-
AWS, история третья. Разрывы
Все статьи из цикла AWS
- Амазон
- AWS, история первая. Внезапный мегабайт
- AWS, история вторая. Афина прекрасная
- AWS, история третья. Разрывы
- AWS, история четвертая. Когда null не совсем null
В третьей истории расскажу, как я страдал от сетевых проблем в Амазоне. Как абонент Уральский: раньше не было разрывов, а теперь есть разрывы.
У нас в проекте много лямбд, и каждая вызывает другие. При таком раскладе невыгодно передавать результат напрямую. Можно использовать S3 как шину данных. Например, одна лямбда вызывает другую и говорит: положи результат в такой-то бакет и файл. Затем опрашивает файл, пока он не появится.
Это удобно, когда результат огромен: иные лямбды производят CSV-шки по нескольку гигабайт. Не гонять же их напрямую между лямбдами. Но файлы привносят хаос: не всегда очевидно, кто произвел файл и кто его потребители. Если изменить путь, через день придет коллега из другого сервиса и скажет: мы каждый день забираем файл из этой папки, куда он делся? Или наоборот: ты обнаружил, что некий сервис производит удобный файл, в котором все есть. Через месяц он перестал появляться, потому что они переехали на что-то другое. Мы вам ничего не обещали.
Файлы CSV удобно стримить прямо из S3. Послал GET-запрос, получил InputStream. Передал его в парсер и готово: получается ленивая коллекция кортежей. Навесил на нее map/filter, все обработалось как нужно, красота. Не нужно сохранять файл на диск.
То же самое с форматом JSONL, где каждая строка — отдельный объект JSON. Из стрима получаешь Reader, из него ленивый line-seq, и пошел колбасить.
Неожиданно это схема перестала работать с большими файлами. Где-то на середине цикл обрывается с IOException. Чего я только не пробовал: оборачивал стрим в BufferedInputStream с разным размером, засекал время обработки, передавал опции в к S3… ничего не помогло. Запросы в Гугл тоже ничего внятного выдали.
У меня подозрение, что дело в неравномерном чтении. Когда вы читаете файл, Амазон определяет скорость забора байтиков. Поскольку мы читаем и обрабатываем стрим в одном потоке, чтение чередуется с простоем на обработку данных. В больших файлах я нашел записи, которые больше других во много раз. Возможно, что когда обработка доходила до них, ожидание было больше среднего, и Амазон закрывал соединение.
Я пытался повторить это на публичных файлах S3: читал в цикле N байтов и где-то на середине ставил длинный Thread/sleep. Но S3 покорно ждал аж две минуты, и эксперимент провалился.
Словом, я так и не выяснил, почему вылазит IOException, но смог это исправить в два шага.
Первый — файл S3 тупо записывается во временный файл, и дальше с ним работаешь локально. Перенос стрима делается одним методом
InputStream.transferTo. Во время переноса ошибки связи не возникают.Второй — иные агрегаты достигают 3.5 гигабайтов, а у лямбды ограничение на 10 гигабайтов места. Скачал три агрегата — и привет, out of disk space. Поэтому при записи файл кодируется Gzip-ом, а при чтении — декодируется обратно.
Все вместе дало мне функцию, которая:
- посылает запрос к S3, получает стрим
- создает временный файл
- переносит стрим в файл, попутно сжимая Gzip-ом
- возвращает
GzipInputStreamиз файла
Со стороны кажется, что вызвал
get-s3-reader— и байтики потекли, делов-то. А внутри вот какие штучки.Примечательно, что в одном проекте я сам спровоцировал
IOException. Разработчик до меня позаботился о переносе файла S3 во временный файл. Я подумал, что он просто не знает, как обработать данные из сети и убрал запись на диск. Возможно, он что-то знал, но не оставил комментария. А надо было!Из этой истории следует: никогда не обрабатывайте файл S3 сразу из сети. Сохраните его во временный файл и потом читайте локально — так надежней. Рано или поздно вы схватите
IOException, а на расследование будет времени. Чтобы сэкономить диск, оберните файл в Gzip.
На этом я закончу истории про Амазон. У меня есть еще несколько, но они не такие интересные и сводятся к тезису “думал так, а оно эдак”. Ну и обсасывать одну и ту же тему уже не хочется.
Думаю, вы поняли, что в Амазоне хватает странностей. Это не баги, потому что все они описаны в документации. Примерно как в Javascript: никто не знает, почему
{} + [] = 0, а[] + {} = [object Object]. Да, в стандарте описано, но кому от этого легче? Выбирая Амазон, закладывайте время и деньги на подобные непонятки. -
AWS, история вторая. Афина прекрасная
Все статьи из цикла AWS
- Амазон
- AWS, история первая. Внезапный мегабайт
- AWS, история вторая. Афина прекрасная
- AWS, история третья. Разрывы
- AWS, история четвертая. Когда null не совсем null
Расскажу о еще одном случае с AWS, который стоил мне пару бессонных ночей.
В Амазоне есть славный сервис Athena — супер-пупер агрегатор всего и вся. Он тащит терабайты данных из разных источников, обрабатывает и складывает в другие сервисы. Хадуп на стероидах. По-русски читается “Афина”.
Мы пользуемся им так. Есть лямбда, которая складывает в S3 сущности в JSON. Сущностей более миллиона. Другим сервисам нужны все сущности разом — и оказывается, выгрести их из S3 невозможно.
