-
Умиление дикарями
Цивилизованные люди умиляются дикарями: племенами Африки, жителями крайнего севера, американскими амишами и так далее. Считается, их нужно всячески оберегать от цивилизациии, хранить их язык, культуру и все такое.
Почему это так, понять не трудно. Еще несколько сотен лет назад белый человек завоевывал мир варварским способом, и в результате исчезли даже не особи (кто их считал), а виды – как животных, так и людей. Сегодня это умиление – своего рода плата за бесчинства в прошлом. Смотрите, теперь мы добрые.
Однако умиляясь дикарями, спросите себя: хочу ли я, чтобы мои дети жили как они. Чтобы девочкам делали женское обрезание и вынуждали рожать по пятнадцать раз. Чтобы дети не знали школы, книг, классической музыки, мультиков. Чтобы с ранних лет им долбили в голову мифы про богов с большой горы.
Хотели бы? То-то же. Поэтому умиление правильно назвать лицемерием. Если говоришь, что нравится, но не хочешь себе такого же, значит не нравится.
Умиляясь дикарями, помните, что когда-то они были детьми, у которых отняли право жить цивилизованно. В случае с Африкой, конечно, ребенку нелегко выбраться из саванны в город. Однако те же амиши живут в километре от моллов и городов. Помеха в данном случае одна – родители.
Амишам официально разрешено не иметь номера социального страхования. Их детям официально разрешено не посещать школу, если родители против. Разумеется, закон в последнюю очередь интересуется мнением ребенка. Родители не пустили в школу – ок, пусть сидит дома.
Я хочу, чтобы в мире не было амишей, цыган и других рудиментов общинно-первобытного строя. Не поймите неправильно: я не хочу, чтобы с ними случилось что-то плохое! Я лишь хочу, чтобы их дети пошли в школу, росли со сверстниками и вступили в брак с кем-то не из общины. Чтобы они читали книги, смотрели фильмы, ходили в бассейн и музыкальную школу. Чтобы потом то же самое случилось с их детьми. Престарелые члены общины тихо состарятся и умрут, а на месте поселения откроют музей. Смотрите, тут жили дикари, которые лечились чесноком, приносили в жертву баранов, пихали бамбук в половые органы и прочий кринж.
Поэтому к черту разнообразие культур и языков; традиций, как правильно креститься: двумя или тремя пальцами, слева направо или наоборот. Из-за подобных штучек поубивали слишком много людей, чтобы ими интересоваться. Образованный человек без скреп, культурных кодов и прочих наслоений – самый мирный представитель нашего вида.
Не забывайте о том, что дикари хороши только на картинке в атласе. В точности как пираты – это отдельная часть культуры, и каждый из нас играл в пиратов. И все же я не хочу, чтобы в мире были пираты.
Но если пираты требуют истребления, то с дикарями все проще. Всего лишь отдайте их детей в школу – и дикарей не станет.
-
Айтишные вузы
Иные студенты жалуются, что месяцами ищут работу в айти. В итоге идут в сантехники, официанты, продажи.
Рекрутеры жалуются, что месяцами не могут найти сеньорного разработчика.
В первом случае можно винить ИИ: свежий выпускник примерно ему и соответствует. С точки зрения фирмы, зачем его брать? Возьмем опытного, а где новичку набирать опыт — его дело.
Мне кажется, проблема вот в чем: выпускники не готовы к работе в айти. Даже после пяти лет обучения их нужно учить Гиту, рабочему процессу, минимальной рабочей этике. Фирма берет на себя то, что должен быть дать университет.
Появилось великое множество онлайн-школ; слово “айти-курсы” стало мемом, потому что влечет за собой контекст, одновременно смешной и грустный. И все равно на рынке кадров несоответствие спроса: много выпускников, мало опытных ребят.
Проблема в том, что многие преподы не понимают предмета, который преподают. Годами они дают студентам Паскаль или Си с классами, не понимая, что это бесконечно далеко от реальности.
Однажды я помогал студентке первого курса с Кложей. Ужаснулся: им велели писать парсеры без какого-либо введения в язык. Препод дал кошмарный код: запутанный, без единого комментария, с жирным макросом, который я понял не сразу. Никакой пользы от такого обучения нет — материал не усвоился, а их уже перекинули на Пролог.
Зачем так учить студентов?
