-
Сервисы
Приходилось работать в проекте со множеством сервисов. Решил пожаловаться, какое же это неблагодарное дело — выскребать данные по углам, чтобы собрать конфету.
Ощущение, что сервисы делают люди, лишенные эмпатии. Например, есть метод
get-by-id, чтобы взять сущность по айдишке. Угадайте, сколько сервисов поддерживаютget-by-idS— получить список по айдишкам? В лучшем случае половина. У оставшейся половиныget-by-idsвозвращает сущности порциями по сто. Тебе нужно 250? Пиши обертку с пагинацией,next-page,limit/offset, вот это все.Вызывал сервис несколько тысяч раз? Начинаются разборки “кто нас дидосит”. Вызывай редко, не больше десяти раз, а еще лучше никогда. И везде проблемы с сообщением об ошибке. Передал что-то не то — иди смотри логи.
Я согласен с тем, что логику нужно разносить по сервисам. Но сервисы должны использовать общую шину данных: базу, очередь сообщений, файлы в S3 в конце концов. Гонять друг другу JSON выглядит хорошо в теории, но на практике — фу.
Условный Постгрес выплюнет миллион записей за доли секунды. Забрать этот же миллион из другого сервиса — приключение на неделю. Тут и метрики, лимиты, квоты, сетевые спайки, etc… А когда таких запросов несколько, сервис ложится спать.
Эти сервисы напоминают современного айтишника: хрупкого, тряпковатого мужчину 25 лет, который чуть что — выгорает. У которого все токсичны и вообще — отстаньте.
Удивляет, что подобные архитектуры строятся намеренно, и их создателям платят большие деньги. При этом опция “легкий доступ к данным” в архитектуру не входит.
А мне разгребать.
-
Карго-культ (2)
В комментариях к прошлой заметке один из читателей заметил, что эксперимент с обезьянами — выдумка и никогда не проводился. Похоже, он прав!
Впервые эксперимент упоминется в книге Competing for the Future by Gary Hamel and C. K. Prahalad. Вот дословная цитата:
4 monkeys in a room. In the center of the room is a tall pole with a bunch of bananas suspended from the top. One of the four monkeys scampers up the pole and grabs the bananas. Just as he does, he is hit with a torrent of cold water from an overhead shower. He runs like hell back down the pole without the bananas. Eventually, the other three try it with the same outcome. Finally, they just sit and don’t even try again. To hell with the damn bananas. But then, they remove one of the four monkeys and replace him with a new one. The new monkey enters the room, spots the bananas and decides to go for it. Just as he is about to scamper up the pole, the other three reach out and drag him back down. After a while, he gets the message. There is something wrong, bad or evil that happens if you go after those bananas. So, they kept replacing an existing monkey with a new one and each time, none of the new monkeys ever made it to the top. They each got the same message. Don’t climb that pole. None of them knew exactly why they shouldn’t climb the pole, they just knew not to. They all respected the well established precedent. EVEN AFTER THE SHOWER WAS REMOVED!
Эксперимент зашел публике, и его стали широко использовать. Позже несколько людей пытались узнать подробности: кто и когда проводил этот эксперимент. Но один из авторов умер, а второй отвечал отписками через секретаря. Самое интересное, что удалось из него выжать:
Our apologies, but Professor Hamel does not have the original source information at hand in terms of your request.
Похоже, эксперимент был выдуман авторами, чтобы придать вес другой идее. Возможно, они слышали что-то краем уха от зоологов, а остальное додумали. Надо иметь в виду, что книга написана в 1996 году, когда интернет был убогим, и проверить информацию было невозможно.
Напоминает историю про 25 кадр, который, в отличие от обезьян, был полностью развенчан.
Я получил урок, что все популярные истории нужно проверять. Не так уж и трудно было погуглить несколько минут. Александру, который написал об этом, больше спасибо.
См. обсуждение на Stack Exchange.
-
Карго-культ (1)
Возможно, не все знают, как работает карго-культ у обезьян. А это очень интересно.
В вольер с обезьянами вешают приманку: всякие сласти и ништяки. Если к ней притронуться, обезьян обливают холодной водой. Из-за своей физиологии им это очень неприятно, гораздо неприятней, чем людям.
Обезьяны быстро понимают, что приманку трогать нельзя. Когда в вольер подсаживают новую обезьяну, старожилы запрещают ей приближаться к приманке.
Дальше самое интересное: постепенно из вольера убирают обезьян, которых обливали. Остаются те, которым только запрещали трогать приманку, но которые не знают последствий. И все равно: они рьяно запрещают подходить к приманке новичкам.
Мораль — команда не должна быть обезьянами в вольере. Все запреты нужно время от времени пересматривать, чтобы не растить карго-культ. Удивляет, как часто я слышу объяснение в духе “мы делаем так, потому что мы так делаем”. Пусть не все, но некоторое из этого нужно сесть и пересмотреть.
