-
AI и Apple
В определенном смысле мне жаль компанию Apple. Каждый вшивый блоггер пинает их за то, что они отстают в гонке ИИ. Гугл в этом плане, наоборот, на коне: пихают ИИ в каждую выпадашку, в каждую менюшку. У Гугла есть свой браузер, абсолютный монополист, и сегодня он напичкан ИИ-функциями. Фактически Хром — выставка достижений Гугла, витрина всех его сервисов.
Мне жаль Apple, потому что ИИ — определенно не их конек, но их вынудили играть на чужом поле и по чужим правилам. О том, чтобы догнать Гугл, речь уже не идет: тут хотя бы показать что-нибудь. Но пока что все громкие обещания отложены. Стоит ли говорить, что в таких условиях выиграть невозможно.
Меня печалит, что лучшие разработчики Эпла работают день и ночь, чтобы выкатить сырую ИИ-хрень и успокоить инвесторов. Эту хрень я в лучшем случае выключу, либо научусь ее игнорировать. Эти усилия можно было направить в полезное русло: стабилизацию софта и его производительность, например. Но об этом сегодня смешно говорить.
Так, в последнем обновлении Эпл предложил “интеллектуальную” сортировку писем. Разумеется, я отказался, даже не проверяя, что это. Я работаю с почтой 25 лет и за это время сформировал свои правила. Если письма начнут падать не туда, где я их ожидаю, это будет катастрофа. И вообще, почту уже некуда развивать: ей полвека, есть система папок, фильтры, правила. А ведь какой-то бедняга сидел и программировал этот ИИ-бред. Пил кофе, курил сигареты, трекал часы. Жаль человека.
На мой взгляд, борьба на рынке ИИ не принесет Эплу пользы. По-хорошему им нужно ответить чем-то другим, чтобы переломить повестку. Например, выкатить принципиально новый дизайн, причем не скруглить кнопки и добавить воздуха, а придумать что-то принципиально иное. Примерно как в прошлом веке придумали кнопки “копировать” и “вставить”. Это сейчас они в каждом утюге, а тогда стали революцией. Вот и сейчас нужно что-то такого же масштаба. Это может быть и не дизайн, а некое переосмысление того, как человек взаимодействует с устройствами и софтом.
Словом, нужно то, что позволит сказать: ребята, пока вы долбились со своим ИИ, лучшие умы опять всех опередили. Теперь правильно делать так, а не эдак. Лузеры будут скулить, но все равно перейдут на нашу сторону. Так делал Джобс. Справедливости ради, даже с учетом всех искажений продукты у него выходили что надо.
История знает случаи, когда руководитель не ввязывался в текущую повестку, а навязывал свою. Например, товарищ Сталин прекрасно знал, что конкурировать с Америкой в океане он не может, а танки плавать не умеют. Поэтому он сделал ставку на космос и добился там первенства. Американские космонавты в обязательном порядке учили русский язык, он играл в космосе такую же роль, как итальянский — в музыке, а латынь — в медицине. Сейчас это кажется небылицей: представьте, что в айти международным языком стал русский. А ведь на короткий период именно так и было.
Мораль тут простая: нельзя играть против конкурента на его поле. Я бы искренне не хотел, чтобы лучших разработчиков Эпла бросали в ИИ, а остальное делали по остаточному принципу. Эпл должен навязать что-то свое. Других способов выбраться из ямы, в которую они себя загнали, я не вижу.
-
ИИ заменит
Говорят, что ИИ скоро заменит разработчиков. Похоже, это наконец сбылось — вместо человека мне отвечает нейросеть.
Вот как это было: с утра падают билды. Причина в том, что определенный образ качается из Докера слишком часто, и он отвечает с кодом 429: Too many requests. И сообщенька: мол, убавь пыл, горячий ты наш.
Пишу об этом девопсу: Джон, давай перенесем этот образ из Докера в наш репозиторий? Потому что иначе ошибка 429, слишком много запросов к Докеру.
Что же ответил Джон? Иван, я посмотрел документацию, код 429 означает слишком частые обращения. Подожди немного и повтори билд. И заботливая ссылка на сайт Мозиллы со статьей про HTTP-код 429.
Словом, и не поспоришь — да, заменил. Возразить нечем.
