-
Вайб-кодинг и новички
Все чаще слышу комментарии: помогите решить задачу, я нуб, сижу за вайб-кодингом две недели, ничего не выходит. На мой взгляд, это очень тревожно, и вот почему.
Плохо не то, что человек чего-то не умеет – всегда можно научиться. Беда в том, что он прошляпил две недели, хотя мог бы спросить уже через час.
Ресурсы вроде StackOverflow для того и созданы, чтобы люди общались и передавали знания. Кроме SO, сейчас полно тематических Слак, Дискордов, каналов в Телеграме. Заходи, спрашивай.
Известно, что правильно заданный вопрос уже частично решает задачу. Но вместо того, чтобы сформировать вопрос, новичок ведет долгие и путаные диалоги с нейросетью. Он не развивает важный навык – внятно объяснить другим, какую проблему решает и что надеется получить.
В итоге контур замыкается: новичок что-то требует от нейросети, а у нее либо токены кончились, либо контекст потерялся. Либо самое худшее: новичку не хватает знаний, чтобы объяснить, чего он хочет. Получается порочный круг, примерно как спор двух студентов за бутылкой водки: компетенции нет ни у одной из сторон.
Другой минус в том, что нейросеть не может критиковать плохие решения. Скажем, для обхода графа человек затащил библиотеку, не зная, что из коробки для этого есть три разных способа. Это напоминает фронтендеров, которые, чтобы выровнять текст, ищут в npm пакет Leftpad. Последствия такого мышления всем известны.
Недаром в Твиттере кто-то сказал: нейросети для студентов, стажеров и всяких новичков – это как бесплатный сахар для диабетиков. Вместо того, чтобы развивать свой интеллект, они перекладывают задачу на искусственный – не понимая, для этого уже нужен интеллект! В этом точно нет ничего хорошего.
-
Обсуждение с AI
В разговорах про AI люди говорят: обсуждаю с ним задачу. Я даже недавно спрашивал, как вы программируете с AI, и большинство ответили – обсуждаю. Именно это мне непонятно – что именно обсуждают с моделью?
Скажем, дали вам задачу: сделать рейтинг пользователей. Что тут обсуждать? Нужно создать две таблицы: начисления баллов и рейтинг. Добавить несколько апишек: начислить баллы, получить начисления, получить топ-100 пользователей. Написать тесты, обновить документашку, погонять на стейджинге.
Все это записывается на бумажку, а потом каждый пункт детализируется. Таблицы с такими-то полями в такой-то схеме. Апишки принимают то и возвращают это. Тестировать так-то. Задеплоить туда-то.
Когда более-менее ясно, созваниваешься с тем, кто принимает работу. Так пойдет? Пойдет, только добавь это и вот это. Окей. Далее пишешь миграции, добавляешь апишки, тесты и так далее.
И вот теперь вопрос – что из этого вы обсуждаете с моделью? Вы что, не можете объявить таблицу? Или рестовую апишку добавить? Вы же каждый день их пишете! Я бы еще понял, если бы вам сказали написать драйвер клавиатуры на ассемблере. Но вам же дают рутинную рутину – то, что вы мусолите каждый день!
Если вы не можете разложить сложную задачу на шаги, это плохо. Этот навык нужно развивать, он должен быть своим, а не на аутсорсе у модели. То же самое с технической сложностью: если вы прям вообще не понимаете, с какой стороны подойти к задаче, то скорее всего она плохо поставлена. Нужно созваниваться, догонять людей, выяснять требования. Это тяжело, неприятно, но это данность профессии. Выяснение деталей порой занимает больше, чем исполнение. И с какой стороны сюда приткнуть ИИ-модель, я все еще не понимаю.
Как-то посмотрел два видоса про кодинг с моделью. Если честно, ничего не понял. Человек в VS Code постоянно трындит, и я терялся, к кому он обращается: к зрителям, к гостю или к модели. Без конца куда-то кликает, переключает буферы, словом – хаос. Я даже не понял, какую задачу он ставил, не говоря о том, достиг ли ее.
