial value (which might be mutable) and logic that adds the next row to that value. Before returning the value, a folder might post-process it somehow, for example turn it into an immutable value.
The default folder (which you don’t need to specify) acts exactly like this: it spawns a new
transientvector andconj!es all the incoming rows into it. Finally, it returns apersistent!version of this vector.PG2 provides a great variety of folders: to build maps or sets, to index or group rows by a certain function. With folders, it’s possible to dump a database result into a JSON or EDN file.
It’s quite important that folders process rows on the fly. Like transducers, they don’t keep the whole dataset in memory. They only track the accumulator and the current row no matter how many of them have arrived from the database: one thousand or one million.
A Simple Folder
Technically a folder is a function (an instance of
clojure.lang.IFn) with three bodies of arity 0, 1, and 2, as follows:(defn a-folder ([] ...) ([acc] ...) ([acc row] ...))-
The first 0-arity form produces an accumulator that might be mutable.
-
The third 2-arity form takes the accumulator and the current row and returns an updated version of the accumulator.
-
The second 1-arity form accepts the last version of the accumulator and transforms it somehow, for example seals a transient collection into its persistent view.
Here is the
defaultfolder:(defn default ([] (transient [])) ([acc!] (persistent! acc!)) ([acc! row] (conj! acc! row)))Some folders depend on initial settings and thus produce folding functions. Here is an example of the
mapfolder that acts like themapfunction fromclojure.core:(defn map [f] (fn folder-map ([] (transient [])) ([acc!] (persistent! acc!)) ([acc! row] (conj! acc! (f row)))))Passing A Folder
To pass a custom folder to process the result, specify the
:askey as follows:(require '[pg.fold :as fold]) (defn row-sum [{:keys [field_1 field_2]}] (+ field_1 field_2)) (pg/execute conn query {:as (fold/map row-sum)}) ;; [10 53 14 32 ...]Standard Folders and Aliases
PG provides a number of built-in folders. Some of them are used so often that it’s not needed to pass them explicitly. There are shortcuts that enable certain folders internally. Below, find the actual list of folders, their shortcuts and examples.
Column
Takes a single column from each row returning a plain vector:
(pg/execute conn query {:as (fold/column :id)}) ;; [1 2 3 4 ....]There is an alias
:columnthat accepts a name of the column:(pg/execute conn query {:column :id}) ;; [1 2 3 4 ....]Map
Acts like the standard
mapfunction fromclojure.core. Applies a function to each row and collects a vector of results.Passing the folder explicitly:
(pg/execute conn query {:as (fold/map func)})And with an alias:
(pg/execute conn query {:map func})Default
Collects unmodified rows into a vector. That’s unlikely you’ll need that folder as it gets applied internally when no other folders were specified.
Dummy
A folder that doesn’t accumulate the rows but just skips them and returns nil.
(pg/execute conn query {:as fold/dummy}) nilFirst
Perhaps the most needed folder,
firstreturns the first row only and skips the rest. Pay attention, this folder doesn’t have a state and thus doesn’t need to be initiated. Useful when you query a single row by its primary key:(pg/execute conn "select * from users where id = $1" {:params [42] :as fold/first}) {:id 42 :email "test@test.com"}Or pass the
:first(or:first?) option set to true:(pg/execute conn "select * from users where id = $1" {:params [42] :first true}) {:id 42 :email "test@test.com"}Index by
Often, you select rows as a vector and build a map like
{id => row}, for example:(let [rows (jdbc/execute! conn ["select ..."])] (reduce (fn [acc row] (assoc acc (:id row) row)) {} rows)) {1 {:id 1 :name "test1" ...} 2 {:id 2 :name "test2" ...} 3 {:id 3 :name "test3" ...} ... }This process is known as indexing because later on, the map is used as an index for quick lookups.
