-
Глава 3. JSON в таблицах
Главы
- Введение в документы
- Базовые возможности JSON
- JSON в таблицах
- Индексирование JSON
- Ограничения в документах
- Язык путей JSONPath
- Отчеты и функции
- Функции на языке Python
- Версионирование и архивация документов
- Релевантный поиск
Содержание
- Главы
- Определение сущности
- Дизайн таблицы
- Тосты, сжатие и хранение
- Множественность и статистика
- Генерация и вставка
- Псевдослучайные значения
- Чтение
- Вставка
- Обновление
- Вставка с обновлением (UPSERT)
- Удаление
До сих пор мы работали с документами, которые не превышали нескольких строк. На практике документы объемны и занимают сотни килобайт. В этой главе мы обсудим, как хранить JSON в таблицах, читать его, изменять и удалять – полностью и частично.
Для начала обсудим задачи, которые выполним ниже по тексту. План таков:
-
мы определим сущность, с которой будем работать до конца книги. Ее структура повторяет аналог из проекта, в котором работал автор. Сущность содержит разные типы данных и вложенные поля. На ней мы опробуем техники, которые уже рассмотрели, и многое другое.
-
Подготовим таблицу для документов. Здесь же мы рассмотрим сжатие типов (compression) и понятие множественности (cardinality).
-
Запишем в базу миллион документов. Это будут не клоны одной и той же записи, а псевдослучайные данные. Пороги случайности мы определим сами.
-
Выполним простые запросы: поиск по ключу, поиск по реквизитам, обновление, вставку с конфликтом и другие частые операции.
Цель – получить миллион разнообразных документов и опробовать на них все, что мы изучили.
-
Числа №1. Счет на пальцах
Несколько постов на тему чисел. Начнем с чего-нибудь несерьезного, например счета на пальцах.
Мы привыкли разгибать пальцы при счете. На две руки приходится десять пальцев, а этого мало – хотелось бы больше.