А препод — писал ли он хоть раз код за деньги? Имеет ли представление о промышленной разработке? Знает ли, что такое код-ревью? Спорю на что угодно: большинство айти-преподов не пройдет собеседование на джуниора. Причина не в возрасте, а в отсталости от реалий: нужно знать Линукс, терминал, язык, тулинг к нему, тесты, фреймворки, хорошие практики и все остальное.
Бывают продвинутые преподы, которые одновременно с вузом работают в айти-компаниях. Я знаю двух, и вы тоже назовете несколько имен. Но они — исключения. Я хочу, чтобы по возможности каждый специалист вносил вклад в образование: вел лекции, писал книги, учил студентов.
Наверное, нам нужны частные айти-вузы на базе крупных компаний. Их преподаватели — сотрудники, которые, скажем, три дня в неделю работают, а два — преподают. Сами составляют программу, набирают студентов, учат, проводят экзамены. Совмещать сложно, но можно. Есть вариант с чередованием не по дням, а месяцам или даже годам. Устал от разработки— берешь год на преподавание за ту же зарплату в той же фирме.
Беда в том, что сфера образования зарегулирована по самые помидоры. Наши учителя и врачи — это самый подневольный слой общества. Учитель учит лишь в последнюю очередь, а так у него стек задач от министерства образования. Если он накосячит, дадут по голове директору, тот — завучу, а завуч съест учителя с потрохами.
В университетском образовании не сильно лучше. Когда работал в Датаарте 10 лет назад, некоторые сотрудники преподавали в воронежском ВГУ. Постоянно жаловались на бюрократию и бумажную работу, многие в итоге ушли. А ведь это были специалисты с реальным опытом работы! Не Си с классами за 98 год, а настоящая промышленная разработка! Большая потеря для студентов.
Возможно, такой вуз не будет иметь официальной силы, но будет востребован компаниями. Еще бы: если выпускник понимает азы настоящей, промышленной разработки, его надо брать — довести его сильно проще, чем знатока Паскаля или Пролога.
Я бы предложил жирным финтахам вроде тинькова-сбера подумать о создании частных вузов. Да, это сложно, долго, выгода не очевидна и ее трудно измерить. Но мне кажется, это верное направление. Обычные вузы не вывозят роль кузницы кадров. Нужен прецедент — частный айти-вуз с преподами, которые работают, а не пересказывают пыльный учебник.
И внезапно окажется — да, так можно было. Для крупной фирмы содержать свой вуз станет тем же самым, что постить сториз в соцсетях, то признаком современности.
Нужно всего лишь начать.
UPD: в комментариях в Телеграме накидали примеры подобных вузов. Не знал, спасибо!
-
Даты и файлы
Бывает, мы сохраняем файл в папку, а такой файл уже есть. Возникает диалог что делать, в котором чаще всего нас интересует переименование. Поскольку мы уже выбрали имя, то хотели бы оставить его как есть и добавить хвостик. Обычно программы дописывают в конец счетчик:
document,document (1),document (2)и так далее.Счетчик – это, конечно, лучше, чем ничего. Но еще лучше было бы дописывать в конец дату. С ней
document,document (1),document (2)становятсяdocument,document_20250807,document_20250808и так далее. Как быть, если замена происходит в рамках одного дня? Добавлять часы и минуты, например:document_20250808.doc document_202508081442.doc document_202508081446.doc document_202508081458.docУже слышу как вы пишете: дата изменения хранится в мете файла, зачем таскать ее в имени? Дело в том, что эта дата всегда теряется. Это же мета – поэтому файловый менеджер может ее скопировать, а может и нет. Если закинуть файл в какой-нибудь S3, всю мету вы потеряете.
Или скинул файл коллеге в каком-нибудь Teams, тот загнал его в Шарепоинт, а третий человек получил его в электронной почте. Уверены, что мета сохранится? Я бы очень удивился, если бы это было так.
Однажды я работал с женщиной, у которой был пунктик. Каждый файл на ее компе начинался с префикса
YYYYMMDD_. Она часто шарила экран, и я видел как при сохранении файлов она прописывала дату вручную. И таких файлов – сотни, если не тысячи. Скорее всего она знала про поиск файлов по датам, но с именем ей было удобней.Это на самом деле круто. Это убеждение, построение своего порядка. Классно, когда человек возвел это в привычку.
