-
Три состояния
Упрощая, можно сказать, что человек бывает в трех состояниях: когда он один, когда с кем-то наедине и когда вокруг двое и более людей. В последнем случае неважно, сколько именно: два, три или сотня. Разница есть, но несущественная. Поэтому рассматриваю только варианты 0, 1 и 2+.
В каждом из состояний человек ведет себя по-разному. Фактически это три роли, между которыми мы часто переключаемся.
Понимание этих переключений помогает в жизни. Если человек хочет побыть один, не лезь с разговорами. Чтение книги и просмотр фильма относятся сюда же, потому что оба – про уход в себя.
Если человек в компании, не начинай важный разговор. При свидетелях человек думает прежде всего о том, как прикрыть свой зад и не опозориться перед другими. Здравый смысл отодвигается на второй план: репутация важнее.
Все сводится к тому, что любой разговор можно завалить, если начать его с человеком в неподходящем состоянии. С другой стороны – почти любой разговор можно завершить успехом, если собеседник в правильном состоянии. Осталось понять: где, когда и с кем, а остальное просто.
-
Про Обсидиан
Это заметка про Обсидиан, которая не понравится никому. Тем не менее…
В программе Обсидиан ничего плохого нет. Наоборот, это хорошая программа: у нее даже есть признаки адекватности. С ней можно начать без облачной учетки, хотя другая программа потребовала бы ее на старте и напоминала бы каждые пять минут: дорогой, ты не авторизован! Данные пропадут, скорей оформи подписку.
Меня смущает не программа Обсидиан, а ее пользователи. Здесь прямая аналогия с механическими клавиатурами. В них нет ничего плохого, но есть пользователи, которые годами крафтят кастомные клавиатуры и годами их обсуждают. Точно так же пользователи Обсидиана придают много внимание тому, что этого не стоит.
Обсидиан и аналоги создали некую моду: все толковые ребята ведут цифровые заметки, аналог Цеттелькассена. Если ты ведешь Обсидиан, ты профессионально растешь, ты крут, свой чувак. А если нет – фу-фу.
Эта мода сквозит в различных сообществах и Телеграм-каналах; об этом говорят в комментариях ко всем статьям на тему заметок. Пишут статьи о том, как из набора сервисов собрать свой “чемодан заметок”. В первом же комментарии упоминают Обсидиан, и начинается срач.
Обсидиан вывел в тренд некрасивую привычку: показывать всем свой граф знаний. Подобно владельцу айфона, который только что его купил и открывает без надобности, пользователь Обсидиана без конца смотрит на граф заметок. Искусственно наращивает его, добавляет лишние связи, потому что теория “чемодана” учит, что заметок без связей быть не должно. Стоит ли говорить, что этот граф – всего лишь ментальный онанизм.
Я не верю, что заметки и граф связей как-то помогают в обучении. Человек на полном серьезе пишет, что благодаря Обсидиану “выучил” Питон. То есть он прослушал лекции и для каждого урока составил заметки и связал их. Разумеется, попади он в первый проект на Питоне, эти заметки пойдут лесом. Важно не составлять заметки, а практиковать знания и закреплять их практикой. Скажем, прослушал урок про списки в Питоне – открываешь учебник по Турбо-Паскалю и прорешиваешь 20 задач, заменяя слово “массив” на “список”. От этого есть польза, а от цифровой заметки – нет.
То же самое пишет Барбара Оакли в книге “Думай как математик”, а также ее колеги-преподы. Все они утверждают, что конспектирование – это хорошо, но гораздо важнее вспоминать и пересказывать материал самому себе, а также скорее закрепить его практикой. Без этого конспектирование дает лишь видимость изучения и уподобляется подчеркиванию в книгах.
Я с трудом представляю, для чего люди ведут заметки в Обсидиане. Изучаешь ты, например, Питон, пишешь заметки к видеокурсу. Так заведи публичный канал в Телеграме и пиши туда! – пусть другие тоже видят, комментируют, поправляют. Всем польза. Для списка ссылок Обсидиан явно избыточен, подойдет файлик или скрытый канал в Телеграме. Для списка дел и дневника подходит обычный блокнот. Зачем брать какую-то программу?..
О том, что при работе с бумагой и ручкой мозг работает по-другому, я писал сотню раз и не буду повторять. Просто попробуйте.
В книге Make Time один из авторов приводит хороший пример. Он подсел на программу заметок, и после обновления операционки она отвалилась. Автор к тому времени забил и обновление не выпустил. Вряд ли это случится с Обсидианом, но тем не менее: не нужно становиться заложником софта.
