-
О заголовках
Совет тем, кто пишет:
НЕ ВЫПЕНДРИВАЙТЕСЬ С ЗАГОЛОВКАМИ
Что это значит? То, что заголовок не должен быть крылатой фразой; цитатой из фильма; популярным названием; советским штампом и так далее.
Иные авторы пишут хорошие статьи, но с заголовками у них беда. Почему-то считается, что простой понятный заголовок — это зашквар. Например, в тексте автор тестирует процессоры. Вместо “Тестирование процессоров Ryzen” он пишет “Ryzen и все-все-все”. Или вместо “Запуск Kafka в продакшене” у него закос под былину: “Как я Kafka на сервере поднимал”.
Автор думает, что оригинален и неповторим, а на самом деле это лютый колхоз. Первый пришедший в голову штамп. Лично мне от таких заголовков стыдно.
Другие примеры: “Чтобы сказку сделать былью”, “вновь продолжается бой” — советская тема. Былинный порядок слов: “как я то и сё делал”. Винни-Пух: “…и все-все-все”. Просто штампы: не чем-то единым. Двойное название: “То-то то-то, Или это-это”. Цитаты: “в чём сила, брат”, “вы нам за X ответите”. “Но это уже другая история” и так далее.
Как только вам в голову пришёл штамп, одумайтесь и не пишите его. Пусть заголовок будет простым, скучным, но не затасканным. Люди думают одинаково, и фраза из Брата 2 приходит в голову всем, не только вам. Это ни разу не стиль, а слабость.
Вспоминаю только считанные разы, когда заголовок с отсылкой был небанальным. Но и отсылка тоже должна быть небанальной, то есть понятной только узкому кругу читателей. Её разгадка — своего рода награда.
Но это уже другая история.Еще раз:
НЕ ВЫПЕНДРИВАЙТЕСЬ С ЗАГОЛОВКАМИ
-
Systems in Clojure
Clojure in Production
- Chapter 1. Web development
- Chapter 2. Clojure.spec
- Chapter 3. Exceptions
- Chapter 4. Mutability
- Chapter 5. Configuration
- Chapter 6. Systems in Clojure
- Chapter 7. Tests
In This Chapter
- More Details on Systems
- Dependencies
- Advantages
- Preparing for the Overview
- Mount
- Component
- How It Works
- The First Component
- Constructor
- Slots feature
- Database Component
- Transactional Component
- Worker
- Manual dependencies
- System in Production
- System Storage
- Correct Completion
- More about Waiting
- Improving Dependencies
- Grouping slots
- Conditional System
- Sharing Components
- Idempotence
- Alternative Way
- Integrant
- Summary
In this chapter, we will talk about systems, i.e., collections of interrelated components. We’ll look at how large projects are assembled of small parts as well as how to overcome complexity and make all the parts work as one.
The concept of a system is related to the configuration we discussed recently. The configuration answers the question of how to get the parameters, and the system knows how to use them.
Systems emerged when the demand for long-running applications arose. We don’t require such things from scripts and utilities as they have a short runtime and a state that does not last long. When scripts and utilities finish their work, resources get released, so there is no point in monitoring them.
Things are different for server applications: they work all the time, and therefore, are designed differently than scripts. The application consists of components that run in the background. Each component performs its specific task. At startup, the app enables components in the correct order and builds connections between them.
-
Не подчёркивайте в книгах
Вы наверное видели, как успешные люди подчёркивают фразы в книгах. Со стороны это смотрится супер-круто: сидит такой мега-мозг, водит карандашом и всё запоминает. Плюс сто к интеллекту.
Эффект хороший, но толку от этого нет. Поэтому — перестаньте портить книги. Подчёркивание не делает вас умнее и не увеличивает запас знаний. Вы просто водите карандашом. Портите книжку. Хватит.
Два доказательства. Первое — давно заметил по себе, что подчёркивание не несет пользы. Подчёркнул, и через день уже не помню, что именно. Всякие заметки на полях, стикеры с умными мыслями — все это чушь собачья. Выглядит умно, пользы никакой.