Сказанное не значит, что нужно быть бунтарем и расшатывать основы. Здоровый баланс между крайностями — вот что нужно соблюдать.
-
Лук
Что ж, таки подъехал новый лук от Гугла. И не соврали: современный и прочувственный, что бы это ни значило.
Главное, теперь мы знаем: форму даже с одним импутом можно растянуть на 80 процентов площади. Дизайнерам воздушных интерфейсов взять на заметку.
-
Firefox и обновления
У меня сложные отношения с Firefox. Все как в песне: мое тело говорит да, но мое сердце говорит нет. Иногда я пытаюсь начать с чистого листа, но Firefox делает все, чтобы этого не случилось.
Когда вышел Хром, он поразил меня отладочной консолью. Сегодня это норма, но тогда, десять лет назад, нигде не было такого легкого доступа к сетевым запросам, логам и реплу Javascript. В FF было что-то на голову ниже, но в виде плагина, а тут — из коробки. Пока писал, вспомнил — Firebug, вот как он назывался.
Когда FF догнал Хром плане консоли, я пользовался им какое-то время. Потом устроился в фирму, где были токены Yubikey. В Хроме они работали из коробки, а что в FF? Надо скачать и поставить OpenSCP, затем добавить девайс в FF и прописать путь к бинарнику. Сам он не может. В итоге худо-бедно работало, но с перебоями и перезапуском браузера. Вернулся в Хром.
Сегодня я работаю в фирме, где тоже выдают Yubikey. Я открыл FF, и он сходу кидает модалку, которая просит пароль к токену. Минуточку, кто тебя просил? Нет ни одной вкладки, которая просит авторизации. Зачем кидаешь модалку? Тем более что токен нужен bash-скрипту для VPN, а в браузере он не используется. Какой-то бред.

Ладно, стерпим и это. Но с какой-то версии FF запретил опцию “не ставить обновления”. Либо они ставятся автоматом, либо браузер долбит мозг постоянной плашкой “вышел апдейт, поставь немедленно”. А у меня пунктик — если программа кричит об обновлениях, я либо отключаю их, либо не пользуюсь программой. И отключить никак не выходит.
Я пошел в
about://configи прошелся по всем атрибутам, содержащим “update” в названии. Таковых нашлось штук двадцать. Менял так и этак, ставил 0, -1 и false — ничего не помогает. Проклятая плашка регулярно вылазит.Похоже, опять не судьба выстроить отношения с FF, но я все-таки спрошу. Как в FF ставить обновления по требованию? Чтобы я нажал “install update” и оно обновилось, а до этого молчало? Неужели Firefox, наше все, звезда опенсорса и все такое, больше на это не способен?
Верю, что способен. Вам слово.
-
Firefox и полиси
На выходных посидел с Firefox. Понял, как заблокировать обновления, а также много чего другого.
Если коротко: демократия закончилась. Начиная с какой-то версии Firefox перешел на систему полиси для расширенных настроек. Редактор about:config по-прежнему работает, но нужно понимать: многие опции теперь — бутафория. Можете до посинения что-то включать и выключать, эффекта не будет.
Теперь Firefox работает с полиси. Это JSON-файл с директивами, которые включают ту или иную функцию. По сравнению с about:config преимущество в коллекциях: в полиси можно задать массив объектов, например, для настройки расширений или mime-типов, а в
about:configвсе было плоским.Полиси описаны в формате JSON, но на Маке используется яблочный формат plist. Может быть, JSON тоже можно, но я не проверял.
Преимущество полиси в том, что можно задать поведение браузера до последних мелочей. И все это — в текстовом файле, который хранится в Github. Не нужна облачная учетка для синхронизации — вы сами решаете, как раскидывать файл по машинам. Я положил в приватный dotfiles, но приведу копию ниже.
Firefox не пытается оспорить то, что указано в полиси. Если сказано не ставить обновления — он не ставит. Сказано не проверять браузер по умолчанию — не проверяет. Никаких попапов, бейджей, нотификаций, алертов, всплывающих полосок и прочей ахинеи.
Теперь технические шаги. Все примеры будут под мак; на другие системы, думаю, переложить будет не трудно.