Верный признак того, что Обсидиан избыточен – это обилие инструментов к нему. Фирма, которая его пишет, вынуждена тащить все подряд, чтобы удовлетворить всех. Помните, это как вкладки в браузере? Кому-то вертикальные, кому-то горизонтальные, по кругу, с предпросмотром, с попапом с данными о потребленной памяти, с закрытием по таймеру и так далее.
Не за горами час, когда вы обновите свой Обсидиан и обнаружите, что он стал медленным и появились интеграции с Твиттером, Покетом и бог знает чем – все потому, что об этом попросили упоротые клиенты, а менеджмент пошел на поводу. Если вам это ни о чем не говорит, погуглите историю сервиса Evernote.
Еще напомню про Агату Кристи, которая написала 50 томов без Обсидиана. Стивен Кинг пользовался блокнотом: первая электронная печатная машинка (даже не компьютер) появилась у него в зрелом возрасте. Чтобы дать что-то миру, вам не нужна программа электронных заметок. Все уже здесь.
Обсидиан сегодня – это мода. Это забавная программа вроде Майнкрафта, в которую не зазорно играть взрослым. Строишь свой мирок, наблюдаешь прогресс, делишься успехом с друзьями. Не возводите его в культ. Не будьте чуваком с картинки ниже. Это пройдет.
-
Программисты и бизнес
Иные говорящие головы двигают такой тезис: хороший программист по мере развития все больше приобщается к бизнесу. Думает, как улучшить продукт, повысить конверсии-воронки и все такое… ходит на совещания с владельцами бизнеса.
Ну… не знаю. Пытался играть в эти игры, но не смог. Мне не интересен бизнес. Не интересно, сколько пользователей привлекли, сколько уников зашло и так далее. Не мое это, хоть убейте.
Мне интересен код. Люблю делать задачу максимально просто: поменьше библиотек, меньше сервисов, без ОРМ. Пишу тесты, добиваюсь, чтобы все случаи покрывались локально, без облака. В общем-то и все. За это прошу лишь минимальную свободу и право выбора технологий.
И знаете, кажется, это то, чего от меня ждут. Заказчик хочет, чтобы задача была сделана быстро и качественно, и чтобы в будущем можно было легко поправить. Это я и делаю. Не имею понятия, кто и как пользуется моей работой, и бывает, узнаю об этом через год.
Я совершенно не сочувствую бизнесу, когда дела идут плохо. Это не мое дело. Я работал в настолько абсурдных стартапах, что искренне недоумевал, что в них кто-то верит. Их судьба предопределена, единственный вопрос — сколько раундов инвестиций они протянут. И еще: сколько опыта я унесу с собой после ухода.
Поэтому рассказы про лояльность бизнесу на меня не действуют. Я пишу качественный код и получаю деньги. Если код не принес прибыли — извините, тут помочь не могу.
Вряд ли я достойный пример для подражания, но рассказы про бизнес нужно воспринимать с прохладой. Это лапша.
-
Вертикальная полоса
Как-то сижу, быдлокодю понемножку и замечаю, что в редакторе включена вертикальная полоса – ограничитель 80 символов. Думаю: странно, не помню, что ее включал. Я таким не пользуюсь – переношу код согласно внутреннему чутью. Но пусть будет, тем более что лень искать, как выключить.
А через месяц я подвинул окно и обнаружил, что это не ограничитель, а вертикальный ряд битых пикселей. Представьте, он не двигается за редактором и искажает цвет в любой программе.
Может быть, в прошлом я бы устроил внутреннюю истерику: как так, 4к-монитор, 144 герц, и вдруг сдох целый ряд. Но потом я подвинул редактор на место и продолжил быдлокодить. С тех пор притворяюсь, что это ограничитель.
Чем меньше истерик – как внешних, так и внутренних – тем лучше для психики. Мне кажется, это правило продлевает жизнь, хоть и доказывать еще рано.
-
JSAM: a simple JSON writer and reader
JSam is a lightweight, zero-deps JSON parser and writer. Named after Jetstream Sam.
- Small: only 14 Java files with no extra libraries;
- Not the fastest one but is pretty good (see the chart below);
- Has got its own features, e.g. read and write multiple values;
- Flexible and extendable.