Почему? Даже если предположить, что за секунду мы скачаем 10 сущностей параллельно (что невозможно), за 900 секунд мы получим 9000 сущностей, что меньше одного процента. А нам нужно не девять тысяч, а миллион. Напомню, что 900 секунд — это 15 минут, максимальное время работы лямбды.
Архитектуру дизайнил не я, поэтому не спрашивайте, почему так.
На помощь приходит Афина. Мы говорим ей: склей все JSON файлы из бакета в один и положи туда-то. Афине, при всей мощи Амазона, нужно на это 4 минуты. Чудес не бывает, и чтобы забрать из S3 миллион файлов, Амазону нужно попотеть.
В ответ на нашу просьбу Афина дает айдишник задания, и мы его поллим. Готово? Нет. Готово? Нет. Готово? Да. И если да, в ответе будет ссылка на файл-агрегат.
Таких агрегатов у нас несколько, и я столкнулся с тем, что лямбда не укладывается в 15 минут. Если тратить по 4 минуты на агрегат, то на ожидание трёх уйдёт 12 минут. Процессинг файлов занимает еще 5-6 минут, и готово — ты не успел.
Тратить 12 минут впустую глупо, поэтому я сделал поллинг Афины параллельным. В самом деле, зачем ждать 4 минуты, если можно запустить второй поллинг? Логично же? Но вот к чему это привело.
Кто-то заметил, что в отчетах стали появляться “дырки”, то есть пустые ячейки. С точки зрения кода это выглядит так, словно в агрегате не было записей. Сначала я отнеткивался, но потом проверил размеры агрегатов. Оказалось, что сегодняшний файл, собранный Афиной, в два раза меньше вчерашнего. Или наоборот: вчера ок, а сегодня половина. Файл не битый, открывается, просто в нем половина данных.
После гуглений, осбуждений и вырванных волос обнаружились сразу три бага.
Первый — разработчик, который писал код до меня, допустил ошибку. Он поллил Афину по условию “пока статус pending”. Если что-то другое, он читал результат. Оказалось, что у задачи может быть три статуса: pending, ready и error. И в нашем случае статус был error.
Второй — даже если задача в статусе error, она содержит ссылку на собранный файл. Да, Афина не смогла, и файл собран частично. Считается, что это лучше, чем ничего.
Третий — в чем была причина error? Напомню, что я запускал в Афине несколько задач параллельно. Каждая задача собирала файлы из S3. В итоге сработал лимит на доступ к S3 — он ответил, что кто-то слишком часто обращается ко мне, убавьте пыл, господа. Поэтому задача упала.
Интересно, что S3 не волнует, что обращается к нему не сторонний потребитель, а сама Афина. При всем абсурде я считаю это правильным, потому что если лимит задан, он должен соблюдаться глобально, без поблажек “для своих”.
В итоге я сделал следующее. Все отчеты, которые обращаются к Афине, я разнес по времени с разницей в 5-10 минут. Раньше они стартовали одновременно, что порождало много задач в Афину, а та насиловала S3. С разницей по времени стало легче.
Потом я додумался до решения лучше. Сделал фейковый warmup-отчет, который работает как прогрев кеша. Он запускается первым и триггерит все задачи в Афине. Когда другим отчетам что-то нужно из Афины, они проверяют, была ли задача с такими параметрами за последние 2 часа. Если да, ссылка на агрегат берется из старой задачи.
Вот такая она, борьба с AWS. Перечитываю и понимаю, что, хоть и звучит умно, хвастаться здесь нечем. Не будь этой архитектуры, результат обошелся бы дешевле. Усилия потрачены, но неясно зачем.
Я пишу комментарии к коду, надеясь, что следующий разработчик поймет хоть толику все этой котовасии. Но не особо на это надеюсь: скорее всего, он скажет — что это наговнокодили такое? Пойду переделаю. И все повторится.
-
AWS, история первая. Внезапный мегабайт
Все статьи из цикла AWS
- Амазон
- AWS, история первая. Внезапный мегабайт
- AWS, история вторая. Афина прекрасная
- AWS, история третья. Разрывы
- AWS, история четвертая. Когда null не совсем null
Прошлая заметка про AWS была затравкой. Теперь расскажу о случаях в Амазоне, от которых трещали мозги.
Первая история касается сервиса Lambda. Он выполняет произвольный код на любом языке и возвращает результат. Особенность Лямбды в том, что клиент платит только за те ресурсы, что потребил. Считаются время процессора, память и диск в секунду. Если не вызывать Лямбду, ее стоимость будет нулевой.
Это выгодно отличает Лямбду от EC2, за который клиент платит всегда. Наверное, все видели мемы про бомжа, который скатился в бедность, не выключив инстанс EC2.
Кто-то считает, что Лямбда — простой сервис, но это не так. Наоборот, он один из самых сложных в AWS. Он работает как огромная очередь задач. Лямбду можно скрестить с HTTP-сервером, чтобы принимать сообщения прямо из браузера. Лямбду можно прицепить к любому сервису AWS в качестве реакции на что угодно. Загрузили файл в S3 — вызвалась лямбда. Отправили сообщеньку в очередь — вызвалась лямбда и так далее.
Я работаю в проекте, в котором все на лямбдах. Раньше мне казалось это фантасмагорией, но со временем привыкаешь. В порядке вещей, когда лямбда дергает лямбду, которая дергает лямбду, которая дергает лямбду. Постепенно видишь в этом особый шарм.
У лямбды жесткие лимиты, которые нельзя нарушать. Время работы не может быть дольше 15 минут. Если его превысить, лямбда умирает и запускается опять. Максимальное число повторов — 4. Ответ не может быть больше 6 мегабайтов. В теле может быть только текст, бинарные данные запрещены.