Firefox ищет полиси в разных местах, но самое очевидное — файл
~/Library/ Preferences/org.mozilla.firefox.plist. ОпцияEnterprisePoliciesEnabledозначает, использовать ли полиси или пропускать их. Установите ее в истину командой:defaults write ~/Library/Preferences/org.mozilla.firefox EnterprisePoliciesEnabled -bool TRUEОбратите внимание, что расширение
.plistуказывать не нужно.Чтобы выключить обновления, задайте
DisableAppUpdateв истину:defaults write ~/Library/Preferences/org.mozilla.firefox DisableAppUpdate -bool trueПерезапустите браузер и откройте About Firefox или настройки — там будет следующее:

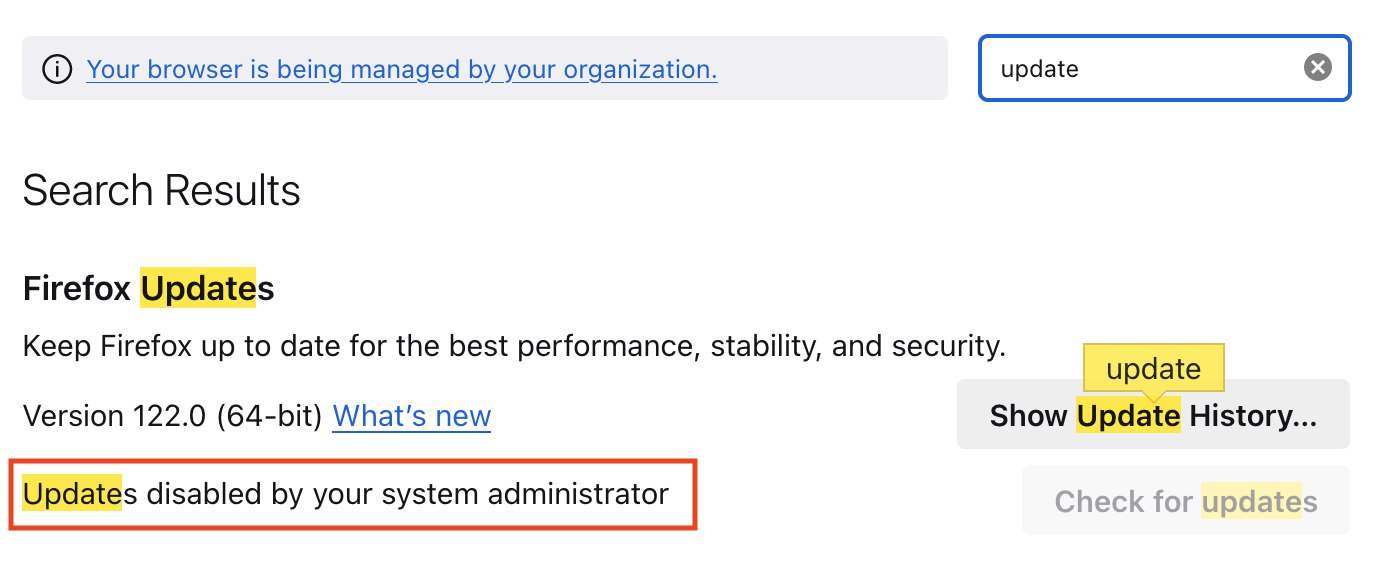
Обновления запрещены, никто не пройдет.
Список полиси можно посмотреть во вкладке
about:policies. Выглядит так: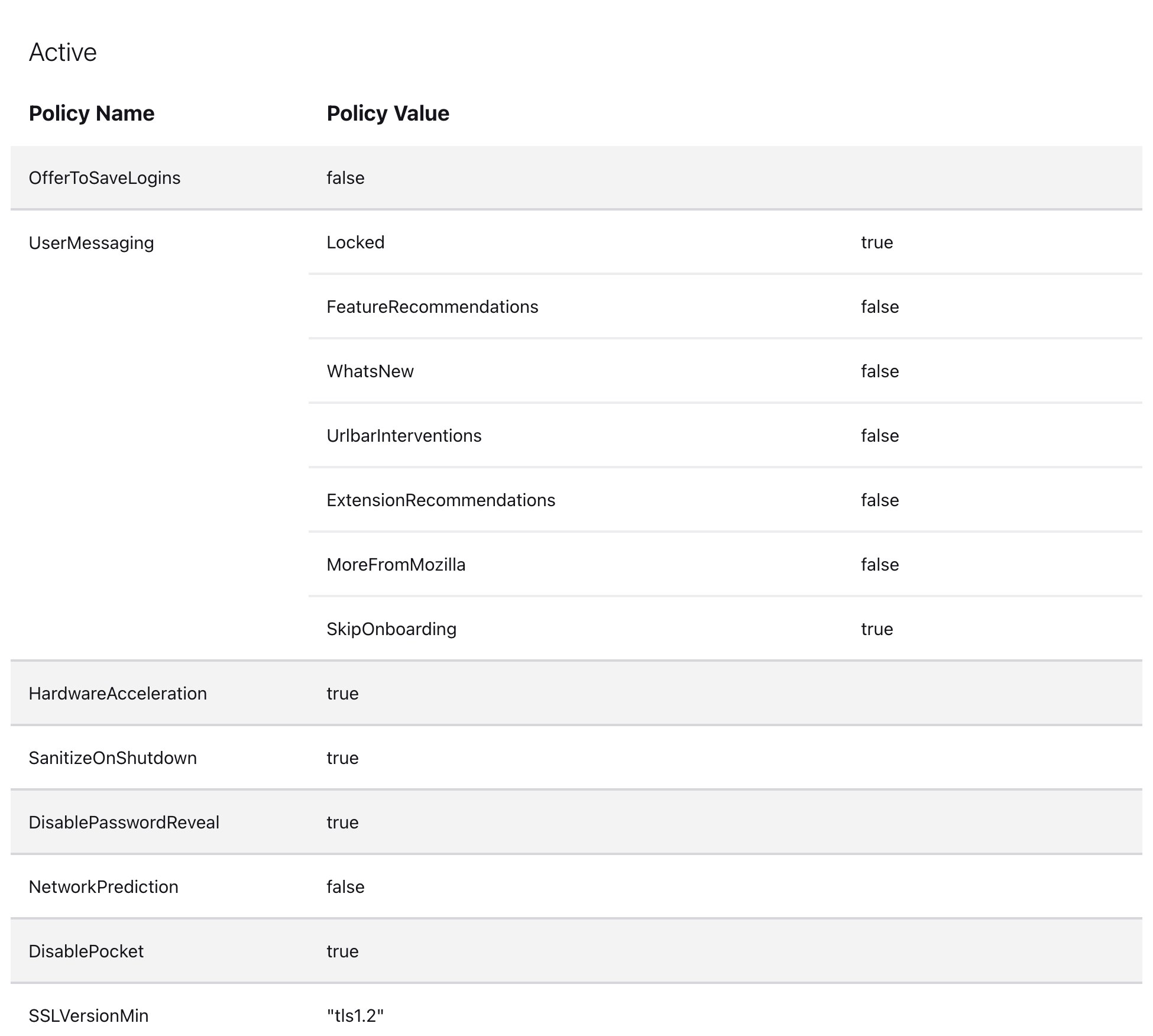
Назревает два вопроса. Первый: как узнать, какие полиси есть в принципе и их значения? Второй: ты предлагаешь вводить их в консоли вручную?
Полный список полиси находится на этой странице, и он довольно велик. Проще скачать заголовку под вашу систему и поправить руками. Названия директив говорят сами за себя.
По второму пункту — разумеется, нужно создать файл в редакторе, но в случае с plist есть нюанс. Файлы plist бывают двух форматов: текстовый и бинарный. В первом случае это XML с тегами
<plist>,<dict>и<key>. Во втором случае там байты вперемешку с текстом.Беда в том, что Firefox работает только с бинарным plist: если положить текстовый, он его игнорирует. Бинарник можно поправить в XCode, но это неудобно: не станете же вы хранить бинарь в Github и редактировать программой, которой нужно 15 гигов. К счастью, утилита plutil умеет импорт-экспорт, а заодно проверяет формат на корректность.
У меня получилась папка в dotfiles со следующими файлами. Прежде всего это org.mozilla.firefox.plist, который я выложил в Gist. Вот неполный список того, что он делает:
- отключает обновления
- отключает проверку браузера по умолчанию
- отключает менеджер паролей, мастер-пароль
- отключает Pocket
- убирает партнерские ссылки, top-sites и прочий шлак на главной
- открывает PDF-файлы в Preview.app. Для меня это важно, потому что встроенные открывашки PDF, как правило, убогие
- отключает всякий трекинг и фингерпринт
- включает запросы нотификаций, локации
- блокирует попапы
- отключает “что новенького”, рекомендованные расширения, фичи.
Второй файл — конфиг Make, чтобы управлять конфигурацией. Он короткий, приведу полностью:
DOMAIN = ~/Library/Preferences/org.mozilla.firefox.plist SOURCE = org.mozilla.firefox.plist policy-import: policy-check defaults import ${DOMAIN} ${SOURCE} policy-false: defaults write ${DOMAIN} EnterprisePoliciesEnabled -bool FALSE policy-true: defaults write ${DOMAIN} EnterprisePoliciesEnabled -bool TRUE policy-check: plutil ${SOURCE}Команда
policy-importпереносит настройки из текстового .plist-файла в бинарный в домашней папке. Она зависит отpolicy-check, которая проверяет конфигурацию на корректность.Команды
policy-falseиpolicy-trueотключают и включают полиси. Дело в том, что пока они включены, вы не можете обновиться даже если захотите — функция запрещена. Чтобы это сделать, отключите полиси, перезапустите браузер, обновитесь, затем снова включите. На короткое время ужаснитесь тому, как жили раньше: браузер выплюнет сто попапов, что пора обновиться, сделать его главным по умолчанию, а вот здесь у нас новая менюшка, а вот новое расширение, ну и все такое.В общем, разобраться с полиси было полезно. По аналогии с Емаксом и прочими утилитами, я храню конфиг в дотфайлах и синхронизирую через Гитхаб. Опасение вызывает лишь то, что полиси все еще на этапе разработки. Не ровен час, обновишься — и все слетит.