Второе — поскольку я не авторитет, обратимся к Барбаре Оакли. Она как Дональд Кнут, только женщина. В книге “Думай как математик” Барбара пишет:
Вас наверняка удивит информация о том, что выделять и подчёркивать текст нужно осмотрительно, иначе такой способ будет неэффективен и даже вреден. Движение руки, подчёркивающей текст, может дать вам иллюзию, будто вы переместили изучаемый материал в сознание. Поэтому, когда делаете пометки, сначала научитесь находить в тексте важное, а уже потом что-то отмечать и старайтесь не выделять много текста: максимум одно предложение на абзац
Внезапно, да? Вот что пишет научный руководитель Барбары:
Учась в магистратуре, я порой видел, что другие студенты интенсивно выделяют в учебнике этапы доказательств или подчёркивают предложения в абзацах. Я никогда этого не делал. Подчёркивание нарушает оригинал без всякой гарантии того, что выделенная информация отложится в сознании и принесет пользу.
Далее:
Мой собственный опыт, таким образом, созвучен исследованиям и открытиям, о которых вы читаете в этой книге. Лучше не подчёркивать и не выделять фрагменты текста, поскольку – по крайней мере судя по моему опыту – это действие лишь создает иллюзию компетентности. Вспоминать и пересказывать текст – гораздо более мощное средство. Попытайтесь добиться того, чтобы основная идея рассказанного на каждой странице отложилась у вас в сознании прежде, чем вы перейдете к следующей.
Один из главных пунктов в конце книги:
После каждой прочитанной страницы отведите от нее взгляд и вспомните основные идеи. Не выделяйте (например, подчёркиванием) большое количество текста на странице и никогда не отмечайте то, чего предварительно не закрепили в памяти. Пытайтесь вспоминать учебный материал по дороге на занятия или в тех аудиториях, где вы не занимались им изначально. Способность вспоминать, т. е. генерировать идеи изнутри сознания, – один из ключевых показателей эффективной учебы.
С большой гордостью сообщаю, что своим умом дошел до того же, что пишут умные люди.
Итак, что же делать, чтобы материал запомнился? Вот список.
- Читать небольшими порциями, потом откладывать и пытаться вспомнить. Если не выходит, значит вы читали зря. Вернуться и перечитать. Сократить разовый объём чтения.
- На прогулке мысленно пересказать материал самому себе.
- Выписать в тетрадь опорные тезисы или краткий конспект. Именно выписать, а не переписать, то есть воспроизвести по памяти.
Этого достаточно, чтобы запомнить материал. Если вы часто скачете по книге, пригодятся обычные закладки. Но не надо чиркать — даром что книгу испортили, так и обманули себя.
На тему выделений цветом см. также заметку об Экселе.
-
Обновил зипперы
В подкасте с подлодкой я пытался объяснить зипперы. Пытался, — потому что формат подкаста не подходит для таких вещей. Нужна маркерная доска, схемы и всё такое. На словах — ерунда, только заинтересовать.
А потом вспомнил, что полгода назад написал руководство по зипперам. Оно разбито на восемь постов и по объёму тянет на главу книги — около 30 страниц. Сразу после выпуска я вернулся к ним и отредактировал: почистил текст, доработал примеры и код.
Уверен, в интернете нет более подробного текста по зипперам на русском. Да и на английском не густо: обрывочные посты в блогах и бородатые пейперы. Последние хороши, но на Хаскеле, что не наш метод. А у меня — сплошной шоколад. Скоро будет версия на английском.
Пользуйтесь!
Оглавление
- Зипперы (часть 1). Азы навигации
- Зипперы (часть 2). Автонавигация
- Зипперы (часть 3). XML-зипперы
- Зипперы (часть 4). Поиск в XML
- Зипперы (часть 5). Редактирование
- Зипперы (часть 6). Виртуальные деревья. Обмен валют
- Зипперы (часть 7). Обход в ширину. Улучшенный обмен валют
- Зипперы (часть 8). Заключение
-
Тултипы
Дизайнеры Гугла совсем офонарели. Всплывающее окно показывает другие всплывающие элементы. Никого не парит, что места с гулькин нос, и ничего не видно.
