-
Кража дизайна
Иногда я слушаю дизайнера Женю Арутюнова, он говорит клевые вещи. Говорит мягко и с самоиронией. Не бывает так, что слушаешь тезис, а потом: кто не со мной, тот мудак.
У Жени как-то спросили, как не красть чужой дизайн. Он ответил: спокойно воруй, потому что даже если не будет последствий, ты увидишь, что чужой дизайн не решает задачу полностью. Чтобы решал, нужно поправить здесь, поправить тут, и в итоге краденый дизайн либо развалится, либо изменится так, что перестанет быть краденым.
То же самое можно сказать про код. Даже если вы украли чей-то код, заставить работать его на вас трудно. Адаптация кода под задачу займет столько времени, что проще написать свой. А если выигрыш и возможен, его трудно оценить.
Иные проекты тянут сотни зависимостей — их написали другие люди. И все-таки мы пишем и отлаживаем свой код в папке src. Есть даже похожие сервисы и бизнесы, и некоторые с открытым кодом. Но нет — не смотря на колоссальные объемы открытого кода, нас продолжают нанимать. Мы пишем код, ловим баги, сидим в отладчике.
Именно поэтому когда случилась колоссальная утечка Яндекса — 50 гигабайтов исходников — я даже ухом не повел. Их обсасывали на всех новостных ресурсах, но скажите: что вы хотели там найти? Обычный корпоративный код: прочитать JSON, проверить его, положить в базу, дернуть очередь, записать в лог, собрать эксепшены в сборщик ошибок.
По той же причине я скептичен к коду, написанному ИИ. Пусть он пишет тетрис и змейку, этого добра на Гитхабе пруд пруди. Как мне поможет ИИ, если нужно впендюрить очередной if цепочку бизнес-процессов, чтобы ничего не упало? Как он придумает новый твиттер? Как он придумает игру, где участники отрывают жопы от стула(!) и идут в парк ловить виртуальных зверей?
Идея первична, лишь затем следует код.
Вот почему, имея горы открытого кода, мы, словно герой Никулина, ищем “такой же, но с перламутровыми пуговицами”. Потому что требования. Потому что это наша работа.
-
Телефонный спам
Ситуация с телефонным спамом печальная. Звонки поступают часто, и самое главное — их качество растет феноменально. Живые люди уже давно не звонят, вместо них на проводе “интеллектуальные помощники” — боты с элементами ИИ.
Иногда я слушаю, что скажет тот или иной “помощник”, чтобы быть в курсе технологий. Повторюсь, качество просто запредельное. Хорошо подобраны фоновый шум, интонация, неточности разговорной речи. Бот определяет, когда его пытаются перебить и вежливо просит дослушать до конца, а потом обсудить вопросы. Дерево сценариев огромно, продумано много случаев.
Не сомневаюсь, что многие люди говорят с ботом как с живым человеком. Не зная заранее, что звонки автоматизированы, легко принять бота за чистую монету.
По-настоящему раздражает несколько вещей. Первая — именование спама. Подобно тому, как взрыв называют “хлопком”, а пожар — “задымлением”, спамерские услуги называют “информированием” населения, а ботов — “интеллектуальными помощниками”. Такая манипуляция вызывает тошноту.
Вторая вещь — полный беспредел со звонками при помощи ПО. Еще можно понять, когда нанимают студентов в колл-центр. Но когда скрипт фигачит столько звонков, сколько выдерживает сеть оператора до временного бана, это ни в какие ворота.
Третья вещь — должно быть предупреждение, что обзвон совершает робот. Помнится, такое хотели принять в США, чтобы, когда говоришь с ботом, было предупреждение: с вами говорит робот. А тем, кто предупреждение не ставит, выкатывать конский штраф. Не знаю, приняли или нет, но считаю, это должно быть.
С телефонным спамом борются и фирмы. Почти у всех операторов есть услуга “антиспам”, и она даже работает, я проверял. Тиньков разрывает звонок и шлет смс, что это спам. Но почему фирмы борются с фирмами при полном попустительстве закона?
Напоминает современный веб: трекинг — блокировщики, еще больше трекинга — еще больше блокировщиков, а при открытии вкладки закипает мой ноут.
