-
Бан в XBox
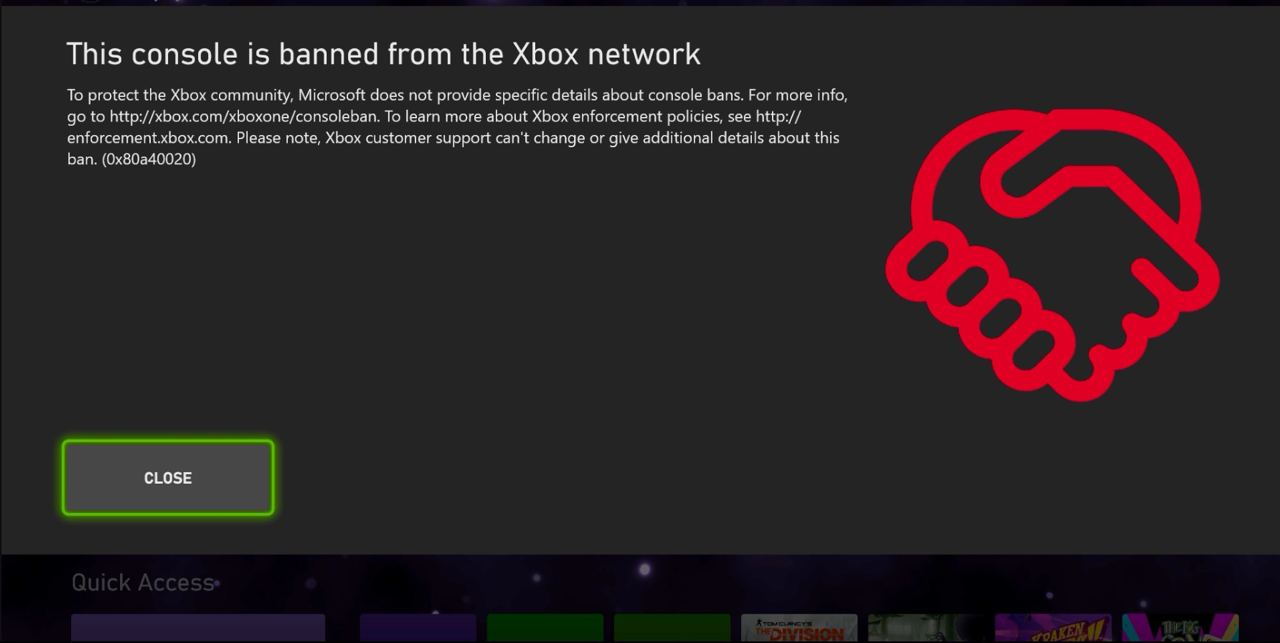
У меня нет приставки, и я почти ни во что не играю (разве что в старые игры на эмуляторе). Однако я не мог пройти мимо такой картинки в интернете. Это скриншот из интерфейса XBox, где написано, что вас забанили.
Удивляет пиктограмма рукопожатия справа. Что было в голове у дизайнера, который ее добавил? Мало того, что забанили клиента без объяснения причины; так еще нарисовали рукопожатие, мол, дружище, без обид, держись там. Бан пройдет, и мы снова будем друзьями.
Тупизна какого-то вселенского масштаба. В точности как все у Микрософта.
-
Warn
Не допускайте, чтобы в коде встречались логи с уровнем warn(ing).
Во-первых, warn, предупреждение, — это ни то, ни сё. Вроде важнее обычного info, но и не ошибка. Что делать? Продолжать вести наблюдение?
Во-вторых, warn — отличный способ отстрелить ногу. В текущем проекте много фоновых задач, и для них используется библиотека-аналог крона. Каждую задачу она оборачивает в try/catch, чтобы не падать, но при этом логирует исключение с уровнем warn. Мол, тут что-то упало, но не беспокойся. Авось в следующий раз повезёт.
Наш логгер устроен так, что только error попадает в Sentry; остальное идёт в файл, который никто не читает. В результате мы прошляпили кучу ошибок в фоновых задачах — просто потому, что автор библиотеки не считает их чем-то важным. Крон работает и хорошо. Подумаешь, половина задач валится, главное, что у меня всё в порядке.
Не надо так.