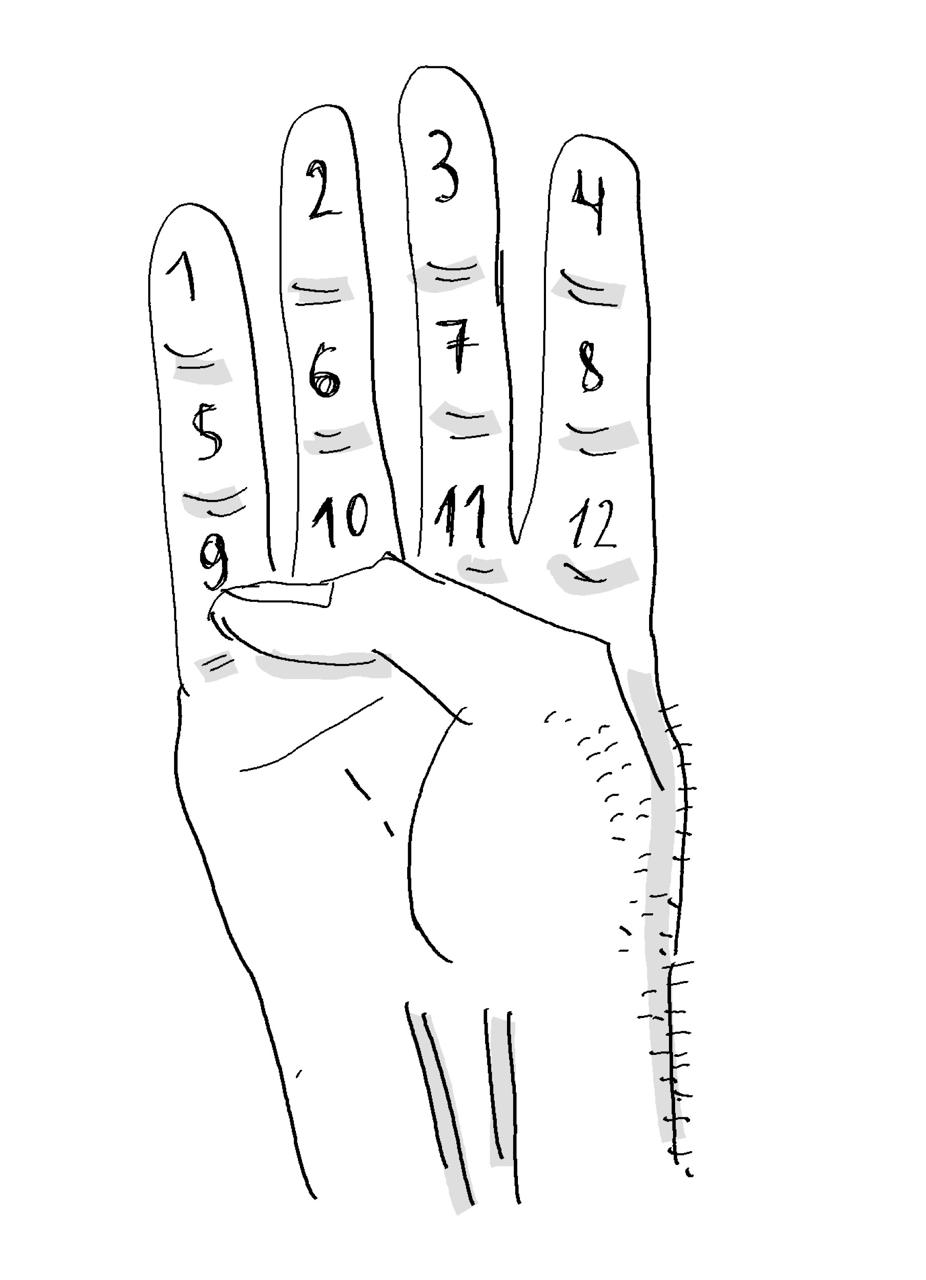
У каких-то шумеров или Майя (не помню точно) был счет на фалангах. Берем все пальцы кроме большого, у каждой три фаланги. На одной руке их двенадцать. Считают, прикладывая большой палец фаланге. Можно слева направо и вниз, можно снизу вверх и направо – как душе угодно.
Две руки — 24 единицы! Почти в два с половиной раза больше, чем обычно.
Когда я прочитал про эту систему, то некоторое время ей пользовался. Привыкаешь быстро – это дело механики. Когда подходишь к десяти, возникает странное чувство – вроде бы много, а пальцы не кончились! И даже руку не сменил.
Счет на фалангах – один из частных случаев счета на пальцах. Разные народы придумали способы, чтобы обойти лимит в десять пальцев. Ознакомьтесь в Википедии.
-
Мульты №4
Может быть, вы не смотрели “Трио из Бельвилля”. Если так, уделите ему время. Мульт необычный, он не похож ни на что другое, очень самобытная вещь. Вышел в 2003 году, завоевал множество премий.
На юге Франции живут бабушка и внук (родителей можно увидеть на фотографиях, но что с ними – неясно). Внук любит велосипед, становится велогонщиком. Во время “Тур де Франс” он сходит с маршрута, и его похищают странные личности. Бабушка отправляется в погоню, пересекает океан и оказывается в мегаполисе Бельвилль – очевидно, копии Нью-Йорка. Всюду толстяки и неприветливость. Здесь же обосновалась итальянская мафия, которая похищает спортсменов и устраивает подпольные ставки. Бабушке предстоит разрушить планы мафии, спасти внука и вернуться во Францию.
Необычность в том, что главным героем становится бабушка, а не внук. Внимание приковано к мальчику, и когда он пропадает, кажется, что это на пять минут. Но именно бабушка пересекает океан на катамаране, находит мафию и карает наркобосса.