Пожилые люди запуганы спамерами и мошенниками. Много раз наблюдал: у человека звонит телефон, неизвестный номер, он смотрит на цифры, пытаясь определить — спам или нет? Думает, местный или нет, боиться принять вызов… до чего довели!
В моем случае было три раза, когда я не мог дозвониться людям старше себя. Я не был в их телефонной книжке, и вдобавок у меня виртуальный оператор с чудными цифрами. Вместо привычных 933 человек видел загадочные 399 и поэтому не брал трубку. Приходилось писать в вацапы-вайберы, чтобы догнать.
От некоторых ребят я слышал, как они живут припеваючи, разрешив вызов только с номеров в телефонной книжке. У меня не получилось: стоило включить это правило, как не дозвонился курьер, сорвалось мероприятие, разминулся с сантехником и прочая бытовуха.
Объясните родственнику: если он сомневается в номере, пусть сбросит вызов и перезвонит через минуту. В лучшем случае он никуда не дозвонится, потому что у мошенников динамический пул номеров. Если это банк с кредитом, он услышит музыку и номер в очереди. Наконец, если это был обычный человек, он примет вызов.
И покажите, как блокировать номер из списка недавних вызовов, это несложно. Шанс, что через месяц позвонят с этого номера, хоть и мал, но есть.
-
Синтаксис Лиспа
Когда неподготовленный человек видит Лисп, он как-то реагирует: хихикает, лепит эмодзи, вовлекает других, словом — переживает. В такую минуту он напоминает школьника, который принес эротический журнал: смотрит на груди и попы, конфузится, краснеет, показывает другим под партой. Вроде бы интересно, но что с этим делать — не понятно.
Хорошо, если бы программистам объяснили: Лисп — лучший способ записать код. Любой язык можно улучшить хотя бы тем, что сделать синтаксис лиспо-подобным. Пусть даже парадигма останется прежней.
У скобочной записи есть преимущество: каждое выражение имеет начало и конец. Убедитесь, что прочли последнее предложение вдумчиво. В Лиспе каждая форма имеет начало и конец. В других языках — нет.
Предположим, я вижу выражение:
x = foo + barЗначит ли это, что выражение закончено? Конечно нет. За
barвполне может быть продолжение:x = foo + bar * kek + lolКроме того, что выражение определяется “на глазок”, сюда вкрадывается приоритет операторов:
bar * kekнельзя разорвать.В то время на Лиспе первое выражение будет таким:
(var x (+ foo bar))Скобки задают границы. Если скобка закрылась, то выражение закончилось, точка. Все, что следует дальше, относится ко внешнему выражению. Второе выражение сводит на нет котовасию с приоритетом операторов:
(var x (+ foo (* bar kek) lol))Все задано явно, вопросов быть не может. Вы, конечно, скажете, что приоритет умножения известен каждому школьнику? Тогда счастливой отладки дебажить что-то такое:
Some shit = foo && bar || test ^ foo;Из сказанного следует, что в Лиспе удобно работать с выражениями. Например, я могу выделить текущую форму. Обратите внимание — форму! Не метод, не сложение чисел, не класс, а именно форму! Потому что в Лиспе все это — форма. Мне не нужны хоткеи “Select method”, “Select class”, “Select whatever”. Мне достаточно одной клавиши, чтобы покрыть все случаи.
Формы в Лиспе можно разбивать и объединять. Стоит нажать кнопку, и выражение
(+ foo bar)становится просто+ foo bar. Далее я могу что-то сделать с его элементами. Форму можно двигать выше, ниже по текущему уровню вложенности. Можно втолкнуть ее внутрь. Можно вытолкнуть наверх из-под условия.Форма может поглощать другие формы. Например, у меня есть код:
(do-some-stuff x y z)Теперь нужно, чтобы форма была внутри условия. Прямо над ней я пишу:
(when some-condition) (do-some-stuff x y z)Далее, находясь внутри
when, я жму кнопку, и форма втягивает в себя следующую за ней форму, и получается:(when some-condition (do-some-stuff x y z))Разумеется, есть другая кнопка, чтобы “выплюнуть” форму, и я получу то, что было до поглощения.