-
Стереокартинки
В детстве я любил стереокартинки. У меня был альбом с ними, и я их подолгу рассматривал. Мне казалось это магией: на плоской бумаге возникала 3D-сцена, и это было невероятно. Были картинки, где текстура удачно совпадала с моделью, и от этого становилось еще круче.
Недавно ходили с дочкой в книжный магазин, и я купил набор карточек со стереокартинками. Теперь сижу и рассматриваю по вечерам. Такая вот простая радость.
Оказалось, в семье никто кроме меня этого не умеет. Пытаюсь научить жену и старших детей, но не получается (UPD: получилось). Младшая, которой три с половиной, посмотрела на карточку и сказала: папа, что ты тут намазал?
Завтра попробую другой подход. А вам вопрос: любите стереокартинки? Умеете их смотреть?
-
Правильное ООП
Словосочетание “правильное ООП” звучит для меня как “коренной москвич”. В середине прошлого века кому-то было важно, приехал человек из региона или родился в столице. А сегодня в адрес тех, кто применяет этот тезис, крутят пальцем у виска.
То же самое я чувствую, когда говорящая голова ездит по городам с лекцией о “правильном” ООП. Тут можно сказать одно: современное программирование настолько широко и сложно, что искать в нем “правильное” ООП — то же самое, что искать “правильное” изложение “Колобка” или “Курочки Рябы”. Все версии правильные — бери по вкусу.
Этот тезис закрывает любую лекцию по ООП.
-
Форматирование строк
Шел 2025 год, а в Питоне делают очередное форматирование строк. На этот раз оно называется t-строки из-за префикса t. Такие строки по-настоящему всемогущи: могут делать любые преобразования, ходить по модулям, вызывать такси и заказывать пиццу. Без шуток, найдется тот, кто напишет на них интерпретатор Питона.
Может показаться странным, но именно из-за подобных штучек я завязал с Питоном. Я любил его где-то до версии 2.7, ну и немного третью. Переход на тройку был тяжелым, но необходимым, и это можно было стерпеть. А потом начались бесконечные улучшения: новые операторы, синтаксический сахар на каждый чих, f-строки, t-строки и так далее.
Я понял, что не успеваю за Питоном. Как его ни изучай, энтузиасты навалят новых PEP-ов. Для конкретного проекта это не страшно, но перейдешь в другой — а там уже затянули все нововведения, и сиди разбирайся.
Особенно меня коробит форматирование строк. Напомню, что в Питоне, наверное, десять способов форматировать строки, и число вариантов все растет. Есть процент с кортежем, есть метод
.format, есть f-строки,string.Template, сейчас готовят t-строки. Это только стандартная библиотека, а еще полно сторонних пакетов.Крафтить подобные вещи интересно, я не спорю. Но почему не нашлось никого, кто бы сказал: братцы, мы делаем херню. Плодим одно и то же, засоряем стандартную библиотеку. Неужели, имея с десяток способов сделать X, нужно писать еще один? Где был это человек? Или их выгнали?
Мое любимое занятие — форматировать процентом (как в Си) и выкладывать на ревью. У питонистов начинается пожар: они говорят, что есть f-строки, что процент использовать не надо, а почему — объяснить не могут. Со стороны кажется, что у них чешутся внутренности: так странно они себя ведут. Если здесь уязвимость, покажи, как она работает. Если медленно, сделай замеры. Но нет, карго культ: мы делаем так, потому что мы так делаем.
Современный Питон переусложнен. Он без конца развивается, и это обратная сторона популярности. Как писатель, которого вынудили писать одно, хотя душа лежит к другому. Каждый раз, когда читаю про новый оператор, думаю об одном: боже, как хорошо, что в Кложе нет новых операторов в каждом релизе. Там все просто: хочешь оператор — пишешь макрос, выносишь в библиотеку и делаешь анонс в Слаке. Все довольны и ставят пальчики.
Бесконтрольное развитие языка — тоже плохо. Это трудно заметить в моменте, потому что эффект проявляет себя десятилетиями. Но нужно держать его в голове.
-
Видео с митапа о Postgres и JSON
Подъехала запись, очень оперативно, как раз на выходные. Сначала болтология минут на 30, потом техническая демка тоже на 30 минут. Потом вопросы. В сумме почти два часа.
-
Разрешения
Обновил яблочную операционку, и началось: слетели все разрешения. Каждое приложение при запуске кукарекает: можно ли сканить локальную сеть? Можно ли смотреть файлы в Downloads? Воткнул флешку — можно ли подключить Kingston Datatraveler 8Gb? Воткнул микрофон — можно ли подключить микрофон?