Вроде бы хороший конец, но все равно — с толикой грусти. Эта борьба вызвана тем, что некие придурки спрятали опции из интерфейса. Не будь придурков — не было бы суеты, конфигов и прочего. Энтропия и трение — вот есть то, что здесь описано.
Напоследок — ссылки:
-
Файлы с мака на винду
Небольшая заметка, чтобы в будущем не искать в интернете.
Предположим, нужно перенести большой файл с мака на виндоуз. Сеть не настроена, файлы не пошарены, настроить все это займет час. В распоряжении есть флешка большой емкости, но вот засада:
-
файловая система NTFS на маке работает только для чтения;
-
яблочная файловая система APFS не видна в винде;
-
файловая система FAT32 работает в обоих средах, но не поддерживает файлы больше двух гигабайт.
Что же делать? Можно поставить продвинутый архиватор с поддержкой мульти-архивов. Это когда архив делится на тома foobar.zip.01, 02 и так далее заданной величины. Но ставить софт очень не хочется.
Оказывается, все утилиты есть в коробке. На маке делаем так:
split -b 2024m SomeMovie.mkv SomeMovie.mkv.Последний аргумент с точкой — шаблон нарезанных кусков. К ним будут добавлены строки aa, ab, ac и так далее для правильной сортировки. Если исходный файл был 5 гигабайтов, получатся файлы
SomeMovie.mkv.aa,SomeMovie.mkv.abиSomeMovie.mkv.ac.Скидываем все добро на флешку, и теперь с FAT32 не будет проблем, потому что каждый кусок не превышает два гига. Чтобы собрать файл на винде, запускаем команду:
copy /b SomeMovie.mkv.* SomeMovie.mkvОчевидно, это нужно делать не на флешке, а на жестком диске. Можно положить рядом батник, если собирать будете не вы.
Польза способа в том, что не нужен сторонний софт, права администратора и прочая ахинея. Просто работает.
UPD: в комментариях к написли про exFat, а я про него как-то забыл. Действительно, с ним все работает. Поэтому все, что описано выше, пригодится, если флешка мала. Например, когда нужно перетащить файл на 16 гигов, а флешка только два.
-
-
AWS, история третья. Разрывы
Все статьи из цикла AWS
- Амазон
- AWS, история первая. Внезапный мегабайт
- AWS, история вторая. Афина прекрасная
- AWS, история третья. Разрывы
- AWS, история четвертая. Когда null не совсем null
В третьей истории расскажу, как я страдал от сетевых проблем в Амазоне. Как абонент Уральский: раньше не было разрывов, а теперь есть разрывы.
У нас в проекте много лямбд, и каждая вызывает другие. При таком раскладе невыгодно передавать результат напрямую. Можно использовать S3 как шину данных. Например, одна лямбда вызывает другую и говорит: положи результат в такой-то бакет и файл. Затем опрашивает файл, пока он не появится.
Это удобно, когда результат огромен: иные лямбды производят CSV-шки по нескольку гигабайт. Не гонять же их напрямую между лямбдами. Но файлы привносят хаос: не всегда очевидно, кто произвел файл и кто его потребители. Если изменить путь, через день придет коллега из другого сервиса и скажет: мы каждый день забираем файл из этой папки, куда он делся? Или наоборот: ты обнаружил, что некий сервис производит удобный файл, в котором все есть. Через месяц он перестал появляться, потому что они переехали на что-то другое. Мы вам ничего не обещали.
Файлы CSV удобно стримить прямо из S3. Послал GET-запрос, получил InputStream. Передал его в парсер и готово: получается ленивая коллекция кортежей. Навесил на нее map/filter, все обработалось как нужно, красота. Не нужно сохранять файл на диск.
То же самое с форматом JSONL, где каждая строка — отдельный объект JSON. Из стрима получаешь Reader, из него ленивый line-seq, и пошел колбасить.
Неожиданно это схема перестала работать с большими файлами. Где-то на середине цикл обрывается с IOException. Чего я только не пробовал: оборачивал стрим в BufferedInputStream с разным размером, засекал время обработки, передавал опции в к S3… ничего не помогло. Запросы в Гугл тоже ничего внятного выдали.
У меня подозрение, что дело в неравномерном чтении. Когда вы читаете файл, Амазон определяет скорость забора байтиков. Поскольку мы читаем и обрабатываем стрим в одном потоке, чтение чередуется с простоем на обработку данных. В больших файлах я нашел записи, которые больше других во много раз. Возможно, что когда обработка доходила до них, ожидание было больше среднего, и Амазон закрывал соединение.