Каждый думает, что к нему это не относится, ведь он же пишет не на Лиспе. Но вот реальный пример на Джаве с цепочкой футур:
return prepare(sql, executeParams) .thenCompose((PreparedStatement stmt) -> sendBind(portal, stmt, executeParams)) .thenCompose((Integer ignored) -> sendDescribePortal(portal)) .thenCompose((Integer ignored) -> sendExecute(portal, executeParams.maxRows())) .thenCompose((Integer ignored) -> sendClosePortal(portal)) .thenCompose((Integer ignored) -> sendCloseStatement(stmt)) .thenCompose((Integer ignored) -> sendSync()) .thenCompose((Integer ignored) -> sendFlush()) .thenCompose((Integer ignored) -> interact(executeParams)) .thenCompose((Result res) -> CompletableFuture.completedFuture(res.getResult()));Каждый видит в меру своей испорченности, но я вижу здесь Лисп. Ему немного не повезло: нужно только переставить скобки, и получится нормально. Но вот курьез: Джава-человек в упор этого не видит. Для него это по-прежнему код на Джаве, а переставишь скобки — и сразу смешно.
Теперь нужно изменить код так, чтобы
stmtоставался в поле видимости на большее число шагов. Получится вот так:return prepare(sql, executeParams) .thenCompose((PreparedStatement stmt) -> sendBind(portal, stmt, executeParams) .thenCompose((Integer ignored) -> sendDescribePortal(portal)) .thenCompose((Integer ignored) -> sendExecute(portal, executeParams.maxRows())) .thenCompose((Integer ignored) -> sendClosePortal(portal)) .thenCompose((Integer ignored) -> sendCloseStatement(stmt))) .thenCompose((Integer ignored) -> sendSync()) .thenCompose((Integer ignored) -> sendFlush()) .thenCompose((Integer ignored) -> interact(executeParams)) .thenCompose((Result res) -> CompletableFuture.completedFuture(res.getResult()));Знали бы вы, как тяжело это было сделать! Поскольку у нас не формы, а выражения, приходится выделять каждое мышкой, вырезать и копировать. Ошибся на одну скобку — и все, начинается ад. Окончание каждого метода неочевидно. Над таким примитивным рефакторингом я сидел полчаса. В Лиспе я бы подвинул формы, даже не отдав себе отчета в том, что делаю.
Что тут можно сказать? Есть вещи, которые хоть и были открыты давно, остаются непревзойденными. Синтаксис Лиспа — одна их них. Много воды утекло с 1958 года, но в плане работы с кодом удобней ничего не придумали.
Не обязательно писать на Лиспе, но нужно знать эту его сторону. Чтобы не выглядеть глупо, не хихикать и не прыскать в кулачок, когда случится увидеть Лисп.
-
Список дел
Как и все остальные, я пробовал разные способы GDT — методы завершения дел. До сих пор помню восторг, когда перенес дела в список и казалось бы — бери с головы и делай. Но дела никогда не кончаются, список неограниченно растет с хвоста, и наступает апатия. Зачем вести список, если он никогда не кончится? Зачем разгребать это дерьмо, если всегда наложат сверх всякой меры? И вообще, кто мы, откуда и куда идем?
Даже если в какой-то день порвать рубаху и выполнить десять дел, придет новых десять дел. Это как убраться в квартире навсегда, чтобы больше не убираться. Так не бывает.
Я понял, что список дел — это бесконечный источник. В норвежских легендах была история о том, как разыграли Тора. Ему дали отпить вина из рога, который был соединен с морем. И даже он, будучи полубогом, отпил лишь часть. Ваш список дел — такой же рог, одним концом соединенный с бесконечностью.
Эта аналогия в корне меняет дело. Я по-прежнему веду список дел — не в программе, а на бумаге — но твердо понимаю, что сделаю далеко не все. Я установил правило — выполнять пункты с минимальной производительностью, например — одно дело в день и не больше. Сделав одно дело, в идеале с утра, становишься героем на оставшийся день и не чувствуешь угрызений.