Installation
Requires Java version at least 17. Add a new dependency:
;; lein [com.github.igrishaev/jsam "0.1.0"] ;; deps com.github.igrishaev/jsam {:mvn/version "0.1.0"}Import the library:
(ns org.some.project (:require [jsam.core :as jsam]))Reading
To read a string:
(jsam/read-string "[42.3e-3, 123, \"hello\", true, false, null, {\"some\": \"map\"}]") [0.0423 123 "hello" true false nil {:some "map"}]To read any kind of a source: a file, a URL, a socket, an input stream, a reader, etc:
(jsam/read "data.json") ;; a file named data.json (jsam/read (io/input-stream ...)) (jsam/read (io/reader ...))Both functions accept an optional map of settings:
(jsam/read-string "..." {...}) (jsam/read (io/file ...) {...})Here is a table of options that affect reading:
option default comment :read-buf-size8k Size of a buffer to read :temp-buf-scale-factor2 Scale factor for an innter buffer :temp-buf-size255 Inner temp buffer initial size :parser-charsetUTF-8 Must be an instance of Charset:arr-supplierjsam.core/sup-arr-cljAn object to collect array values :obj-supplierjsam.core/sup-obj-cljAn object to collect key-value pairs :bigdec?falseUse BigDecimal when parsing numbers :fn-keykeywordA function to process keys If you want keys to stay strings, and parse large numbers using
BigDecimalto avoid infinite values, this is what you pass:(jsam/read-string "..." {:fn-key identity :bigdec? true})We will discuss suppliers a bit later.
Writing
To dump data into a string, use
write-string:(jsam/write-string {:hello "test" :a [1 nil 3 42.123]}) "{\"hello\":\"test\",\"a\":[1,null,3,42.123]}"To write into a destination, which might be a file, an output stream, a writer, etc, use
write:(jsam/write "data2.json" {:hello "test" :a [1 nil 3 42.123]}) ;; or (jsam/write (io/file ...)) ;; or (with-open [writer (io/writer ...)] (jsam/write writer {...}))Both functions accept a map of options for writing:
option default comment :writer-charsetUTF-8 Must be an instance of Charset:pretty?falseUse indents and line breaks :pretty-indent2 Indent growth for each level :multi-separator\nHow to split multiple values This is how you pretty-print data:
(jsam/write "data3.json" {:hello "test" :a [1 {:foo [1 [42] 3]} 3 42.123]} {:pretty? true :pretty-indent 4})This is what you’ll get (maybe needs some further adjustment):
{ "hello": "test", "a": [ 1, { "foo": [ 1, [ 42 ], 3 ] }, 3, 42.123 ] }Handling Multiple Values
When you have 10.000.000 of rows of data to dump into JSON, a regular approach is not developer friendly. It leads to a single array with 10M items that you read into memory at once. Only few libraries provide facilities to read arrays lazily.
It’s much better to dump rows one by one into a stream and then read them one by one without saturating memory. Here is how you do it:
(jsam/write-multi "data4.json" (for [x (range 0 3)] {:x x}))The second argument is a collection that might be lazy as well. The content of the file is:
{"x":0} {"x":1} {"x":2}Now read it back:
(doseq [item (jsam/read-multi "data4.json")] (println item)) ;; {:x 0} ;; {:x 1} ;; {:x 2}The
read-multifunction returns a lazy iterable object meaning it won’t read everything at once. Also, bothwrite-andread-multifunctions are pretty-print friendly:;; write (jsam/write-multi "data5.json" (for [x (range 0 3)] {:x [x x x]}) {:pretty? true}) ;; read (doseq [item (jsam/read-multi "data5.json")] (println item)) ;; {:x [0 0 0]} ;; {:x [1 1 1]} ;; {:x [2 2 2]}The content of the data5.json file:
{ "x": [ 0, 0, 0 ] } { "x": [ 1, 1, 1 ] } { "x": [ 2, 2, 2 ] }Type Mapping and Extending
This chapter covers how to control type mapping between Clojure and JSON realms.