Про размер тела я и хотел рассказать.
Одна из лямбд распухла и стала отдавать JSON, который не пролазил в 6 мегабайтов. Это нетрудно поправить. Нужно сжать тело Gzip-ом и обернуть в base64. Зачем? Как я сказал, в теле не может быть бинарь, потому что данные передаются в JSON. Такой вот костылик, но что поделаешь.
Не обошлось без приключений: клиенты лямбды использовали кривую библиотеку, которая не учитывала сжатие Gzip. Пришлось починить ее тоже: проверять Content- Encoding и оборачивать стрим, если там gzip. В общем, кое-как все подружились, и сообщения пошли как надо. Как-то раз я задался вопросом: какого размера был тот ответ, что не влез в лимит?
Добавил лог с размером JSON до сжатия. Оказалось, он был 5.2 мегабайта.
Может быть, не всем понятно это противоречие, но я впал в ступор. Сказано ясно: тело не больше 6 мегабайтов, а у нас 5. Почему сообщение не проходит? Откуда лишний мегабайт? Это страшно взволновало меня: происходит какая-то фигня, о которой я не догадываюсь.
Я полез в интернет и выяснил, что какой-то бедняга уже наступал на эти грабли. На StackOverflow нашелся вопрос, и автор долго искал ответа. Он даже писал сводки с апдейтами! Были разные предположения, в том числе такие, что AWS дописывает мету в сообщения. Но не мегабайт же! Они что, Анну Каренину в заголовках передают?
На сегодняшний день у вопроса 21 тысяча просмотров и ни одного верного ответа (за исключением моего). Этот вопрос был скопирован в сервис Repost.AWS — базу знаний AWS, и там тоже ничего не сказали по делу. Это доказывает: в Амазоне бывает нечто, что никто не может объяснить.
Мысль о лишнем мегабайте не отпускала меня. И вот однажды, прогуливаясь, я все понял.
Когда лямбда отдает HTTP-сообщение, она строит примерно такой ответ. В его теле — строка JSON с данными:
return HTTPResponse( 200, body=json.encode(data), content_type="application/json" )На этом работа программы кончается. А что происходит с ответом? Он перестраивается в такой словарик:
{:statusCode 200, :body <JSON-string>, :headers {"content-type" "application/json"}}Потом словарик кодируется в JSON и отправляется в дебри AWS, которые называются Lambda Runtime API. Это очередь, которая отвечает за прием и отдачу сообщений. Ваша лямбда — клиент, который забирает оттуда сообщеньки и рапортует об исполнении. Примерно как Consumer в Кафке.
Теперь про этот мегабайт. Напомню, что до кодирования наш словарик выглядел так (кложурный синтаксис):
{:statusCode 200, :body "{\"foo\":{\"bar\":[\"a\",\"b\",\"c\"]}}", :headers {"Content-Type" "application/json"}}Далее он кодируется в JSON. А в поле
:bodyуже закодированный JSON! Получается двойное кодирование: данные перегнали в JSON первый раз, чтобы получить текстовое поле body, а потом еще раз, чтобы закодировать верхний словарь! При кодировании JSON происходит экранирование некоторых символов. Например, если в строке двойная кавычка, перед ней будет обратный слэш. Покажу это на примере:(pg.json/write-string "aaa \" bbb") "\"aaa \\\" bbb\""Интересно, сколько же будет этих слэшей? Примерно x2 от числа ключей в словарях и строк в значениях. Например, если в словаре два ключа и в значениях строки, то слэшей получится 8. Легко посчитать отношение длины JSON с одним и двойным кодированием. Оно получится примерно 1.4:
(-> {:foo {:bar [:a :b :c]}} pg.json/write-string count) 29 (-> {:foo {:bar [:a :b :c]}} pg.json/write-string pg.json/write-string count) 41 (/ 41.0 29) 1.4137931034482758Проверим это на больших файлах. В интернете нашелся большой публичный JSON. Вот цифры для него:
(-> "https://github.com/seductiveapps/largeJSON/raw/master/100mb.json" java.net.URL. slurp pg.json/read-string pg.json/write-string count) 60129867 (-> "https://github.com/seductiveapps/largeJSON/raw/master/100mb.json" java.net.URL. slurp pg.json/read-string pg.json/write-string pg.json/write-string count) 70361681 (/ 70361681.0 60129867) 1.170161926351841Коэффициент вышел 1.17, а размер вырос аж на 10 мегабайтов.
Резюмируя: двойное JSON-кодирование прибавляет от 5 до 17% к длине строки. Прибавка состоит из обратных слэшей из-за экранирования кавычек. В моем случае было примерно 800 Кб слешей. 5.3 + 0.8 = 6.1 мегабайтов. Все сходится. Напоминает шутку про украденный код на Lisp, где были одни закрывающие скобки. Тут то же самое, только слэши.
Вот такая штука. Когда все шаги пройдены, она не кажется загадкой, но как же напрягала тогда! Ее нельзя назвать багом, потому что документация не врет: шесть мегабайтов. Но дело в том, что эти шесть мегабайтов касаются финального сообщения, которое уходит в Runtime API. Это не длина данных, что возвращает ваш код, вот в чем дело. И конечно, документация ничего не знает о двойном кодировании и проблеме слэшей.
Важно понять: если вы отдаете HTTP-сообщеньки из Лямбды, и в теле JSON, вы кодируете его дважды. Это добавляет 5-17% процентов от исходной длины. Лучше сразу использовать Gzip+base64, чтобы не выстрелить в ногу.