В мультике почти нет разговоров, и это дает особый шарм. Бабушка и внук, пока еще вместе, настолько понимают друг друга, что ничего не говорят: каждый знает, что нужно другому, и потому слова излишни. Детали не проговариваются, их нужно читать с предметов: картин, фотографий, одежды.
Замечательно проработаны персонажи. У каждого свои привычки, которым они следуют на протяжении всего фильма. Бабушка поправляет очки одним и тем же жестом. Пес Бруно лает на поезда, потому что в детстве паровозик наехал ему на хвост. Оказавшись на другом конце земного шара, он по-прежнему подстерегает электрички, чтобы полаять на них. Постоянство этих привычек делает персонажей живыми.
В мультике мало звукового сопровождения, в основном шумы: скрип полов, звон посуды, гул улицы. Но шумы, напротив, только усиливают погруженность. В некоторых моментах играет Великая месса Моцарта.
Трудно понять, чему учит “Трио”. Мультфильм очень самобытный, и каждый извлечет из него что-то свое. Режиссер посвятил его родителям: возможно, этим он пытался сказать, как многим мы им обязаны. В последнем кадре мы видим постаревшего внука; он слышит голос бабушки из начала фильма. Это напоминание, что благодаря ей он прожил долгую жизнь.
Я бы не предложил “Трио” в кандидаты на лучший мультфильм, но ознакомится с ним стоит.




-
Мульты №3
Еще один незаслуженно забытый мульт, о котором хотелось бы рассказать — это “Титан: после гибели Земли”. Вышел в 2000 году, в оригинале называется Titan A.E. Буквы A.E означают After Earth и подразумевают эру подобно BC и AD.
Будущее, человечество осваивает космос. Герой — мальчик, отец которого работает над секретным проектом. На Землю нападают дреджи — пришельцы, похожие на протоссов из Старкрафта. За считанные минуты они уничтожают планету. Лишь немногие успевают улететь включая мальчика. Отец спасает проект, и судьба его неизвестна.
Проходят годы. Люди живут на космических станциях в положении бомжей, а то и рабов. Без своей планеты они никто. Мальчик вырос, работает техником на станции, получает люлей от других рас. Отец оставил послание: он работал над кораблем “Титан”, который может построить планету. На борту содержатся геномы всех организмов и растений, источник энергии для первого поселения. Словом — бекап Земли. Отец его спрятал, осталось найти и включить. Парень отправляется на поиски.
Финал грандиозен: корабль спрятан среди ледяных колец, к нему устремляются все стороны конфликта. Происходят бои, предательства, жертвы и так далее. В последнюю секунду Титан запускают, и он дает люлей флоту дреджей. Затем формирует из мусора планету, пригодную для обитания. На нее слетаются люди, начинается новая эра летоисчисления — AE.
Такой вот сюжет, а реализация подкачала. При всем масштабе мульт провалился в прокате. Сборы были такими низкими, что фильм досрочно сняли с программы. По этой же причине свернули одноименную игру для Playstation, к которой уже приступили.
Трудно понять, отчего фильм постигла такая неудача. Даже если найти отдельные недостатки, у него прочный хребет — сюжет, где все герои приходят в финалу. У героя есть внешний конфликт (пришельцы) и внутренний (отец многое держал в тайне). Есть любовная линия: парень и девушка конфликтуют, но становятся парой. Наставник героя оказывается предателем, раскаивается и жертвует собой. Злодеи повержены. При таком сюжете, то есть когда закрыты все вопросы, фильм просто не может получиться провальным.
Я не пересматривал “Титан” с детьми, а просто вспомнил о нем. Привожу его как образец отлично выполненной работы, которая по каким-то причинам не зашла зрителю. Увы, такое бывает. Жаль.
Мультик напоминает, как хрупка наша планета и какая участь ждет того, кто ей не дорожит.