Writing is served using a protocol named
jsam.core/IJSONwith a single encidng method:(defprotocol IJSON (-encode [this writer]))The default mapping is the following:
Clojure JSON Comment nil null String string Boolean bool Number number Ratio string e.g. (/ 3 2)->"3/2"Atom any gets deref-edRef any gets deref-edList array lazy seqs as well Map object keys coerced to strings Keyword string leading :is trimmedAnything else gets encoded like a string using the
.toStringinvocation under the hood:(extend-protocol IJSON ... Object (-encode [this ^JsonWriter writer] (.writeString writer (str this))) ...)Here is how you override encoding. Imagine you have a special type
SneakyType:(deftype SneakyType [a b c] ;; some protocols... jsam/IJSON (-encode [this writer] (jsam/-encode ["I used to be a SneakyType" a b c] writer)))Test it:
(let [data1 {:foo (new SneakyType :a "b" 42)} string (jsam/write-string data1)] (jsam/read-string string)) ;; {:foo ["I used to be a SneakyType" "a" "b" 42]}When reading the data, there is a way to specify how array and object values get collected. Options
:arr-supplierand:obj-supplieraccept aSupplierinstance where thegetmethod returns instances ofIArrayBuilderorIObjectBuilderinterfaces. Each interface knows how to add a value into a collection how to finalize it.Default implementations build Clojure persistent collections like
PersistentVectororPersistenHashMap. There is a couple of Java-specific suppliers that buildArrayListandHashMap, respectively. Here is how you use them:(jsam/read-string "[1, 2, 3]" {:arr-supplier jsam/sup-arr-java}) ;; [1 2 3] ;; java.util.ArrayList (jsam/read-string "{\"test\": 42}" {:obj-supplier jsam/sup-obj-java}) ;; {:test 42} ;; java.util.HashMapHere are some crazy examples that allow to modify data while you build collections. For an array:
(let [arr-supplier (reify java.util.function.Supplier (get [this] (let [state (atom [])] (reify org.jsam.IArrayBuilder (conj [this el] (swap! state clojure.core/conj (* el 10))) (build [this] @state)))))] (jsam/read-string "[1, 2, 3]" {:arr-supplier arr-supplier})) ;; [10 20 30]And for an object:
(let [obj-supplier (jsam/supplier (let [state (atom {})] (reify org.jsam.IObjectBuilder (assoc [this k v] (swap! state clojure.core/assoc k (* v 10))) (build [this] @state))))] (jsam/read-string "{\"test\": 1}" {:obj-supplier obj-supplier})) ;; {:test 10}Benchmarks
Jsam doesn’t try to gain as much performance as possible; tuning JSON reading and writing is pretty challenging. But so far, the library is not as bad as you might think! It’s two times slower that Jsonista and slightly slower than Cheshire. But it’s times faster than data.json which is written in pure Clojure and thus is so slow.
The chart below renders my measures of reading a 100MB Json file. Then the data read from this file were dumped into a string. It’s pretty clear that Jsam is not the best nor the worst one in this competition. I’ll keep the question of performance for further work.
Measured on MacBook M3 Pro 36Gb.

Another benchmark made by Eugene Pakhomov. Reading:
size jsam mean data.json cheshire jsonista jsoniter charred 10 b 182 ns 302 ns 800 ns 230 ns 101 ns 485 ns 100 b 827 ns 1 µs 2 µs 1 µs 504 ns 1 µs 1 kb 5 µs 8 µs 9 µs 6 µs 3 µs 5 µs 10 kb 58 µs 108 µs 102 µs 58 µs 36 µs 59 µs 100 kb 573 µs 1 ms 968 µs 596 µs 379 µs 561 µs Writing:
size jsam mean data.json cheshire jsonista jsoniter charred 10 b 229 ns 491 ns 895 ns 185 ns 2 µs 326 ns 100 b 2 µs 3 µs 2 µs 540 ns 3 µs 351 ns 1 kb 14 µs 14 µs 8 µs 3 µs 8 µs 88 ns 10 kb 192 µs 165 µs 85 µs 29 µs 96 µs 10 µs 100 kb 2 ms 2 ms 827 µs 325 µs 881 µs 88 µs Measured on i7-9700K.
On Tests
One can be interested in how this library was tested. Although being considered as a simple format, JSON has got plenty of surprises. Jsam has tree sets of tests, namely:
- basic cases written by me;
- a large test suite borrowed from the Charred library. Many thanks to Chris Nuernberger who allowed me to use his code.
- an extra set of generative tests borrowed from the official
clojure.data.jsonlibrary developed by Clojure team.
These three, I believe, cover most of the cases. Should you face any weird behavior, please let me know.
-
Flyway
Волею судеб я использую джавную библиотеку Flyway для миграций. Должен сказать: ее писали клоуны.
Вот как это проверить: запускаем миграции на Postgres 15.8, версия Flyway 7.5.4. Все благополучно работает. А если поднять версию до последней 11.7.2, получим исключение:
Unsupported Database: PostgreSQL 15.8
Не менял абсолютно ничего, никаких настроек, только бампнул версию. И вот пожалуйста.