Короче, я бы не отказался, если бы в диалоге сохранения файла был выбор, какой паттерн использовать: счетчик или дату. Еще лучше, если это будет глобальная настройка системы. Но вряд ли это скоро случится.
-
Благотворительные фонды
Есть много благотворительных фондов, и считается хорошим тоном их поддерживать. Во всех банках можно настроить так, чтобы часть платежа уходила в тот или иной фонд. Можно оформить подписку, например 100 рублей ежемесячно в фонд поддержки котят. Человек, который добровольно подписался, считается сознательным и вообще он этакий мини-герой.
Я довольно скептичен к подобным фондам, и вот почему.
Фонд – это бюрократическая организация, у которой одна цель – обеспечить свое существование как можно дольше. Помощь бездомным и больным людям — это хорошо, но прежде всего деньги идут на поддержку фонда. Это зарплаты администрации и сотрудников, аренда офиса, коммуналка, компьютеры, машины, бензин и прочее. Только когда все это оплачено, можно потратить деньги на кого-то еще.
Растраты в благотворительных фондах настолько часты, что об этом нет смысла говорить. Отдавая свои деньги, нужно понимать, что в первую очередь вы оплачиваете ипотеку сотрудников или образование их детей. Может быть, только малая часть денег пойдет на кому-то на помощь.
Фонды зарегистрированы как некоммерческие организации. Это всегда вызывает у меня усмешку. Любой фонд – это именно коммерческая организация, потому что она работает с деньгами и заинтересована в том, чтобы их было больше. Фонды буквально кричат – ДАЙТЕ ДЕНЕГ!!! Больше денег означает больше возможностей и выше зарплаты. Просто есть такая лазейка: регистрируешь некоммерческую фирму и платишь меньше налогов.
Вы еще скажете, что фонд Гейтсов, пропускающий через себя миллионы долларов – некоммерческий? Во-первых, самый что ни на есть коммерческий, а во-вторых, подобные фонды — инструменты международного влияния. Это было хорошо видно во времена ковидной истерии и тандема “ВОЗ – фонды”.
Я считаю, помощь должна быть короткой и точечной – такой, чтобы она не стала бесконечным процессом. А ведь именно это происходит с фондами. Они не заинтересованы в том, чтобы тех, кому нужна помощь, стало меньше. Это влечет банальное закрытие фонда. Поэтому он помогает, но так, чтобы растянуть удовольствие.
Нужно бороться не с явлением, а причиной – например, почему люди оказываются без дома; почему дети становятся сиротами; или отчего появляются бездомные собаки. Присмотревшись, мы увидим, что фонд либо сознательно не работает в этом направлении, либо у него нет полномочий.
Когда некий благотворитель летит в горячую точку спасать детей, нужно понимать следующее. Дети для него – это продукт. Человек питается продуктами войны. Я бы хотел, чтобы этих детей не пришлось спасать в принципе, а не чтобы их спасли. Хотел бы, чтобы этот благотворитель остался без работы и пошел в учителя, если ему так нравятся дети. Но не жил их спасением.
Если заговорил про детей, то вспомнилась одна вещь. В каком-то либеральном издании, которое уже сто раз заблокировали, одна женщина писала о жизни ребенка в детских домах. И выделяла капсом: НЕ ДАРИТЕ ИМ НИЧЕГО И НЕ УСТРАИВАЙТЕ ЕЛКИ. Потому что весь декабрь ребенок проводит на елках, иной раз по две в день. Фондам нужно отчитаться о работе, и они устраивают тур по детским домам. Вы бы хотели по две елки в день в течении двух недель?
То же самое с подарками: современным детям дарят телефоны и планшеты, которые либо присваивают сотрудники, либо их скупают перекупщики за четверть цены. Старшим детям нужны деньги, а не подарки, а живых денег им не дают, отсюда этот порочный круг.
Взять ребенка из детского дома – это вершина благотворительности. Это лучше, чем занести миллион долларов в фонд. Человек, который взял и вырастил ребенка, сделал свою жизнь сплошной благотворительностью. Сравните его с тем, кто оформил подписку в фонд. Масштаб такой, что плюнуть и растереть.
Одно время у нас не получалось с третьим ребенком, мы обследовались и изучали тему усыновления или удочерения. Но потом все получилось, тема с адаптацией ушла, а на четвертого, извините, нет сил. Так что я не сделал то, за что топлю абзацем выше.