Словом, вам, конечно, виднее, но я считаю, что для повседневной работы модель не нужна. А уж сколько на них сливают времени и денег – представить страшно.
-
Тире
С удивлением узнал, что AI-тексты определяют по наличию тире. Мол, если есть тире, значит писала нейросеть. Потому что как иначе набрать его обычному пользователю? На клавиатуре тире нет, значит — читер.
Доходит то того, что всякие рекрутеры смотрят на сопроводительное письмо, видят тире и раз — в мусорку.
Если вы тот самый рекрутер или тоже объявили охоту на тире, то знайте следующее. Набрать его сегодня гораздо легче, чем раньше. Если пять лет назад надо было ставить раскладку Бирмана, то сегодня это решается автозаменой. Например, пишешь в Гугло-доке или Ворде двойной дефис, и он становится тире. Прикладываю видео.
Кстати, почти любой текст я пишу в Гугло-доке. Не потому, что я фанат Гугла, а просто у него отличная проверка ошибок. Он проверяет не отдельные слова, а их сочетания; ловит повторы, неверные предлоги (“из” и “их”) и многое другое.
Так что тире — не признак нейросети. В этом тексте оно встречается четыре раза, и я ни разу не утруждался с его набором: просто жал двойной дефис. Эйчары, рекрутеры и прочая братия — вы там подкалибруйте детектор AI, что ли. А то попали пальцем в небо.
-
Как вы используете AI?
Спрашиваю без сарказма: что вы такое пишете на своем AI? Чем он помогает? Из каждого утюга слышно, что продуктивность увеличилась в разы. Мне не хватает конкретики – за счет чего? Как это выглядит? Модель пишет функцию по описанию? Генерит тесты? Словом, я не понимаю.
Если судить по себе, то скажу вот что. Моя работа примитивна. Я хожу в базу, в сетевые сервисы, S3, всякие очереди задач. Все сводится к тому, чтобы собрать из ошметков данных что-то целостное и записать в файл или базу. Точка. Оптимизации я придумываю сам, чтобы мозги не засохли. Скажем, использую стримы, виртуальные треды, параллельность, иной раз – алгоритмы. Но вообще это можно выкинуть. Пусть код работает в два раза медленней, никто не заметит.
Моя работа тупая. Я много копирую, потому что фрагментация кодовых баз огромна. Иногда я честно пытаюсь представить, как бы выглядел AI в моей работе, но не могу даже близко. Что конкретно мне попросить у AI? Сходить в базу? Написать запрос с двумя джоинами? Я его на бумажке напишу лучше, чем многие в редакторе. Тесты? Я просто скопирую другие и слегка поправлю.
Говорят: используй AI для новых областей. Ну, тут дело удобства. Для новых областей есть документация, книги, cookbook, стек-оверфлоу, слаки-телеграмы. Неужели этого не хватает?
Как-то я покупал Idea Ultimate Edition; среди прочих фич у нее продвинутый подсказчик. Например, пишешь
InputStream in = newи он предлагает: стрим из файла, из сети и так далее. А если на следующей строчке написать
OutputStream out =, то вероятность правильного варианта равна единице.
И все же эту хрень я отключил. Поначалу кажется, что да – супер удобно. Нажал пару клавиш и выбрал из выпадашки! Продуктивность бьет в потолок. А потом понимаешь: это выбивает из потока. Когда я пишу код, то обычно знаю, что мне нужно. А тут на каждой строчке тебя прерывают и предлагают выбор. Нужно остановиться, пробежать глазами, оценить адекватность, выбрать. На это уходят такты мозга.
Напоминает парное программирование, когда ты в потоке, а собеседник кукарекает: давай переименуем класс, давай переместим функцию и так далее – не понимая, что сперва нужно в принципе решить задачу, а потом заняться украшательством. Просто ему нечего делать, и он изображает вовлеченность.
Ради чего это написано. Хорошо, если бы кто-то подробно описал, за счет чего повысилась продуктивность с AI. В идеале нужны примеры, скажем, вот по такому описанию я получил код, он полностью рабочий. Я бы послушал.
-
Значения-классы
В очередной раз читаю спор а-ля “динамическая типизация против статической”. Заметил вот что.
