-
Обновление MacOS
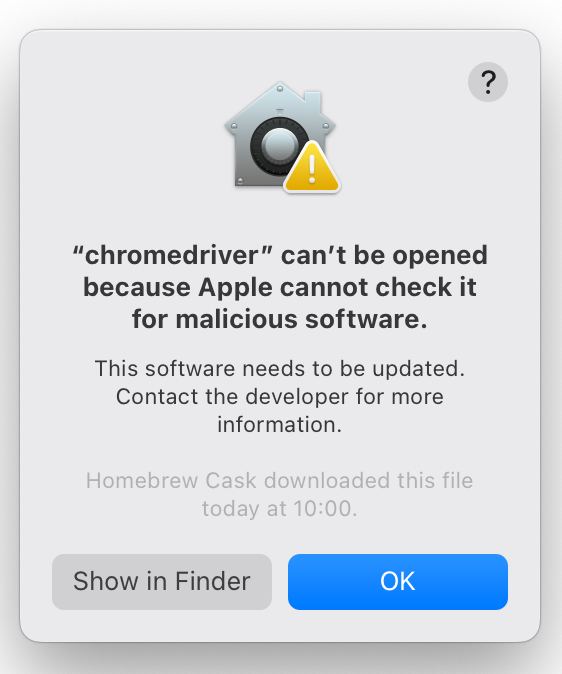
Современная MacOS раздражает мелкими косяками. Из сегодняшнего: накатил минорное обновление, и пожалуйста: программа chromedriver опять считается опасной, недоверенной и прочее. Иди в настройки → безопасность → мотай до нужного пункта, жми “разрешить”, вводи админский пароль.
Все это я уже делал, но обновление сбросило флаги для сторонних программ.
Господа разработчики из Эпла, это же баг, его надо поправить. Почему вы гоните халтуру? Обновление не должно сбрасывать то, что я уже настроил.
Вообще, ощущение такое, что всех толковых разработчиков забрали в iOS, а десктоп пилят по остаточному принципу. Да и то — тупо копируют то, что на мобиле.
-
Переход в айти
Иногда я беседую с людьми, которые хотят в айти. Обычно это взрослые люди: они где-то работают и наслышаны про высокие зарплаты в айтишной отрасли. Спрашивают, с чего начать, какой язык выбрать, каким курсам доверять. Когда-то я отвечал плоско, то есть давал буквальные ответы: Питон, Хекслет и все в том же роде. Позже я решил, что это неправильно, и теперь строю диалог по-другому. А чтобы не повторять одно и то же, решил сбросить мысли в заметку.
Итак, тем, кто подумывает о переходе в айти, я говорю следующее.
Не стоит идти туда ради денег. Да, зарплаты в вакансиях высокие: двести, триста, четыреста тысяч рублей. Это выше средней планки даже по столичным меркам. Такая зарплата покрывает все потребности: в короткий строк покупается квартира, машина, телефоны и прочая техника. На отпуск тоже хватает, как и на любые кружки детям. Зарплаты в пять, восемь, десять тысяч долларов тоже реальны. И хотя те, кто работает за валюту на зарубежные компании, испытывают трудности, схема остается в силе.
Но никакая зарплата не удержит в айти, если вы не любите его. Это должно быть вашим делом. Вы должны любить кодить, ревьюить, проектировать и далее по списку. Без любви не пойдет, потому что в айти очень много бесячих вещей. Дикая фрагментация стандартов, протоколов, платформ, технологий. Их бешеная несогласованность. В некоторых отраслях немыслимый темп, когда один фреймворк сменяет другой через год, и все считают нормальным переписывать проект со старого на новый (привет, JavaScript). Ошибки прошлых разработчиков: неуклюжие, негибкие решения, которые вам предстоит исправлять. Переработки, бесконечные звонки, обсуждения, поток булщита от руководства и прочее и прочее.
Все это перевешивает одна вещь – любовь к коду. То приятное ощущение, когда найдено простое, изящное решение проблемы. Если оно не вызывает отклик в мозгу, большая зарплата не покроет негативные стороны айти.
Мысль о том, что получают много только айтишники, ошибочна. Стоматологи, менеджеры, судьи получают не меньше. Например, просто хороший стоматолог-терапевт в частной фирме – двести тысяч. Имплантолог – пятьсот-шестьсот. Топ-менеджеры и судьи не только получают миллионы, но и входят в особое сословие с неофициальными правами. Любой бытовой спор с ними вы проиграете; попадете им под машину – еще и окажетесь виноваты.
Я немного кривлю душой, потому что стоматология, судебная и прочие отрасли регулируются государством. Нельзя пройти курсы и открыть зубной кабинет, а в айти – пожалуйста, даже высшее образование не нужно. Но важно понимать, что зарплаты в 200, 300 и 400 тысяч ориентированы на тех, кто в айти десять лет. Это совершенно не ваш вариант.
Переход в айти протекает нелегко. Вы запишетесь на курсы и будете проводить вечера после работы за ноутом. Хорошо если нет семьи и детей, в противном случае легко нажить скандал. Впрочем, многих мужчин толкают в айти их жены, потому что «у Снежаны муж айтишник».
Слово «курсы» сегодня звучит анекдотом. Их великое множество, их штампуют на коленке за вечера. Безусловно, есть среди них и достойные, но как выбрать – я не знаю. Я получал много приглашений делать курсы по Питону и Кложе, но всегда отказывался. Сделать качественный курс – долго и трудно, а оплата школы на порядок меньше того, что я получаю. Не хочу судить обо всех по себе, но специалист не будет делать курс ради денег – это не выгодно. Допускаю, можно сделать его ради пиара. Большинство курсов, на мой взгляд, сделаны не профессионалами, а людьми, знающими предмет лишь немного лучше аудитории.