В какой-то день вообще устраиваю “выходной” — никаких сторонних дел, только работа и тупняк в интернете.
Вот так, разгребая дела на минималках, подобно улитке по склону Фудзи, как-то справляешься. Список дел выглядит списком, но на самом деле он становится процессом. А у процесса нет конца.
-
Снова о выпадающих меню
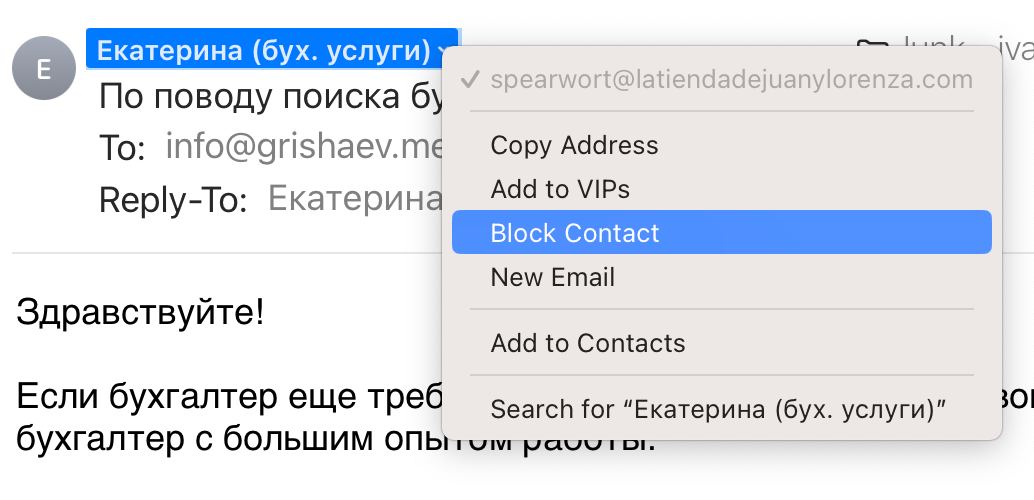
Пришел спам, хочу добавить отправителя в бан-лист. И вот опять: почему контекстное меню не упорядочено по алфавиту? Почему сначала идет Copy, потом Add, а потом Block? Почему Add to Contacts отделен черточками и находится посередине? Чем он отличается остальных групп меню?
Почему контекстные меню всегда такие? Почему в них ничего не упорядочено по алфавиту? Почему нужно каждый раз бежать по списку сначала за O(N)? Почему пункты относятся к разным группам безо всякого смысла?
Почему, почему, почему?
-
Контекст
Расскажу про ужасный паттерн, который разгребаю уже в третьем проекте. Что самое ужасное, он попадается в Кложе. Вы, наверное, слышали, что в Кложе только пони и радуга, там не отцветает жасмин и не смолкает пение птиц? На самом деле в ней так быдлокодят, что тушите свет.
Речь о паттерне “контекст”. Это когда через приложение прокидывается мапа, в которой:
- текущий запрос
- текущие пользователь, сессия, токен
- подключение к базе
- подключение к Эластику
- подключение к кешу
- прочитанные файлы-справочники, например классификаторы, валюты и прочее
- переменные среды
- настройки логирования
- подключение к очереди задач
- еще миллион разных ключей
Эта мапа гуляет по стектрейсу, при этом каждый участник что-то оттуда читает или складывает свое барахло. Увидев в коде ctx или context, нужно отматывать на три экрана вверх, чтобы понять, кто и что туда сложил.
Случайный принт этой мапы убивает Емакс, потому что он захлебывается в выхлопе и попытке его распарсить. Знаю как обойти, но все же.
Отдельные гении оборачивают мапу в атом, чтобы она стала мутабельной! В результате ищи-свищи, кто поправил это поле по всему стеку вызовов.
Вот прямо сейчас, дорогая редакция: человек кладет в контекст подключение к базе. Ниже по стеку он берет подключение из контекста, открывает в нем транзакцию и снова кладет в контекст поверх старого, чтобы все, кто ниже, работали с транзакционным подключением. Такая схема ломается в два счета, что я и сделал, а затем два дня искал, почему посыпались данные в базе…
Интересно, что в Кложе есть библиотеки Component, Integrant и Mount для управления системой компонентов. У каждой плюсы и минусы, но выбрать есть из чего — не говоря о том, что некоторые ребята пишут свои менеджеры систем. Но найдется умник, который скажет — это скучно, джава-вей, давайте через мапку прокидывать.