-
Мульты №2
Еще один мульт, о котором хочется сказать добрые слова – это “Стальной гигант” (The Iron Giant). Вышел в 1999 году, студия Warner Brothers.
Америка, 1958 год. Холодная война, СССР только что запустили спутник. Возле крохотного городка из космоса падает огромный робот. Его находит мальчик и прячет сперва в лесу, а потом на свалке металлолома. Робот дружелюбный, но с особенностью: если в него стрелять, он атакует в ответ. Мальчик сталкивается с этим, когда играет с роботом в войну и чуть не гибнет из-за ответки.
Детектив из Вашингтона раскрывает робота и вызывает вояк. Те стреляют, и робот становится машиной для убийства. Мальчик, рискуя жизнью, заставляет робота вспомнить их дружбу и того отпускает – он становится добрым как прежде. По ошибке вояки выпускают ракету в то место, где люди. Робот жертвует собой, сбивая ее в воздухе.
Мульт поучительный: он напоминает, к чему приводит гонка вооружений и мнительность. На примере робота показано, как агрессия порождает агрессию, и только дружба способна ее остановить.
Хорошо переданы настроения и уклад американского общества того времени. Везде газеты о советском спутнике, разговоры про ядерную войну. Детектив уверен, что робота создали китайцы или русские, чтобы уничтожить Америку. В школе проводят “разговоры о важном”: атомный холокост, как выжить при ядерном взрыве и так далее.
Итого – есть над чем подумать. Хороший мульт на нестареющую тему, обязательно посмотрите с детьми.



-
Мульты №1
Заметки о Постгресе не то чтобы надоели, но хочется их чем-то разбавить. Скопилась гора заметок, которые я не писал из-за Постгреса — и пора уделить им внимание! Так вот: речь пойдет о мультиках. В детстве я любил мультфильмы, и многие из них пересмотрел с детьми. В этом цикле речь о тех мультах, которые вы скорее всего не смотрели, и я рекомендую это сделать.
Первый мульт, который мне запомнился — “Планета сокровищ” Диснея. Он особенный, и ниже я объясню почему.
Как ясно из названия, мульт обыгрывает знаменитую историю — “Остров сокровищ”. Дело происходит в будущем, в мире стимпанка а-ля “межзвездные дирижабли на дровах”. Вся техника аналоговая, но работает в космосе. Звездолеты — в буквальном смысле корабли с мачтами и парусами, которые плывут в магнитном пузыре от планеты к планете.
Мульт в точности повторяет ключевые сцены книги. Старый пират передает карту Джиму, и за ним начинается охота. Карта попадает доктору и сквайру, они собирают экспедицию. На борту добрый повар Сильвер. Далее заговор, бегство с корабля, обстрел из плазменной пушки, битва за крепость, переговоры Сильвера и так далее. Тот, кто помнит книгу, оценит, как точно переданы акценты, иной раз — отдельные фразы персонажей.
Сценаристы хорошо передали характер Сильвера и его симпатию к мальчику. Сильвер должен выбирать: быть добрым с Джимом или угождать команде. В мультике это обыграно более линейно, потому все-таки он для детей. Однако тема отношений пирата и юноши идет через весь фильм.
Теперь главное: что же особого в мультике? Студия была довольна им, и еще до выхода в прокат начались работы над продолжением. Однако в прокате “Планета сокровищ” оказалось крайне неудачной. Сборы были низкими, и работы над второй частью свернули. По этой же причине, я уверен, мало кто из вас слышал про этот мульт.
В детстве, посмотрев “Планету сокровищ” на видике, я был в восторге. А когда пересмотрел с детьми, задумался, почему провалился прокат. Думаю, дело вот в чем: картина полностью производна от книги. Идти на нее нужно только в том случае, если вы читали “Остров сокровищ” — причем не смотрели другие фильмы, а именно читали книгу. Разумеется, все сотрудники Диснея читали ее, потому что это классика. Фильм оценивали по тому, насколько точно он передает книгу, и по этому критерию он на высоте.