Но — делайте благотворительность сами, не доверяйте ее фондам. Платите за все из своего кармана. Я, например, отдал в школу несколько системников и мониторов, хотя мог бы продать их на Авито. Потом купил и установил в школе велопарковки, потому что ученики прятали велики по кустам. Теперь даже на парковке не хватает места.
В садовом кооперативе была плохая дорога. В первый раз я отремонтировал ее за 300 тысяч – это был асфальтовый срез с битумной эмульсией. Через пять лет она пришла в негодность. Тогда я сделал настоящий асфальт за два миллиона – полностью за свой счет, перевел бригаде как физлицо.
Приходилось оплачивать за свой счет и другие, менее масштабные вещи в пользу третьих лиц — я имею в виду не родственников и даже не друзей. В целом мой благотворительный фонд составил примерно три миллиона — думаю, это больше, чем в среднем по больнице.
Вы же айтишники, вы много получаете. Купили айфон, машину, квартиру, еще одну квартиру ребенку, а дальше что? Вариант, о котором часто не подозревают — улучшать пространство вокруг себя.
На мой взгляд, чем сознательней человек, тем лучше он понимает: не стоит доверять благотворительность третьим лицам. Это лучше, чем ничего, не спорю. Возможно, ваши триста рублей, которые капают фонду раз в месяц, и вправду спасут чью-то жизнь. Но в идеале благотворительность нужно творить самому.
-
Объяснение
Расскажу, почему опубликовал предыдущий пост. Разумеется, это копипаста ИИ, на которую наткнулся почти случайно. Я хотел открыть свой пост, названный “Ненависть к SQL”, и вбил в браузер заголовок, думая, что меня перекинет в блог. Вместо этого сработал поиск в Гугле, и открылась выпадашка с Gemini (или как там называется модель Гугла). Там была вся эта графомания. Мне показалась она смешной, и я разместил ее у себя на память. А чем конкретно она меня рассмешила – тому долгое объяснение.
Дело в том, что я люблю шутить на острые темы. Про бога, веганов, секс-меньшинств, выгоревших айтишников, феминизм, абьюз… всего не перечислить. Однако, во-первых, я шучу только в узком кругу лиц, где все свои и понимают. Во-вторых, я смеюсь только над типажом или явлением, но никогда – над конкретным человеком. Если необходим человек, выставляю себя в его роли.
Например, жена просит почистить картошку. Я чищу две, падаю со стула, сворачиваюсь на полу и плачу, что выгорел, что не могу больше терпеть картофельное рабство. Жена легонько пинает меня и говорит, что я просто зажравшийся айтишник. Я говорю, что она газлайтерша, которая блюрит мое восприятие несправедливости и руинит мое эго. Могу выдать комбо из десяти слов-новоязов, которые подцепил из западной повестки. Иногда это звучит так смешно, что от смеха болит лицо. В первые годы жене многое было непонятно, и мы записывали слова на доске с переводом. Даже устраивали экзамены.
Другой способ подурачиться – говорить максимально общими фразами вроде “не совершай ошибок”, “будь заряжен на успех”, “будь продуктивен” и так далее. Я называю этот режим “мистер Пустые Фразы”. Он популярен сегодня благодаря копирайтерам всех мастей и нейросетям, которые у них учатся.
Иногда жена смеется, когда я с ней так разговариваю, иногда лупит тряпкой (хотя потом все равно смеется). Разумеется, я всегда понимаю, когда можно нести бред, а когда быть нормальным.
Так вот – текст выше напомнил меня самого, когда я включаю бредогенератор и несу чушь. Сами посмотрите: человек ненавидит SQL, и очевидно у него проблемы с пониманием, причем на идейном уровне. Нейронка советует выучить операторы SELECT и UPDATE, а еще обратиться за помощью к онлайн-сообществам. Это настолько тупо, плоско, банально, что хочется надавать ей тряпкой по лицу. С таким же успехом можно посоветовать не совершать ошибок и быть внимательным. Только с точки зрения Гугла это всерьез.
Текстов, которые дают очевидные советы вроде “изучи и спроси в сообществе”, в интернете навалом, и они не работают. Гугл выдал еще один, и что хуже, возможны тысячи их вариаций, и все они производятся в полете. Каждый раз, когда гуглишь, получаешь портянку текста с набором банальностей. В таком тексте нет глубины, он ничему не учит. А ведь есть те, кто принимает указания ИИ за чистую монету.