Причем это было минорное обновление (последняя правая цифра).
Увы, в 2025 году обновления по-прежнему ломают то, что работало до них. Что у Микрософта, что у Гугла, что у Эпла. Все одинаково хороши. Или это нарочно?
-
Большой запрос
Последние дни я безвылазно сижу в PGAdmin: пишу запрос, чтобы построить важный репорт. В нем уже 470 строк плюс понадобились пять функций для разных преобразований (например денег, округления дат). Итого 550 строк чистого скуля.
Не знаю, что обо мне скажут коллеги, когда это увидят. Наверное, проклянут и будут правы. Но дело в том, что у меня началась профдеформация: мне уже легче писать на SQL, чем на Кложе.
Со временем понимаешь следующий момент. В SQL любое значение — это таблица, а операторы — различные JOIN-ы: левое, правое, внутреннее или декартово произведение. Как только пришел к этому, мышление поворачивается под другим углом.
Скажем, вот список мап в Кложе:
[{:id 1 :name "Ivan"} {:id 2 :name "Huan"} {:id 3 :name "Juan"}]То же самое в SQL:
id name 1 Ivan 2 Huan 3 JuanЛюбая операция над этим списком сводится либо к фильтрации, либо джоину, либо агрегатной функции. Скажем, фильтрация по ID это обычный
where:select * from users where id > 2То же самое, что написать:
(filter #(> % 2) users)Предположим, есть список мап вида “пользователь -> аватар”. В SQL его легко выразить таблицей:
user_id photo_url 1 https://test.com/avatar.jpg 3 https://test.com/cat.jpgА вот их различные объединения: с сохранением левой части (пользователи без аватары останутся):
select users.*, p.photo_url from users u left join photos p on p.user_id = u.id id name photo_url 1 Ivan https://test.com/avatar.jpg 2 Huan 3 Juan https://test.com/cat.jpgи без:
select users.*, p.photo_url from users u join photos p on p.user_id = u.id id name photo_url 1 Ivan https://test.com/avatar.jpg 3 Juan https://test.com/cat.jpgВ общих словах, любой SQL-оператор сводится к джоину. Скажем, новички часто передают список айдишников с оператором IN:
where id in (1, 2, 3, ...999)И не знают, что гораздо эффективнее выразить то же самое джоином и таблицей с полем
id:select * from users u join user_ids on u.id = user_ids.idВ SQL даже одно значение является таблицей. Переменная
x=42— это таблица с колонкойXи кортежем(42, ). Примерно как в Матлабе все является матрицей.Есть расхожее мнение, что джоины тормозят, но вообще говоря это неправда. Джоины очень эффективны. Почти любой оператор можно ускорить, если свести его к джоину с другой таблицей. Если связующее поле индексировано, это будет быстро: почти как выборка. Важно, что выборка проекции двух и более таблиц быстрее, чем две отдельные выборки и обработка их силами Питона или другого языка.
Мышление таблицами и их проекциями — очень крутая вещь. Не знаю, во что это выльется, но чувствую себя как десять лет назад, когда ломал мозги об Кложу после императивного программирования. Волнует и возбуждает.
-
Возможности JSON_TABLE
Небольшая добавка ко вчерашнему посту. Приведу пример, очень близкий к реальности.
Предположим, есть пользователи, они совершают заказы. Каждый заказ состоит из позиций. У позиции есть стоимость и код валюты. Одна позиция может быть в евро, вторая в долларах и так далее.
Задача в том, чтобы собрать из микросервисов нужных пользователей с заказами и позициями и составить табицу: пользователь, заказ, сумма позиций в евро. Для конвертации валют использовать таблицу коэффициентов.
Вот что получается на практике. Вы идете в микросервис А и получаете джейсончик как на первой картинке:

Потом идете в микросервис В, чтобы получить курсы валют:
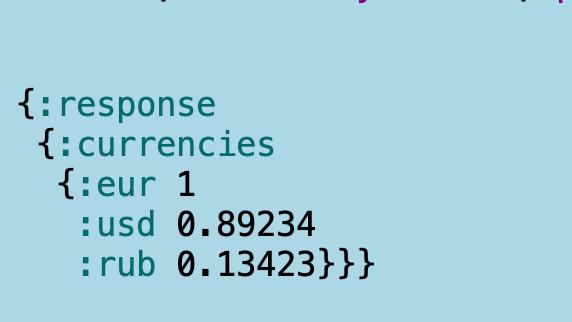
Из этих данных вам предстоит слепить конфету. Имейте в виду, что на картинах — лишь малые подмножества данных. В реальности и полей, и вложенных сущностей больше.