Мои дети тоже читали книгу (со мной и сами), поэтому мульт им зашел. Но современные американские дети, которые шли в кинотеатры, вряд ли читали “Остров”. В отрыве от книги фильм, хоть красочный, теряет смысловую нагрузку. Книга, пусть и небольшая, не может быть передана целиком за час с лишним. Те или иные сцены подразумевают, что читатель знает контекст из книги.
Разумеется, это всего лишь догадки: я не знаю наверняка, чем не угодил американскому зрителю этот мульт. Однако это не повод его игнорировать: будет время — посмотрите “Планету сокровищ” с детьми. Уважьте незаслуженно забытый труд.




-
Postgres №42
Как мы выяснили, открывать соединение на каждый запрос – медленно. Во-первых, новый сокет – это системный вызов и аллокация ресурсов в операционной системе. Во-вторых, после открытия сокета клиент и сервер обмениваются начальными сообщениями. Сервер сообщает, каким образом нужно пройти авторизацию, клиент проходит ее (а это еще несколько сообщений), после чего сервер высылает метаданные (локаль, формат дат, кодировки и так далее). Представьте, что все это происходит на каждый запрос – быстродействие падает на два порядка.
Среди прочего рассмотрим авторизацию. До версии 15 алгоритм по умолчанию был md5. Он довольно прост: нужно сцепить пользователя и пароль, посчитать md5, приклеить соль, взять md5 еще раз, а затем привести к hex-строке:
message = hex(md5(md5(user+password) + salt))Эта авторизация занимает одно сообщение сервера и одно клиента. Вычисления клиента при этом простые: два md5-хэша.
С версии 15 авторизация по умолчанию называется scram. Она происходит в несколько шагов, примерно так:
- сервер говорит: начинаем авторизацию scram, доступны варианты sha-256 и sha-256-plus (о них позже);
- клиент загадывает случайный массив байтов и отправляет серверу;
- сервер возвращает особую крипту и число шагов (по умолчанию 4096);
- клиент выполняет цикл из 4096 итераций, где на пароль накладывается XOR-ом байтовый массив и вычисляется отпечаток hmac sha265; эта крипта отправляется серверу;
- сервер отправляет финальную сигнатуру. Клиент проверяет ее и если что не так, кидает исключение.
Вся эта котовасия нужна вот зачем:
- клиент считает не пару md5-хэшей, а множество XOR- и hmac-операций. Это крайне осложняет брутфорс;
- сделать реверс 4096 операций — задача нереальная в отличие от md5;
- scram допускает защиту от человека посередине (разберем чуть позже).
Итого, чтобы авторизоваться, клиент вычисляет хэши в цикле. Это гораздо дольше обычного md5. Поэтому со scram новое соединение обходится еще дольше, чем раньше.
Что касается защиты от MITM, то scram предлагает интересное решение. Клиенту сообщают, какие подвиды авторизации доступны (sha-256 и sha-256-plus), и он может выбирать. Метод sha-256-plus называется связыванием каналов. Он работает так: если мы соединяется по SSL с TLS, то первоначальная крипта, которую загадывает клиент, берется из т.н. peer-сертификата. Это первый сертификат в цепочке TLS, и его особенность в том, что он общий для сервера и клиента. Все вычисления отталкиваются от него, и это гарантирует, что между клиентом и сервером нет посредника.
В самом деле: если такой посредник есть, у него открыты два соединения: с клиентом и сервером, и он перекладывает пакеты между ними. Однако peer-сертификаты у клиента и сервера будут разные. В результате вычисления не сойдутся, и авторизация не пройдет.
Так что scram, хоть и замедляет авторизацию, делает ее безопасней и учитывает много нетривиальных штук.
Посмотреть реализацию scram на Джаве можно тут.