Итак, с лямбдой разобрались. В следующей заметке будет кулстори про AWS Athena (читается “Афина”). Там тоже трещали мозги.
-
Амазон
Все статьи из цикла AWS
- Амазон
- AWS, история первая. Внезапный мегабайт
- AWS, история вторая. Афина прекрасная
- AWS, история третья. Разрывы
- AWS, история четвертая. Когда null не совсем null
Последние три года я плотно работают с Амазоном. Все больше утверждаюсь в мысли: для своих нужд я никогда не возьму Амазон, какими бы пряниками он меня не заманивал.
Двадцать лет назад, когда я только познакомился с AWS, он был набором сервисов. Если тогда это был город, то сегодня он — целая планета. Число сервисов выросло на порядок или два, усложнилось взаимодействие между ними.
Разрабатывая на AWS, важно иметь особый навык — знание AWS. Языка программирования и базы данных уже недостаточно. Нужно понимать концепции AWS, систему прав и полиси, квоты и много чего другого.
В фирме редко бывает человек, который знает AWS целиком. Чаще всего каждый, как муравей, видит маленький ландшафтик, и когда начинаются проблемы взаимодействия, их тяжело расследовать.
AWS — это дичайший вендор-лок, то есть зависимость от поставщика. Байки на тему “посидим и слезем” остаются байками. Амазон, как пылесос, со временем перетягивает на себя все решения — файлы, базу, сообщения — и портировать их обратно очень дорого.
Важно понимать, что второго Амазона в мире нет. Бывают сервисы, которые повторяют некоторые API Амазона, например S3. Но переехать на что-то другое целиком будет очень затратно, причем даже не в плане денег, а нервов.
Амазон дорогой. Разумеется, я не могу назвать, сколько платят заказчики, но это весьма дорого даже по западным меркам. Реляционные базы данных — дорогие. Лямбды, если их вызывать постоянно — дорогие. Если использовать S3 как шину данных между сервисами, это тоже дорого.
Пожалуй, моя главная претензия к AWS — его трудно имитировать локально. Когда у вас Постгрес и Редис, все это запускается в Докере и покрывает 99% случаев. Постгрес в Докере — это настоящий Постгрес, тот самый, что работает на серверах. Любую ситуацию можно повторить локально: блокировку транзакций, медленный запрос, загрузку миллиарда записей, попадание в индекс.
С Амазоном так не получится: сервисы DynamoDB, SNS/SQS или Athena нельзя запустить в Докере. Можно заткнуть их имитацией, которая выплевывает нужный JSON, но… это имитация. В проде случается масса вещей, о которых вы и не подозревали.
Для разработки под Амазон нужно dev-окружение. Это такой же Амазон, только он не пересекается с продом. Там своя база, инстансы, очереди задач. Вы пишете код, заливаете в Амазон, гоняете и смотрите логи. Что-то упало — исправляете код и все по-новой. Это долго, потому что каждый шаг выполняется не мгновенно, а по нескольку минут.
Разумеется, dev-окружение тарифицируется как обычное. За все нужно платить. Кроме прода, заказчик платит за 5-10 dev-окружений. Если вы расчитываете стоимость AWS, умножайте хотя бы на два, чтобы заложить бюджет на dev-окружения.
Амазон радует крайне неочевидным поведением. Не могу назвать его багами, потому что оно описано в докуменации. Но документация огромна, читать ее никогда, да и требует усилий. Каждый раз, разобравшись, думаешь: ну все, теперь сюрпризов не будет. И буквально через два дня — новая головоломка.
В следующих заметках я расскажу о случаях с AWS, над которыми изрядно поломал голову. Надеюсь, они будут кому-то полезны и сэкономят нервы.
-
Авито (2)
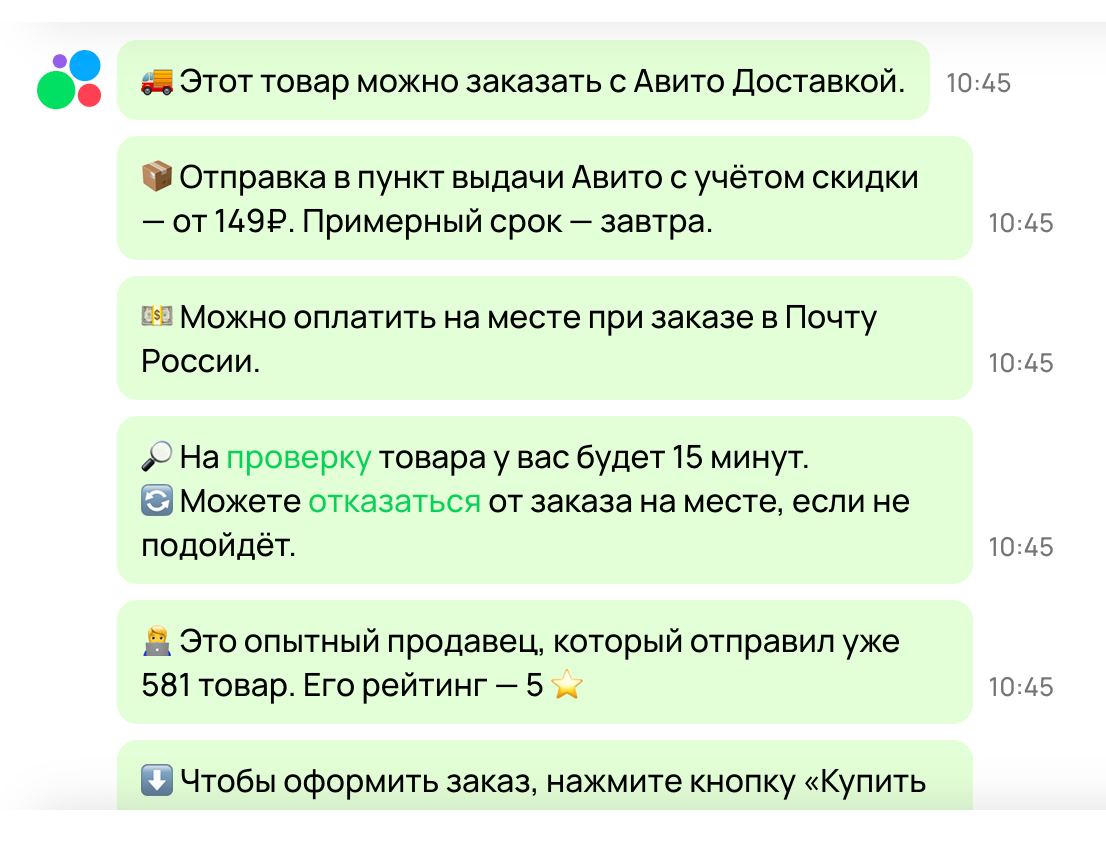
Уж простите за спам про Авито, но я не могу, правда. Это какой-то лол.