This approach, although is quite common, has flaws. First, you traverse rows twice: when fetching them from the database, and then again inside
reduce. Second, it takes extra lines of code.The
index-byfolder does exactly the same: it accepts a function which is applied to a row and uses the result as an index key. Most often you pass a keyword:(let [query "with foo (a, b) as (values (1, 2), (3, 4), (5, 6)) select * from foo" res (pg/execute conn query {:as (fold/index-by :a)})] {1 {:a 1 :b 2} 3 {:a 3 :b 4} 5 {:a 5 :b 6}})The shortcut
:index-byaccepts a function as well:(pg/execute conn query {:index-by :a})Group by
The
group-byfolder is simlar toindex-bybut collects multiple rows per a grouping function. It produces a map like{(f row) => [row1, row2, ...]}whererow1,row2and the rest return the same value forf.Imagine each user in the database has a role:
{:id 1 :name "Test1" :role "user"} {:id 2 :name "Test2" :role "user"} {:id 3 :name "Test3" :role "admin"} {:id 4 :name "Test4" :role "owner"} {:id 5 :name "Test5" :role "admin"}This is what
group-byreturns when grouping by the:rolefield:(pg/execute conn query {:as (fold/group-by :role)}) {"user" [{:id 1, :name "Test1", :role "user"} {:id 2, :name "Test2", :role "user"}] "admin" [{:id 3, :name "Test3", :role "admin"} {:id 5, :name "Test5", :role "admin"}] "owner" [{:id 4, :name "Test4", :role "owner"}]}The folder has its own alias which accepts a function:
(pg/execute conn query {:group-by :role})KV (Key and Value)
The
kvfolder accepts two functions: the first one is for a key (fk), and the second is for a value (fv). Then it produces a map like{(fk row) => (fv row)}.A typical example might be a narrower index map. Imagine you select just a couple of fields,
idandemail. Now you need a map of{id => email}for quick email lookup by id. This is wherekvdoes the job for you.(pg/execute conn "select id, email from users" {:as (fold/kv :id :email)}) {1 "ivan@test.com" 2 "hello@gmail.com" 3 "skotobaza@mail.ru"}The
:kvalias accepts a vector of two functions:(pg/execute conn "select id, email from users" {:kv [:id :email]})Run
The
runfolder is useful for processing rows with side effects, e.g. printing them, writing to files, passing via API. A one-argument function passed torunis applied to each row ignoring the result. The folder counts a total number of rows being processed.(defn func [row] (println "processing row" row) (send-to-api row)) (pg/execute conn query {:as (fold/run func)}) 100 ;; the number of rows processedAn example with an alias:
(pg/execute conn query {:run func})Table
The
tablefolder returns a plain matrix (a vector of vectors) of database values. It reminds thecolumnsfolder but also keeps column names in the leading row. Thus, the resulting table always has at least one row (it’s never empty because of the header). The table view is useful when saving the data into CSV.The folder has its inner state and thus needs to be initialized with no parameters:
(pg/execute conn query {:as (fold/table)}) [[:id :email] [1 "ivan@test.com"] [2 "skotobaza@mail.ru"]]The alias
:tableaccepts any non-false value:(pg/execute conn query {:table true}) [[:id :email] [1 "ivan@test.com"] [2 "skotobaza@mail.ru"]]Java
This folder produces
java.util.ArrayListwhere each row is an instance ofjava.util.HashMap. It doesn’t require initialization:(pg/execute conn query {:as fold/java})Alias:
(pg/execute conn query {:java true})Reduce
The
reducefolder acts like the same-name function fromclojure.core. It accepts a function and an initial value (accumulator). The function accepts the accumulator and the current row, and returns an updated version of the accumulator.Here is how you collect unique pairs of size and color from the database result:
(defn ->pair [acc {:keys [sku color]}] (conj acc [a b])) (pg/execute conn query {:as (fold/reduce ->pair #{})}) #{[:xxl :green] [:xxl :red] [:x :red] [:x :blue]}The folder ignores