Я пытался повторить это на публичных файлах S3: читал в цикле N байтов и где-то на середине ставил длинный Thread/sleep. Но S3 покорно ждал аж две минуты, и эксперимент провалился.
Словом, я так и не выяснил, почему вылазит IOException, но смог это исправить в два шага.
Первый — файл S3 тупо записывается во временный файл, и дальше с ним работаешь локально. Перенос стрима делается одним методом
InputStream.transferTo. Во время переноса ошибки связи не возникают.Второй — иные агрегаты достигают 3.5 гигабайтов, а у лямбды ограничение на 10 гигабайтов места. Скачал три агрегата — и привет, out of disk space. Поэтому при записи файл кодируется Gzip-ом, а при чтении — декодируется обратно.
Все вместе дало мне функцию, которая:
- посылает запрос к S3, получает стрим
- создает временный файл
- переносит стрим в файл, попутно сжимая Gzip-ом
- возвращает
GzipInputStreamиз файла
Со стороны кажется, что вызвал
get-s3-reader— и байтики потекли, делов-то. А внутри вот какие штучки.Примечательно, что в одном проекте я сам спровоцировал
IOException. Разработчик до меня позаботился о переносе файла S3 во временный файл. Я подумал, что он просто не знает, как обработать данные из сети и убрал запись на диск. Возможно, он что-то знал, но не оставил комментария. А надо было!Из этой истории следует: никогда не обрабатывайте файл S3 сразу из сети. Сохраните его во временный файл и потом читайте локально — так надежней. Рано или поздно вы схватите
IOException, а на расследование будет времени. Чтобы сэкономить диск, оберните файл в Gzip.
На этом я закончу истории про Амазон. У меня есть еще несколько, но они не такие интересные и сводятся к тезису “думал так, а оно эдак”. Ну и обсасывать одну и ту же тему уже не хочется.
Думаю, вы поняли, что в Амазоне хватает странностей. Это не баги, потому что все они описаны в документации. Примерно как в Javascript: никто не знает, почему
{} + [] = 0, а[] + {} = [object Object]. Да, в стандарте описано, но кому от этого легче? Выбирая Амазон, закладывайте время и деньги на подобные непонятки. -
AWS, история вторая. Афина прекрасная
Все статьи из цикла AWS
- Амазон
- AWS, история первая. Внезапный мегабайт
- AWS, история вторая. Афина прекрасная
- AWS, история третья. Разрывы
- AWS, история четвертая. Когда null не совсем null
Расскажу о еще одном случае с AWS, который стоил мне пару бессонных ночей.
В Амазоне есть славный сервис Athena — супер-пупер агрегатор всего и вся. Он тащит терабайты данных из разных источников, обрабатывает и складывает в другие сервисы. Хадуп на стероидах. По-русски читается “Афина”.
Мы пользуемся им так. Есть лямбда, которая складывает в S3 сущности в JSON. Сущностей более миллиона. Другим сервисам нужны все сущности разом — и оказывается, выгрести их из S3 невозможно.
Почему? Даже если предположить, что за секунду мы скачаем 10 сущностей параллельно (что невозможно), за 900 секунд мы получим 9000 сущностей, что меньше одного процента. А нам нужно не девять тысяч, а миллион. Напомню, что 900 секунд — это 15 минут, максимальное время работы лямбды.
Архитектуру дизайнил не я, поэтому не спрашивайте, почему так.
На помощь приходит Афина. Мы говорим ей: склей все JSON файлы из бакета в один и положи туда-то. Афине, при всей мощи Амазона, нужно на это 4 минуты. Чудес не бывает, и чтобы забрать из S3 миллион файлов, Амазону нужно попотеть.
В ответ на нашу просьбу Афина дает айдишник задания, и мы его поллим. Готово? Нет. Готово? Нет. Готово? Да. И если да, в ответе будет ссылка на файл-агрегат.
Таких агрегатов у нас несколько, и я столкнулся с тем, что лямбда не укладывается в 15 минут. Если тратить по 4 минуты на агрегат, то на ожидание трёх уйдёт 12 минут. Процессинг файлов занимает еще 5-6 минут, и готово — ты не успел.
Тратить 12 минут впустую глупо, поэтому я сделал поллинг Афины параллельным. В самом деле, зачем ждать 4 минуты, если можно запустить второй поллинг? Логично же? Но вот к чему это привело.
Кто-то заметил, что в отчетах стали появляться “дырки”, то есть пустые ячейки. С точки зрения кода это выглядит так, словно в агрегате не было записей. Сначала я отнеткивался, но потом проверил размеры агрегатов. Оказалось, что сегодняшний файл, собранный Афиной, в два раза меньше вчерашнего. Или наоборот: вчера ок, а сегодня половина. Файл не битый, открывается, просто в нем половина данных.
После гуглений, осбуждений и вырванных волос обнаружились сразу три бага.