Прохождение курса дает чувство ложной уверенности. Речь вот о чем: школа заинтересована в том, чтобы курс прошли. Если курс никто не проходит, то даже если за него заплатили, он не будет прибыльным. Ученики делятся отзывами о курсах, и если выяснится, что курс никто не прошел, на школу обрушится гнев. Школа вынуждена подтягивать учеников: мотивировать их, вводить геймификацию, нанимать менторов. Я не говорю, что это плохо, напротив – если кому-то помогло, то ради бога. Но имейте в виду, что школа заинтересована в окончании курса и возможно ваши успехи переоценены.
Курсы почти не дают преимущества при поиске первой работы. Если точнее, дают, но очень низкие. Вместе с вами на место будут претендовать десятки тех, кто тоже закончил курсы, а то и несколько. Курсы считаются чем-то вроде школьного образования: они просто обязаны быть. У вас один курс? У Михаила, менеджера автосалона, их два! Слесарь Николай прошел три курса. Козырять ими совершенно бессмысленно.
После прохождения курсов будьте готовы к долгим отказам. Конкуренция в айти большая, туда идут и молодые, и взрослые. Будет череда отказов без объяснения причин. Вам даже не будут перезванивать. Вы ждете две недели, робко напоминаете о себе – и получаете отказ. По тону собеседника ясно, что вам отказали уже на пятой минуте собеса и не посчитали нужным известить.
Отказы демотивируют и опытных разработчиков. Я писал о том, как, даже имея работу, собеседовался в одну фирму. Прошел четыре кодинг-сессии и получил отказ в одном предложении: “Иван, мы подумали и решили, что продолжать нет смысла, спасибо.” Это обидно, это бесит, нужно иметь запас ментальной прочности. Есть ли у вас этот запас в 35 лет, особенно если вы не меняли работу последние пять лет?
Период отказов может занять до года, в это время нужно на что-то жить. Когда вас возьмут, зарплата будет самой обычной: 60-70 тысяч рублей. Рекрутеры не дураки и выжмут из вашего положения все, что можно. Если вы снимаете квартиру в Москве, то этого хватит, чтобы не умереть с голоду. Если есть семья и дети, то я даже не знаю.
Вот поэтому, когда человек подумывает об айти, я спрашиваю: что мешает двигаться вверх в текущей отрасли? Если это госслужба, почему не перейти в частный сектор? Если вы уже частном, может, сменить фирму? Взять новые задачи, повести новый проект. Зайти к начальству и спросить прямо: за что взяться, чтобы получать больше?
Подозреваю, иным людям не хватает на это смелости. Вариант с айти кажется проще: окончу курсы с «гарантией трудоустройства» и начну получать больше. Там компьютеры, общаться с людьми не надо. Все это неправда: рядом с «гарантией» всегда стоит звездочка, где написано: школа отправит за вас резюме в три фирмы, и на этом все. Общаться с людьми в айти нужно не меньше, чем в других профессиях. Спросите айтишника, сколько часов он проводит в зуме – он закатит глаза. Два-три часа минимум не считая офлайн, если это офис.
Тем, кого беспокоят высокие зарплаты в айти, я советую заняться плавным развитием себя. Именно плавным. Вот что это значит.
Если вы работаете за компьютером, повысьте навыки работы с ним. Подойдет любая книжка из Читай-города или курс. Просто чтобы выполнять рутину быстрее. Освойте Total Comander вместо стандартного файлового менеджера. Заучите хоткеи. Почитайте про офисный пакет, Ворд, Эксель – там можно творить чудеса.
Если хочется автоматизировать рутину – пройдите базовый курс по Питону. Важно: занимайтесь не для того, чтобы свалить из проклятой кабалы и зарабатывать 300 тысяч в час! Занимайтесь для себя, чтобы однажды раз – и собрать документ за минуту вместо двух часов. Чтобы проанализировать массив данных скриптом, а не вручную, как раньше. Чтобы внести в программу платежки автоматом. Чтобы найти ошибки в работе операторов и предоставить их начальству с указанием, как исправить. Такие вещи не останутся незамеченными.
Почитайте Ильяхова и Сарычеву насчет переписки. Не обязательно «Пиши, сокращай» – подойдут «Новые правила деловой переписки». Вы не представляете, как мало людей, которые умеют пользоваться почтой и мессаджерами так, чтобы не бесить. Станьте одним из тех, кто радует сетевым этикетом.
Научитесь писать. Речь о способности написать текст А4 без вздохов, ахов и перекуров. Сел – и написал связный текст: письмо, предложение, заметку в блог. У большинства навык письма неразвит: иной менеджер с радостью разгрузил бы вагон картошки вместо странички текста. Люди не умеют писать связно: они кидаются обрывками фраз, из которых нужно восстановить смысл. Навык письма ведет к повышению зарплаты, это аксиома.
Почитайте о переговорах, например «Сначала скажите нет» Кемпа. Это сложная книга, она будет усваиваться не один год. Первые несколько лет вы будете делать ошибки, бездумно повторяя тезисы оттуда. Позже придет понимание, и книга даст плоды.
Если у вас опыт в текущей сфере, не уходите в айти, сжигая мосты. Используйте его как опору для плавного смещения в айтишную отрасль. Вы юрист? Займитесь делами, связанными с разработкой ПО. Работаете в торговле? Значит, вы знаете тонкости продаж, поставок, скидок и прочего – в отличие от студента, который выучил Питон, но дебет от кредита не отличит. Максимально задействуйте текущий опыт.