Первая беда в том, что данные вложены, и с ними нельзя нормально работать. Я уже сто раз писал об этом: когда у вас мапа с вектором мап с вектором мап с вектором мап, ни о каком удобстве не может быть и речи. Код, который обходит такое дерево, поддерживать невозможно, неважно Питон это или Кложа. В первом случае это будет императивный быдлокод, во втором — функциональный. Это когда код — цепочка из десяти вызовов
map/mapcat/reduce/group-by.В Кложе есть макрос
forдля декартовых произведений, но для каждого дерева нужно писать свою логику. Универсальный вариант я пока не придумал.Вот как сделать то же самое в SQL. Загоняем оба джейсона в базу. Теперь плющим первый функцией
JSON_TABLE: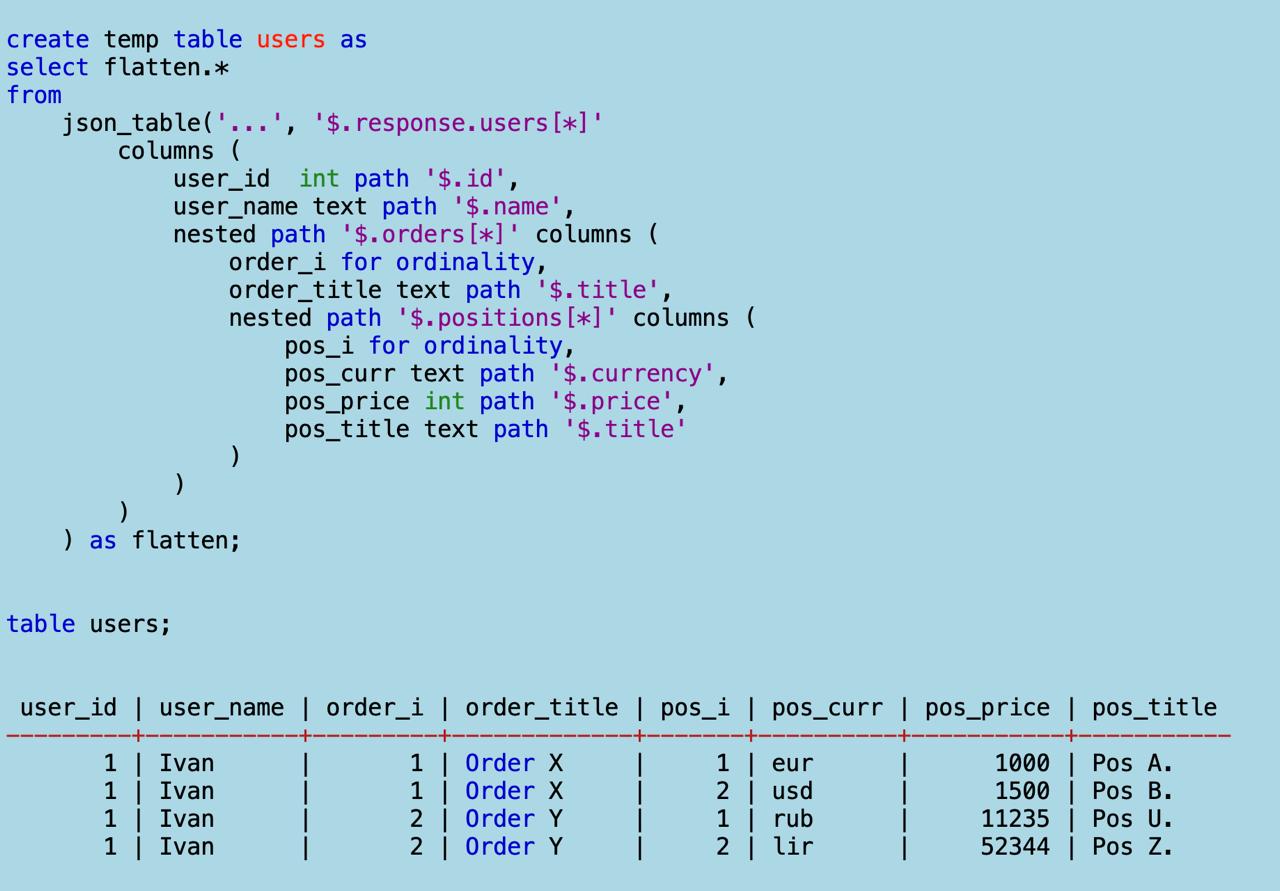
Получаем таблицу