reducedlogic: it performs iteration until all rows are consumed. It doesn’t check if the accumulator is wrapped withreduced.The
:reducealias accepts a vector of a function and an initial value:(pg/execute conn query {:reduce [->pair #{}]})Into (Transduce)
This folder mimics the
intologic when it deals with anxform, also known as a transducer. Sometimes, you need to pass the result throughout a bunch ofmap/filter/keepfunctions. Each of them produces an intermediate collection which is not as fast as it could be with a transducer. Transducers are designed such that they compose a stack of actions, which, when being run, does not produce extra collections.The
intofolder accepts anxformproduced bymap/filter/comp, whatever. It also accepts a persistent collection which acts as an accumulator. The accumulator gets transformed into a transient view internally for better performance. The folder usesconj!to push values into the accumulator, so maps are not acceptable, only vectors, lists, or sets. When the accumulator is not passed, it’s an empty vector.Here is a quick example of
intoin action:(let [tx (comp (map :a) (filter #{1 5}) (map str)) query "with foo (a, b) as (values (1, 2), (3, 4), (5, 6)) select * from foo"] (pg/execute conn query {:as (fold/into tx)})) ;; ["1" "5"]Another case where we pass a non-empty set to collect the values:
(pg/execute conn query {:as (fold/into tx #{:a :b :c})}) ;; #{:a :b :c "1" "5"}The
:intoalias is a vector where the first item is anxformand the second is an accumulator:(pg/execute conn query {:into [tx []]})To EDN
This folder writes down rows into an EDN file. It accepts an instance of
java.io.Writerwhich must be opened in advance. The folder doesn’t open nor close the writer as these actions are beyond its scope. A common pattern is to wrappg/executeorpg/queryinvocations with thewith-openmacro that handles closing procedure even in case of an exception.The folder writes down rows into the writer using
pr-str. Each row takes one line, and the lines are split with\n. The leading line is[, and the trailing is].The result is a number of rows processed. Here is an example of dumping rows into a file called “test.edn”:
(with-open [out (-> "test.edn" io/file io/writer)] (pg/execute conn query {:as (fold/to-edn out)})) ;; 199Let’s check the content of the file:
[ {:id 1 :email "test@test.com"} {:id 2 :email "hello@test.com"} ... {:id 199 :email "ivan@test.com"} ]The alias
:to-ednaccepts a writer object:(with-open [out (-> "test.edn" io/file io/writer)] (pg/execute conn query {:to-edn out}))To JSON
Like
to-ednbut dumps rows into JSON. Accepts an instance ofjava.io.Writer. Writes rows line by line with no pretty printing. Lines are joined with a comma. The leading and trailing lines are square brackets. The result is the number of rows put into the writer.(with-open [out (-> "test.json" io/file io/writer)] (pg/execute conn query {:as (fold/to-json out)})) ;; 123The content of the file:
[ {"b":2,"a":1}, {"b":4,"a":3}, // ... {"b":6,"a":5} ]The
:to-jsonalias accepts a writer object:(with-open [out (-> "test.json" io/file io/writer)] (pg/execute conn query {:to-json out}))
For more details, you’re welcome to the readme file of the repo.
-
Перекладывание
Иногда говорят: это тебе не джейсоны перекладывать, тут думать надо. А между прочим, перекладывать джейсоны – очень трудное занятие.
Прилетает вам джейсон из сети. Надо его прочитать, провалидировать, распарсить даты, подрезать лишнее. Потом выгрести из базы то, из кэша се, из S3 третье и все это собрать в нечто нужное бизнесу. Сделать эксельку, положить в S3 и отписать в очередь.
На каждом шаге может быть сто причин для эксепшена. Записать логи, не раскрывая бизнес-данных и секретов, собрать исключения и отправить в Сентри.
Иные джейсоны пятиэтажной вложенности. Нужно рыскать по их кишкам и строить обратные мапы (индексы). Потом передавать по пять индексов в другие функции.