Пример с юристом здесь неслучайно. Я знал человека, опытного юриста. Он ходил к нам на митапы, давал выступления про авторские права в разработке ПО. Он занялся Питоном, потом машинным обучением и голосовыми моделями. Сейчас у него консалтинговая фирма, которая базируется на колоссальном опыте этого человека в сфере права и юриспруденции. Да, он пишет на Питоне хуже меня, но знает, как работает право и бизнес. Отсюда и результат: я нанимаюсь, а он нанимает.
Вот, пожалуй, что вы услышите от меня, если спросите о переходе в айти. Еще раз коротко: конкуренция большая, айти надо любить, на курсы особо не надейтесь. Будет много отказов, первая зарплата окажется ниже, чем сейчас. Зарплата в 400 тысяч будет через 5-10 лет. Рассмотрите альтернативы: самообучение и рост в текущей отрасли. На крайний случай отталкивайтесь от опыта в той сфере, что есть сейчас.
Если что-то забыл, напишите – дополню. Можно в личку.
-
Таб About
У всех медиа-платформ один и тот же косяк.
Предположим, я кликаю на ссылку исполнителя, и открывается страница с табами. При этом нулевым, главным табом является “About” или “Info” — общая информация об исполнителе. Так вот — этот таб не нужен. В нем нет ничего полезного, и он целиком дублирует контент из других табов, например “Видео” или “Треки”.
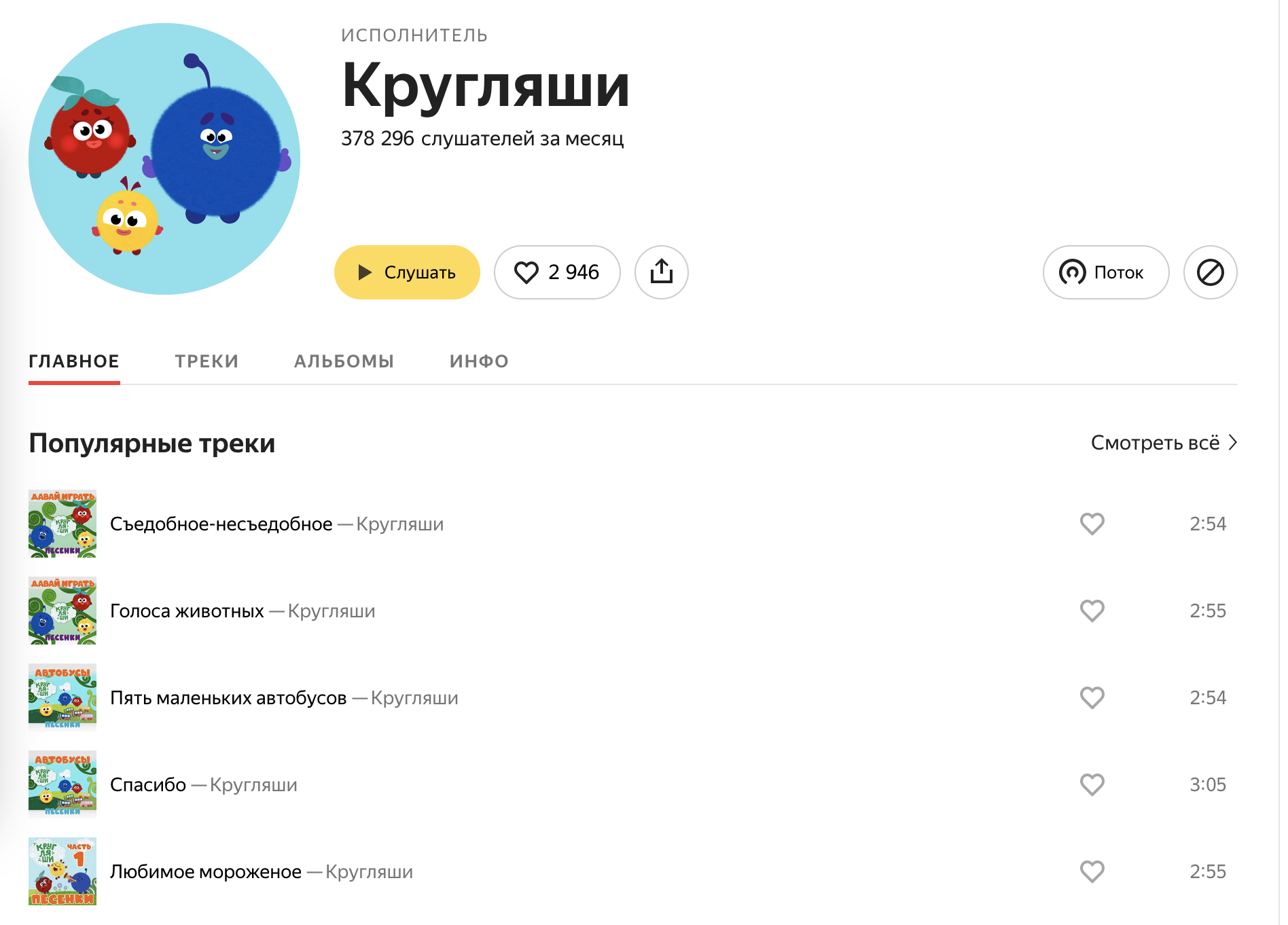
Пример — Яндекс.Музыка. На странице “Главное” — популярные треки. На странице “Треки” — те же самые треки в той же последовательности, отличается только рендер. На “Главной” перед треками иконки альбома, в “Треках” иконок уже нет.