Продавец выставил серию книг, и я спрашиваю, есть ли среди них такая. Что делает бот Авито? Он выплевывает 7 сообщений о том, что:
- можно купить с доставкой
- сроки отправки
- сколько занимает проверка товара
- рейтинг продавца
- куда нажать, чтобы купить
И остальное, что не влезло на скриншот, хотя информация есть на странице, и я ее прекрасно вижу. Самую мелочь — есть ли книга или нет — я так и не узнал.
Как же все это душит. Казалось бы, пройдя все авторизации и преграды, можно спросить человека и получить живой ответ. Но Авито не оставляет шансов: и здесь поджидает бот, который засрет переписку бессмыслицей. И не только Авито, конечно.
Все это нежно, мягко, с заботой, но поддушивает.
-
Авито (1)
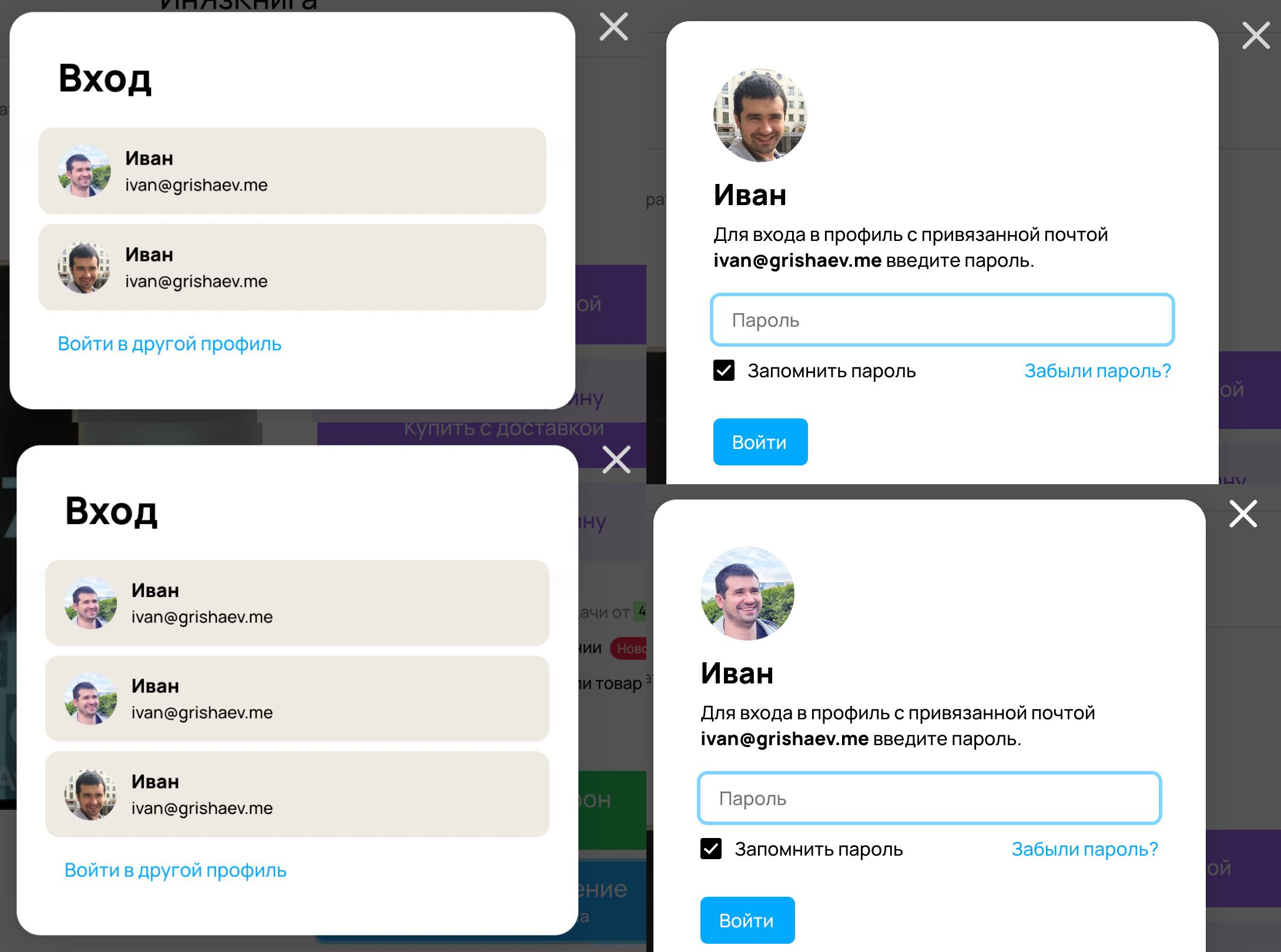
Не знаю, что курят в Авито, но система допускает два профиля с одинаковой почтой, и я должен выбрать один из них. Может, это из-за разных клиентов: десктоп и телефон? Или из кеша пришли левые данные? Это неважно: техническое объяснение всегда найдется. Но так быть не должно.
