-
Ответ с эмодзи
Важная новость: в Microsoft Outlook появились реакции к емейлам. Работает так: вы написали письмо, отправили, а под ним появляются пальчики, сердечки и прочее. Пошарить скриншот не могу, поверьте на слово.
Интересно, как это работает? Особая апишка в протоколе Outlook? Или пустое письмо с заголовком? Или какой-то особый пейлоад? Или если в письме только эмодзи, оно показывается по-другому?
В любом случае, шлю лучи добра пользователям Аутлука.
-
Корпоративные обновления
Когда работаешь на корпоративном ноуте, постигаешь всю беспощадность обновлений. Ничего нельзя отключить, в фоне работают программы, которые следят за обновлениями. Раз в несколько дней обновится то Хром, то Idea, и начинаются выпадашки: Иван, чтобы защитить себя от угроз, поставь обновление! Откладывать можно фиксированное число раз, и в какой-то момент обновление ставится силой — конечно, перед релизом или звонком. Поэтому со временем я стал накатывать обновления на выходных.
Так вот, в который раз попадаюсь на дурацкое поведение Эпла. Вылазит выпадашка: обновись до Секвойи, тянуть больше нельзя. И кнопочка “Install update”. Я закрываю все программы, все реплы, докеры и остаюсь с выпадашкой наедине. Жму кнопку и вижу: отлично, загружаю обновление, осталось 3 часа. Три часа, Карл! Я мог бы ничего не закрывать и работать чуть ли не полдня, пока качается обновление!
Нажимая “Install update”, я рассчитываю, что оно уже загружено и я в шаге от того, чтобы начать установку. А загрузка даже не начиналась! И качать там не три мегабайта, а 5-7 гигов.
Спрашивается, что мешало скачать обновление в фоне? Если от него нельзя отделаться, так скачай сам, зачем парить мне мозги?
Дизайнер тоже хорош: если кнопка запускает загрузку обновления, ее нужно назвать “Download & Install update”. Я ведь хочу самую малость: чтобы на кнопке было написано то, что она делает на самом деле.
Сюда же относится виджет обновления Эппловских программ. Вылазит окошко поверх всего, и там кнопка “Обновить”. Нажимаешь, оно начинает загрузку, а потом сто раз перехватывает форус. Почему нельзя скачать в фоне? Почему нельзя поставить его в фоне? Зачем тыкать в лицо модалки?
Та же самое с Саблаймом. Поработав минут 20, он начинает показывать модалку с прогрессбаром: загружаю обновление. Тупица, что мешает скачать обновление в фоне? Зачем ты показываешь прогресс-бар? Чтобы пользователь смотрел на него? Других дел у пользователя нет?
В общем, сегодня каждая программа обновляется как не в себя, только нормальные обновления так и не сделали. На ум приходит только одно исключение — Хром, который обновляется полностью незаметно. Все остальное — обычные модалки с прогрес-баром.
-
Taggie
Taggie is an experimental library trying find an answer for a strange question: is it possible to benefit from Clojure tags and readers, and how?
Taggie extends printing methods such that types that could not be read from their representation now can be read. A quick example: if you print an atom, you’ll get a weird string:
(atom 42) #<Atom@7fea5978: 42>Run that string, and REPL won’t understand you:
#<Atom@7fea5978: 42> Syntax error reading source at (REPL:962:5). Unreadable formBut with Taggie, it goes this way:
(atom 42) #atom 42 ;; represented with a tagAnd vice versa:
#atom 42 ;; run it in repl #atom 42 ;; the resultThe value is an atom indeed, you can check it:
(deref #atom 42) 42Tags can be nested. Let’s try some madness:
(def omg #atom #atom #atom #atom #atom #atom 42) (println omg) #atom #atom #atom #atom #atom #atom 42 @@@@@@omg 42But this is not only about atoms! Taggie extends many types, e.g. refs, native Java arrays,
File,URI,URL,Date,java.time.*classes, and something else. See the corresponding section below.Installation and Usage
Add this to your project:
;; lein [com.github.igrishaev/taggie "0.1.0"] ;; deps com.github.igrishaev/taggie {:mvn/version "0.1.0"}Then import the core namespace:
(ns com.acme.server (:require taggie.core))Now type in the repl any of these:
#LocalDate "2025-01-01" #Instant "2025-01-01T23:59:59Z" #File "/path/to/a/file.txt" #URL "https://clojure.org" #bytes [0x00 0xff] #ints [1 2 3] #floats [1 2 3] #ByteBuffer [0 1 2 3 4] ...Each expression gives an instance of a corresponding type: a
LocalDate, anInstane, aFile, etc…#bytes,#intsand similar produce native Java arrays.You can pass tagged values into functions as usual:
(deref #atom 42) 42 (alength #longs [1 2 3]) 3To observe what happends under the hood, prepend your expression with a backtick:
`(alength #longs [1 2 3]) (clojure.core/alength (taggie.readers/__reader-longs-edn [1 2 3]))Internally, all tags expand into an invocation of an EDN reader. Namely,
#longs itemsbecomes(taggie.readers/__reader-longs-edn items), and when evaluated, it returs a native array of longs.EDN Support
Taggie provides functions to read and write EDN with tags. They live in the
taggie.ednnamespace. Use it as follows:(def edn-dump (taggie.edn/write-string #atom {:test 1 :values #longs [1 2 3] :created-at #LocalDate "2025-01-01"})) (println edn-dump) ;; #atom {:test 1, ;; :values #longs [1, 2, 3], ;; :created-at #LocalDate "2025-01-01"}It produces a string with custom tags and data being pretty printed. Let’s read it back:
(taggie.edn/read-string edn-dump) #atom {:test 1, :values #longs [1, 2, 3], :created-at #LocalDate "2025-01-01"}The
writefunction writes EDN into a destination which might be a file path, a file, an output stream, a writer, etc:(taggie.edn/write (clojure.java.io/file "data.edn") {:test (atom (ref (atom :secret)))})The
readfunction reads EDN from any kind of source: a file path, a file, in input stream, a reader, etc. Internally, a source is transformed into thePushbackReaderinstance:(taggie.edn/read (clojure.java.io/file "data.edn")) {:test #atom #ref #atom :secret}Both
readandread-stringaccept standardclojure.edn/readoptions, e.g.:readers,:eof, etc. The:readersmap gets merged with a global map of custom tags.Motivation
Aside from jokes, this library might save your day. I often see people dump data into .edn files, and the data has atoms, regular expressions, exceptions, and other unreadable types:
(spit "data.edn" (with-out-str (clojure.pprint/pprint {:regex #"foobar" :atom (atom 42) :error (ex-info "boom" {:test 1})}))) (println (slurp "data.edn")) {:regex #"foobar", :atom #<Atom@4f7aa8aa: 42>, :error #error { :cause "boom" :data {:test 1} :via [{:type clojure.lang.ExceptionInfo :message "boom" :data {:test 1} :at [user$eval43373$fn__43374 invoke "form-init6283045849674730121.clj" 2248]}] :trace [[user$eval43373$fn__43374 invoke "form-init6283045849674730121.clj" 2248] [user$eval43373 invokeStatic "form-init6283045849674730121.clj" 2244] ;; truncated [clojure.lang.AFn run "AFn.java" 22] [java.lang.Thread run "Thread.java" 833]]}}This dump cannot be read back due to:
- unknown
#"foobar"tag (EDN doesn’t support regex); - broken
#<Atom@4f7aa8aa: 42>expression; - unknown
#errortag.
But with Taggie, the same data produces tagged fields that can be read back.
Supported Types
In alphabetic order:
Type Example java.nio.ByteBuffer#ByteBuffer [0 1 2]java.util.Date#Date "2025-01-06T14:03:23.819Z"java.time.Duration#Duration "PT72H"java.io.File#File "/path/to/file.txt"java.time.Instant#Instant "2025-01-06T14:03:23.819994Z"java.time.LocalDate#LocalDate "2034-01-30"java.time.LocalDateTime#LocalDateTime "2025-01-08T11:08:13.232516"java.time.LocalTime#LocalTime "20:30:56.928424"java.time.MonthDay#MonthDay "--02-07"java.time.OffsetDateTime#OffsetDateTime "2025-02-07T20:31:22.513785+04:00"java.time.OffsetTime#OffsetTime "20:31:39.516036+03:00"java.time.Period#Period "P1Y2M3D"java.net.URI#URI "foobar://test.com/path?foo=1"java.net.URL#URL "https://clojure.org"java.time.Year#Year "2025"java.time.YearMonth#YearMonth "2025-02"java.time.ZoneId#ZoneId "Europe/Paris"java.time.ZoneOffset#ZoneOffset "-08:00"java.time.ZonedDateTime#ZonedDateTime "2025-02-07T20:32:33.309294+01:00[Europe/Paris]"clojure.lang.Atom#atom {:inner 'state}boolean[]#booleans [true false]byte[]#bytes [1 2 3]char[]#chars [\a \b \c]double[]#doubles [1.1 2.2 3.3]Throwable->map#error <result of Throwable->map>(see below)float[]#floats [1.1 2.2 3.3]int[]#ints [1 2 3]long[]#longs [1 2 3]Object[]#objects ["test" :foo 42 #atom false]clojure.lang.Ref#ref {:test true}java.util.regex.Pattern#regex "vesion: \d+"java.sql.Timestamp#sql/Timestamp "2025-01-06T14:03:23.819Z"The
#errortag is a bit special: it returns a value with no parsing. It prevents an error when reading the result of printing of an exception:(println (ex-info "boom" {:test 123})) #error { :cause boom :data {:test 123} :via [{:type clojure.lang.ExceptionInfo :message boom :data {:test 123} :at [taggie.edn$eval9263 invokeStatic form-init2367470449524935680.clj 97]}] :trace [[taggie.edn$eval9263 invokeStatic form-init2367470449524935680.clj 97] [taggie.edn$eval9263 invoke form-init2367470449524935680.clj 97] ;; truncated [java.lang.Thread run Thread.java 833]]}When reading such data from EDN with Taggie, you’ll get a regular map.