Читать из базы миллион джейсонов так, чтобы не умереть от нехватки памяти в AWS.
В идеале покрыть все случаи тестами, желательно с Докером, чтобы были настоящие база, Редис, S3 и так далее.
Все еще легко, на ваш взгляд? Не знаю, мне кажется трудным. Поэтому над “перекладыванием” я не смеюсь.
-
Excel и CSV
Маленькая техническая заметка. Не пользуйтесь CSV в надежде, что он откроется в Экселе. Если ваши потребители – люди с Экселем (а таких большинство), нужно генерить
.xlsx, а не.csv.Дело в том, что Эксель писали в Микрософте. Может быть, сегодняшний MS уже обрел какую-то человечность. Но Эксель отсчитывает возраст с 1985 года – прямо как я – и старше многих читателей этой заметки. Поэтому ни о какой человечности говорить не приходится.
Эксель никогда не откроет CSV без ошибок. Он обязательно промажет с разделителем: если в файле запятая, он ищет точку с запятой и наоборот. Для обхода придумали грубый костыль: в первой строке может быть выражение sep=, и тогда Эксель возьмет запятую. Но этот заголовок ломает парсеры CSV, которые ни о каком Экселе не слышали.
Разделитель по умолчанию может зависеть от локали. У француза откроется, а у австрийца не откроется.
Эксель по-прежнему игнорирует UTF8. Немецкие умляуты становятся кракозябрами. Махинации с меткой BOM ни к чему не приводят.
В Экселе есть мастер импорта из CSV, но можно подумать, людям больше нечем заняться, как импортировать что-то куда-то ради таблички.
В общем, нужно напрячь булки и выкинуть CSV, и вместо этого генерить нормальный Эксель.
Если вдруг у вас Джава или Кложа, берите fastexcel и fastexcel-reader – они быстрее и компилируются Граалем. Все, что основано на Apache POI, тормозное и не компилируется Граалем. Я эту дорогу прошел и вот делюсь с вами.
-
Мои объявления
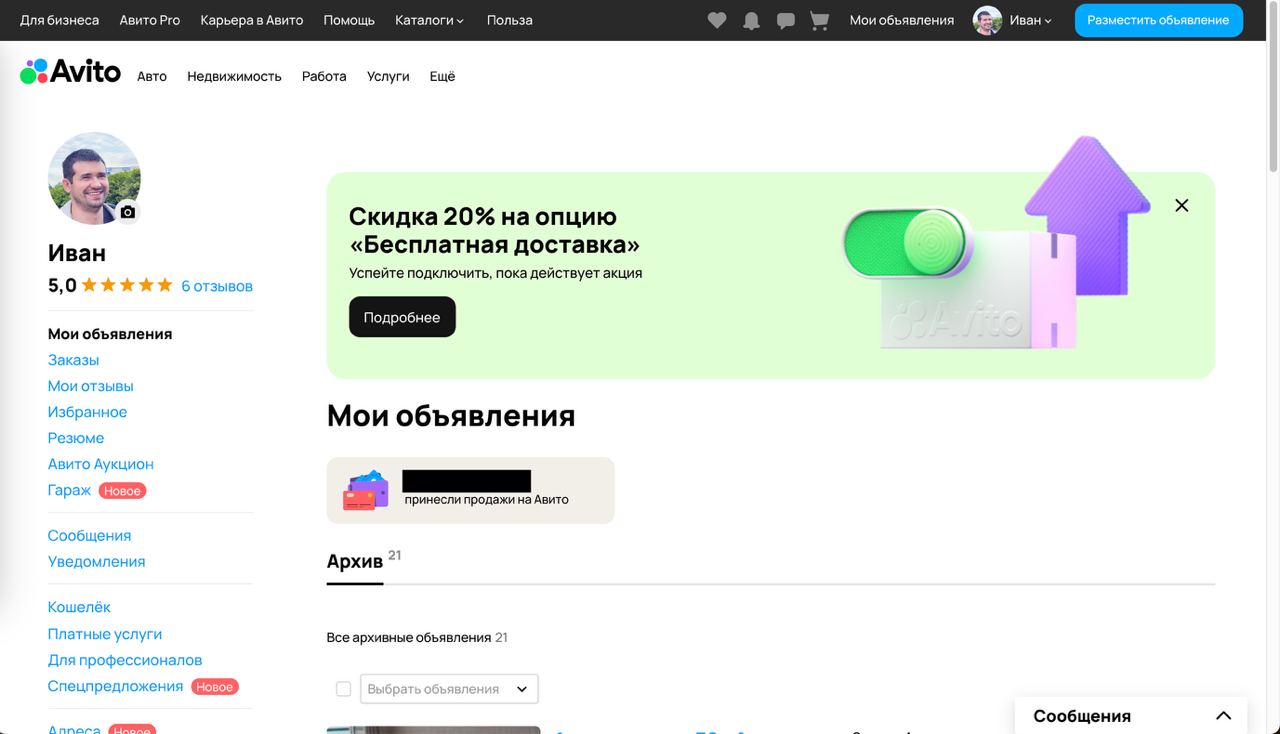
Авито, страница “Мои объявления” — разве это не забавно? На экране все что угодно, кроме моих объявлений. Огромная плашка, громадные пустоты. Слоеный дизайн, когда каждый слой, пусть даже занимает сантиметр в ширину, растекается на весь экран.
Очередной калека-дизайнер, которому “не хватило места”. Важная часть уехала на экран ниже — потому что первый экран занял всякий шлак.