Попадаются отчаянные джависты, которые говорят: даже простые значения нужно делать классами, чтобы не допустить ошибки. Например, телефон должен быть не строкой, а классом
Phone, который оборачивает строку; почта — классомEmail, имя —Nameи так далее.Идея в том, что если метод принимает имя, телефон и почту, то строки легко перепутать: передать почту вместо имени или телефон вместо почты. А если параметры типизированы —
Name, Email, Phone, — то ошибки быть не может.То же самое предлагается делать с числами: температура по Фаренгейту — один класс, по Цельсию — другой. Для коров и лошадей тоже разные классы:
HorseNumberиCowNumber. У таких классов свои методы сложения и вычитания, чтобы можно было сложить коров только с коровами, но не дай бог с лошадьми.К счастью, в Джаве нельзя наследоваться от базовых классов вроде
String,Numberи других. Каким-то образом ее создатели догадались, что если каждый Васян будет делать свои строки и числа, то откроется дверь в ад.Но нашлись лазейки. Иные джависты делают записи с одним полем
value, примерно так:public record Phone(value String) {}; Phone phone = new Phone("223-322");Примеры, что они приводят, на первый взгляд красивы. Сигнатура как в примере ниже
someMethod(Name name, Email email, Phone phone)действительно выглядит лучше, чем
String, String, String.Однако первая беда в том, что ничто не мешает мне выполнить такой код:
Phone phone = new Phone("test@hello.com");и передать этот псевдо-телефон в метод. Можно добавить валидацию в конструктор, но в любом случае она сработает в рантайме — компилятор ничего не знает о том, что строка
test@hello.com— это неправильный телефон.А вторая беда в том, что классы не дружат между собой. Даже если ты наколбасил классы телефона, почты и числа коров, они не подойдут другим таким же классам. Например, коллега создал класс
UserPhone, полностью аналогичный вашему. Компилятору все равно, что они одинаковы: нельзя передать Phone туда, где ожидаетсяUserPhoneи наоборот. Все это закончится конвертацией в духе:UserPhone ph = new UserPhone(phone.value());Джавистам, которые мечтают о таком подходе, я бы пожелал столкнуться с ним на практике. Чтобы у них был проект с классами
ЧислоЯблок,ЯблокВЯщике,ЧислоЯщиков,ВозрастПользователя,ВозрастСотрудника,КуритИлиНет,МужчинаИлиЖенщинаи так далее. Как говорится, бойся своих желаний!Кстати, чтобы избежать путаницы в параметрах, они должны поддерживать передачу по имени, например так:
new User(name="...", phone="...", email="...");В Джаве такого нет; там приняты билдеры:
User.builder().name("...").phone("...").email("...").build();Билдеры занимают экраны кода, но с таким синтаксисом легче понять семантику параметров.
Общая проблема в том, что джависты не видят баланса между безопасностью и удобством. Если ради этой вашей безопасности — которая все еще под вопросом — нужно поступиться удобством, то я не согласен.
-
Книга о Postgres и JSON
Поздравьте меня, что ли: в эту пятницу я закончил писать черновик новой книжки. Это будет книга о Postgres. Вся она посвящена одной специфичной теме: работе с JSON. Расскажу, как хранить в Postgres сложные документы, индексировать их, версионировать, делать отчеты, работать с ними из Python, искать разными способами и многое другое.
Главы
- Введение в документы
- Базовые возможности JSON
- JSON в таблицах
- Индексирование JSON
- Ограничения в документах
- Язык путей JSONPath
- Отчеты и функции
- Функции на языке Python
- Версионирование и архивация документов
- Релевантный поиск
“Черновик” означает, что текст полностью готов, но пропущены места с кодом. Буду их заполнять. Далее верстка, обложка и печатная подготовка.
Будет в следующем году, скорее всего летом.