Словом, пока что указания ИИ на тему как жить и учиться напоминают мой личный бредогенератор. Отличие одно – хочется грустить, а не смеятся.
-
Причины ненависти к SQL
Ненависть к SQL, или, скорее, сложности и разочарования, связанные с его изучением и использованием, часто возникают из-за специфики языка и подхода к работе с базами данных. SQL, как язык запросов, имеет свой синтаксис и логику, которые могут отличаться от привычных парадигм программирования. Некоторые разработчики, привыкшие к более высокоуровневым языкам, могут испытывать трудности в понимании и применении SQL для решения своих задач. Кроме того, ошибки в SQL-запросах могут приводить к неожиданным результатам или даже к сбоям в работе базы данных, что также может вызывать негативные эмоции.
Вот несколько причин, почему SQL может вызывать негативные эмоции:
Непривычный синтаксис и логика:
SQL имеет свой собственный синтаксис, отличный от многих других языков программирования. Это может потребовать времени и усилий для привыкания и освоения.
Работа с большими объемами данных:
SQL часто используется для работы с большими объемами данных в базах данных, что может усложнять отладку и оптимизацию запросов.
Сложности в понимании планов запросов:
Оптимизатор запросов в СУБД (Системе Управления Базами Данных) может принимать решения, которые не всегда очевидны для разработчика, что может приводить к неожиданным результатам.
Необходимость учитывать особенности конкретной СУБД:
Разные СУБД (например, MySQL, PostgreSQL, Oracle) могут иметь свои особенности реализации SQL, что требует дополнительного изучения и адаптации к конкретной платформе.
Высокая ответственность:
Ошибки в SQL-запросах могут приводить к серьезным последствиям, таким как потеря данных или сбои в работе приложения, что может вызывать стресс и тревогу.
Как преодолеть негативное отношение к SQL:
Начать с основ:
Изучите базовые понятия SQL, такие как операторы SELECT, FROM, WHERE, JOIN, и постепенно переходите к более сложным темам.
Практиковаться на реальных задачах:
Решайте практические задачи, связанные с работой с базами данных, чтобы закрепить полученные знания.
Использовать инструменты для отладки и оптимизации:
Ознакомьтесь с инструментами, которые помогают анализировать планы запросов и находить узкие места в работе базы данных.
Обращаться за помощью:
Не стесняйтесь обращаться за помощью к коллегам или в онлайн-сообщества, если у вас возникают трудности.
Помнить о цели:
Понимание того, для чего нужен SQL и как он помогает в решении реальных задач, может мотивировать к изучению и преодолению трудностей.
SQL, как и любой другой язык программирования, требует времени и терпения для освоения. Понимание его сильных сторон и потенциальных сложностей, а также применение правильных стратегий обучения и работы, помогут преодолеть негативное отношение и успешно использовать его для решения задач.
В ответах искусственного интеллекта могут быть ошибки. Подробнее…
-
О перенаселении
Что это я все про айти да айти… так и помереть можно. Вот задача, которую я прочел в советском журнале: сколько территории понадобится, чтобы разместить всех людей мира? Наверное, континент размером с Австралию? Оказывается, гораздо меньше.
Предположим, людей у нас 8 миллиардов. Их может быть и 9 миллиардов – мы увидим, что даже такой разброс ни на что не влияет.
Если поставить каждого человека на квадратный метр, понадобится 8 миллиардов квадратных метров. Это много. Однако вспомним, что в одном квадратном километре – миллион квадратных метров (потому что 1000 х 1000). Делим 8 миллиардов на миллион, получаем 8 тысяч квадратных километров.
Открываем список стран по возрастанию территории. Ближайшим кандидатом оказывается Кипр, чья площадь – 9 тысяч квадратных километров с копейками. Отсюда вывод: все люди мира свободно поместятся на Кипре. Все – включая китайцев, индийцев, американцев, европейцев, Великую Прекрасную Россию (с) и остальных без исключения. При этом между ними будет свободное место. Если утрамбовать, эта биомасса займет около трети острова.
Прикладываю скриншоты гугловых сервисов, чтобы вы оценили масштаб: что есть Кипр и что есть земной шар.