Считаю, таких дизайнеров надо даже не учить, а лечить. Обучение бессильно, пусть действуют профильные специалисты.
-
Загрузка в Амазоне
У веб-панели S3 есть особенность: если скачать оттуда файл, Амазон поправит расширение в зависимости от Content-Type, который назначили файлу при создании. Например, если у файла нет расширения, а Content-Type равен
application/json, то Амазон допишет в конец .json, чтобы файлик открылся.Казалось бы, хорошо? А вот что имеем на практике.
Если залить файл
hello.json.gzip, внутри которого сжатый Gzip-ом JSON, и указать заголовкиContent-Type: application/json,Content-Encoding: gzip, то при загрузке произойдет следующее.Файл будет декодирован Амазоном, чтобы клиенту не пришлось делать это руками. Не бог весть какая помощь, потому что и текстовые редакторы, и файловые менеджеры открывают gzip-файлы. Но ладно.
После раскодировки Амазон смотрит: что там внутри? Application/json? Значит удалим
.gzipи добавим.json. В результате получается файлhello.json.json. Я не шучу, проверьте сами.Второй случай: я залил в Амазон файл
report.xlsx, но указал не тот Content-Type. Указал старыйapplication/vnd.ms-excelдля xls документов, а надо было такую колбасу:application/vnd.openxmlformats-officedocument.spreadsheetml.sheet. При загрузке Амазон молча исправил расширение с.xlsxна.xls. А Эксель тоже хорош: по клику на файл он пишет, что формат битый, ничего не знаю – нет бы первые 100 байтов проверить, тупица.На ровном месте Амазон заруинил файл, хотя никто об этом не просил.
Понимаете, не нужно мне помогать! Не нужно что-то тайно переименовывать для моей же пользы. Если прям чешется в одном месте – спроси, и я нажму “больше не спрашивать”.
Кроме того, надо помнить: в Амазоне работают не боги, а такие же кодеры, как и везде. Перед нами обычный баг, который живет в проде не один год, и никому нет дела. Баг состоит в том, что махинации с расширением нужно производить только если у файла нет расширения. Вдобавок у расширения приоритет выше, чем у Content-Type, потому что последний – это метаинформация, которая может потеряться или исказиться. Вероятность потерять расширение гораздо ниже, нежели Content-Type.
Верю, что когда-нибудь в Амазоне это поймут.