-
Новая модель
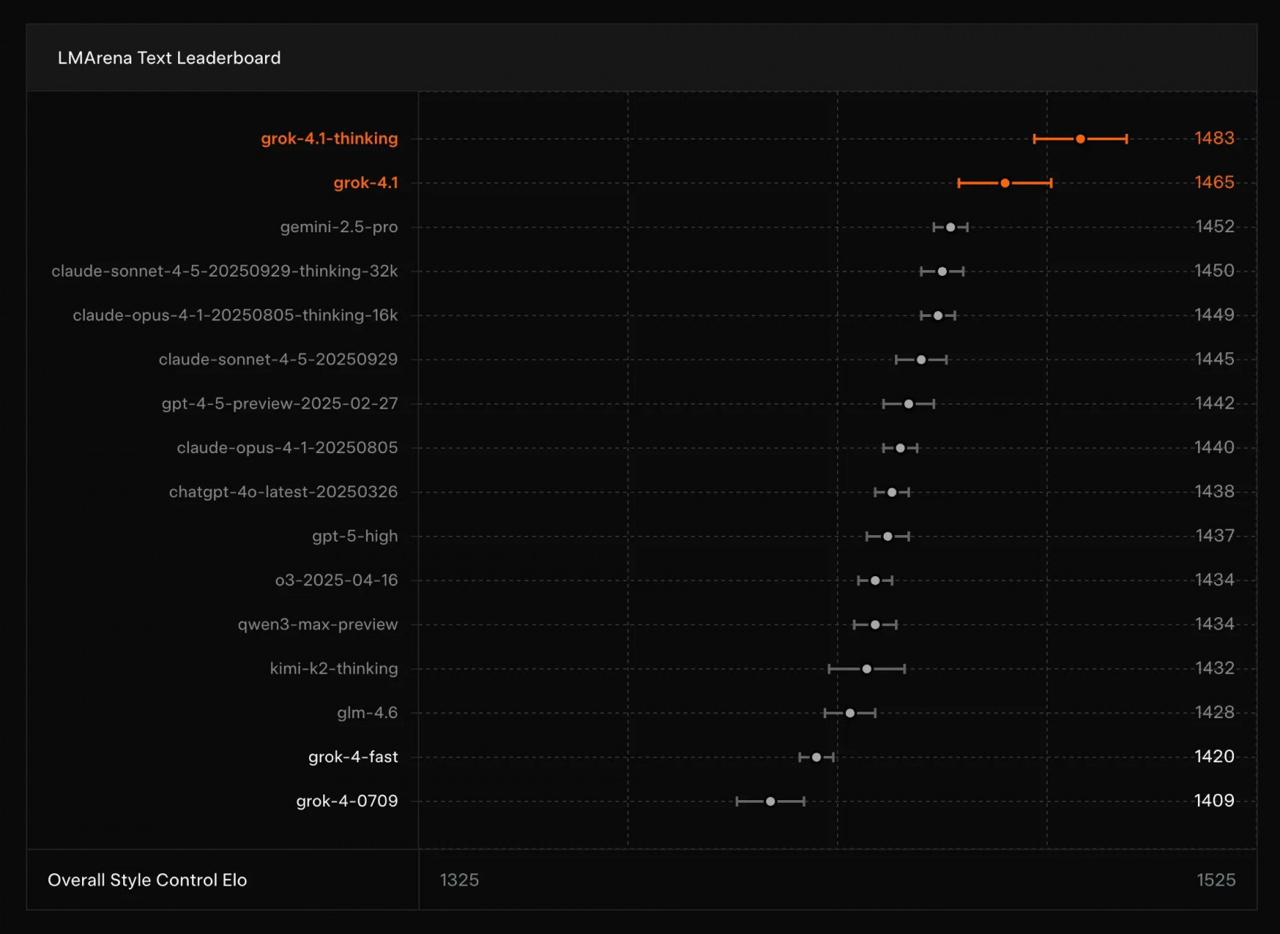
Каждый раз, когда выходит новая языковая модель, повторяется одно и то же. Постят график с гантелями, где модель якобы обходит конкурентов в бенчмарках. При этом все смотрят на график как на что-то само собой разумеющееся. Никто не спросит, как вообще эти гантели читать? Левый конец — то, что было раньше, правый — сейчас? Зачем точка посередине? Что это за бенчмарки такие? Чем один отличается от другого? Я понимаю, есть ребята, которые в теме, но если пишешь для всех, можно и объяснить.