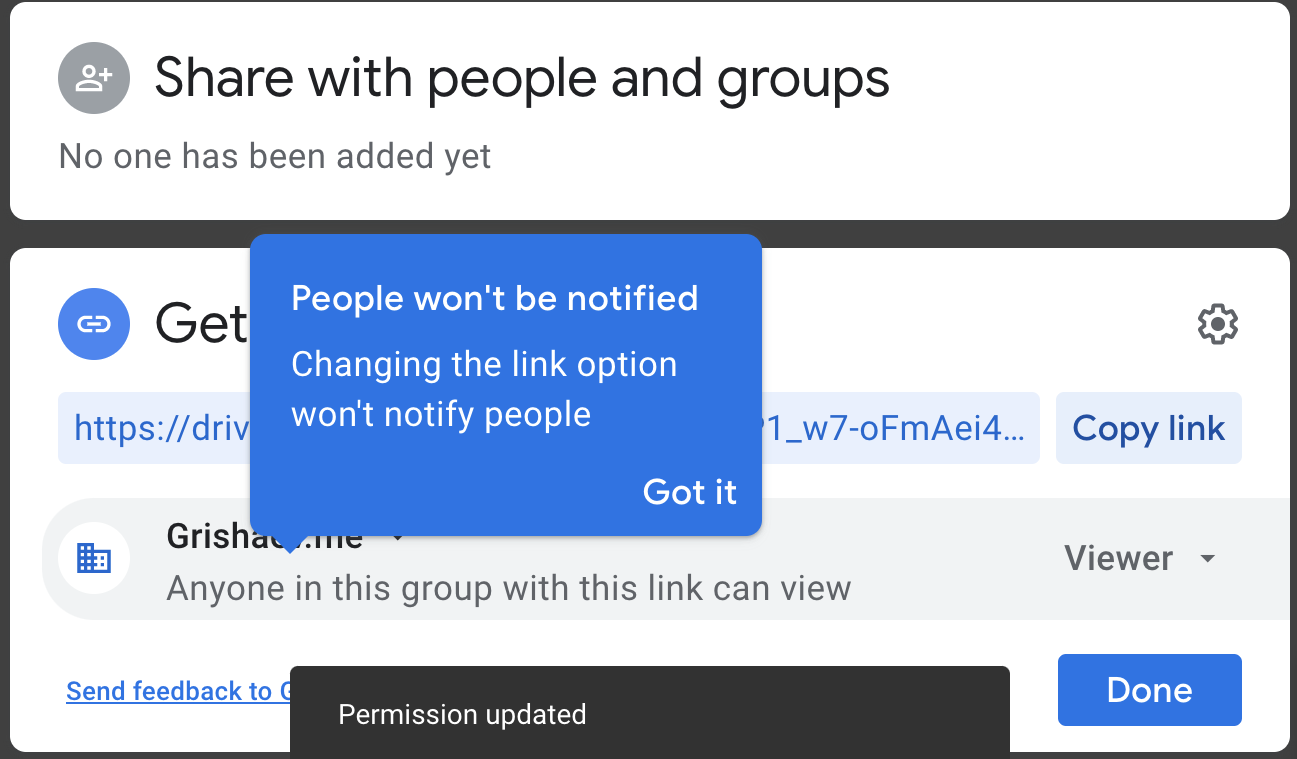
Тултипы и попапы — настоящая болезнь дизайнеров. Сегодня, что бы ты ни открыл — настольную программу или сайт — интерфейс взрывается тултипами. Или красными шариками, которые означают непрочитанные сообщения. Будь ты хоть трижды аноним за Тором и VPN, всё равно — у нас персональное сообщение именно для тебя.
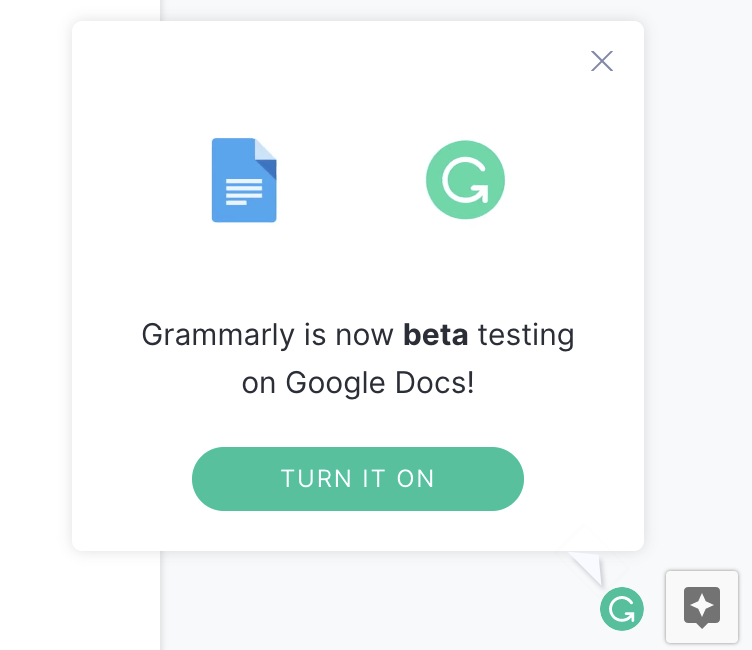
Всплывающие элементы – признак импотенции дизайнера, примерно как три точки с выпадашкой. Жаловаться можно бесконечно — достаточно открыть любой современный сайт. Но я очень надеюсь, что хотя бы один дизайнер прочтёт этот текст и однажды откажется следовать идиотизму.