Adding Your Types
Imagine you have a custom type and you want Taggie to hande it:
(deftype SomeType [a b c]) (def some-type (new SomeType (atom :test) (LocalDate/parse "2023-01-03") (long-array [1 2 3])))To override the way it gets printed, run the
defprintmacro:(taggie.print/defprint SomeType ^SomeType some-type writer (let [a (.-a some-type) b (.-b some-type) c (.-c some-type)] (.write writer "#SomeType ") (print-method [a b c] writer)))The first argument is a symbol bound to a class. The second is a symbol bound to the instance of this class (in some cases you’ll need a type hint). The third symbol is bound to the
Writerinstance. Inside the macro, you.writecertain values into the writer. Avobe, we write the leading"#SomeType "string, and a vector of fieldsa,bandc. Callingprint-methodguarantees that all nested data will be written with their custom tags.Now if you print
some-typeor dump it into EDN, you’ll get:#SomeType [#atom :test #LocalDate "2023-01-03" #longs [1 2 3]]The opposite step: define readers for
SomeTypeclass:(taggie.readers/defreader SomeType [vect] (let [[a b c] vect] (new SomeType a b c)))It’s quite simple: the vector of fields is already parsed, so you only need to split it and pass fields into the constructor.
The
defreadermutates a global map of EDN readers. When you read an EDN string, theSomeTypewill be held. But it won’t work in REPL: for example, running#SomeType [...]in REPL will throw an error. The thing is, REPL readers cannot be overriden in runtime.But you can declare your own readers: in
srcdirectory, create a file calleddata_readers.cljwith a map:{SomeType some.namespace/__reader-SomeType-clj}Restart the REPL, and now the tag will be available.
As you might have guessed, the
defreadermacro creates two functions:__reader-<tag>-cljfor a REPL reader;__reader-<tag>-ednfor an EDN reader.
Each
-cljreader relies on a corresponding-ednreader internally.Emacs & Cider caveat: I noticed that
M-x cider-ns-refreshcommand ruins loading REPL tags. After this command being run, any attempt to execute something like#LocalDate "..."ends up with an error saying “unbound function”. Thus, if you use Emacs and Cider, avoid this command. - unknown
-
Просто берите Postgres
Несколько месяцев назад завирусилась статья Just Use Postgres. Она была на всех площадках, а том числе в переводе на русский. Я чуть было не репостнул ее, но передумал. На проверку статья оказалось поверхностной: скажем, автор на полном серьезе сравнивает Postgres с SQLite. Мне показалось, в статье нет глубины, и тезис из заголовка ничем не подтверждается. И хотя вывод верный — Just Use Postgres — автор пришел к нему странным способом.
В своей заметке я расскажу, как пришел к аналогичному выводу сам — только доводов будет больше.
Последний год я занимаюсь Посгресом все активнее. Я мигрировал большую систему с OpenSearch на Postgres. Это 30 сервисов с большими JSON-документами — от нескольких тысяч до миллионов в каждом сервисе. Нужен поиск по вложенным полям, поиск по вхождению, простое ранжирование, а также всякая отчетность. И пока я все это мигрировал, узнал о Постгресе столько, что хватит на несколько докладов. В том числе — почему именно Постгрес так хорош.
Я давно понял одну вещь, а миграция только ее укрепила. Хранение данных определяет разработку. Это фундамент, относительно которого планируешь куда копать и что возводить. Кто-то считает, что абстракцией можно уравновесить любое хранилище: сделать так, что get-by-id либо идет в базу, либо качает файл из S3. Это справедливо в простых случаях. На практике каждое хранилище вносит свои особенности, с которыми нужно мириться. Если у вас условные OpenSearch или Cassandra, их особенности будут фонить сквозь код. Избежать этого нельзя. На мой взгляд, Постгрес фонит меньше всех: с ним у вас будет меньше проблем в абстракцях.
Но довольно расплывчатых слов, перейдем к конкретике. Начну с того, что Постгрес легко ставится и работает на любой машине, будь то локальный комп с Виндой, Маком, Линуксом или сервер. Он есть во всех пакетах. Постгрес написан на Си, и на выходе бинарный файл, которому не нужна Джава. Помню, как ставил Датомик на Убунте — это было тяжело. Вроде бы Джава, “compile once, run everywhere (c)” — но вылетают ошибки о том, что классы не найдены. Оказалось, нужна другая Джава, которую нужно ставить отдельно. С Постгресом такого не было никогда.
Для Мака есть проект Postgres.app. Это приложение с графическим интерфейсом, чтобы запустить Postgres. Можно скачать любую версию по отдельности; есть убер-приложение со всеми версиями и установленным PostGis. Так что любой человек может завести Postgres + PostGis в два клика.
Особой похвалы заслуживает докерный образ Postgres. Он очень гибко настраивается: почти любую опцию можно задать переменной среды, легко прокинуть свою конфигурацию. У образа убойная фича: папка, куда можно накидать файлы .sql, .sh и .gz. При запуске образ запустит эти файлы в алфавитном порядке. Если у вас миграции или посев тестовых данных, смонтируйте файлы в образ, и при запуске получится готовая база.