Ну и примеры. Какое мне дело, что в бенчмарке X модель набрала на пять баллов больше? Где примеры того, в чем конкретно она улучшилась?
Каждый релиз LLM — это взрыв на фабрике гантелей. Армия чудаков растаскивает графики по соцсетям, делая вид, что понимает их.
-
Еще про API
Вдогонку про рестовые апишки. С первого дня, что я работаю с ними, меня бесит одна вещь, которую никто не замечает. Она состоит в следующем: данные размазаны по всему HTTP-запросу.
Часть параметров нужно взять из урла, например айдишки сущностей. Другие данные – из заголовков. Если это GET/HEAD, взять параметры query string. Если POST – читать multipart или парсить json. В итоге первые 5-10 строк кода уходят на то, чтобы выковырять данные из разных мест.
Всегда поражало: почему никто не видит проблемы? Почему не заслать все в джейсоне через POST? Ради чего размазывать поля по разным местам?
Я хочу, чтобы апишка была описана данными, например словариком с полем
actionиparams. Все в одном месте, и дальше этот словарик разруливается по полюaction. Под каждый словарик пишется схема и документашка. Что еще нужно?У этого подхода миллион преимуществ, вот хотя бы некоторые:
-
не нужно парсить урлы и query-параметры. Парсинг урлов, вычленение айдишек с приведением к числу – это сложно;
-
не нужно клеить урлы на клиенте. Это лютейшая боль: зачем вам
/api/v1/users/123/orders/456вместо{:user_id 123 :order_id 456}? -
сообщенька отделяется от транспорта; становится неважно, как ее передали: по HTTP или иначе.
-
следствие 1: легко добавить новый транспорт. Фронтенд захотел веб-сокеты – пожалуйста, это делается за день. Напомню, что в веб-сокете никаких урлов нет, только данные.
-
следствие 2: очереди. Тяжелые сообщения можно складывать в кафки-реббиты.
-
следствие 3: тесты и сценарии. Можно подготовить файл, где каждая строка – сообщенька. После чего сказать: выполни их по порядку. В результате система придет в нужное состояние.
-
пакетный режим: тот же JSON RPC позволяет заслать несколько сообщений за раз. Их можно обработать параллельно.
-
бывает, один обработчик должен вызвать другой. Ты же не будешь слать сам себе HTTP-запрос! Подготовил сообщеньку и скормил ее функции, которая их разруливает.
Замечу, что под сообщением я имею в виду не очереди задач, а нечто другое. Сообщение – это набор данных, которые описывают действие. Удобно, когда все это хранится рядом.
Я уж молчу о том, что в классическом REST вечно не хватает методов или они неочевидны. В одной фирме коллеги чуть не подрались, когда спорили, что использовать для изменения: PUT или PATCH. Самая жесть – это запросы, которые меняют сразу несколько сущностей. Там вся концепция ресурсов идет лесом.
Сообщения удобней для понимания. Что легче читается:
POST /api/v1/ordersилиCreateOrder? Другой пример:PATCH /api/v1/orders/123456/cancelилиCancelOrder? То-то же.Сообщения используются не только в вебе. Например, любое обращение к Postgres – это обмен сообщеньками. У них общий контейнер: метка, длина и произвольное тело, которое парсится в зависимости от метки. Как только написал парсер сообщений, считай, клиент почти готов.
В Кассандре, Кафке то же самое: заголовок/cooбщенька, заголовок/cooбщенька.
Поэтому я уверен: нужно думать над сообщениями, а транспорт всегда найдется. Это вторичная вещь. Жаль, этого не понимают REST-маньяки со своими сваггерами, постманами, бест-практис и так далее.
-
-
Европейский закон о зарплате
Пишут, что в 2026 году в Европе введут новые правила о зарплате. Вот неполный их список:
-
зарплата должна быть указана в любом объявлении о найме;
-
соискателя обязаны уведомить о зарплате еще до интервью и подписания договора;
-
разглашение зп не может быть поводом для увольнения или других воздействий;
-
сотрудникам можно запрашивать информацию о зарплатах других сотрудников;
-
компании штатом более 250 сотрудниками должны публиковать отчеты о зп в разрезе гендера.