-
Подкаст с Подлодкой
На прошлой неделе выступил в подкасте “Подлодка”. Говорили про Кложу и связанные с ней вещи: философию, окружение, зарплаты и поиск работы.
Итоговая версия на SoundCloud:
Черновой стрим на Ютубе:
Ещё ссылки:
-
Правила
Есть такой популярный жанр — правила жизни знаменитого человека. Актер, певец или политик рассказывают, что они встают в пять утра, всегда говорят правду или верят в бога. Сюда же относятся правила успеха — быть отзывчивым, больше давать, чем брать, посылать в космос лучи добра.
Из бульварной сферы жанр перекочевал в айтишный, и теперь люди читают то же самое, только под другим соусом. Или не читают, а смотрят или слушают в подкастах. Никого не осуждаю за это, но важно понимать следующее.
Если вы всерьез интересуетесь чьими-то правилами жизни, то неплохо бы спросить себя, как они коррелируют с успехом того человека. Например, писатель встает в пять утра. Как это ему помогает? Я знаю много людей, которые встают рано, но они ничего не написали. Кто-то пьет только дистиллированную воду, но в тридцать шесть выглядит на тридцать пять — особого эффекта молодости не наблюдаю.
У огромного числа людей своя ментальная модель добра и вселенской справедливости, а также того, что кому и на каком свете зачтется. Говорить с ними об этом все равно что наблюдать ожившие картины Босха — мрак и безумие.
У всех у нас свои правила, и важны не они сами, а как мы к ним пришли. Тот, кто встает в пять утра, скорей всего выстроил так свой день в силу множества обстоятельств. Помню, я тоже двигал свой биоритм туда и сюда по многим причинам — семейным и личным. И мое утверждение о том, что надо вставать во столько-то будет звучать глупо без полного контекста. А контексту обычно нет места в жанре правил. Там должно быть все четко, чтобы легко было запомнить.
Главное правило в том, что не надо тащить в свое гнездо чужие правила, будь они хоть от Аллы Пугачевой, Нельсона Манделлы и Илона Маска. За каждым правилом стоит сложный контекст, который вы все равно не поймете. Это как пустая коробка от дорогого товара — только похвастать в соцсети. Истинная цель — вывести свои правила, которые опираются только на ваш опыт. Одно свое правило стоит тысячи мотивирующих цитат, даже если перечит им.
-
Абстрактный слой
Все хорошо, задача ясна, готов сесть и заимплементить. Но нет, приходит упырь и говорит: решение, хоть и простое, не отвечает нашим принципам и не следует общему стилю. Надо добавить абстрактный слой, чтобы было больше гибкости.
Упыря хочется убить, но похоже, он и правда уверен в своих словах. Понятно, если бы он просто хотел мне нагадить. Но в его проекте та же хрень: абстракция на абстракции. Надо разобраться.
Если убрать лишние слова, перед нами выбор. А) быстро сделать задачу и, возможно, в будущем её доработать. Б) делать задачу долго, и, возможно, уже не касаться ее в будущем.
Важно понимать, что в обоих случаях “возможно” означает “придется по-любому” или “никогда не придется”. Что это значит? То, что в реальности доработка не зависит от технической реализации. Если это важная фича, которой будут постоянно пользоваться, улучшать ее придётся при любой реализации. И наоборот — если фичей пользуются мало, новых усилий скорей всего не понадобится.
В выборе А против Б нормальный человек поймет, что лучше взять А — быстро достичь результата и улучшать, отталкиваясь от ситуации. Этот вариант обещает успех сейчас и, возможно, труд в будущем. Вариант Б означает труд сейчас, и, возможно, успех в будущем. Если вы сомневаетесь, я просто развожу руками.
Опыт показывает, что худшее, что можно сделать в ситуации — спорить с упырем. Если молча перетерпеть, он уползет обратно в свое болото, и никто про него не вспомнит. Но если начнёте срач, то сделаете упырю подарок — народ заметит дискуссию, и подключатся посторонние. А кто-то из посторонних, хотите или нет, встанет на сторону упыря.