Первый — разработчик, который писал код до меня, допустил ошибку. Он поллил Афину по условию “пока статус pending”. Если что-то другое, он читал результат. Оказалось, что у задачи может быть три статуса: pending, ready и error. И в нашем случае статус был error.
Второй — даже если задача в статусе error, она содержит ссылку на собранный файл. Да, Афина не смогла, и файл собран частично. Считается, что это лучше, чем ничего.
Третий — в чем была причина error? Напомню, что я запускал в Афине несколько задач параллельно. Каждая задача собирала файлы из S3. В итоге сработал лимит на доступ к S3 — он ответил, что кто-то слишком часто обращается ко мне, убавьте пыл, господа. Поэтому задача упала.
Интересно, что S3 не волнует, что обращается к нему не сторонний потребитель, а сама Афина. При всем абсурде я считаю это правильным, потому что если лимит задан, он должен соблюдаться глобально, без поблажек “для своих”.
В итоге я сделал следующее. Все отчеты, которые обращаются к Афине, я разнес по времени с разницей в 5-10 минут. Раньше они стартовали одновременно, что порождало много задач в Афину, а та насиловала S3. С разницей по времени стало легче.
Потом я додумался до решения лучше. Сделал фейковый warmup-отчет, который работает как прогрев кеша. Он запускается первым и триггерит все задачи в Афине. Когда другим отчетам что-то нужно из Афины, они проверяют, была ли задача с такими параметрами за последние 2 часа. Если да, ссылка на агрегат берется из старой задачи.
Вот такая она, борьба с AWS. Перечитываю и понимаю, что, хоть и звучит умно, хвастаться здесь нечем. Не будь этой архитектуры, результат обошелся бы дешевле. Усилия потрачены, но неясно зачем.
Я пишу комментарии к коду, надеясь, что следующий разработчик поймет хоть толику все этой котовасии. Но не особо на это надеюсь: скорее всего, он скажет — что это наговнокодили такое? Пойду переделаю. И все повторится.
-
AWS, история первая. Внезапный мегабайт
Все статьи из цикла AWS
- Амазон
- AWS, история первая. Внезапный мегабайт
- AWS, история вторая. Афина прекрасная
- AWS, история третья. Разрывы
- AWS, история четвертая. Когда null не совсем null
Прошлая заметка про AWS была затравкой. Теперь расскажу о случаях в Амазоне, от которых трещали мозги.
Первая история касается сервиса Lambda. Он выполняет произвольный код на любом языке и возвращает результат. Особенность Лямбды в том, что клиент платит только за те ресурсы, что потребил. Считаются время процессора, память и диск в секунду. Если не вызывать Лямбду, ее стоимость будет нулевой.
Это выгодно отличает Лямбду от EC2, за который клиент платит всегда. Наверное, все видели мемы про бомжа, который скатился в бедность, не выключив инстанс EC2.
Кто-то считает, что Лямбда — простой сервис, но это не так. Наоборот, он один из самых сложных в AWS. Он работает как огромная очередь задач. Лямбду можно скрестить с HTTP-сервером, чтобы принимать сообщения прямо из браузера. Лямбду можно прицепить к любому сервису AWS в качестве реакции на что угодно. Загрузили файл в S3 — вызвалась лямбда. Отправили сообщеньку в очередь — вызвалась лямбда и так далее.
Я работаю в проекте, в котором все на лямбдах. Раньше мне казалось это фантасмагорией, но со временем привыкаешь. В порядке вещей, когда лямбда дергает лямбду, которая дергает лямбду, которая дергает лямбду. Постепенно видишь в этом особый шарм.
У лямбды жесткие лимиты, которые нельзя нарушать. Время работы не может быть дольше 15 минут. Если его превысить, лямбда умирает и запускается опять. Максимальное число повторов — 4. Ответ не может быть больше 6 мегабайтов. В теле может быть только текст, бинарные данные запрещены.
Про размер тела я и хотел рассказать.
Одна из лямбд распухла и стала отдавать JSON, который не пролазил в 6 мегабайтов. Это нетрудно поправить. Нужно сжать тело Gzip-ом и обернуть в base64. Зачем? Как я сказал, в теле не может быть бинарь, потому что данные передаются в JSON. Такой вот костылик, но что поделаешь.
Не обошлось без приключений: клиенты лямбды использовали кривую библиотеку, которая не учитывала сжатие Gzip. Пришлось починить ее тоже: проверять Content- Encoding и оборачивать стрим, если там gzip. В общем, кое-как все подружились, и сообщения пошли как надо. Как-то раз я задался вопросом: какого размера был тот ответ, что не влез в лимит?
Добавил лог с размером JSON до сжатия. Оказалось, он был 5.2 мегабайта.