Другими словами, человек не знает, как организовать зависимости между компонентами. Он выбирает самое глупое решение — хранить все в одном месте — и маскирует провал рассказами о простоте и докладами Рича Хикии.
Словом, знайте — в проектах на Кложе много любительского быдлокода. Порой я жалею, что нет фреймворка уровня Джанги, где все прибито гвоздями и за шаг в сторону — расстрел. Глядишь, hammock driven-девелоперы чему-нибудь подучились.
-
Облачная учетка
В повести 1984 герой читает книгу братства. В числе прочего ему попадаются строки: “нужно, чтобы колеса индустрии вращались, но мир оставался бедным”. В мире Оруэлла решением стала война, которая сжигала лишние ресурсы.
Эти строки напомнили о том, что происходит с разработкой софта. Недостаточно выпустить программу и продать ее. Нужно навязать услугу, за которую пользователь платит постоянно. Решением стала облачная учетная запись.
В самом деле, как раньше писали софт? Выпустили условный The Bat! или WinAMP версии 1. Продали. Через год выпустили версию 2. Тоже продали. Третья версия либо вышла унылым г..вном, потому что идея выдохлась, либо пользователи не хотят обновляться, либо продавать уже некому. Поток денег иссяк, а штат за эти годы только распух, и чем платить зарплату, тоже не ясно.
Идеальное решение — посадить клиента на ежемесячную подписку, но как? Для этого нужно обоснование, ведь если ты выпускаешь программу раз в год, то резонно услышать вопрос — за что подписка?
Облачная учетка снимает эти проблемы. Она требует хостинг (конечно, в Амазоне) со всеми вытекающими: виртуальные машины, база данных, файловое хранилище, очередь задач и другие облачные штучки. Плюс нужны пара бекендеров, пара фронтов, специалист по безопасности. Все это требует денег просто за факт своего существования. Еще емейл рассылки, копирайтер и верстальщик писем.
И вот фирма выпускает анонс, что для нашего же блага (!) для работы программы нужна учетная запись. Все, кто ее покупали, получат полгода грейс-периода, а потом — плати или до свидания.
Примеров на моей памяти было достаточно. Шесть лет назад я покупал 1Password версии 5. Сегодня он не работает без облачной учетки: первый экран требует авторизации — на мастер-пароля, как раньше, именно облачной учетки.
Программа Dash для офлайн-документации пошла тем же путем. Я купил версию 6, а уже следующая версия перешла на подписку.
Я понимаю подписку с точки зрения бизнеса: она дает прогноз финансов. Умножаешь цену на число пользователей и готово: точно знаешь, сколько денег упадет на счет. Ясно, что можно планировать, а что нельзя.
Я понимаю подписку как программист: добавил в базу флаг “есть доступ”, и когда подписка оформлена, ставишь true, а если остановилась, то false. На практике не все так просто, но по крайней мере понятно.
У меня у самого был коммерческий пет-проект. Идея о том, что нужно считать потребленные ресурсы и добавлять их в квитанцию, бросала в ужас. Я повесил подписку через Paypal и был таков.
Но я отказываюсь принимать подписку как пользователь. Что 1Password, что Dash, что WinAMP были уже хорошими тех версий, что я их скачивал. Мне не нужен 1Password версии 7 и 8, если шестая отлично работает. Мне не нужна облачная учетка. Мне не нужны емейл рассылки, опросы и остальное. Достаточно, чтобы над программой работал один человек, подчищая баги. Но тогда не будет бизнеса.
Так и получается колесо Сансары: бизнес делает софт, собирает базу пользователей и вводит подписку. Пройдя этот круг раз десять, я понял, что пора выбираться: брать софт, который поддерживается на некоммерческой основе. На первый взгляд он не такой крутой, как коммерческий, но ведет себя лучше на долгой дистанции.