-
Время в Interstellar
Вы же смотрели Интерстеллар? Помните высадку на планету с волной? А музыку в фоне, такую тревожную, помните? Тик-так, тик-так по нарастающей?
Этот тик-так — неспроста. Каждый тик равен 1.37 секунды, и за это время на Земле проходят сутки. Именно такое соотношение времени между Землей и той планетой из-за близости к черной дыре. Ганс Циммер гений.
Когда знаешь об этом, в сцену добавляется новый оттенок. Теперь уже не смотришь на метания за разбитым кораблем: слушаешь тик-так и представляешь, как впустую проходит чья-то жизнь — твоя, например.
Иногда по вечерам, вытряхнув себя из-за компа, я чувствую что-то похожее. Словно жизнь — это фильм, а в фоне кто-то цокает языком. Исправляешь чей-то быдлокод и косяки, потом идешь домой и думаешь — что я вообще делал?
Нечто похожее встретилось в дневниках Корнея Чуковского времен блокады Ленинграда: “дни сгорают как бумажные”. Потому он и великий писатель, что не уходят, не летят, а именно сгорают.
Впрочем, потом меня отпускает, и я снова иду править чужой код и косяки. И так постоянно.
-
Список через запятую
Одна из самых дурацких вещей в айти – это список через запятую, например:
(1, 2, 3) ["test", "foo", "hello"] [{:id 1}, {:id 2}, {:id 3}]Каждый, кто работал с таким форматом, знает, какой геморрой учитывать запятые. Элементы нельзя просто записать в цикле. Нужно собрать их в массив, а потом join-ить запятой. Это сводит на нет стриминг элементов, когда их много. А чтобы работал стриминг, нужно завести флажок “запятая уже была”, выставить его в первый раз и постоянно проверять: была или не была?
То есть на каждом шаге из миллиона нужно делать эту проверку, которая сработала один раз. Из-за какой-то никчемной запятой.
Какие проблемы возникнут, если запятые убрать?
(1 2 3) ["test" "foo" "hello"] [{:id 1} {:id 2} {:id 3}]Не вижу причины, по которой любой из списков не может быть распаршен. Все три читаются и подлежат парсингу на ура.