-
Postgres №41
В прошлых заметках мы говорили про пулы соединений вроде HikariCP. Их еще называют пулами приложения. Это библиотека, которая открывает соединения, одалживает их тредам и закрывает. Аналогично устроен пул на Питоне из состава psycopg2.
Есть, однако, другой подход – пулы на уровне сети. Запускается утилита, которая притворяется сервером Postgres (разговаривает по протоколу PG Wire). Она открывает несколько соединений к целевой базе. Как только к ней подсоединяются, она помечает одно из соединений как занятое. Далее она перекладывает сообщения от клиента серверу и обратно. Как только клиент уходит, занятое им соединение помечается свободным. Все это напоминает HTTP-прокси, только с другим протоколом. Наиболее известный PG Wire прокси – это pgbouncer; есть и другие аналоги.
Pgbouncer отлично подходит для платформ, где по каким-то причинам нет пула приложения. Например, в PHP, многократно вызывая
postgres.connect(), мы будет соединяться с сетевым пулом, который направит сообщения в одно из заранее открытых соединений.Кажется, что решение идеально: поставил перед базой
pgbouncerи готово: превысить лимит подключений невозможно. Однако мне подход с pgbouncer не нравится, и вот почему.Во-первых, появляется бутылочное горлышко, за которым нужно следить. Если
pgbouncerили аналог отвалится, доступ к базе пропадет у всех. Сюда же относится конфигурация: нельзя перезагрузить pgbouncer, потому что отвалятся все клиенты.Во-вторых, когда у каждого приложения свой пул, это дает гибкость. Скажем, одному сервису понадобилось больше соединений, второму – меньше. Это легко исправить, не затрагивая всю инфраструктуру. Потреблением базы таким образом можно управлять гранулярно.
В-третьих,
pgbouncerвидится мне костылем для платформ, где нет своего пула соединений. Постоянные подключения к pgbouncer – это открытие сокета и системные вызовы, которых можно избежать, будь у вас нормальный пул.AWS предлагает
pgbouncerза отдельную плату. Не хочешь возиться с пулами – будь добр плати.Итог последних трех заметок. Никогда не задирайте
max_connectionsбольше сотни. В идеале он не превышает нескольких десятков. Изучите, как приложение работает с базой, исправьте очевидные ошибки из прошлой заметки. Используйте пул даже для одного соединения. Занимайте его только чтобы прочитать данные из базы; обработка данных не должна удерживать соединение. Читайте логи пула, собирайте метрики.Если под вашу платформу нет пула, рассмотрите прокси вроде
pgbouncer. Этот вариант ограничивает всех клиентов без исключения. Он сложнее, поскольку образует новый узел инфраструктуры, а значит – это потенциальная точка отказа и мониторинг. -
Postgres №40
Продолжение про пулы и соединения.
Если вы часто видите ошибку “too many connections”, это не значит, что нужно срочно повышать
max_connections. Это то же самое, что дать деньги алкоголику в надежде, что он выйдет на работу. Если приложение плохо работает с соединениями, не сомневайтесь: оно угробит двойной лимит подключений, тройной и так далее. Надо искать причину.В прошлой заметке говорилось о том, что использование пула, пусть даже для одного соединения, снижает риск ошибки. Но что это за ошибки? Перечислим некоторые из них.
Первая – открывать и закрывать соединение на каждый запрос. Например, в одном месте выбираем пользователей:
conn = postgres.connect(host=localhost, port=5432...) conn.execute("select * from users where...")В другом — профили:
conn = postgres.connect(host=localhost, port=5432...) conn.execute("select * from profiles where...")В третьем — что-то другое. На ровном месте три соединения вместо одного, вдобавок не закрытых.