Главная:
Треки:
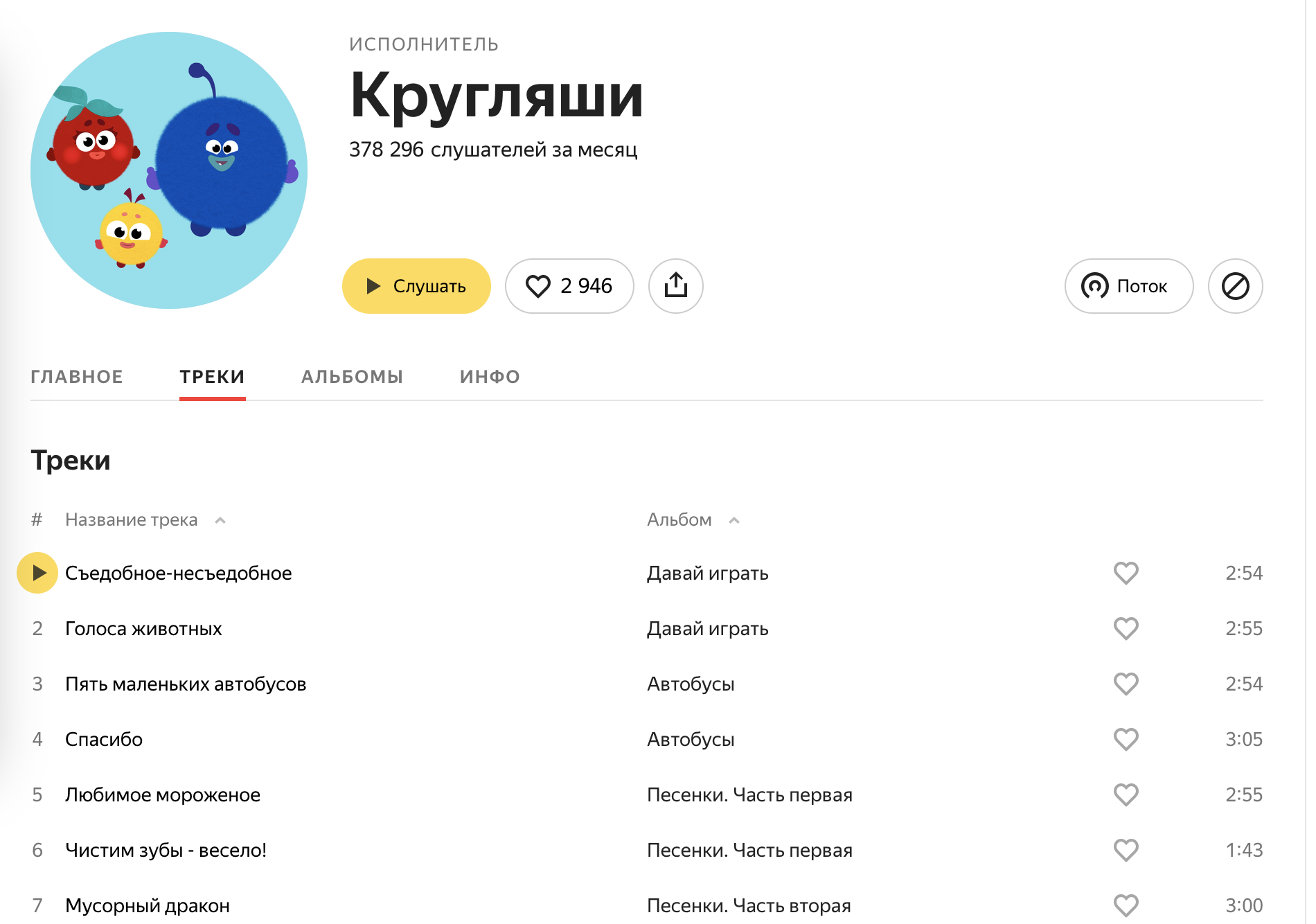
В чем разница?
То же самое в Ютубе или, прости господи, Порнохабе. На главном табе какой-то хлам, который никому не нужен. Никто не читает графоманию автора о себе и своем канале. От промо-ролика на главной уже тошнит. Каждый зритель хочет контент — то есть таб “Видео”. Получается два клика вместо одного: сперва на ссылку исполнителя, а потом /video.
Именно таб с контентом должен быть главным, а “About” или “Info” нужно задвинуть в конец. Это как если бы главной страницей сайта была “О компании”. Глупо? Так почему же везде копируют этот паттерн?
-
Джек Торранс
Отпуск, перечитываю “Сияние” Стивена Кинга. Та самая книга из детства: суперобложки давно нет, зеленая корка без каких-либо надписей. Перевод местами странный, на каждой третьей странице — опечатка или путаница имен. Но это та самая книга, которую я читал двадцать пять лет назад, поэтому можно закрыть глаза.
Удивительно, как меняется восприятие книги с возрастом. В детстве я обращал внимание в основном на крипоту, а теперь — на проработку персонажей. На мой взгляд, “Сияние” особенно сильно с этой стороны. Центральные персонажи — Джек, Венди и Денни — переданы столь качественно, что лучше и нельзя. Читая роман, буквально погружаешься в персонажей, в их тесный семейный мир.
На фоне жены и сына лучше всего, на мой, взгляд, проработан Джек. Действие отталкивается от него, и мы узнаем все больше деталей из его прошлого. Джек — крайне сложный, противоречивый персонаж. Его амбиции стать писателем подкошены алкоголизмом. Роль главы семьи тоже под вопросом — пьяный Джек сломал сыну руку. И хотя проблемы от алкоголя в прошлом, каждый поступок рождает флешбек, когда Джек пил.