-
Фрагментация Телеграма
Когда я пользовался VK, меня удивляла фрагментация сущностей. Заметка, пост, фотография, видео и прочее — всё уже не упомню. Были записи на стене, сама стена, группы, форум. Я никогда не мог запомнить, что и где создавать и удивлялся — почему нельзя свести этот зоопарк к “сообщению”? Да, пусть у него будет много полей: гео-теги, фото, видео, ссылки… но это лучше, чем дюжина разных сущностей! Причём не только для программистов, но и для пользователей, потому что заморочки бекенда не будут на них проецироваться.
Ясно, что ВК был клоном Фейсбука (запрещенная организация) и унаследовал его родовые травмы. В свою очередь в Фейсбуке была та же фрагментация, потому что изначально это был закрытый форум. А на форумах до сих пор такая фигня: создать заметку, фотографию, видео.
Учетку VK, ровно как и других соцсетей, я удалил лет семь назад и ни разу не пожалел.
Удвиляет, что при всем идиотизме этой фрагментации она продолжает жить в мессенджерах. Скажем, я написал заметку на лист А4, она прекрасно помещается в Телеграме. Но стоит добавить картинку или видео — размер сокращается в разы, буквально 150 символов или около. Почему? Потому что это уже не “заметка”, а “картинка”. А в чём проблема показать и картинку, и текст? Очевидно, там какие-то заморочки на бекенде — Эрланг, Mnesia, — но какое они имеют значение для меня как пользователя? Никакого.
Чтобы исправить этот косяк, Телеграм сделал Телеграф — сервис анонимных заметок, в котором текст чередуется с картинками. Телеграфные ссылки открываются в Телеграме без перехода в браузер, но в целом это костыль — решили симптом, проблема осталась.
А с недавними сторисами вышел смех и грех. Совершенно бесполезная функция, которую нельзя отключить. Мало того, что это буквальное неуважение к пользователю, так еще чувствуется вторичность и запоздалое заимствование. Телеграм — хороший месаджер, при чём тут какие-то сторис? У нас что, Инстаграм? Полная нелепица.
В итоге происходит следующее: люди уходят из соцсетей в месаджеры, потому что устали от фрагментации контента. Не хочется групп, стен, форумов. Хочется единого потока сообщений. Для некоторых целей это не подходит, но в целом удобно. И тут опять приходит фрагментация. Деление каналов на топики — как же они глючили и кувыркались в первые недели работы! — и сторизы.
Конечно, найдется тот, кто скажет: не нравится — не пользуйся. Но так не работает. Уже построены связи, диалоги, люди стучатся в Телеграм, и слезть с него так просто не выйдет.
Словом, Телеграм плавно становится комбайном, который “может все”, как китайский Ви-чат. Это немного, но огорчает: мне не нужно всё.
Мне нужно чуть-чуть.
-
Parasite Eve
На первой PlayStation была замечательная игра Parasite Eve. И была там музыкальная шкатулка с красивой темой:
Оказывается, это Бах. Всего-то 23 года прошло, прежде чем я это понял.
Кто играл в эту замечательную игру, почтите ее прослушиванием саундтрека.
-
PG docs, part 5. Notifications
(This is a new documentation chapter from the PG project.)
ToC
Notifications
Introduction
Notifications are somewhat pub-sub message systems in Postgres. They can be described in these simple steps:
-
client B subscribes to a channel; the channel gets created if it doesn’t exist.
-
client A sends a message to that channel;
-
every time client B interacts with the database, they receive messages sent to this channel by other clients.
To handle a message, the client invokes a special handler. This handler comes from the configuration. The default handler just prints the notification map. Pay attention that the handler is called synchronously blocking the interaction with a socket. To prevent the connection from hanging due to the time-consuming handling of a notification, provide a handler that sends it to some sort of channel, agent, or message queue system.
-
-
PG docs, part 4. Arrays
(This is a new documentation chapter from the PG project.)
ToC
In JDBC, arrays have always been a pain. Every time you want to pass an array to the database or read it back, you’ve got to wrap your data with various Java classes, extend protocols, and multimethods. We do it in each project, and it doesn’t have to be like this.
The recent release of PG ships a significant feature: arrays. You can pass an array to a query and read it back as easily as they were native Clojure vectors. No more ceremonies with classes, manual parsing, etc.
-
PG docs, part 3
(This is a new documentation chapter from the PG project.)
ToC
Connection Pool
- Basic usage
- With-pool & with-open
- Config
- Thread safety
- Pool Exhausting
- Exception handling
- Logs
- Component
To interact with a database effectively, you need a connection pool. A single connection is fragile on its own: you can easily lose it by an accidental lag in the network.