Бывают клиенты, которые принимают не соединение, а его конфигурацию. В этом случае они открывают соединение, выполняют запрос и закрывают его:
(dеf config {:host … :port …}) (jdbc/execute! config "select * from table")Этим страдает кложурный JDBC. Функция
execute!и другие принимают не соединение, а экземпляр протоколаConnectable. У протокола два метода:borrow-connectionиreturn-connection– занять и вернуть соединение (пишу по памяти, но семантика такая). У обычного соединенияborrow-connectionвернет его же, аreturn-connectionничего не делает. Для пулаborrow-connectionзаймет одно из свободных соединений,return-connection– вернет в пул.Наконец, можно передать словарь с параметрами подключения. Для него
borrow-connectionоткроет соединение, аreturn-connection– закроет. Из этого следует, что каждый запрос будет открывать и закрывать соединение. Производительность такого кода ниже на два порядка, вдобавок вы насилуете сервер частымиfork.Другая ошибка – не закрывать соединение при исключении:
conn = postgres.connect(host=..., port=...) users = conn.execute("select …") for user in users: process_user(user) # exception!Предположим, на очередном шаге process_user выбросил исключение. Начинается размотка стека, мы улетаем куда-то наверх. Но соединение осталось открытым – реакции на ошибку не было.
Решение в том, чтобы использовать конструкции, которые гарантированно что-то сделают даже при ошибке. Самое банальное – try/catch. В Джаве есть try with resources, когда у каждого объекта вызывается метод .close. В Кложе для этого служит макрос with-open. В питоне есть контекстный менеджер with, где в точке выхода можно проверить, было ли исключение.
Еще ошибка – держать соединение занятым, когда на самом деле оно свободно. Кложурный пример:
(with-open [conn (jdbc/get-connection ...)] (let [users (jdbc/execute! conn "select ...")] (doseq [user useres] (process-user users))))Соединение будет закрыто при выходе из
with-open, что в данном случае неверно. Большая часть времени уходит на обработку результата, и соединением мог бы воспользоваться кто-то другой. Однако мы держим его, пока не обработаем всех пользователей. Будет правильно переписать его так:(let [users (with-open [conn (jdbc/get-connection ...)] (jdbc/execute! conn "select ..."))] (doseq [user users] ...))В этом коде макрос
with-openсодержит только запрос. Как только он выполнится, соединение закроется, а результат окажется в переменной users, для работы с которой соединение не нужно. Разумеется, если вы стримите из базы или пагинируетесь по ней, способ не подойдет — соединение должно быть открыто все время.Всех этих ошибок можно избежать, если использовать пул. Многие клиенты возвращают в него соединения автоматом. Даже если этого не случилось, пул определяет, что соединение взяли и не вернули, и пишет лог. По умолчанию у него нет права закрывать потерянные соединения – это слишком сурово. Однако такое полномочие можно дать, и пул будет закрывать соединения, которые, по его мнению, заняли безвозвратно.
Главная мысль заметки: повышать
max_connectionsследует только после того, как вы разобрались с кодом и метриками. Если нет понимания, кто и как расходует соединения, нет смысла в повышении лимита. Плохой код сожрет его и попросит еще. -
Postgres №39
Поговорим про пулы и проблемы соединений.
При всех достоинствах Постгреса нужно знать его недостатки. Один из них следующий: Постгрес плохо справляется с большим числом подключений. Это следует из того, как устроена его серверная часть.
При запуске сервера запускается мастер-процесс. Когда к нему кто-то подключается, процесс клонирует себя системным вызовом
fork. Получаются два процесса: мастер занимается общими задачами, а второй — слушает и отвечает на сообщения клиента. Когда подключается кто-то еще, мастер снова клонирует себя и так далее.Для обмена информацией служит общий участок памяти — shared memory. Такой участок можно создать в Unix-подобных системах. Если один процесс что-то изменит в этой памяти, друге получат изменения мгновенно.
Разработчики давно обсуждают как уйти от модели “новый процесс на соединение”. Предлагаются нативные треды, но когда они будут — я не знаю.