Может быть, не всем понятно это противоречие, но я впал в ступор. Сказано ясно: тело не больше 6 мегабайтов, а у нас 5. Почему сообщение не проходит? Откуда лишний мегабайт? Это страшно взволновало меня: происходит какая-то фигня, о которой я не догадываюсь.
Я полез в интернет и выяснил, что какой-то бедняга уже наступал на эти грабли. На StackOverflow нашелся вопрос, и автор долго искал ответа. Он даже писал сводки с апдейтами! Были разные предположения, в том числе такие, что AWS дописывает мету в сообщения. Но не мегабайт же! Они что, Анну Каренину в заголовках передают?
На сегодняшний день у вопроса 21 тысяча просмотров и ни одного верного ответа (за исключением моего). Этот вопрос был скопирован в сервис Repost.AWS — базу знаний AWS, и там тоже ничего не сказали по делу. Это доказывает: в Амазоне бывает нечто, что никто не может объяснить.
Мысль о лишнем мегабайте не отпускала меня. И вот однажды, прогуливаясь, я все понял.
Когда лямбда отдает HTTP-сообщение, она строит примерно такой ответ. В его теле — строка JSON с данными:
return HTTPResponse( 200, body=json.encode(data), content_type="application/json" )На этом работа программы кончается. А что происходит с ответом? Он перестраивается в такой словарик:
{:statusCode 200, :body <JSON-string>, :headers {"content-type" "application/json"}}Потом словарик кодируется в JSON и отправляется в дебри AWS, которые называются Lambda Runtime API. Это очередь, которая отвечает за прием и отдачу сообщений. Ваша лямбда — клиент, который забирает оттуда сообщеньки и рапортует об исполнении. Примерно как Consumer в Кафке.
Теперь про этот мегабайт. Напомню, что до кодирования наш словарик выглядел так (кложурный синтаксис):
{:statusCode 200, :body "{\"foo\":{\"bar\":[\"a\",\"b\",\"c\"]}}", :headers {"Content-Type" "application/json"}}Далее он кодируется в JSON. А в поле
:bodyуже закодированный JSON! Получается двойное кодирование: данные перегнали в JSON первый раз, чтобы получить текстовое поле body, а потом еще раз, чтобы закодировать верхний словарь! При кодировании JSON происходит экранирование некоторых символов. Например, если в строке двойная кавычка, перед ней будет обратный слэш. Покажу это на примере:(pg.json/write-string "aaa \" bbb") "\"aaa \\\" bbb\""Интересно, сколько же будет этих слэшей? Примерно x2 от числа ключей в словарях и строк в значениях. Например, если в словаре два ключа и в значениях строки, то слэшей получится 8. Легко посчитать отношение длины JSON с одним и двойным кодированием. Оно получится примерно 1.4:
(-> {:foo {:bar [:a :b :c]}} pg.json/write-string count) 29 (-> {:foo {:bar [:a :b :c]}} pg.json/write-string pg.json/write-string count) 41 (/ 41.0 29) 1.4137931034482758Проверим это на больших файлах. В интернете нашелся большой публичный JSON. Вот цифры для него:
(-> "https://github.com/seductiveapps/largeJSON/raw/master/100mb.json" java.net.URL. slurp pg.json/read-string pg.json/write-string count) 60129867 (-> "https://github.com/seductiveapps/largeJSON/raw/master/100mb.json" java.net.URL. slurp pg.json/read-string pg.json/write-string pg.json/write-string count) 70361681 (/ 70361681.0 60129867) 1.170161926351841Коэффициент вышел 1.17, а размер вырос аж на 10 мегабайтов.
Резюмируя: двойное JSON-кодирование прибавляет от 5 до 17% к длине строки. Прибавка состоит из обратных слэшей из-за экранирования кавычек. В моем случае было примерно 800 Кб слешей. 5.3 + 0.8 = 6.1 мегабайтов. Все сходится. Напоминает шутку про украденный код на Lisp, где были одни закрывающие скобки. Тут то же самое, только слэши.
Вот такая штука. Когда все шаги пройдены, она не кажется загадкой, но как же напрягала тогда! Ее нельзя назвать багом, потому что документация не врет: шесть мегабайтов. Но дело в том, что эти шесть мегабайтов касаются финального сообщения, которое уходит в Runtime API. Это не длина данных, что возвращает ваш код, вот в чем дело. И конечно, документация ничего не знает о двойном кодировании и проблеме слэшей.
Важно понять: если вы отдаете HTTP-сообщеньки из Лямбды, и в теле JSON, вы кодируете его дважды. Это добавляет 5-17% процентов от исходной длины. Лучше сразу использовать Gzip+base64, чтобы не выстрелить в ногу.
Итак, с лямбдой разобрались. В следующей заметке будет кулстори про AWS Athena (читается “Афина”). Там тоже трещали мозги.
Writing on programming, education, books and negotiations.