Мне не доводилось читать книги, в которой более точно описано состояние человека после алкоголизма. Я имею в виду не краткосрочные последствия вроде протрезвления или развода. Я говорю о более длинном куске жизни — три, пять и более лет. Алкоголизм, даже когда отступил, продолжает давить на человека. Далеко не каждый думает об этом периоде, когда проблема, казалось бы, позади, но на самом деле впереди долгий путь адаптации. Это то, что в драматургии называется “ложный конец”.
Я, хоть и не страдал алкоголизмом (вообще не люблю алкоголь), могу рассказать свою историю. Лет двадцать назад я был знаком с человеком, бывшим в юности алкоголиком. Мы вместе работали и даже пытались делать бизнес.
У человека был сложный характер: это был ходячий комок комплексов, переживаний, подозрений, ревности и много чего еще. Он находил интриги там, где все было чисто. Своим поведением он привлекал женщин, заводил бесконечные романы, которые кончались разрывом в слезах. Многое можно было списать на характер, но на мой взгляд, алкоголизм выступил тем катализатором, который многократно обострил его неприятные черты.
Ключевой особенностью этого человека можно назвать обиду. Он жил обидой на то, что пока он пил, кто-то учился и шел на повышение. Он был обижен на жизнь, в которой он потерял самые важные годы. В таком мире все были виноваты: коллеги, начальники, друзья, женщины.
Насколько я знаю, сейчас у него все хорошо — есть семья и дети, он профессионал в своем деле. Мы были знакомы пять лет или около того, и по моим оценкам, восстановление от алкоголя занимает около десяти лет. Сколько раз я слышал от него про желание напиться; различные уловки, чтобы избежать этого; россказни про собрания анонимных алкоголиков и все остальное. Этот груз давит, его вечно носишь с собой, как Джек Торранс носил свой набор досадных воспоминаний.
Рассказы этого человека дословно повторяют жизнь Джека Торранса. Чувство обиды постоянно угнетало его. Оно чередуется с обидой внутренней — на себя — с обидой внешней на семью и коллег. Почти каждый шаг Джека — это реакция на очередной флешбек, попытка отыграть то, что не удалось тогда, и вот теперь-то выйдет как надо. Но даже когда дела идут, Джек, движимый обидой, звонит Уллману и раскрывает планы на книгу про отель. Этот звонок обходится ему дорого: именно с ответного звонка Эла Шокли психика Джека начинает расшатываться. Подобно Джеку, мой знакомый ссорился с людьми на ровном месте, воскрешая из памяти забытые эпизоды, обильно удобряя их обидой.
Ключевая причина того, что бывший алкоголик ведет себя странно — обида. А мир, в котором все наполнено обидой, неблагополучен для жизни.
Удивляться тому, как точно автор передал Джека Торранса, не приходится. Джек — это сам Кинг, который в ту пору восстанавливался от алкоголя. Он был в точности на том же отрезке пути, когда приемы спиртного уже в прошлом, но человек может в любую минуту сорваться. Вот откуда эта точность, эта интимность всех помыслов Джека и его флешбеков. Вот почему, читая главы “Сияния”, особенно связанные с Джеком, отключаешься от внешнего мира — настолько сильно погружение.
Завершая, скажу, что все сказанное выше относится к книге. Фильм Кубрика я считаю парадоксом: с одной стороны, великолепно подобранные актеры: на месте тех Джека, Венди и Денни я физически не могу представить кого-либо другого. Сам фильм — некая фантасмагория, в которой от замысла Кинга не осталось ничего. Будет время — горячо советую прочитать книжку.
-
Zen of Python
Если вы имеете отношение к Питону, то вот небольшой совет. Никогда не упоминайте знаменитый Zen of Python: ни в шутку, ни всерьез. Если упоминает кто-то другой, пропускайте мимо ушей, не важно насколько он именит.
Объяснение этому следующее. Современный Питон бесконечно далек от тезисов Zen of Python. Я заметил это пятнадцать лет назад, когда писал на Python 2.5. Тогда я не мог высказаться, но время пришло.
Я не говорю, что это плохо. Наоборот, Питон — одна из лучших вещей в айти (иногда мне кажется, что слишком хорошая). Питон — первый язык, ориентированный на пользователя. Отсюда такая любовь и популярность.
Расхождение с Zen of Python было неминуемым, потому что язык развивался. Полагаю, Zen of Python был актуален несколько первых версий, а потом устарел — не быть же языку заложником старых догм. Это совершенно нормально.
Поэтому я рассматриваю Zen of Python как исторический документ. Подкреплять им свои доводы в спорах несерьезно. С таким же успехом можно ссылаться на скрижали Майя или гороскоп.
Половина доводов в Zen of Python не имеет смысла, а вторая потеряла актуальность. Я не буду дотошно перечислять каждый пункт: повторюсь, половина из них бессмысленна. Я не знаю, как комментировать “красивое лучше, чем уродливое” — с таким же успехом можно сказать, что котики лучше пьяной драки. Зато знаю, какие пункты прямо нарушают то, что в Питоне, и сейчас вам о них расскажу.
Один из тезисов звучит примерно как “должен быть один способ сделать что-то”:
There should be one– and preferably only one –obvious way to do it
Когда я слышу это утверждение, то могу только фыркнуть. В Питоне бесконечное число способов что-то сделать. Из-за своей гибкости и многолетнего контриба одну и ту же задачу можно выполнить разными способами. При этом число способов со временем только множится.