В одном скобочном языке запятые вообще считаются пробелами: они уничтожаются парсером, словно их нет. И это никак не влияет работу: все читается, и даже лучше: меньше визуального шума.
Список через запятую – рудимент, от которого пора избавиться. Случись вам изобретать свой формат данных – откажитесь от запятых как значимых символов.
-
Выпадашка в Хроме
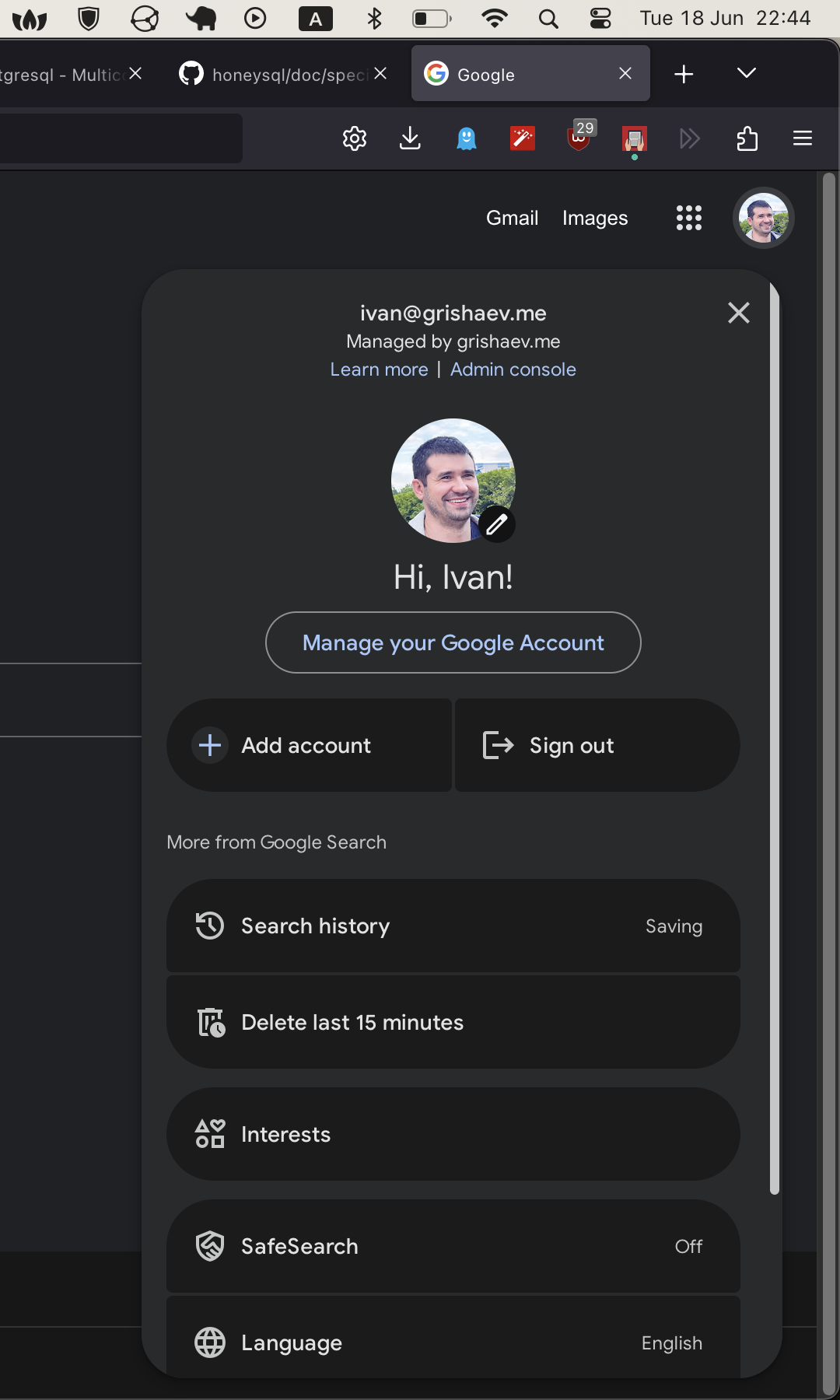
На скриншоте — типичная ситуация наших дней. По клику на аватару появляется выпадашка, но содержимое не вмещается, и у выпадашки появляется прокрутка.
Окно браузера растянуто максимально, ничего не сжато. Зум нулевой. Никаких вредоносных действий с моей стороны. Просто дизайнеру “не хватило” места. Еще бы: если обернуть каждый элемент в паддинг, скруглить углы, добавить отступы где только можно, поместить всю фигуру в другой паддинг, сместить вниз — откуда ж возьмется место?
На полном серьезе спрашиваю: что происходит с фронтендерами? Может у них пост-ковидный синдром? Вакцина дала побочку? Иначе это не объяснить. Дай фронтендеру экран размером со стену — и он поместит все нужное в выпадашку, которая появится по клику на гамбургер. Внутри все “воздушное”, не хватает места, и появляется прокрутка.
Раньше можно было понять: разрешение 800 на 600, кривой IE6, умирающий Netscape, ранние оперы и фейерфоксы. У каждого багов — как блох на жучке. Но сегодня-то что? Везде ретины, 4К, только Хром и его поделки. Что мешает делать нормально: без выпадашек с прокрутками?
Какая-то загадка.
-
Датомик
Лет семь назад я увлекся Датомиком. Кто не знает, это база данных, написанная на Сlojure и Java. Среди ее плюсов – неизменяемость (данные только накапливаются), независимость от времени (можно вернуться в прошлое) и выразительный язык запросов Datalog, взятый из Пролога.