Может быть и врут, я особо не проверял. Но откровенно говоря – очень похоже на правду.
Не мое дело – критиковать европейские законы; пусть принимают что хотят. Я бы сказал, что со своей колокольни не хотел бы таких законов. Я хочу, чтобы моя зарплата оставалась в тайне. Просто потому, что часто мне платили больше, чем остальным, и я не вижу ни одной причины, по которой коллеги должны об этом знать.
Точно также я никогда не интересовался чужими зарплатами. Мое убеждение железно: получает больше тот, кто умеет и знает больше. Стремись ко второму, и первое придет само собой.
Кстати, в этом коренная проблема Европы – тотальное регулирование. Именно поэтому Европа смотрит американский Нетфликс, ищет в американском Гугле, читает американский Твиттер, чатится в американском Вацапе, вызывает американский Убер и так далее.
Где хостится европейский стартап? В американских AWS, Google Cloud, Azure. Куда едут условные финн Торвальдс и голландец Ван Россум? Где зарегистрированы фонды Линкуса и Питона? В Америке.
Чтобы создать сервис, который захватит мир, нужно нарушить чьи-то права. В Америке обе стороны (фирма и работник) идут на это добровольно, и в результате американские сервисы повсюду. Европейские – нет.
В чем Европа достигла успеха, так это в том, что держит американские сервисы в узде. Для жителей Евросоюза действуют особые правила, их данные обрабатываются по-другому. Да, их нельзя перемещать между юрисдикциями и продавать американским партнерам. Но это победа чиновника, а не конечного потребителя.
В этом плане Россия похожа на Америку. Российский айтишник совершенно не против, чтобы его эксплуатировали – если за это платят и результат достойно смотрится в резюме. Даже сейчас, когда российский Яндекс продали олигархам, туда готовы идти за еду. В раннем Яндексе сотрудники буквально там жили. Поэтому в России есть поисковик, соцсети, такси, антивирус, маркетплейсы, карты, музыкальные и видеосервисы.
Закругляясь: я бы советовал поменьше трепаться о зарплате. Это личное и никого не касается. Я уверен, что так лучше для всех – в том числе тех, кто так хочет вашу зарплату узнать. Да будет им известно: лишние знания приумножают скорбь.
-
-
Полоса прокрутки (2)
Небольшое продолжение про Ютуб — и больше поднимать эту тему не буду.
Всякими махинациями я добился того, чтобы полоса была под видео, а не на нем. Для этого классу
ytp-chrome-bottomдобавляется свойствоbottom: -60pxили около того. Но проблема пришла откуда не ждали, и даже не одна.Дело в том, что тулбар появляется только когда наводишь курсор на плеер. Так вот: если тулбар вне плеера, то наведение мыши на него ничего не дает — он остается невидимым. Простыми словами, перестает работать.
Я такой думаю: наверное, на тулбар вешается класс
hiddenили похожий. Сейчас поменяю этот класс, чтобы он был всегда видим и победю систему. Оказалось, видимость определяется не классом, а средствами JavaScript.Тогда я сделал так: растянул плеер, чтобы он охватывал тублар даже после смещения. Это помогло: при наведении на тулбар он появляется. Однако теперь не работают кнопки. Ощущение, будто где-то есть невидимый div, который перехватывает клики. Из-за смещения тулбара они идут мимо него, и ничего не работает.
Ну и в целом сложность: штук двадцать вложенных дивов
yt-player→yt-main-container→yt-main-inner→yt-video-container→yt-video-nodeи так далее. Каждый что-то перехватывает и наследует. Дебажить этот цирк — то еще удовольствие.Так что переносом тулбара вверх я пока и ограничусь. Слишком напряжно этим заниматься. Сложность Ютубного плеера колоссальная: там годы легаси и костылей, чтобы работать во всех браузерах, трекать, показывать рекламу, плашки, рекомендации и так далее. Задача мне не по зубам, признаю поражение.
Writing on programming, education, books and negotiations.