-
Авторизация оскорбляет
Раньше двойная авторизация работала так: ставишь приложение на телефон, сканируешь QR-код и получаешь генерилку кодов. Сайт запрашивает код, ты вводишь, все довольны.
Теперь сервисы отходят от это схемы. Даже если ты включил двойную авторизацию, сайт предложит зайти в другое приложение той же фирмы. Например, чтобы зайти в Гмейл, открой Ютуб. Или открой наше мобильное приложение (Гитхаб, Яндекс). Вариант с кодом прячут под выпадашку “другие способы”.
Меня оскорбляет такой подход. Я заморачивался, ставил эти коды и считаю их безопасней, чем вход в другое приложение. Тем не менее, сервис понизил приоритет у кодов и предлагает способ для домохозяек. Не надо так.
-
ИИ-ревью
Верьте аль не верьте, но в одном проекте у нас было ИИ-ревью. Слушайте.
Фирма назначила нового технического директора. Уже первый разговор с ним посеял тревогу. Его технический стек не имел отношения к тому, что был у нас. Он сходу предложил перейти на MongoDB — оставив за кадром факт, что переезд с гигантской базы Постгреса занял бы несколько лет. Он много говорил о Chat GPT и о том, как ИИ-ревью изменит наши процессы.
Начальство дало добро, и техдир провел три месяца, настраивая ИИ-ревью. Если вкратце, оно работало так.
Нашелся бот на Node.js, который парсит дифф и выдирает изменения. Бот крутится в CI и запускается на каждом коммите.
Выдрав изменения и собрав контекст, бот отправлял все добро в Chat GPT и составлял отчет.
Этот отчет добавлялся в комментарий к пулл-реквесту.
Звучит круто, а что было на самом деле? Это выглядело так. По каждому файлу бот писал: добавлена такая-то функция, переименован такой-то параметр, функция foo-bar теперь принимает три аргумента, а не два. И все таком духе: человекоподобное описание изменений. Ниже он писал вердикт — хороши ли изменения или требуют доработки.
Постарайтесь это представить: в пул-реквесте пятнадцать файлов, и по каждому бот пишет абзац текста. Получается портянка на два экрана, совершенно тупая и бесполезная. Что с того, что написано “добавлена новая функция”? Я из без бота вижу, что она добавлена. Вполне может быть, что похожая функция уже есть, либо это могло быть inline-выражение, либо есть лучшая версия этой функции в библиотеке? Бот ничего об этом не знал.
Открывая PR, ты первым делом видел выхлоп ИИ на два экрана. Нужно было проматывать эту фигню, чтобы добраться до кода.
Получилась своего рода версия PR для менеджеров. Ну, знаете, бывает версия для слабовидящих, а есть версия для менеджеров. Менеджер не может прочесть код, и система генерит ему описание: добавилось то, убавилось это. Читая выхлоп, менеджер думает, что понимает код, хотя это не так. Он понимает действие, но не понимает причины, не понимает смысла, который стоит за этим кодом.
Чтобы портянка на два экрана не мешала, я стал удалять ее из PR. В том числе не только из своих PR, но и коллег, если меня просили сделать ревью. Открывая PR, я рассчитываю увидеть код, а не машинный выхлоп, пусть даже его произвел ИИ. И знаете, никто не жаловался на удаление. Скоро я заметил, что коллеги молча удаляют этот комментарий без моего вмешательства.
Стоит ли говорить, что бот ничего не знал о безопасности и хороших практиках. Он спокойно пропускал места, где SQL-параметр подставлялся склейкой строк. Он ничего не знал о reflection warning, о кривых запросах, неэффективных циклах, запросах мимо индекса.
Удивлял его вердикт: бот мог написать “все отлично” к файлу, к которому у меня было три претензии. Мог написать “требует доработки” к файлу, где все гладко. Само собой, без каких-либо объяснений, что именно требует доработок и каких.
Получался молчаливый бойкот: разработчики не обращали внимания на бота, техдир ничего в Кложе не понимал, а бот не давал ответа на вопрос, хороший мы пишем код или нет.
Добавлю, что еще раньше техдир хотел подключить в CI сторонний говносервис, который делает то же самое. К счастью, в списке поддерживаемых языков не было Кложи.
И вот однажды бота отключили. Я не стал спрашивать о причинах: они были очевидны. ИИ-ревью не оправдало себя, а директор потратил три месяца на его настройку. Ничего не изменилось в лучшую сторону, стало только хуже, потому что добавился новый компонент, усложнился CI, были потрачены деньги. Позже директора уволили.