Простой пример — в Питоне три способа форматирования строк: старый сишный с процентом, джавный
string.format()и f-строки, которые по сути eval. Я обожаю троллить питонистов форматированием с процентом. Если вы возьмете меня в проект на Питоне, я обязательно напишу так:return "<%s %s>" % (user_name, user_email, )Не потому что я упорот, а чтобы проверить вашу реакцию. Происходит следующее: коллега читает код и подвисает на этой строчке. Его уже не волнует бизнес-логика и покрытие тестов. В нем зреет тревога: всем известно, что нужно пользоваться f-строками, а тут какой-то синтаксис времен Unix… Подключается второй питонист, слово за слово, и начинается срач — как правильно форматировать строки. Плывут экраны комментариев, я сижу и улыбаюсь.
Библиотеки с говорящими именами
httplibиhttplib2, а такжеurllib,urllib2иurllib3(последняя — сторонняя). Все они страшные, и нормальную открывашку урлов сделали только вrequests.У словаря есть метод
update. Добавили оператор|=(палка-равно), который делает то же самое. Господи, зачем? Может, добавите еще|>,|~,|-и другие? Удобней и короче, чем.update,.intersectи прочие английские слова.С каждый релизом в Питоне все больше трюков, библиотек и операторов. Забавно, когда одна строчка from
__future__ import fooрасширяет синтаксис или даже интерпретатор.Словом, тезис о том, что должен быть один способ что-то сделать, совершенно неактуален.
Другие тезисы Zen of Python вроде как поощряют простые решения:
Explicit is better than implicit. Simple is better than complex. Flat is better than nested.
Давайте откроем исходники Django Framework, а именно его сердце — модели. Потому что в Django все вращается вокруг моделей — пользователи, данные, админка — и без моделей он никому не нужен.
Смотрим класс
ModelBase, метод__new__(): семь экранов магии. Здесь и махинации с атрибутами, и прокси-классами, и наследование, и то, и се вперемешку с многими if-else. Найдется ли питонист, который внятно объяснит, что там происходит?Но
ModelBase— это всего лишь метакласс классаModel, в котором похожая петрушка. В методе__init__четыре экрана кода с разными манипуляциями с аргументами. И этот код со всей своей магией постоянно крутится у тех, кто ведет проекты на Django.Ничуть не лучше ситуация с формами и виджетами. Там тоже метаклассы с махинациями, которые простым смертным не понять.
Я веду к следующему: чтобы сделать удобно потребителю, код может быть чудовищно сложным. Но потребитель об этом не знает: он вызывает методы и рассказывает догмы из Zen of Python, что simple is better than complex. То, что внутри экраны магии с метаклассами, его не интересует.
Другой довод в пользу того, что в Питоне не приживаются простые решения, следующей. Если бы это было так, то проекты на Питоне строили бы на списках, словарях и функциях. А на практике любой проект на Питоне — как Джава: классы, классы, классы. Гигантский граф изменяемых объектов.
Еще один пункт из Zen of Python говорит про неймспейсы:
Namespaces are one honking great idea – let’s do more of those!
Если кто-то знает о пространствах имен в Питоне, пожалуйста, сообщите мне, потому что за 10 лет я о них ничего не узнал. В Питоне обычная система модулей, которые импортируются друг в друга. Никаких особых свойств у модулей нет.
Для сравнения: в известном скобочном языке символы и кейворды могут быть привязаны неймспейсу. Символ
fooиз неймспейсаcom.testне равен символуfooизbar.test. Такая связь пространства имен и символов/кейвордов открывает полезные техники, о которых я не буду сейчас, потому что это другой язык. В Питоне ничего подобного нет, и к чему тезис о неймспейсах, непонятно.Повторюсь, бессмысленность Zen of Python не имеет отношения к языку. Можно писать на нем отличный код, даже не зная о Дзене. Но доказывать точку зрения, опираясь на тезисы Zen of Python — вот образец бессмысленности.
-
Винда и Скайнет
То, что произошло недавно с виндой, напоминает Скайнет из франшизы про Терминатора. Напомню, по сюжету все компьютеры захватил вирус. Далее он построил роботов, которые пошли убивать людей. На тот момент это было слишком фантастично, потому что единовременно обрушить все компьютеры в те дни было невозможно. Не было такой связанности и централизованности. Не было такого, что каждый утюг качает обновления по три раза в день и ставит автоматом.
А сегодня — пожалуйста! Какие-то бедолаги налажали с указателями, и легла сотая часть компов на виндузе. Если вам кажется, то это мало, то вы не правы. В одном только здании может быть нескольких сотен устройств на винде. Тем сотым компом, что лег из-за обновления, может быть кассовый сервер в Пятерочке, банкомат, шлагбаум на вокзале, дашборд службы спасения.
Это наводит на рассуждения. Были же истории с пилотами, которые нарочно гробили себя и сотни пассажиров. Порой я думаю: вдруг найдется такой же маньяк, только в цифровой сфере? Кто-то, кто устроит цифровой Judgement Day. Он выпустит обновление, которое разойдется по всем виндовым компам, подождет годик-другой и потом вжух — затрет файлы нулями, подаст напряжение на USB-порты, разгонит видеокарты, словом — сделает максимум деструктива.
Все это фантазии, но проблема в том, что они уже не так фантастичны, как в терминаторе. Теоретически они стали возможны, и Микрософт сотоварищи это доказали.
-
Как наполнить базу сгенерированными джейсонами
Предположим, у вас Postgres с миллионами JSONb-документов. Вы хотите проверить нагрузку на стейджинге, но данные с прода брать нельзя – их нужно сгенерить. Тут начинаются проблемы.