Внимание, вопрос: что же такого случилось, что Постгрес 15.8 вдруг не поддерживается? Почему спустя три мажорных релиза он отвалился? Слишком новый? Слишком старый? И что делать?
Между прочим, Постгрес 15.8 — относительно свежий релиз (последняя версия, если что — 17). С каких щщей он попал в немилость?
Что творилось в голове у джавистов, которые писали Flyway, я ума не приложу.
Мне приходилось писать свои миграционные движки, и могу сказать: да, это работа не на один день, конечно. Хорошенько все потестить, а потом стабилизация. Но наколбасить 11 мажорных релизов, которые вдобавок тупо не работают — это надо уметь.
Сюда же относится официальный SDK AWS на Джаве, который я уже упоминал. Ощущение, что писали студенты или вроде того. Все аргументы опциональны, все может быть null, в том числе бакет, который читаешь, или файл, в которых пишешь. В рантайме ловишь сто ошибок, что это не может быть нул, то не может и так далее. Про обязательные аргументы в Амазоне не слышали.
Выпустили SDK 2, а там те же самые проблемы.
Словом, ты вырос и сказка кончилась. Программист в корпорации X может получать 400 тыс. долларов в год и писать лютейший быдлокод. А нам, потребителям, с этим жить.
-
Кнопка Summarize
Компания Эпл следует тенденции: сует AI в каждую щель. Так, в почтовом приложении над каждым письмом теперь кнопка “Summarize”, которая, как предполагается, покажет краткую версию письма.

Разумеется, это полная шляпа. Работает только с английским текстом и text/plain. Если вам прислали графоманию на русском, и к тому же в виде HTML-таблиц — кнопка скажет, что “не шмогла”. В целом, эта кнопка скорее не работает, нежели работает.
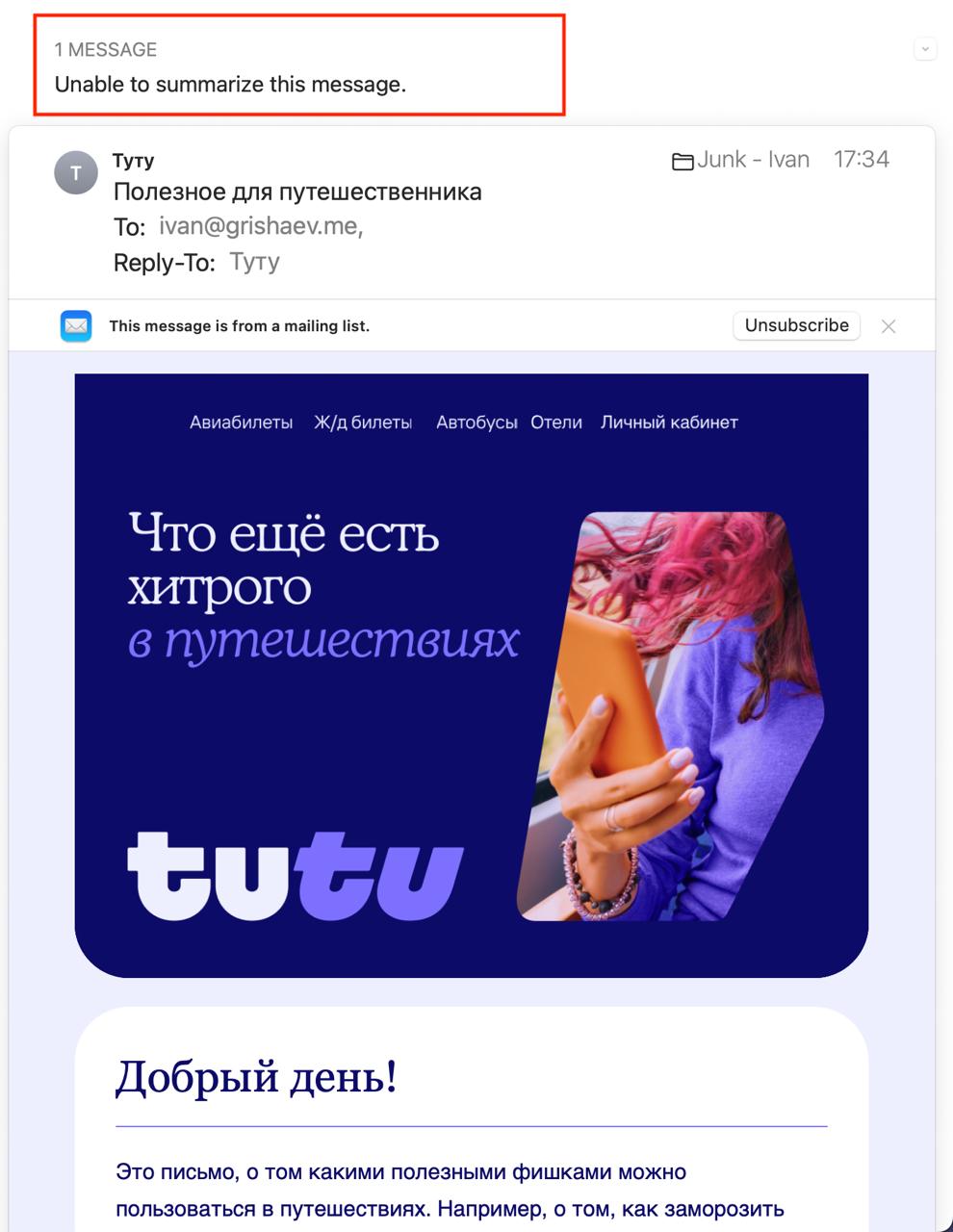
Все, что остается пользователю — это отключить кнопку, но не все так просто. Я снял нужную галку, кнопка пропала, но потом появилась. Может быть, нужно перезагрузиться, но ситуация уже абсурдна.
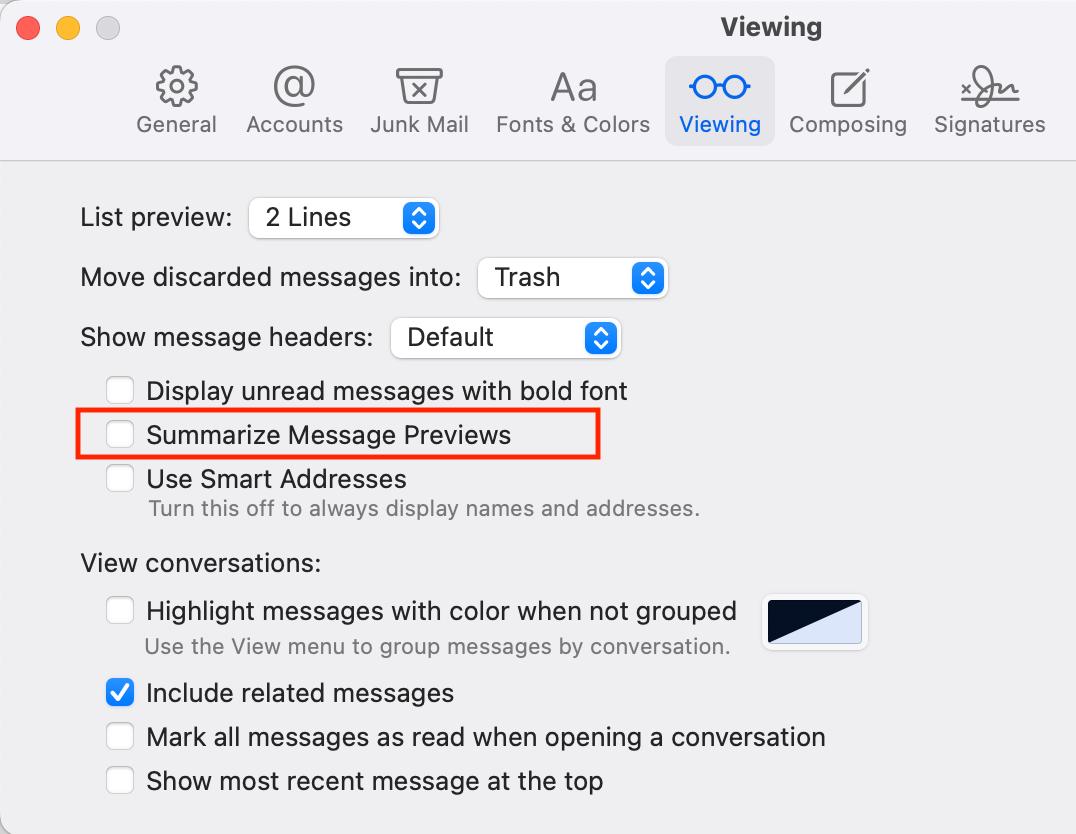
Гугл и поддержка Эпла (читай — AI) как дурачки советуют снять эту галку. То, что это не работает, никого не интересует.