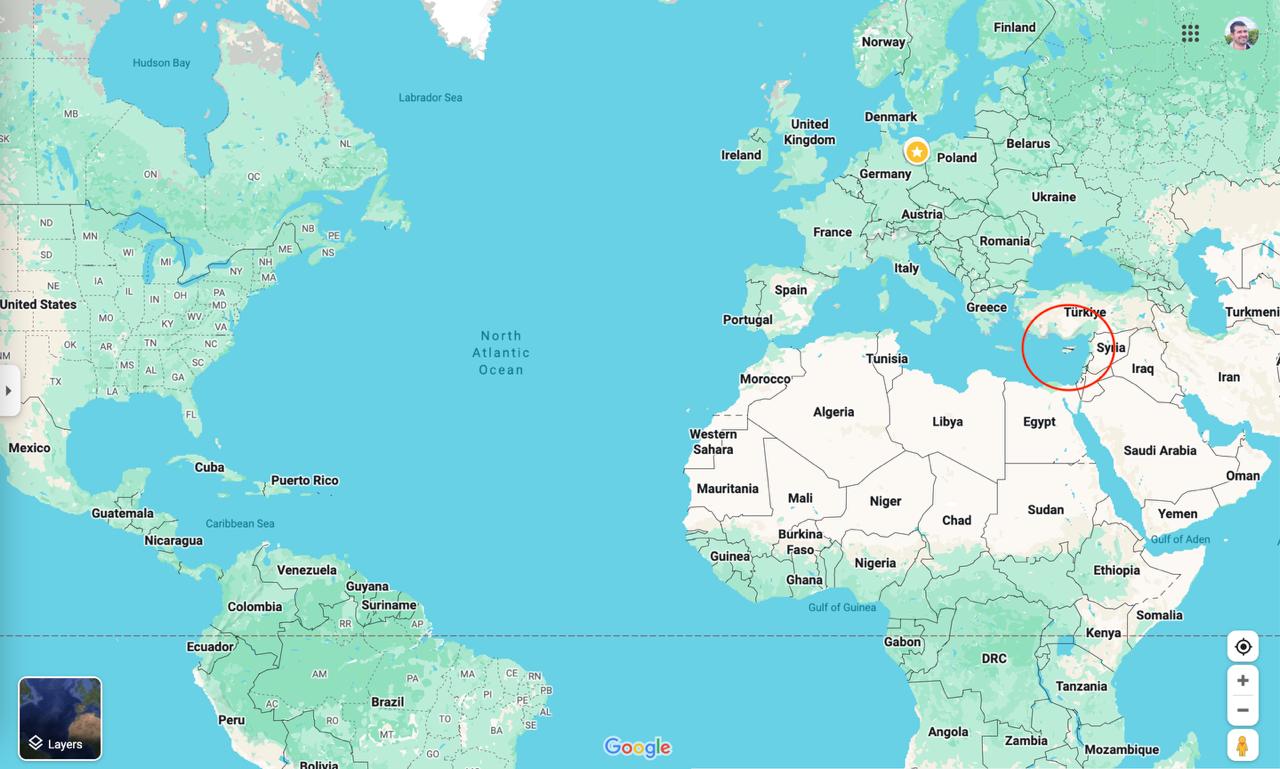
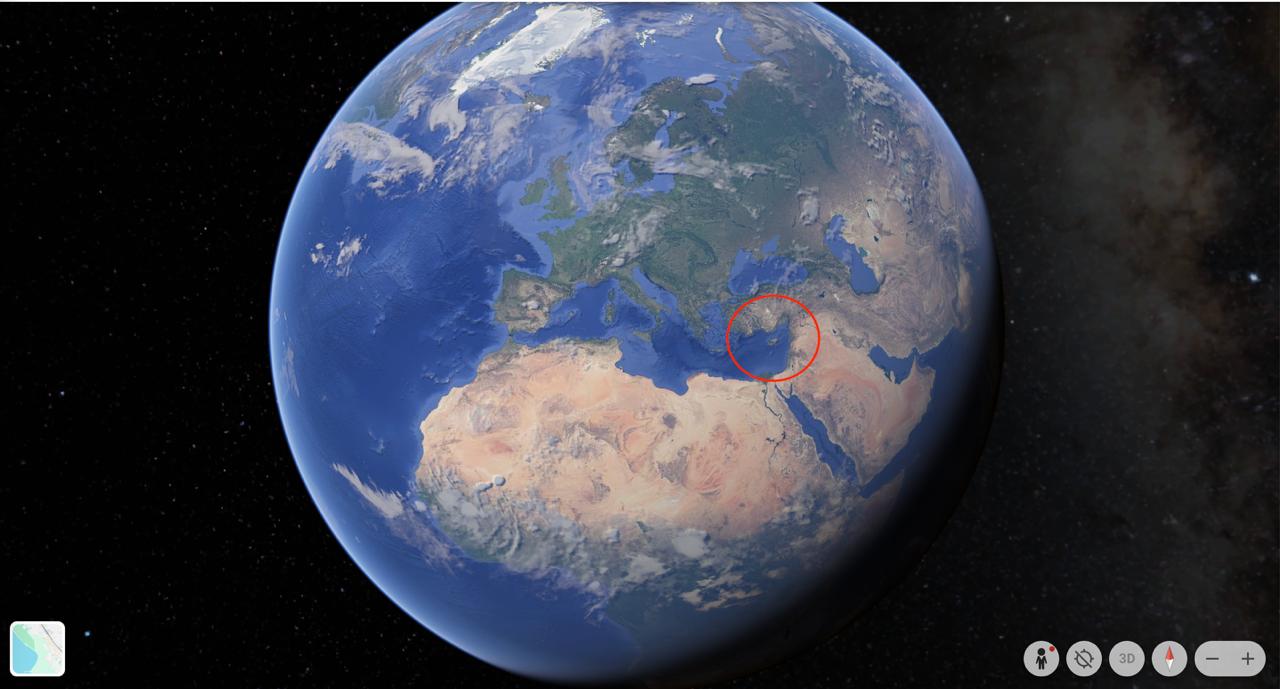
Это присказка, а выводы вот какие.
Когда говорящая голова кричит, что планета перенаселена, неплохо вспомнить: все население помещается на клочке суши, который не виден, стоит едва отзумить. Как-то не похоже не перенаселение. От этого страдают штучные участки планеты, но никак не вся. Проблемы перенаселения нет, она выдумана эко-террористами.
Далее, вы когда-нибудь ездили по России за Уралом? Я имею в виду Сибирь и Забайкалье. Я там родился и ездил. Так вот, Россия до Урала и после – это две разные России. После Урала она пустая. Поезд идет сквозь сибирскую тайгу, и раз в час встречается даже не деревня, а хутор – два дома и сарай, вот и вся цивилизация. Расстояние между городами занимает часы. Как-то раз был сосед поляк, который на хорошем русском удивлялся: я за четыре часа проезжаю свою страну, при этом не бывает безлюдного места. В России за это время я лишь приезжаю в другой город. Да, все так.
Если увеличить атом до размера Большого театра, его ядро будет с булавочную иголку, а электронов мы все еще не увидим. Атом внутри – пустой. Так и наша планета: отдельные мегаполисы очень плотные подобно ядру, но вообще планета пустая.
Поэтому когда говорят про Марс или глубины океана, я скептичен. На Земле полно пустого места! Вся Россия после Урала; Африка и пустыня Сахара, облагородить которую экономически дешевле, чем лететь на Марс; вся Канада – на севере там только мелкие города и деревни.
Другими словами, господа переселенцы – какие проблемы вы собираетесь решить? Где гарантия, что через 300 лет на Марсе не начнутся конфликты а-ля “сектор Газа”, полуостровов, которые были ваши, а стали наши, и различных специальных операций. Откуда уверенность, что там все заживут в мире и согласии?
Сюда же относятся арабы, которые строят города в пустыне. За этим нет ничего, кроме зарывания денег в песок в буквальном смысле. Сколько было рендеров и утопических рассказов – но пока что в таких городах остаются жить сами строители, плюс подтягивается сброд из пустыни: кочевники, беженцы. Город-призрак какое-то время живет, затем его съедает пустыня, а люди уходят.
Поэтому я могу лишь хрюкнуть, когда вижу рендеры города Line. Спрашивается, где взять богатых людей, которые поедут жить в золотой клетке посреди пустыни? Мой сын много играл в Майнкрафт, и там принцип такой: если построить домики, в них, подобно мышам, заводятся крестьяне. Если покормить их хлебом и оставить одних, появится маленький крестьянчик. Похоже, у арабов такие же представления о живых людях.
Если коротко, то проблема перенаселения откладывается. Много лет ей угрожали различные эко-активисты, но не срослось. Ищите новую угрозу, этой уже веры нет.