Размножить один и тот же джейсон будет неправильным, потому что все они дадут одинаковое значение индекса. В итоге индекс будет “перекошен”: миллион записей попадут в один блок, а остальные сто тысяч будут равномерны. В реальности так не бывает.
Второй вопрос – как генерить. Можно взять язык, на котором вы пишете, и наколбасить случайные словари в CSV. Потом сжать в gzip, перетащить на сервер с базой, распаковать и вставить через COPY IN. Но придется писать код и воевать с передачей файлов по SCP/SSH.
Я склоняюсь к вот такому костылику.
Берем с прода любой JSON, записываем в локальный файл с красивым форматированием. Например:
{ "meta": { "eyes": "brown" }, "attrs": { "email": "petr@test.com", "name": "Petr Ivanov" }, "roles": [ "user", "admin" ] }Здесь он маленький для экономии места, а на проде может быть пять экранов. После этого пропускам файл через серию регулярок:
cat sample.json | sed \ -e "s/\"/'/g" -e 's/: /, /g' \ -e 's/{/jsonb_build_object(/g' \ -e 's/}/\)/g' \ -e 's/\[/jsonb_build_array(/g' \ -e 's/\]/)/g'Получается SQL-код, который строит тот же самый JSON:
jsonb_build_object( 'meta', jsonb_build_object( 'eyes', 'brown' ), 'attrs', jsonb_build_object( 'email', 'petr@test.com', 'name', 'Petr Ivanov' ), 'roles', jsonb_build_array( 'user', 'admin' ) )Наберите в консоли
SELECTи вставьте эту колбасу. База выплюнет в точности тот JSON, который был в файле.Если форматировать JSON лень, добавьте в пайп утилиту
jq— по умолчанию она просто форматирует документ.Это был только один джейсон. Теперь размножим его с помощью
select ... from generate_series...select jsonb_build_object( 'meta', jsonb_build_object( 'eyes', 'brown' ), 'attrs', jsonb_build_object( 'email', 'petr@test.com', 'name', 'Petr Ivanov' ), 'roles', jsonb_build_array( 'user', 'admin' ) ) as document from generate_series(1, 5) as x;Выборка вернет столько документов, сколько чисел в диапазоне
generate_series. Но это один и тот же документ, что не подходит. Пройдитесь по значимым полям документа и замените статичные строки на форматирование, например так (переменнаяxссылается на текущее значениеgenerate_series):select jsonb_build_object( 'meta', jsonb_build_object( 'eyes', format('color-%s', x) ), 'attrs', jsonb_build_object( 'email', format('user-%s@test.com', x), 'name', format('Test Name %s', x) ), 'roles', jsonb_build_array( 'user', 'admin' ) ) as document from generate_series(1, 5) as x;Новая выборка станет такой:
document ------------------------------------------------------------------------------------------------------------------------- {"meta": {"eyes": "color-1"}, "attrs": {"name": "Test Name 1", "email": "user-1@test.com"}, "roles": ["user", "admin"]} {"meta": {"eyes": "color-2"}, "attrs": {"name": "Test Name 2", "email": "user-2@test.com"}, "roles": ["user", "admin"]} {"meta": {"eyes": "color-3"}, "attrs": {"name": "Test Name 3", "email": "user-3@test.com"}, "roles": ["user", "admin"]} {"meta": {"eyes": "color-4"}, "attrs": {"name": "Test Name 4", "email": "user-4@test.com"}, "roles": ["user", "admin"]} {"meta": {"eyes": "color-5"}, "attrs": {"name": "Test Name 5", "email": "user-5@test.com"}, "roles": ["user", "admin"]} (5 rows)Вставим выборку в таблицу документов:
create table documents(id uuid, document jsonb)Для этого допишем в запрос шапку
INSERT:insert into documents (id, document) select gen_random_uuid() as id, jsonb_build_object( '__generated__', true, 'meta', jsonb_build_object( 'eyes', format('color-%s', x) ), 'attrs', jsonb_build_object( 'email', format('user-%s@test.com', x), 'name', format('Test Name %s', x) ), 'roles', jsonb_build_array( 'user', 'admin' ) ) as document from generate_series(1, 500) as x returning id;Обратите внимание на поле
__generated__: я добавил его, чтобы отличить обычный документ от сгенерированного.Запустите запрос, и в таблице окажется миллион случайных документов. Вставка может занять до пары минут, потому что JSONb — дорогое удовольствие.
Если что-то пошло не так, удалите сгенерированные документы запросом:
delete from documents where document -> '__generated__' = 'true'::jsonb;Удобство в том, что не нужны питоны-джавы, все делается силами SQL. Не придется генерировать CSV и перетаскивать на сервер. Просто выполнили запрос — и пошли дальше.
Обязательно сохраните скрипт в недрах проекта. Он понадобится если не завтра, то через месяц, а если не вам, то коллеге. И вы такой раз — как Джонни Старк на картинке.
-
Помешательство
Может быть, писал про это раньше, лень искать.
Допустим, у нас современное веб-приложение: на сервере только REST API, а рендер силами JavaScript. Одна из апишек отдает сведения о покупках: число, сумму и дату последней покупки. Что-то вроде такого:
{ "total_orders": 7, "total_sum": "523626", "last_order_date": "2023-12-23T12:23:55Z" }(сумма в копейках, если что)
Ожидается, что на клиенте мы покажем эту информацию так:
Вы совершили семь покупок на сумму 5.236 рублей 26 копеек. Последний раз вы покупали 23 декабря, 20 дней назад.