По наивности я думал, что так работают образы других баз данных. Оказалось нет. Запустил образ Кассандры, а она ничего не знает о первичной настройке. Нужны разделы и таблицы? Создай сам. Нужны топики в Кафке? Создай сам. Нужна точка обмена в RabbitMQ? Создай сам! После запуска образа нужно дождаться, пока поднимутся все потроха (обычно это поллинг порта), а потом создать таблицы и топики. Почему-то в Постгресе подумали над этим, а остальным безразлично. Считаю, что образ postgres нужно брать за образец.
У документо-ориентированных баз и key-value хранилищ есть преимущество: они хорошо реплицируются в силу дизайна. Часто говорят: вы со своим Постгресом упретесь в потолок, когда нужно хранить данные в разных датацентрах, но при этом иметь легкий доступ из одного центра к другому. Условная Кассандра чувствует себя лучше в подобных условиях. Но забывают, что реплицировать нужно не все данные, а только их часть. Например, только базовые сведения о пользователях и сущностях, чтобы быстро выяснить, в каком дата-центре они лежат и выполнить запрос там.
Так у нас было устроено в одном облачном хостинге. В каждом дата-центре данные хранились в MySQL, а пользователи и права доступа дублировались в кластер Кассанды, который в силу репликации был доступен отовсюду.
Postgres тоже не стоит на месте, и в нем все больше средств репликации и кластеризации. Есть проекты вроде Debezium, которые читают журнал WAL и стримят изменения в другие базы, очереди и так далее.
Postgres силен в проекции данных. Бывает, на одни и те же данные нужно смотреть под разным углом: делать группировки, поворачивать таблицы. Часто нужны левые соединения: это когда слева находится полный набор данных, а справа — неполный, и данные слева не должны пропадать. В редких случаях нужно декартово произведение двух таблиц (каждый по каждому), что тоже делается легко. Есть много функций, которые разбивают данные на строки (переводят массивы в строки элементов) и наоборот — агрегируют записи в коллекции.
Postgres силен рекурсивными запросами. Это когда запрос разбивается на две части: первичный посев и рекурсивная логика, которая принимает предыдущий результат и порождает новый. Пока он не пустой, строки складываются в итоговую таблицу. За счет рекурсии прекрасно обходятся таблицы со ссылками на себя, например структура папок, иерархия сущностей.
В финансах очень важны оконные функции: посчитать нарастающий доход, остаток на счете, стоимость проекта по неделям и многое другое. Оконные функции слегка пугают, но достаточно прочитать одну книжку, чтобы овладеть ими (см ниже). Без оконных функций происходит следующее: человек выгребает из базы массив данных и проделывает вручную то, что умеет база — только на порядок медленней и с кучей багов. О похожем случае я как-то уже писал.
Огромную пользу можно получить из связки materialized view и pg_cron. Напомню, materialized view — это вьюхи, которые сбрасываются в физическую таблицу. На нее можно навесить индексы, чтобы ускорить поиск. Польза таких вьюх огромна — это различные проекции и отчеты. Чтобы каждый раз не гонять огромный запрос, его “запекают” во вьюху и материализуют, после чего выбирают строки обычным SELECT.
В текущем проекте мы храним огромные JSON-документы. У них сложная структура, но отчетность должна быть плоской. Сначала я писал запросы со множеством операторов
#>>, которые извлекают данные из JSON по пути в виде массива. Но со временем стал делать плоские представления этих документов вьюхами — и дело пошло лучше. Аналитикам и менеджерам тоже легче: им постоянно нужные данные, и они пишут запросы сами, чтобы не дергать программистов.Расширение pg_cron выводит Постгрес на новый уровень: с его помощью можно выполнить любой скрипт по расписанию. Расширение использует стандартный синтаксис crontab. У меня множество крон-задач на материализацию вьюх и прогрев индексов — их принудительный загон в оперативную память. С
pg_cronбаза становится полностью автономной: не нужен сторонний крон, который пинает скрипты. Я недоволен только одним:pg_cron— стороннее расширение, и его нет в поставке. Однако облачные провайдеры вроде Амазона предустанавливают его.На сегодня Постгрес — лучшая база для работы с JSON-документами. Я не в восторге от JSON и насколько возможно, храню данные в таблицах. Но порой выбора нет: бизнес завязан на какие-то стандарты. Пример — медицинский формат FHIR. Это огромные документы тройной и более вложенности. Раскладывать их по таблицам и собирать джоинами тяжело, поэтому их хранят в поле jsonb. У меня похожая ситуация : 30 сервисов, каждый отвечает за свою бизнес-сущность. Это большие JSON-ы, и сервисы гоняют их туда-сюда; на них завязан фронтенд. Я пытался представить их в плоском виде, но это очень трудно.
Постгрес предлагает богатные возможности для JSON: доступ ко вложенным полям по массиву ключей, обновление вложенных полей, слияние словарей, гибкую замену, индексацию документа целиком или подмножества… Есть даже встроенный язык JSON PATH для поиска! Да, внутри SQL может быть строка с мини-языком JSON PATH. Я использую его в сочетании индексами btree по отдельным полям.