В чем была его ошибка? В том, что он не мог четко объяснить, какую проблему он решал с помощью ИИ. Я уже писал про это: принимаясь за задачу, спрашивай себя, какую проблему ты решаешь. В том проекте у нас было хорошее ревью: никто не затягивал процесс, сложные диффы смотрели несколько человек. В команде была компетенция в плане Кложи и SQL. Словом, ревью было последним местом, куда бы я внедрил ИИ.
Вот что бывает, когда за дело берутся менеджеры. Их стремление автоматизировать понятно: вдруг человек уйдет, а мы такие внедрили ИИ, и ладушки: он с нами навсегда. Увы, это не работает: есть процессы, которые должен выполнять человек. Всякие ИИ могут быть страховкой, но не более того.
-
1Password все
Вот и все, что нужно знать про менеджеры паролей. Однажды тебе скажут: создавай облачную учетку или иди лесом. 1Password упорно шел в этом направлении, так что не удивлен. Я и раньше знал, что восьмая версия не работает без облака и сидел на шестой. Теперь она насильно обновилась.
К счастью, уже два года переехал на Unix Pass и планирую об этом написать.
-
PG2 release 0.1.4: HoneySQL API and shortcuts
Table of Content
PG2 version 0.1.4 is out. In this release, the main feature is improvements made to the
pg-honeypackage which is a wrapper on top of HoneySQL.HoneySQL Integration & Shortcuts
The
pg-honeypackage allows you to callqueryandexecutefunctions using maps rather than string SQL expressions. Internally, maps are transformed into SQL using the great HoneySQL library. With HoneySQL, you don’t need to format strings to build a SQL, which is clumsy and dangerous in terms of injections.The package also provides several shortcuts for such common dutiles as get a single row by id, get a bunch of rows by their ids, insert a row having a map of values, update by a map and so on.
For a demo, let’s import the package, declare a config map and create a table with some rows as follows:
(require '[pg.honey :as pgh]) (def config {:host "127.0.0.1" :port 10140 :user "test" :password "test" :dbname "test"}) (def conn (pg/connect config)) (pg/query conn "create table test003 ( id integer not null, name text not null, active boolean not null default true )") (pg/query conn "insert into test003 (id, name, active) values (1, 'Ivan', true), (2, 'Huan', false), (3, 'Juan', true)")Get by id(s)
The
get-by-idfunction fetches a single row by a primary key which is:idby default:(pgh/get-by-id conn :test003 1) ;; {:name "Ivan", :active true, :id 1}With options, you can specify the name of the primary key and the column names you’re interested in:
(pgh/get-by-id conn :test003 1 {:pk [:raw "test003.id"] :fields [:id :name]}) ;; {:name "Ivan", :id 1} ;; SELECT id, name FROM test003 WHERE test003.id = $1 LIMIT $2 ;; parameters: $1 = '1', $2 = '1'The
get-by-idsfunction accepts a collection of primary keys and fetches them using theINoperator. In additon to options thatget-by-idhas, you can specify the ordering:(pgh/get-by-ids conn :test003 [1 3 999] {:pk [:raw "test003.id"] :fields [:id :name] :order-by [[:id :desc]]}) [{:name "Juan", :id 3} {:name "Ivan", :id 1}] ;; SELECT id, name FROM test003 WHERE test003.id IN ($1, $2, $3) ORDER BY id DESC ;; parameters: $1 = '1', $2 = '3', $3 = '999'Passing many IDs at once is not recommended. Either pass them by chunks or create a temporary table,
COPY INids into it andINNER JOINwith the main table.Delete
The
deletefunction removes rows from a table. By default, all the rows are deleted with no filtering, and the deleted rows are returned:(pgh/delete conn :test003) [{:name "Ivan", :active true, :id 1} {:name "Huan", :active false, :id 2} {:name "Juan", :active true, :id 3}]You can specify the
WHEREclause and the column names of the result:(pgh/delete conn :test003 {:where [:and [:= :id 3] [:= :active true]] :returning [:*]}) [{:name "Juan", :active true, :id 3}]When the
:returningoption set tonil, no rows are returned.Insert (one)
To observe all the features of the
insertfunction, let’s create a separate table:(pg/query conn "create table test004 ( id serial primary key, name text not null, active boolean not null default true )")The
insertfunction accepts a collection of maps each represents a row:(pgh/insert conn :test004 [{:name "Foo" :active false} {:name "Bar" :active true}] {:returning [:id :name]}) [{:name "Foo", :id 1} {:name "Bar", :id 2}]It also accepts options to produce the
ON CONFLICT ... DO ...clause known asUPSERT. The following query tries to insert two rows with existing primary keys. Should they exist, the query updates the names of the corresponding rows:(pgh/insert conn :test004 [{:id 1 :name "Snip"} {:id 2 :name "Snap"}] {:on-conflict [:id] :do-update-set [:name] :returning [:id :name]})The resulting query looks like this:
INSERT INTO test004 (id, name) VALUES ($1, $2), ($3, $4) ON CONFLICT (id) DO UPDATE SET name = EXCLUDED.name RETURNING id, name parameters: $1 = '1', $2 = 'Snip', $3 = '2', $4 = 'Snap'The
insert-onefunction acts likeinsertbut accepts and returns a single map. It supports:returningandON CONFLICT ...clauses as well:(pgh/insert-one conn :test004 {:id 2 :name "Alter Ego" :active true} {:on-conflict [:id] :do-update-set [:name :active] :returning [:*]}) {:name "Alter Ego", :active true, :id 2}The logs:
INSERT INTO test004 (id, name, active) VALUES ($1, $2, TRUE) ON CONFLICT (id) DO UPDATE SET name = EXCLUDED.name, active = EXCLUDED.active RETURNING * parameters: $1 = '2', $2 = 'Alter Ego'Update
The
updatefunction alters rows in a table. By default, it doesn’t do any filtering and returns all the rows affected. The following query sets the booleanactivevalue for all rows:(pgh/update conn :test003 {:active true}) [{:name "Ivan", :active true, :id 1} {:name "Huan", :active true, :id 2} {:name "Juan", :active true, :id 3}]The
:whereclause determines conditions for update. You can also specify columns to return:(pgh/update conn :test003 {:active false} {:where [:= :name "Ivan"] :returning [:id]}) [{:id 1}]What is great about
updateis, you can use such complex expressions as increasing counters, negation and so on. Below, we alter the primary key by adding 100 to it, negate theactivecolumn, and change thenamecolumn with dull concatenation:(pgh/update conn :test003 {:id [:+ :id 100] :active [:not :active] :name [:raw "name || name"]} {:where [:= :name "Ivan"] :returning [:id :active]}) [{:active true, :id 101}]Which produces the following query:
UPDATE test003 SET id = id + $1, active = NOT active, name = name || name WHERE name = $2 RETURNING id, active parameters: $1 = '100', $2 = 'Ivan'Find (first)
The
findfunction makes a lookup in a table by column-value pairs. All the pairs are joined using theANDoperator:(pgh/find conn :test003 {:active true}) [{:name "Ivan", :active true, :id 1} {:name "Juan", :active true, :id 3}]Find by two conditions:
(pgh/find conn :test003 {:active true :name "Juan"}) [{:name "Juan", :active true, :id 3}] ;; SELECT * FROM test003 WHERE (active = TRUE) AND (name = $1) ;; parameters: $1 = 'Juan'The function accepts additional options for
LIMIT,OFFSET, andORDER BYclauses:(pgh/find conn :test003 {:active true} {:fields [:id :name] :limit 10 :offset 1 :order-by [[:id :desc]] :fn-key identity}) [{"id" 1, "name" "Ivan"}] ;; SELECT id, name FROM test003 ;; WHERE (active = TRUE) ;; ORDER BY id DESC ;; LIMIT $1 ;; OFFSET $2 ;; parameters: $1 = '10', $2 = '1'The
find-firstfunction acts the same but returns a single row ornil. Internally, it adds theLIMIT 1clause to the query:(pgh/find-first conn :test003 {:active true} {:fields [:id :name] :offset 1 :order-by [[:id :desc]] :fn-key identity}) {"id" 1, "name" "Ivan"}Prepare
The
preparefunction makes a prepared statement from a HoneySQL map:(def stmt (pgh/prepare conn {:select [:*] :from :test003 :where [:= :id 0]})) ;; <Prepared statement, name: s37, param(s): 1, OIDs: [INT8], SQL: SELECT * FROM test003 WHERE id = $1>Above, the zero value is a placeholder for an integer parameter.
Now that the statement is prepared, execute it with the right id:
(pg/execute-statement conn stmt {:params [3] :first? true}) {:name "Juan", :active true, :id 3}Alternately, use the
[:raw ...]syntax to specify a parameter with a dollar sign:(def stmt (pgh/prepare conn {:select [:*] :from :test003 :where [:raw "id = $1"]})) (pg/execute-statement conn stmt {:params [1] :first? true}) {:name "Ivan", :active true, :id 1}Query and Execute
There are two general functions called
queryandexecute. Each of them accepts an arbitrary HoneySQL map and performs eitherQueryorExecuterequest to the server.Pay attention that, when using
query, a HoneySQL map cannot have parameters. This is a limitation of theQuerycommand. The following query will lead to an error response from the server:(pgh/query conn {:select [:id] :from :test003 :where [:= :name "Ivan"] :order-by [:id]}) ;; Execution error (PGErrorResponse) at org.pg.Accum/maybeThrowError (Accum.java:207). ;; Server error response: {severity=ERROR, ... message=there is no parameter $1, verbosity=ERROR}Instead, use either
[:raw ...]syntax or{:inline true}option:(pgh/query conn {:select [:id] :from :test003 :where [:raw "name = 'Ivan'"] ;; raw (as is) :order-by [:id]}) [{:id 1}] ;; OR (pgh/query conn {:select [:id] :from :test003 :where [:= :name "Ivan"] :order-by [:id]} {:honey {:inline true}}) ;; inline values [{:id 1}] ;; SELECT id FROM test003 WHERE name = 'Ivan' ORDER BY id ASCThe
executefunction acceps a HoneySQL map with parameters:(pgh/execute conn {:select [:id :name] :from :test003 :where [:= :name "Ivan"] :order-by [:id]}) [{:name "Ivan", :id 1}]Both
queryandexecuteaccept notSELECTonly but literally everything: inserting, updating, creating a table, an index, and more. You can build combinations likeINSERT ... FROM SELECTorUPDATE ... FROM DELETEto perform complex logic in a single atomic query.HoneySQL options
Any HoneySQL-specific parameter might be passed through the
:honeysubmap in options. Below, we pass the:paramsmap to use the[:param ...]syntax. Also, we produce a pretty-formatted SQL for better logs:(pgh/execute conn {:select [:id :name] :from :test003 :where [:= :name [:param :name]] :order-by [:id]} {:honey {:pretty true :params {:name "Ivan"}}}) ;; SELECT id, name ;; FROM test003 ;; WHERE name = $1 ;; ORDER BY id ASC ;; parameters: $1 = 'Ivan'For more options, please refer to the official HoneySQL documentation.
Writing on programming, education, books and negotiations.