Чтобы отрендерить этот блок, нам понадобятся:
- библиотека “число прописью”, чтобы 7 стало “семь”;
- склонение с учетом числительных: 1 покупка, 3 покупки, 5 покупок;
- форматирование суммы;
- форматирование дат;
- вычитание дат (20 дней назад);
- возможно, мультиязычные шаблоны, если в приложении несколько языков.
И думаю: есть же люди, которые всерьез делают это на JavaScript(!) в браузере(!!). Подключают тонны библиотек из npm, пишут экраны кода, компилируют мегабайтные бандлы. Запускают всю эту машинерию, кодят месяц и в итоге получают что-то похожее на результат. Который, конечно, работает только в Хроме на 4К-мониторе. На мобиле обрежется, в Фаерфоксе разъедется, в Сафари будет белый экран.
Что движет этими людьми, интересно? И кто за них отвечает? Что за извращенное удовольствие: из всех вариантов выбрать самый хрупкий и тяжелый?
Похоже на массовое помешательство.
-
Прощай, Goo.gl!
Новость о том, что Гугл отключает сокращалку goo.gl, вызвала вьетнамские флешбеки.
Пятнадцать лет назад я был ее активным пользователем. Я тогда жил в Чите и работал в славной компании “Читаэнергосбыт”. Параллельно я пытался сделать какой-нибудь стартап. А поскольку ничего придумать не мог, все поделки сводились к перекладыванию данных: из RSS в Твиттер, из одной соцсети в другую и так далее.
В те времена у Твиттера не было сокращалки урлов. Вставил в сообщение ссылку — и прощай 40-50 символов. Сегодня это звучит дико, но тем не менее. Это был золотой век всяких tr.im, bit.ly и goo.gl — пока у каждой соцести не появились внутренние сокращалки.
Пока я тестировал свои поделки, сократил около 15 тысяч урлов. Я даже написал библиотеку-клиент, и это был, наверное, мой первый опенсорс.
Так вот, возвращаясь к закрытию сокращалки. Если бы я услышал эту новость хотя бы год назад, я бы вознегодовал и написал гневный пост: как так, денег и поддержки не просит, зачем закрывать? А сегодня мне безразлично.
Во-первых, технически забрать данные об урлах проще простого. Не нужные никакие экспорты, достаточно баш-скрипта с курлом и флажком “don’t follow redirects”. Если у вас на сайте есть гугловые ссылки, заменить их нормальными — дело часа. Это технический аспект.
Второй аспект — моральный. Сокращалки урлов устарели и считаются моветоном. Ими пользуются мошенники, СЕО-дрочеры и всякий озабоченный люд, которым важно, сколько раз нажали ссылку, вместо того, что было за ней. Если я вижу сокращенную ссылку, я никогда не нажму на нее, и советую вам то же самое.
У сокращалок урлов был короткий период расцвета. Тогда еще не знали последствий, и сокращать урлы считалось крутым и молодежным. Были плагины для форумов и вордпрессов, которые сокращали все ссылки и подкачивали в админку стату переходов. Но все это в прошлом: у крупных игроков свои методы отслеживания ссылок, а мелким игрокам пользы от сокращалок нет.
Третий аспект касается денег. Обязательно найдется тот, кто скажет: у Гугла денег куры не клюют, пусть поддерживают. Дело в том, что это противоречит миссии Гугла. Его цель — зарабатывать деньги. Это ясно уже лет десять, и почему сокращалка урлов, не приносящая денег, должна быть исключением? Она не приносит денег, поэтому ее нужно закрыть.
Ситуация, когда какой-нибудь менеждер толкает речь на совете директоров о том, что мы должны поддерживать пользователей, потому что обещали им… и все такие: да, что же с нами стало, давайте оставим, только бы не сделать пользователям плохо… Представили картину? Так не бывает. Это возможно в фильме, но не в реальности.
На эту тему советую почитать “Цель 2” Голдрата, причем не обязательно целиком, а хотя бы первую главу. Там как раз заседание директоров, и акулы рвут на части благие намерения. Почему — хорошо описано в диалоге с одной из акул во второй главе.
Так что все своим чередом. Конфето-букетные отношения между пользователями и Гуглом закончились, остался один расчет. Гугл закрыл еще один сервис. Эпоха ушла, жизнь продолжается.
-
Ввод денег
Интересно, бывают ли безглючные виджеты для ввода денег? Например, чтобы ввести тысячу сорок три рубля и тринадцать копеек — при этом так, чтобы не помянуть разработчика и его родню.
По умолчанию в поле стоит ноль, и запросто бывает так, что курсор падает перед ним. В результате цифра умножается на десять. Что-то вроде такого:
|0 123|0Ни один виджет не работает со вставкой. Разработчик думает, что клиент сел — и такой ввел шесть цифр по памяти. На практике люди копируют цифры изо всяких экселей и платежек. Везде беда с десятичным разделителем, пробелами и позицией курсора.
Зачем эти потуги, если результат все равно бажный?
Интересное решение я видел у Пейпала. У них ввод суммы сделан как в старых терминалах. Нужно ввести сумму с точностью до цента, при этом цифры наползают справа налево. Постарался изобразить это табличкой:
state input result 0.00 1 0.01 0.01 2 0.12 0.12 3 1.23 1.23 4 12.34 Все жестко, никаких вариантов. Не уверен, что такой ввод подойдет нам, потому что у нас нет таких терминалов. Но взять на заметку стоит: меньше вариативности — больше надежности.
PS: не привожу скришноты, потому что не вижу смысла. Любой банк, любое приложение. Виджеты денег не работают нигде.
Writing on programming, education, books and negotiations.