А насмешки я как-нибудь переживу, не в первый раз.
-
Автоответчики
Пока мы не ушли от темы, замечание об автоответчиках.
Операторы бессовестно включают автоответчик на всех тарифах. Это работает так: если абонент не берет трубку в течение N секунд, включается бот, который предлагает записать сообщение и передать его.
Все бы ничего, если бы не прогресс в распознавании речи. Все, что надиктует вам собеседник, будет распаршено и прогнанно через алгоритмы. Если звонила тетушка с просьбой собрать шкаф, то у вас вылезет реклама шкафов и сборки мебели на дому.
Как и в прошлой заметке, автоответчики устроены так, чтобы вытянуть из собеседника максимум информации. Недавно звонил сестре, и после четвертого гудка включился бот. На фоне шум, словно едет маршрутка, и женский голос отвечает — алло? Но голос совершенно другой женщины! Упор на то, что я начну разговор, а в конце бот скажет — спасибо, передам.
То же самое у Тинькова: автоответчик Олег включен по умолчанию. Он начинает разговор с приветствия, не уточняя, что он бот. Расчет тот же самый — собрать как можно больше приватной информации.
Убедитесь, что у ваших родственников, особенно пожилых, выключены автоответчики. Во-первых, будет меньше слива приватных данных. Во-вторых, у родственника будет больше времени принять вызов, потому что оператор заинтересован включить бота как можно быстрее.
-
Борьба с PDF (2)
Недавняя заметка про замену PDF на HTML, была, конечно, бредом. Не получится по ряду следующих причин.
Бизнес-требования. Если руководство или тем более регулятор ожидают PDF, ты им ничего не докажешь. Ни про какой HTML там не слышали.
Подписи. Вокруг PDF построены сервисы и тулинг для подписей. Электронно подписанный PDF имеет такую же силу, как и бумажный договор. В техническом плане подписать HTML легко — достаточно поместить в заголовок тег
<signature>с RSA-ключом, — но опять же, под это нет тулинга.Отображение. Ваша правда, PDF везде отображается одинаково — проблемы бывают в самых редких местах. В случае с HTML неопределенность гораздо шире: может поплыть и на телефоне, и на Линуксе, а в Винде браузер заблокирует base64-изображения.
Но все-таки: порой PDF бывает таким душным! Напрягает его ориентация на бумагу, хотя большинство документов сейчас не печатают, а смотрят с экрана. В таких ситуациях HTML дает больше плюшек: он нормально покажет длинные таблицы без разрывов. В HTML работает минимальная интерактивность. В сложном отчете можно сделать табы на чистом CSS. HTML на ура копируется в офисные документы: скажем, тег
<table>идеально сядет в таблицу Excel, в то время как копирование из PDF — сущий ад.Можно сказать, что PDF и HTML лежат на разных концах одной шкалы. Приближаясь к одному, уходишь от удобств другого.
-
Борьба с PDF (1)
По всему миру люди борются с PDF. Скажем, нужно сгенерить отчет, и начинается: рендерим файл LaTeX и скармливаем pdflatex. Глючно, не очевидно, требует установки Латеха и пакетов. Рассыпается при смене минорной версии. Кросплатформенно только в теории.
Можно собрать при помощи Java-библиотеки. Импортировать двадцать классов
com.pdf.MySuperCellFactoryи как-то их соединить. Тоже не очевидно, трудно дебажить.Неплохой вариант: сгенерить HTML и напечатать PDF при помощи headless-Хрома. Уже лучше, но требует установки Хрома и chromedriver. Запускать Хром на каждый чих расточительно, нужна отдельная машина.
Короче, с какой стороны ни зайди, везде плохо.
Так вот: почему бы не генерить документы в HTML? Стили и картинки зашиты в один файл через
src=data:base64. Получаем один .html-файл без зависимостей. Браузер есть везде, не нужно ничего ставить. При желании можно адаптировать стили под мобильный экран, чтобы смотрелось везде хорошо.Почему так не делают? Зачем PDF, если вот он, HTML: любой шрифт, картинки, таблицы и все прочее?
Writing on programming, education, books and negotiations.