В последнем Постгресе 17 появилась функция JSON_TABLE. По указанной спеке она переводит JSON в таблицу с выводом типов. Если у вас вектор мап, то легко получить таблицу. JSON_TABLE поддерживает вложенность, в результате чего можно развернуть мапу мап в плоскую таблицу. Далее вы материализуете ее, ставите на крон и готово — можно выбрать плоские данные селектом.
Для Постгреса создано великое число обучающих материалов: книг, курсов, самоучителей. Многие из них изначально созданы на русском, то есть не являются переводами. Российский вендор Postgres Pro не только пишет отличные книги, но и выкладывает на сайте бесплатно. Бесплатно! Я читал некоторые из них, и это не халтура, а действительно проработанные материалы. Книга Егора Рогова “Postgres изнутри” описывает устройство базы в мельчайших деталях. Наверное, нет книги лучше, чтобы понять, как работают современные базы данных.
В Постгресе отличный анализатор запросов: он покажет, какие стратегии выбрал движок для обхода таблиц и джоинов; какие индексы были использованы и какую их часть пришлось читать с диска. Да, понадобится время, чтобы понять его вывод. Но иные базы данных не предлагают вообще ничего! Просто дают рекомендации, а дальше пробуй сам. Есть расширения, которые фиксируют медленные запросы и их план выполнения. Расширение pg_stat_statements ведет статистику по всем запросам: число вызовов, частота, минимальное, максимальное, среднее время выполнения, ожидание, объем передачи данных и прочее. Все это помогает отлаживать случаи, когда базе нехорошо.
В Постгресе достойный полнотекстовый поиск. Для начала подойдет триграммный нечеткий поиск по коэффициенту совпадения. Позже можно добавить ts_vector — вектор лексем и стемминга. Из коробки есть стемминг для десятка языков, в том числе русского. Когда заходят разговоры об OpenSearch и других поисковых движках, оказывается, что на Постгресе можно сделать не хуже и главное — без добавления в систему нового узла.
У Постгреса обширный тулинг: консольные и графические клиенты — браузерные и настольные. PGAdmin, DBeaver, DataGrip… стандартная утилита psql покрывает множество случаев. Она показывает сведения обо всех сущностях, выводит данные разными способами, умеет импорт-экспорт. Можно редактировать запросы и сущности во внешнем редакторе, например Emacs или Vim.
Постгрес поддерживает апишку COPY, с помощью которой данные гоняют в обе стороны. Если я хочу слить таблицу в CSV, пишу что-то вроде:
COPY my_table (id, name, email) to STDOUT with (HEADER, format CSV)и Постгрес выплевывает CSV-шный файл. Можно записать файл на диск или читать построчно из сети. Это работает и в обратную сторону: если я хочу вставить CSV в таблицу, то пишу:
COPY my_table (id, name, email) from STDIN with (HEADER, format CSV)и стримлю в соединение строки CSV. Кроме CSV, Постгрес поддерживает бинарный формат. Спецификация довольна проста, и на практике он работает на 30% быстрее.
Словом, гонять большие данные в Постгресе очень просто. Я как-то писал о том, что источник данных хорош настолько, насколько удобно забрать из него данные. В том же OpenSearch забор данных превращается в муку: нужна ручная пагинация по страницам. А Постгрес выплюнет миллион строк и не моргнет глазом — только успевай их принимать.
Не менее важна генерация данных. Скажем, у вас на проде миллион записей, и нужно воспроизвести сложный запрос. Если в локальной базе только тысяча записей, он поведет себя по-другому; нужен именно миллион. Как вы их вставите?
Обычно на этом месте расчехляют Питон и всякие FakeMockGenerator-ы — библиотеки для генерации случайных данных по спеке. Этот код долго писать, и вставка тоже будет долгой, потому что мы передаем данные от клиента серверу. Еще нужен рантайм, то есть среда, где запускается код: какая-то машина, нода, плейбук.
А ведь достаточно написать примерно такой скрипт и выполнить его в PGAdmin:
insert into documents (id, document) select gen_random_uuid() as id, jsonb_build_object( '__generated__', true, 'meta', jsonb_build_object( 'eyes', format('color-%s', x) ), 'attrs', jsonb_build_object( 'email', format('user-%s@test.com', x), 'name', format('Test Name %s', x) ), 'roles', jsonb_build_array( 'user', 'admin' ) ) as document from generate_series(1, 500) as x returning id;Он вставит в базу столько JSON-документов, сколько указано в функции generate_series. Хочешь миллион? Да пожалуйста. Важно, что данные генерятся сразу на сервере — мы не гоняем их по сети. Все происходит внутри Постгреса, и это значительно быстрее. Миллион огромных JSON-ов вставляются за несколько минут. Этот скрипт легко поправить, чтобы поля высчитывались по-другому. Каждый может скопировать его и выполнить на свой базе, не прибегая к Питону.
Иные жалуются, что SQL устарел. Мол, это архаичный язык, он плохо шаблонизируется, и логично выразить его данными, например JSON-ом. Что тут сказать… Да, SQL со скрипом ложится на всякие ORM. Но сегодня полно библиотек, которые строят SQL из объектов и коллекций. А во-вторых, мне нравится самобытность SQL, то, что он остается вещью в себе. Когда пишешь большие запросы, начинаешь видеть его красоту. Со временем понимаешь, что заменить его нечем — слишком много ситуаций и выражений.