Я долго ходил вокруг да около, а потом повезло: семья уехала на неделю, и я провел это время, читая доки и экспериментируя. У меня тогда был пет-проект на Postgres, и я перевел его на Датомик. Позже я использовал его в других проектах, в том числе в Хайлоад-капах от Mail.ru. Я написал статью про миграцию с Постгреса на Датомик, и она даже попала на главную Хакер-Ньюз.
У Датомика есть важное свойство: он красивый. Бросил взгляд, и сразу мысль – да, круто. Это изящная абстракция, воздвигнутая на элементарных вещах. Мало проектов, где эти свойства – изящность и простота – выражены столь же ярко.
Я много играл с Датомиком и даже пытался реализовать его поверх реляционных баз. Кое-что мне удалось, но поделки я так и не довел до ума. Практика показала, что скучные Postgres/Maria удобней в работе.
Прежде всего, неизменяемость из коробки не нужна. Там, где нужно хранить историю, Postgres/Maria справляются за счет триггеров или запросов вида
INSERT ... FROM UPDATE/INSERT/DELETE. Когда говорят об исторических данных, у меня сразу вопрос – как вы ими пользуетесь? Они вообще вам нужны?Далее: страшные буквы GDPR. Если пользователь хочет удалить свои данные, с Датомиком будут проблемы. В Датомике атрибуты не меняются, а добавляются новые с поздним временем. Поэтому, читая один и тот же атрибут в разное время, получим разные значения. Но GDPR требует, чтобы в базе физически не было личных данных. Если вы записали в базу атрибут
(42, :user/name "XXXXXX"), то старый атрибут(42, :user/name "Ivan")остался, и прочитать его – дело техники.В Датомике есть функция физической очистки атрибутов, но она дорогая и выполняется во время обслуживания, то есть требует остановки прода.
Можно отключить историю атрибутов, но тогда вопрос – зачем вообще история, которой так гордится Датомик?
Кто-то скажет: ладно, пусть имя пользователя будет без истории, а остальное с историей. Практика показывает, что GDPR требует чистки чуть ли не всех таблиц. Когда мы удаляли пользователей из приложения с короткими видео, то пришлось шерстить десятки таблиц: профили, лайки, коменты, друзья, подписчики, обращения, сообщения… это были недели ада. Если представить, что у каждой таблицы история, ситуация станет еще хуже.
У Датомика никакой поиск, нет сортировки и пагинации. Как с этим жить – решать вам. Кого ни спрашивал – каждый пилит свои костыли, каждый случай – свое маленькое приключение.
Есть еще кое-что: Датомик, при всей своей красоте, нарушает доменную область. Я как-то говорил о том, что главное свойство домена – его ортогональность другим доменам. Другими словами, у базы и кода на Сlojure разные зоны ответственности. Датомик стирает эту границу: он превращает базу в хранилище, к которой только он имеет доступ. Этому есть объяснение, поскольку физически данные хранятся как бинарные дампы с кусками индексов, и работать с ними умеет только Датомик.
На практике это выливается в то, что если я хочу поправить записи в Датомике, нужно писать код на Кложе, который выгребает данные, исправляет и записывает в базу.
Это резко контрастирует с Postgres/Maria, которые предлагают свои языки и инструменты для работы с данными. Это и есть домен, когда я могу исправить данные, не обращаясь к Кложе. Бывает, я сижу в psql днями и неделями, манипулируя данными на чистом SQL.
Датомик нарушает это правило. Да, у него есть веб-консоль, но по сравнению с psql она крайне уныла, а до программ уровня PGAdmin или DBeaver ей как до луны.
Датомик как мороженное: он красивый, но позже липнет и затекает туда, где ему не следует быть. Поэтому я прекратил с ним шашни и продолжаю работать с Постгресом. И кстати, Постгрес в последние годы просто летит в космос, нарадоваться не могу.
Выбирая Датомик, имейте в виду вышесказанное.
Writing on programming, education, books and negotiations.