users. Все плоско и декларативно. Обратите внимание на суррогатные поляorder_iиpos_i— номера мап в массивах. Это значит, если я захочу свернуть таблицу обратно в дерево, не будет никаких проблем.Теперь плющу курсы валют:
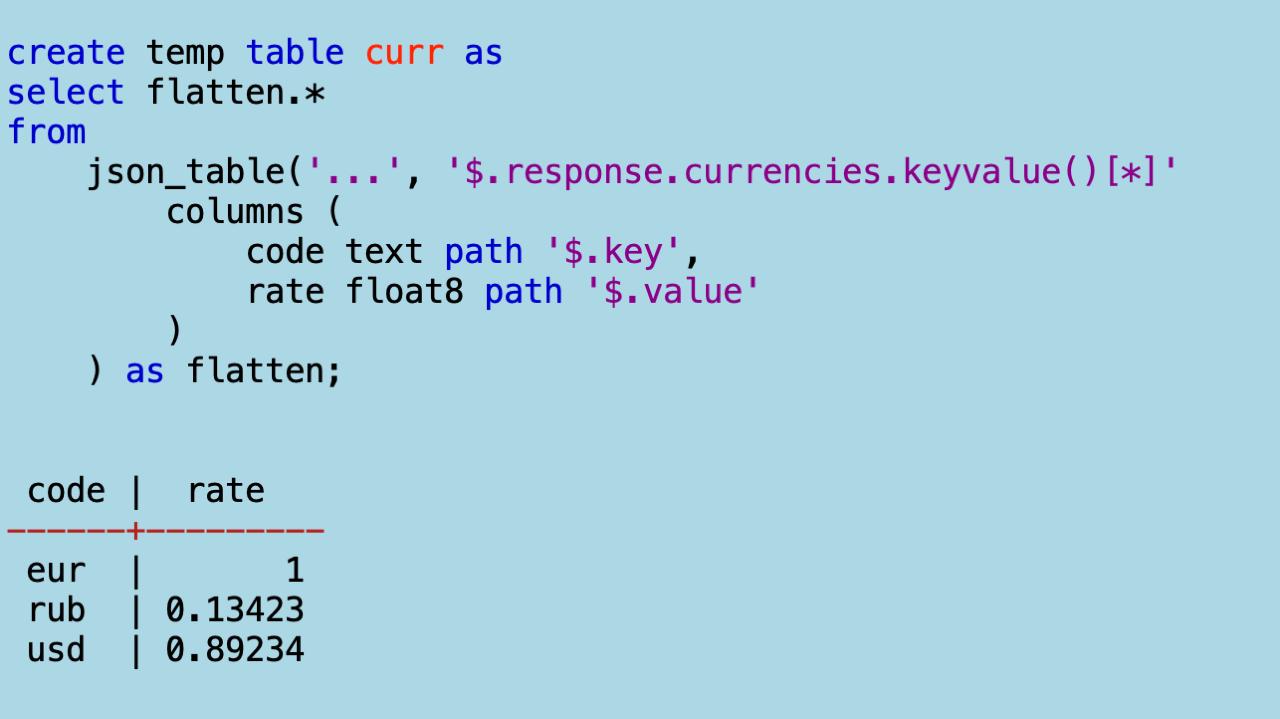
Потом присоединяю слева к юзерам курсы валют по их названиям. Это значит, каждая позиция получит коэфициент ее валюты:
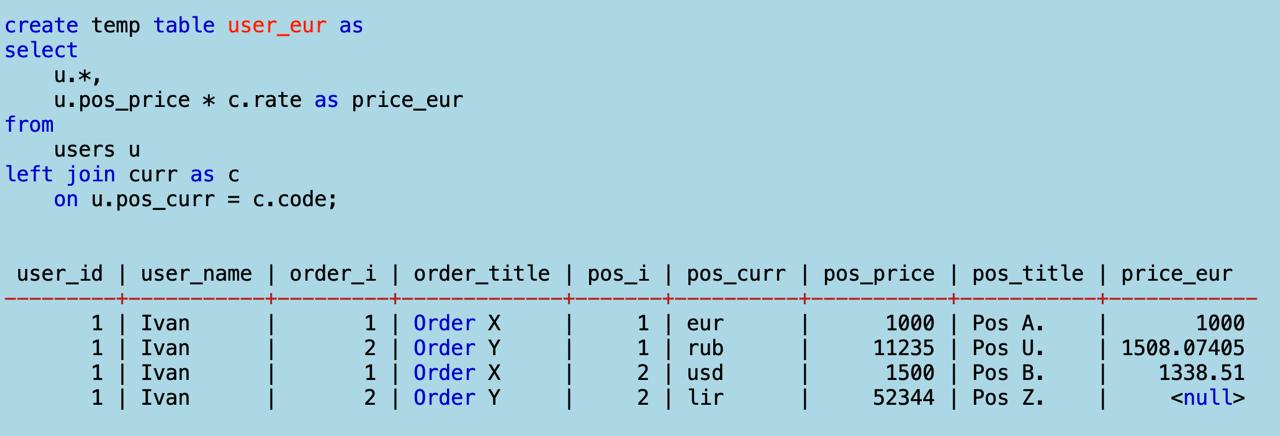
И последний шаг: считаю сумму
price_eurс группировкой по пользователю и заказу.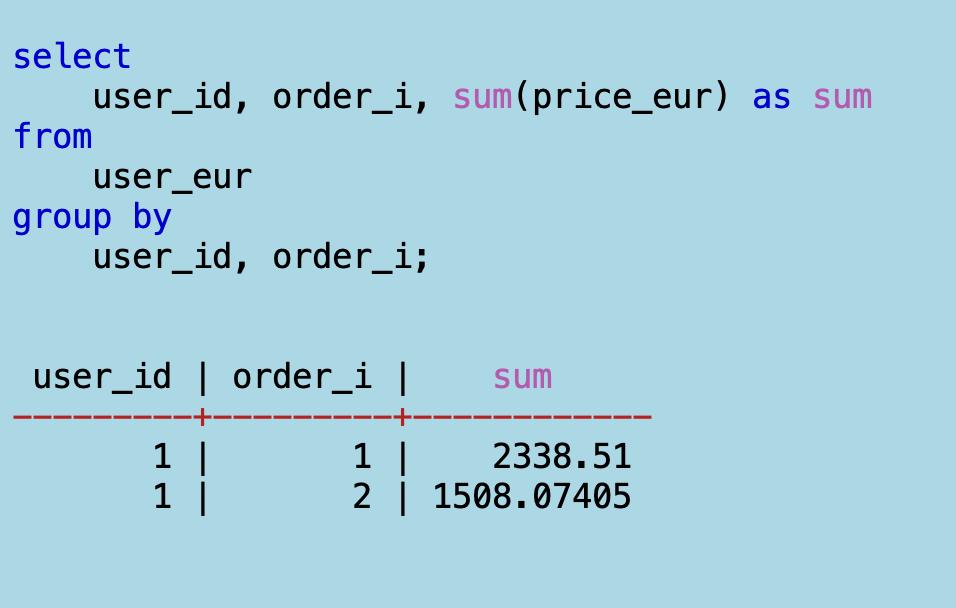
Готово. Самое важное: все декларативно и без циклов, без присваиваний и аккумуляции списков. Среда, что выполняет этот код, написана на чистом Си и многократно протестирована. Что еще нужно?
Все это можно уместить в один запрос, но я специально расписал по шагам.
Обратите внимание, что в списке валют специально нет одной. Это частая история с микросервисами, когда у них неполные данные. В результате запрос не упадет с NPE, как упал бы ваш Питон или Джава. Просто результат будет NULL, и на посчете суммы это никак не скажется.
Предлагаю вам написать то же самое на своем языке и посмотреть, что получится. Только учтите, что вложенность может быть еще глубже, а данных больше.
-
Покупка нот

Часто ищу маме ноты. И порой думаю: хватит шариться по ВК-помойкам, куплю за деньги как белый человек. Открывается форма заказа. Смотрю на нее минуту и опять иду на помойку. С такой формой я ничего не куплю. Интересно, нашелся ли отважный, кто прошел эту форму и купил? Сомневаюсь.
Writing on programming, education, books and negotiations.