Я рассматриваю SQL как REPL к данным. Наверное, вы знаете, что программисты на Лиспе днями сидят в репле. О преимуществе REPL-driven develpoment сказано много, и нет смысла повторять. По аналогии, SQL — это репл для данных со всеми преимуществами REPL-driven develpoment. Легко понять, какие данные прилетят в код, выполнив запрос в базе. Вместо быдлокода, который вынимает тысячи записей, исправляет их и записывает в базу, можно выполнить один UPDATE. Поймал себя на том, что целыми днями сижу в PGAdmin, а к коду приступаю в последнюю очередь.
Повторю тезис, который как-то высказывал. Данные — это отдельный домен. Ключевое свойство домена — его ортогональность другим доменам. Я хочу, чтобы данные не были привязаны ко всяким Питонам и Джавам. Я хочу управлять ими независимо от языка или потребителей. Мне не нравятся встраиваемые хранилища или базы, которые “сливаются” с приложением. Если данные можно извлечь только вызовом метода, я пас.
Рассказывать о том, как динамично развивается Постгрес, нет смысла. Это видно всем. Есть классический Постгрес, есть вендорский Postgres Pro, где доступны различные фичи до того, как они окажутся в классике — правда, за деньги. Развиваются расширения, появляются новые вендоры, проводят митапы и конференции, выходят книги, видосы… на любой запрос найдется контент.
Важно, что сообщество Постгреса прошло проверку на адекватность. Как только один чудак заявил, что нужно выгнать русских разработчиков и откатить их код, ему быстро объяснили, что к чему. Больше эту тему не поднимали, по крайней мере в публичном пространстве.
И вот теперь, в конце шестого листа, я говорю: вот поэтому берите Постгрес.
-
SOLID и контекст
Когда говорят про SOLID, забывают вот о чем. Принцип SOLID — типичный пример, когда контекст, в котором возникло явление, важнее самого явления.
SOLID возник в момент, когда в ООП-тусовке царил упадок. До повсеместного перехода на ООП говорили, что объекты решат все проблемы. Достаточно выразить сущности классами и нарисовать UML-схему — и все станет понятно. Звучит примерно как “Земля плоская”, но тогда в это верили. И когда ООП-модель стала буксовать, придумали SOLID, чтобы вдохнуть в нее новую жизнь.
У SOLID есть даже не аналогия, а буквальный пример из жизни. Каждый тренер знает, что главное у спортсмена — настрой (разумеется, не исключая питание и тренировки). Если настрой в упадке, есть не совсем честные способы его поднять. Скажем, когда команда проигрывает всухую, тренер берет таймаут и выдает “заряженные” клюшки, которыми играли великие спортсмены. Или переставляет участников местами, говоря, что сейчас будем играть по “секретной” тактике. Поскольку спортсмены суеверны, это работает.
Та же самая история у военных, полицейских, пожарных. У них есть церемонии раздачи “заряженных” девайсов, например, касок погибших героев. Надевая такую каску, боец буквально получает +100 к отваге. Вопрос о том, действительно ли герой носил эту каску, тактично обойдем стороной.
С принципом SOLID то же самое. Когда стало ясно, что нагромождение классов не решает прошлых проблем, а только добавляет новых, кто-то придумал SOLID. Посыл в том, что отныне мы не блуждаем в потемках, а идем к некой цели. Пишем не просто быдлокод, а по некой методичке. И пусть она спорна и расплывчата, это неважно — есть ориентир. Спортсмен снова мотивирован и готов брать рубежи.
Поэтому отношение к SOLID у меня спорное. Смысловая составляющая высосана из пальца, но запал колоссальный. Уже десятки лет люди спорят о том, как писать код по SOLID правильно. В этом смысле я снимаю перед создателем шляпу, потому что ведь надо так уметь! — вдохновить толпы народа без какой-либо конкретики.
Но у любой легенды есть запас прочности, и актуальность SOLID подходит к концу. Я понимаю, когда о нем пишут в рекламных блогах или курсах для новичков. SOLID — это все и ни о чем, универсальный рецепт, из которого можно выжать тысячи текстов. Но удивляет, когда кто-то всерьез рассуждает о том, как в 2025 году писать код по SOLID. Здесь можно сказать одно: как бы ни держалась стюардесса, ее пора закопать.
-
SOLID и другие аббревиатуры
Читатель Дмитрий снял с языка одну мысль, которую я приберег для отдельной заметки. Если коротко, все удачные аббревиатуры вроде SOLID, как правило, высосаны из пальца. Вероятность, что первые буквы пяти слов образуют другое емкое слово, равна нулю. Поэтому слова подгоняют под аббревиатуру.
Другими словами, сначала придумывают емкий термин, затем под каждую букву ищется слово. Разумеется, за уши притягивают лишние слова, как например принцип Liskov, который никому не сдался. Но без Liskov не получилось бы слова, поэтому пришлось взять.