Ещё хуже — упырь оттянет на себя мнение руководства, и прощай счастливая жизнь. Вас заставят писать два слоя абстракций, которые пригодятся в лучшем случае через три года. Или никогда. Позже упырь уволится, оставив команду с абстрактным кодом. На его место придет новичок, и круг замкнется.
Я к тому, что надо быть очень осторожным, когда в обсуждение залезает подобный персонаж. Неумелыми фразами можно сильно испортить себе жизнь. Ни пуха.
-
(Не) предлагай
Полезный совет. Если вы что-то спрашиваете, иногда полезно сразу предложить варианты, чтобы собеседнику было легче ответить. Этим вы сэкономите ему нервы, и он будет благодарен за помощь.
Пример. У вас нет задач, и вы спрашиваете менеджера, чем заняться. Может быть, менеджер на звонке, у него что-то горит, и прямо сейчас искать задачу некогда. Но открыто сказать “я не знаю” он не может, потому что это вроде не круто. Поэтому к вопросу надо добавить встречное предложение: могу эту задачу и вон ту. Что лучше? Менеджеру остается только выбрать из двух.
Другой пример. Спрашиваете у тимлида (или кто там у вас), какой выбрать технический подход к задаче. Будет невежливо задать вопрос и тупо ждать. Очевидно, тут нужно исследование. По каждому варианту соберите плюсы и минусы, напишите короткий текст и уже с этим идите к тимлиду (или к кому там у вас).
В общем случае это называется “сделать домашку” — заранее выполнить часть работы.
А иногда свои предложения лучше приберечь. Если вы ведёте переговоры или допытываетесь до важной информации, предположения могут всё разрушить. Собеседник рассердится на то, что вы не слушаете и гнёте свою линию. Или ему проще согласиться, чем объяснить сложную тему.
Пример. В разговоре с заказчиком мы давим на технические детали. Internet Explorer уже не используется, нужно мобильное приложение, а код следует очистить от легаси. Пытливый слушатель узнает, что основная аудитория — люди за сорок из госсектора с кнопочными телефонами. А программа должна работать с отечественным кассовым аппаратом по серийному порту.
Еще пример. Ребенок прогуливает школу из-за конфликта со сверстниками. Ему проще согласиться с родителем, что это из-за лени, чем объяснить конфликт. Так родитель остался не в курсе проблем.
Поэтому: иногда предлагай, а иногда не предлагай. По ситуации.
-
Быстрее
Совет тем, кто что-либо организует: делайте всё быстро.
Как проходит школьная линейка? Дети с родителями пришли и ждут. На сцене суетятся, ходят туда-сюда. Начинают с задержкой в двадцать минут. Слово директору. Слово завучу. Слово заслуженной учительнцие. Слово депутату-спонсору-единоросу. Слово ветерану. Потом, худо-бедно, начинается сценка про пропавший огонь знаний.
Как проходят спортивные соревнования? Дети с родителями пришли и ждут. Все на месте, абсолютно все. Нет, тренер ходит с листочком взад-перед. Начинают с опозданием в полчаса. Слово директору. Слово заслуженному тренеру. Гимн России. Потом, худо-бедно, начинаются соревнования.
Главное правило в том, что заложенное время только увеличивается, но никогда не уменьшается. Потеряется переходник, сядут батарейки в микрофоне. Ноут уйдет в перезагрузку (конечно, с обновлением винды). Человек забудет речь и будет повторять один тезис по пять раз. Затяжкой страдают даже мероприятия за деньги, а уж любительские — подавно.
Каждый этап мероприятия надо проводить как можно короче. Например, давать слово только одному человеку, а не трём. Договориться, что тот самый чел составит речь на бумажке и выучит, при этом слово должно быть не больше трех минут. Не может — возьмите другого. Пусть первый напишет, второй говорит.
Начинать всегда вовремя. Многие проблемы можно решить в полете: менять номера местами, что-то пропускать. Для этого нужен помощник и находчивость. Если ни того, ни другого нет, организовывать что-либо ещё рано.
Хорошая организация — забота о зрителях и уважение к ним. Вы наверное думаете, что зрители не замечают хорошее проведение, потому что так везде. Это не так. Если линейка или утренник прошли за сорок минут как по маслу, я обязательно замечу это вслух. И все говорят — да, и дети не устали, организаторы молодцы.
Быстрее надо, быстрее.
Writing on programming, education, books and negotiations.