-
Уязвимое ПО
Специалист по безопасности: Иван, у тебя установлено уязвимое ПО. Немедленно обновись! Я: можно точнее? У меня установлено много программ. Специалист: минуточку, формирую отчет… ага, это GNU Emacs версии 29. Срочно обновись до версии 30.1!
Конечно, я оперативно обновил GNU Emacs и теперь смеюсь в кулачок над теми, кто до сих пор в опасности.
Если серьезно, то в Емаксе 29 и правда есть уязвимость, связанная с org-файлами. Если открыть документ ниже, файл ~/hacked.txt будет создан автоматом. Проверил – работает:
#+LINK: shell %(shell-command-to-string) [[shell:touch ~/hacked.txt]]Одно время я баловался с орг-файлами, но перестал. На мой взгляд, шутка “офисный пакет в Емаксе” зашла слишком далеко.
-
Код картинкой
Иные ребята постят код картинкой с помощью какого-то сервиса. Прикладываю образец.
Мне непонятно следующее: во-первых, зачем два сантиметра отступа по краям? Это, типа, тень? Зачем она?
Второе — зачем яблочные кнопки в левом верхнем углу? Кто-то будет их нажимать? Так-то это еще один лишний сантиметр по высоте. Если у человека винда, будете генерить для него виндовые кнопки?
Словом, типичный современный дизайн. Бесполезные тени, отступы и слои.
В самом размещении кода картинкой ничего зазорного нет. Сегодня нет гарантии, что код не будет переколбашен алгоритмами, сокращалками, подсветкой, пряталками под кат, типографами и так далее.
И еще — код с картинки превосходно читается в маковской проге для просмотра картинок. Так что в крайнем случае его легко восстановить.
-
Теги в био
Когда пишете о себе в профиле, следуйте правилу: на первом месте идет то, чем вы зарабатываете. Все остальное — музыка, танцы, увлечения детства — должны быть указаны как хобби, даже если вы очень в этом хороши.
Например: программист, увлекаюсь математикой и живописью. Текст нормального человека. Понятно, чем он зарабатывает и на какие темы с ним можно поговорить.
А если так: математик, ученый, программист, музыкант, ментор, знаток лошадей? Мысленно я добавляю: а еще клоун с непомерным ЧСВ. Кто ж ты, наконец?
Во втором примере человек ведет себя как таксист: он владелец газет-параходов, а такси у него для души. Ну-ну.
Разумеется, деньги приносит только что-то одно. Если ты программист, зачем писать, что ты музыкант и математик до кучи? Так-то много кто закончил музыкалку или лабал обдолбанным на гитаре. Но это не приносит денег, поэтому — хобби.
Или человек на серьезных щщах пишет: как физик я утверждаю, что… При этом у него действительно образование физика, олимпиады и все такое. Одна беда — человек зарабатывает сайтами на PHP. Какой ты к черту физик! Ты веб-разработчик.
Я лично тоже программист, линейный кодер. Это приносит мне деньги последние 18 лет или около. Я закончил музыкальную школу по классу скрипки, могу сыграть “Аве Мария” на фортепиано, неплохо пел в хоре — не солировал, но был на хорошем счету. При этом я не музыкант.
В 7 лет я играл во взрослом спектакле “Господин де Пурсоньяк”, это комедия Мольера. Мне даже платили зарплату. Но я не актер.
Я регулярно писал городские олимпиады по математике, а в старших классах выиграл областную. При поступлении в универ математику засчитали автоматом. Но я не математик.
Я работал на телевидении, знаю основы видеомонтажа, могу смонтировать несложный фильм. Могу сделать анимашку в After Effects. Но я не режиссер и не моушен-дизайнер.
Я работал в типографии, обслуживал машину Heidelberg (см. картинку). Могу сверстать книгу или журнал любой сложности и довести их до станка. Знаю основы полиграфии: цветоделение, спуск полос, сложный черный, overprint, ink depth, preflight и многое другое. Но я не полиграфист.
Еще я написал две книги и пишу третью, так что могу называться автором. Но я живу не за счет книг, поэтому я не автор.
Все это осталось в прошлом и порой пригождается, но вообще я программист. Так что не надо врать: ни себе, ни другим.
Обращаюсь к ребятам, у которых в bio десяток тегов — давайте скромнее. Простой принцип: на что живешь, то идет первым. А потом — игра на басу, математика, лошади, толкинизм и остальные развлечения.

Writing on programming, education, books and negotiations.