В своем комментарии Дмитрий приводит пример. Берем выразительную аббревиатуру, например ANALSEX и просим чат-ГПТ придумать расшифровку. Чат справился прекрасно:
-
A: Abstraction Focus on hiding complex implementation details and exposing only essential features.
-
N: Normalization Ensure that data structures and databases are designed efficiently, avoiding redundancy.
-
A: Automation Prioritize automating repetitive tasks and workflows to increase efficiency and reduce errors.
-
L: Loose Coupling Design components to have minimal dependencies, making systems more modular and easier to maintain.
-
S: Scalability Build systems capable of handling growth in users, data, and operations effectively.
-
E: Encapsulation Keep implementation details private within modules or classes, exposing only necessary interfaces.
-
X: eXpandability Design with future growth and adaptability in mind, ensuring that new features can be added without major rewrites.
Особенно хорош последний пункт. Слов на X мало, поэтому чат выделил вторую букву в eXpandability.
И главное, все по делу: абстракции — нужны, автоматизация — нужна, масштабирование — нужно, расширяемость — тоже. Не прикопаешься. Так что всем внедрять ANALSEX! Обсудите с коллегами и расскажите начальству.
-
-
Электронные квитанции
Иногда снабжающие организации присылают письма:
Иван Викторович!
Давайте беречь бумагу и планету! Перейдем на электронные квитанции во имя добра. Согласны? Если да, откройте файл из вложения, заполните и отправьте.
Конечно, я за природу, планету и все такое. Открываю файл
?????????????.docиз вложения, смотрю, а там: укажите ФИО, адрес, юридический адрес, ИНН, реквизиты счета, телефон, номер и дату договора, почту, а еще — название документооборота и фирму-эмитент электронной подписи. Всего-то…Смотрю на этот файл минуту, а потом отправляю в корзину вместе с письмом. До следующего раза.
Хочется спросить: ребята, если вам так нужно перетащить меня в какую-то систему, нельзя ли этому поспособствовать? Скажем, поручить кодеру Васе написать скрипт, который вытащит мои данные из базы — я указывал их при заключении договора — и состряпает PDF, который останется только подписать. Что, нельзя так?
Наверняка эти письма рассчитаны на биг-боссов, которые пересылают их секретарше Леночке со словами “разбери это дерьмо”. Но у меня нет секретарши, и тратить час на заполнение Ворда я не хочу.
Самое забавное — фирма уже высылает документы по электронной почте, но вдобавок зачем-то кладет в почтовый ящик распечатки толщиной с палец. Уже который раз пишу им, мол, перестаньте слать бумагу, электронка вполне устраивает. Но им нужно заявление в Ворде.
Удивительно, как быстро у людей деформируются мозги в больших фирмах.
-
The Fuck
Может быть, вы не знали, но есть программа с выразительным названием The Fuck. Написана на Питоне, 90 тысяч звезд, работает следующим образом.
Предположим, вы запустили что-то в терминале, но получили ошибку. Не указан такой-то флаг, это депрекейтед, то-се. Если ввести
fuck, то программа считает предыдущую команду и повторит ее, но на этот раз правильно.Звучит непонятно, так что рассмотрим пример. Скажем, я сделал новую ветку и хочу запушить ее на сервер:
git checkout -b ssl-no-validation git add . git commit -m "some changes" git pushВот что я получу:
fatal: The current branch ssl-no-validation has no upstream branch. To push the current branch and set the remote as upstream, use git push --set-upstream origin ssl-no-validationГит прекрасно понял, что я имел в виду, но предлагает ввести команду повторно. Если же ввести
fuck, то утилита считает bash_history и выполнит то, что нравится Гиту.В последнем Гите это починили: теперь
git pushделает апстрим самостоятельно. Однако долгое время меня выручал fuck.Сегодня я им не пользуюсь, но вспомнил вот почему. Программа хорошо расширяется регулярками, и народ собрал целую кладезь fuck-рецептов. Получилась своего рода энциклопедия бредовых случаев. Мне кажется, они достойны изучения просто затем, чтобы знать, как делать не надо. Если же ваша программа оказалась среди рецептов – это нужно быстро исправить.
-
Постгрес и отчеты
В очередной раз выручил Постгрес.
По работе я много занимаюсь отчетностью: генерю CSV и эксельки со всякими цифрами. Дело это не хитрое, но много нюансов: нужно собрать данные из десяти источников, очистить, переколбасить, построить прямые и обратные индексы. В идеале распараллелить. Потом пробежаться по коллекциям и записать итоговый документ.
Поскольку дело происходит в лямбде, я очень стеснен в ресурсах и времени. Процессор медленный, памяти и диска немного, а на выполнение дается не более 15 минут. Это только кажется много, а на самом деле первые 7 минут уходят только на то, чтобы скачать архивы.
Из последнего: в папке S3 лежит огромный CSV на 10 миллионов записей. Нужно выбрать из него одно подмножество, затем второе, а потом склеить их по id = parent_id.
Написал на Кложе черновик — работает, занимает 11 минут. Можно плюнуть и оставить, но 11 минут — это уже близко к 15 минутам, а значит, можно получить таймаут. Переписал с параллельной обработкой — стало 5 минут, волноваться не о чем.