Когда уже мир отпустит? Начинает немного раздражать.
-
Ссылки должны быть записаны
Прошлую заметку можно выразить другим тезисом, а именно: каждая ссылка должна быть записана. В файле, в задаче, в заметках, где угодно. Когда это так, нет смысла хранить ее все время открытой.
Например, мне нужно сделать что-то нетривиальное в Постгресе. Путем гугления я нашел два ответа на StackOverflow, два раздела документации и пару чьих-то блогов. Всего шесть ссылок. Можно хранить их открытыми все время, пока работаешь над задачей. А можно добавить их в задачу и спокойно закрыть.
Почему второй способ лучше? По многим причинам, и самая важная – взрослый, организованный подход. Вместо того чтобы сидеть на ссылках, как царь Кощей над златом, мы делимся ими с другими. Возможно, в будущем к этой задаче кто-то вернется и найдет эти ссылки. Их проще скопировать и переслать. Если работа основана на сторонних материалах (код, замеры быстродействия), я считаю правильным ссылаться на источники, чтобы было понятно, откуда решение.
В комментариях кто-то писал: моя задача требует документации, ссылок на то, се, пятое-десятое плюс макеты в Фигме. Так добавь эти ссылки в задачу! Или ты ждешь, что каждый участник будет искать эти ссылки? Это же свинство.
Разумеется, так мало кто делает, ровно как мало кто соблюдает сетевой этикет и правила переписки. Это тот случай, когда нужно не смотреть на других, а самому ставить нормы поведения. Например, добавлять в задачи ссылки на все нужные материалы и просить других делать так же. Может быть, кто-то поймет, что это правильно.
Или ты открыл десяток вкладок и тебя экстренно перекинули на другую задачу, а она тоже требует 10 вкладок. Так и будешь хранить первые десять? Я понимаю, что есть разные профили, окна, группировки… но не говорите, что все это работает как надо, я даже слушать не хочу. Разве не было такого, что браузер вылетел и все забыл? Или обновился и показывает одинокую вкладку “What’s new”?
Запись ссылок важна даже если работаешь в одиночку. Скажем, пилю я свой клиент к Постгресу и мне нужны:
- ссылки на документацию
- ссылки на исходники Постгреса
- ссылки на чужие клиенты, чтобы подсматривать решения
- вопросы на StackOverflow
- всякие мейл-листы.
Поэтому я завожу в репозитории файл
links.mdи пишу туда ссылки.Когда кто-то говорит, что у него пять сотен вкладок, увы, я не верю, что в них возможен какой-то порядок. Это самообман. Все сводится к принципу: записал – отпустил. Пока что-то не записано, оно не свободно. И мы тоже от него не свободны.
-
Табы и закладки
Раз уж заговорили о браузерах, выскажу еще одну мысль.
Меня удивляет, как много обсуждают табы и закладки. Когда выходит какой-нибудь Вивальди и об этом постят новость, комментари сводятся к табам и закладкам. Когда будут вертикальные табы? Когда группировка? Когда автозакрытие как в расширении X? И так далее.
Иногда мне даже жаль разработчиков, потому что сделать так, чтобы понравилось всем, невозможно. Всегда найдется чудак, которому нужны табы по диагонали, в крапинку и с синхронизацией через Амазон в докере. Приходится объяснять, что этого не планируется, а он будет поливать разработчиков дерьмом.
Поэтому расскажу, как управлять табами в любом браузере: будь то Хром, форк Фаекфокса или что угодно. Записывайте: когда у вас много табов, зажмите клавиши Ctrl/Command + W. Все табы закроются. После этого откройте табы, что нужны для текущей задачи. Конец.
Я использую эту схему много лет. Расплодились табы – сношу к чертям и начинаю сначала. Не нужны расширения и синхронизации, вертикальные-горизонтальные и прочий бред.
Уже рассказывал: человек шарит экран, и у него в Хроме 30 вкладок. И не вздумай говорить, что ты ими управляешь!!! Табы сжаты до размеров иконки – как ты найдешь нужный таб? Только перебором: вот этот таб, ой, не тот, ой, другой, ага, вот этот. В чем прикол тыкать каждый раз как слепой щенок? Это как набрать в руки десять предметов и утверждать, что можешь управиться с каждым.
Будь я разработчиком браузера, я бы открыто сказал: ребят, если вы держите 40 вкладок, вам нужно не расширение, а пойти прогуляться.