Нужно понимать, что системный вызов
fork— очень дорогой. Он копирует всю информацию о процессе, а именно: регистры процессора, стек, номера потоков и открытых файлов. Поэтому каждое новое соединение — это вызовforkи ожидание, пока операционная система клонирует процесс.Даже если предположить, что вместо fork Постгрес использует треды, помните: запуск нового потока — это тоже системный вызов и конкуренция за время планировщика. А кроме того, частые сетевые подключения — это тоже системные вызовы.
Настройка, которая определяет максимальное число соединений, называется
max_connections. Увидеть ее можно командойSHOW:SHOW max_connections;У себя я вижу число 100. Это весьма адекватная цифра: число соединений не должно превышать нескольких десятков и уж тем более — сотен. Ситуация, когда вам не хватает 300 соединений, говорит об одном из двух. Либо у вас биллинг федерального значения и супер-пупер хайлоад. Либо приложение неправильно работает с соединениями: не закрывает их, теряет, удерживает без всякой нужды. Гораздо вероятней второе, а не первое.
Соединениями управляют на двух уровнях: сетевом (прокси) и в приложении. Во втором случае это пул соединений. Это объект, который имитирует обычное соединение, но на самом деле открывает их несколько. Когда мы выполняем запрос, пул помечает одно из них занятым и передает сообщения через него. Когда мы закрываем соединение, этого не происходит — оно помечается свободным и доступно другим потокам приложения.
Самый известный пул в Джаве называется HikariCP (от слова “харакири”). Он очень быстрый: разработчики писали, что анализировали байт-код и путем экспериментов уменьшили его минимума. В пуле нет блокирующих операций вроде
synchronized: все сделано через CAS-примитивы. Написаны свои версии классовListи подобных, которые не проверяют выход за границы — это гарантируется в коде.У HikariCP множество характеристик и шаблонов поведения. Например, сколько соединений открывать на старте; до какого предела расти; если предел достигнут, а кому-то нужно соединение, то сколько ждать; как долго клиент может удерживать соединение; как определять потерянное соединение, которое взяли и не вернули; как проверять, что соединение живое и так далее.
Хорошая практика в том, чтобы использовать пул всегда независимо от типа приложения. Этим вы гарантируете минимальную гигиену в работе с базой. Даже если у вас одно соединение, пул все равно необходим: он откроет его и будет держать открытым. Приложение не будет без конца стучаться в сокет, проходить авторизацию и клонировать серверный процесс.
Последнее — частая ошибка ребят, пришедших их PHP. В их мире не принято следить за ресурсами. Открыл файл, соединение, сокет и работай с ними, а закрывать на надо. Зачем, если скрипт отработает, и все закроется само? В системах, отличных от скриптовых, состояние не исчезает. Если открыли соединение, его нужно закрыть, но при этом следить, чтобы “открыл-закрыл” это не повторялось постоянно.
Пул решает эту проблему — берет на себя заботу об открытии и закрытии. Если одного соединения перестанет хватать, это дело настройки: увеличьте предел с 1 до 2. Стратегия может быть разной, например не открывать при запуске ничего, а делать это по требованию. Либо наоборот — открыть столько, сколько указано в лимите, чтобы каждый запрос выполнятся с уже открытым соединением.
Сколько выделить соединений пулу — вопрос сложный и решается банальным подбором. Начните с адекватной цифры вроде четырех и посмотрите на результат: как быстро приложение отвечает на запросы в многопоточном режиме. Собирайте метрики пула через JMX или обычные логи. Особенна важна метрика ожидания: как долго очередной поток ждет, пока пул выдаст ему соединение.
Другой важный показатель — сколько в пуле свободных соединений. Если их много, очевидно вы задрали лимит. Скорее всего, в этом соединении нуждается другой экземпляр приложения.
Поэтому — гадать не нужно, все сводится к метрикам.
Это была первая часть темы о пулах и соединениях. В следующих выпусках продолжим.
Writing on programming, education, books and negotiations.