А потом смотрю и думаю: ты же, дурачок, написал ровно то, что делает база данных. Только раз в десять медленней и костыльней. Убери быдлокод, загони CSV в базу и выполни запрос — получишь то же самое.
Так и сделал: получаю из Амазона стрим с CSV-содержимым. Не скачивая его на диск, направляю прямиком в Постгрес во временную таблицу (апишка COPY FROM STDIN). Тот загружает 10 миллионов записей за 40 секунд. Потом посылаю SQL с двумя подзапросами и джоином — результат готов за 15 секунд. Его даже не нужно писать в CSV самому. Вызываешь COPY TO STDOUT — и Постгрес сам записывает CSV на диск. Точнее, в стрим, который я направляю в файл.
Минус два экрана быдлокода, быстрее почти на порядок — все довольны, все смеются. Сразу после этой доработки мне написал один человек — мол, репорт хороший, только надо еще одну табличку заджойнить. Да не вопрос.
Отсюда мораль — если что-то можно поручить базе, поручайте базе. Постгрес уже 20 лет делает джоины и проекции таблиц. Вероятность того, что вы сделаете быстрее, стремится к нулю.
Ради интереса глянул на SQLite — зачем брать серверный Постгрес, если можно локально справиться? Оказалось, SQLite не умеет импортировать CSV. Такая команда есть в интерактивном шелле, а в протоколе обмена — нет. А в Постгресе есть потоковый COPY, поэтому выбора не остается.
Есть у нас сервис, который пилят другие люди. Там логика крутится вокруг CSV и пакетного импорта в другие сервисы. Посмотрел и ужаснулся: километры кложурного быдлокода можно заменить импортом в базу и парой-тройкой запросов. Дай бог доберусь, переделаю.
-
Код на русском
Я как-то рассказывал про феномен: показываешь человеку код на Лиспе, и он начинает хихикать, хрюкать, постить смайлики, словом, теряет всякое лицо. Примерно как школьник, принесший в класс эротический журнал.
Заметил, что такая же ерунда с кодом на 1С. Если где-то всплывет код на русском, начинаются крики, эмоции… ужасно.
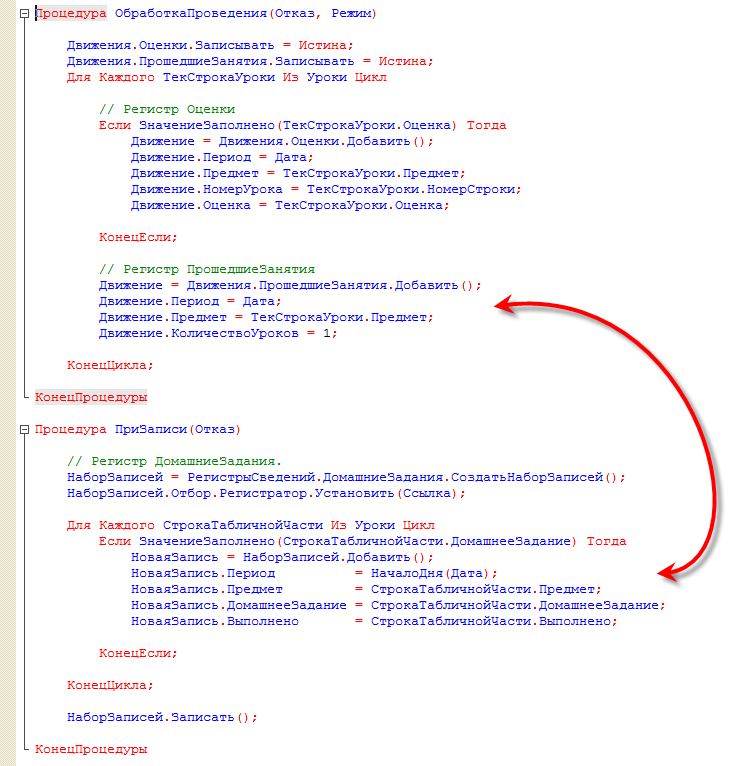
Я писал на 1С три с половиной года в Чите, в славном Энергосбыте. У нас были две жирные программы: одна на Дельфях, вторая на 1С. Я поддеживал обе, и до сих пор нежно люблю эти платформы.
Так вот, торжественно заявляю: код на русском поддерживается точно так же, как и на английском. Разницы нет. Когда читаешь код, то воспринимаешь его как структурированный набор команд. Никто не читает по буквам “Если…То… Конец”. Глаз выделяет структуру, операторы, циклы, словом, все как в обычном языке.
Да, у 1С свои проблемы. Во-первых, язык не отличается врожденной красотой, а во-вторых, у 1С радикально низкий порог входа. Хотя то же самое можно сказать о раннем PHP. Еще одна косвенная проблема – 1С стоит особняком от других технологий, и в результате типичный 1С-программист ничего не знает о протоколах, безопасности и алгоритмах.
Эти проблемы я признаю и готов обсуждать. Но когда очередной клоун смеется над кодом с русскими буквами, боюсь, он получит только мое презрение.
Writing on programming, education, books and negotiations.