Сюда же относятся закладки: тратят сотни часов, чтобы найти расширение и настроить синхронизацию. А потом ноют, что в каком-то андроиде не подсосались последние ссылки.
Решение простое: храните ссылки в файлике, который синхронизируется через Dropbox, iCloud или что там у вас. У меня это файлы
music.md,postgres.mdи другие. Содержимое примерно такое:# Silent Hill 2 Remake OST https://www.youtube.com/watch?v=UFBq69uB-es&list=PLjvrSyTT3pvSbHUpqC3sSC3b9Fq7NuF6b # J. S. Bach - Organ Works - Lionel Rogg - DISC 2/12 https://www.youtube.com/watch?v=rudjAUtfx-g # Toccata & Fugue in C Major, BWV 564 https://www.youtube.com/watch?v=kxtJ_av5NHo # Pink Floyd - Obscured By Clouds (1972) [Full Album] https://www.youtube.com/watch?v=Te_-nISxLVIПоскольку это маркдаун в Емаксе, то работают всякие плюшки. Клик на ссылку открывает ее в браузере, есть быстрый переход по заголовкам, просмотр оглавления и так далее. Можно делать несколько уровней, например так:
# Ambient ## Portal 2 ## Klaus Schulze # Rock ## Queen ## Pink Floydи оно будет красиво отображаться в виде дерева. Но мне достаточно одного уровня. Схема проста как лопата, в ней нечему ломаться. Обновление браузера и расширений на нее не влияют. Что еще нужно?
Конечно, кто-то всплакнет, мол, неудобно на телефоне. Ну и пусть – пока ты не за компом, надо смотреть на солнце, а не тупить в экран. А если не дочитал статью, то кинь ссылку себе в Телеграм, в чем проблема?
Главная мысль этого поста: не быть рабом своих желаний. Хочется такие-сякие табы и закладки – перехочется. Бери то, что не сломается ни при каких обстоятельствах. На долгой дистанции это единственный вариант.
-
Летнее время
Как известно, перевод часов на летнее время несет сплошную пользу. Прямо так хорошо от него, так хорошо, что аж сам себе завидую. И под это дело потерял день рабочего времени, и остальные тоже.
На работе я занимаюсь отчетностью. В Амазоне у меня зашедулено много отчетов, каждый из которых уходит своим потребителям. Большинство из них я сделал прошлой осенью и зимой, когда у заказчика было время +1. А весной произошло вот что.
Если не указать в Амазоне часовую зону cron-выражения, то по умолчанию берется UTC. Это хорошо, потому что точка отсчета фиксирована. Но одно и то же время UTC в зависимости от времени года дает разное локальное время. Например, зимой время 08:00 am UTC будет 9:00 am UTC+1, а летом – 10:00 am UTC+2.
Это значит, что после перевода часов потребители получат отчеты не в 9 часов, а в 10 по местному времени.
Начались жалобы: что-то подумал, что все сломалось, кто-то не успел предоставить отчет к созвону, где-то упал скрипт, который перекладывает отчеты в другое место. Починил так: нужно указать под cron-выражением местную зону, например
Europe/<City>, и сдвинуть часы так, чтобы они совпадали с зимним временем, по которому работало раньше. На то, чтобы разобраться, задеплоить и проверить, ушел день. В первый раз я поднял часы на +2 вместо +1, и пришлось переделывать.Коснулось и других коллег: Майкл, почему твоя задача запустилась на час позже? И Майклу предстоит то же самое: считать на бумажке часы, деплоить и проверять.
У меня стойкая ассоциация: каждые полгода страна садится голой задницей на гвоздь. За полгода рана заживает, и кажется, что в этот раз обойдется без последствий. Но нет: снова боль, снова проблемы, крики. Никогда такого не было, и вот опять.
Спрашивается: сколько можно? Сколько еще нужно выбросить времени, денег, нервов, здоровья, чтобы чиновников отпустило? Десять лет? Сто лет? Уверен, в будущем над нами будут смеяться: представляете, дети, эти придурки на рубеже тысячелетий гоняли часы туда-сюда, чтобы сэкономить тысячу долларов на 20 миллионов человек. Примерно как раньше сжигали людей, чтобы задобрить бога – с таким же результатом.
Слышал, что за перевод времени люто топил Яков Перельман. Что неудивительно: более яростного человеконенавистника нужно еще поискать. Может, хватит брать с него пример?
Writing on programming, education, books and negotiations.