Another thing that is worth bearing in mind is, that opening a new connection every time you want to reach PostgreSQL is expensive. Every connection starts a new process on the server. If your code opens too many connections, say in a cycle or within threads/futures, sooner or later you’ll reach an error response saying “too many connections”.
The connection pool is an object that holds several open connections at once. It allows you to borrow a connection for some period of time. A borrowed connection can be only used in a block of code that has borrowed it but nowhere else. Once the block of code has done with its duties, the connection gets returned to the pool.
The pool is also capable of calculating the lifetime of connections and their expiration moments. Once a connection has expired, it gets terminated and the pool spawns a new connection.
The connection pool is shipped in a dedicated library
com.github.igrishaev/pg-poolas it depends on the logging facility. -
PG docs, part 2
ToC
In this chapter, we’ll discuss how to reach Postgres using the Client library.
- Basic usage
- Queries
- Execute
- Prepared Statements
- Processing result with :fn-result
- Column names
- Column duplicates
- Reducers and bundles
- Transactions
- Configuration
- Authorization
- Cloning a connection
- Cancelling a query
- Notices
- Thread safety
- Debugging
Basic usage
Here is a brief example of using the client library:
(ns scratch (:require [pg.client :as pg])) (def config {:host "127.0.0.1" :port 5432 :user "test" :password "test" :database "test"}) (pg/with-connection [conn config] (pg/query conn "select 1 as one")) ;; [{:one 1}]First, you import the
pg.clientnamespace which brings the top-level API functions to interact with Postgres. Theconfigmap above specifies the minimal configuration; it might have more fields which we will explore in a separate section.The
with-connectionmacro establishes a new connection, binds it to theconnsymbol, and executes the body. The connection is closed afterward, even if an exception pops up.Technically you can open and terminate a connection manually like this:
(let [conn (pg/connect config) data (pg/query conn "select 1 as one")] (pg/terminate conn) data) ;; [{:one 1}]but it’s not recommended. Also, since the
Connectionobject implementsjava.io.Closeable, it’s possible to use it inwith-open:(with-open [conn (pg/connect config)] (pg/query conn "select 1 as one")) ;; [{:one 1}] -
PG docs, part 1
TL;DR: I’m writing a Postgres driver in pure Clojure. In general, works! Now I proceed with the most miserable part of the project: writing documentation. I decided to do it step by step and share it on my blog.
ToC
About
This project is a set of libraries related to the PostgreSQL database. The primary library called
pg-clientis a driver for Postgres written in pure Clojure. By purity I mean, neither JDBC nor any other third-party Java libraries are involved. Everything is driven by a TCP socket and implementation of the Posrgres Wire protocol. Fun!Besides the client, the project provides such various additions as a connection pool (see
pg-pool). Thepg-typeslibrary holds the encoding and decoding logic which determines how to write and read Clojure data from and into the database. You can use this library separately in pair with JDBC.next andCOPYfor efficient data transcoding in binary format.The question you would probably ask is, why would create a Postgres client from scratch? JDBC has been around for decades, and there are also good
clojure.java.jdbcandjdbc.nextwrappers on top of it?The answer is: that although these two libraries are amazing, they don’t disclose all Postgres features. JDBC is an abstraction whose main goal is to satisfy all the DB engines. A general library that works with MS SQL, MySQL, and Postgres at the same time would reduce the variety of features each backend is capable of.
-
Анонс второй книги

Вышел второй том “Сlojure на производстве” — продолжение первой книги. Без той помпы, что в прошлый раз, когда я каждую неделю выкладывал апдейты, фото черновиков и прочее. На всё это не хватает времени, плюс хочется меньше пафоса.
В книге три главы, черновые версии которых я выкладывал в блоге. Это зипперы, базы данных и REPL. Всё это можно прочесть здесь на сайте, но каждую главу я многократно улучшил. Кроме банальных опечаток, изменилась структура, а примеры стали убедительней.
Книжка выполнена в том же стиле и манере повествования. Текст чередуется с кодом, каждый тезис подтверждается примером. Длинный код разбит на части с пояснением, что происходит. Код “подсвечен” с помощью градаций серого и начертания. Ссылки, коих много по тексту, вынесены в QR-коды на поля.
Твёрдая обложка, B5, 364 страницы. Форматы для мобильных устройств появятся позже. Издано в ДМК-Пресс тиражом в 100 экземпляров. Двадцать из них — мои, полученные в качестве гонорара, и я готов разослать их читателям.
Все подробности – где купить, открывок, галерея – указаны на странице книги.
Writing on programming, education, books and negotiations.