-
О написании заглавных
Не люблю, когда ставят заглавные буквы там, где этого не требуется. Примеры:
- квитанция за Март;
- следующее собрание в Понедельник;
- низкие оценки по Алгебре;
- повышение тарифов за Водоотведение;
- лучший подарок Любимой;
- в ответ на Ваше обращение…;
- с Новым Годом!
Теперь по пунктам. Названия дней недели и месяцев в русском языке пишутся со строчной буквы: понедельник, январь. Это в английском Monday и January, а в русском – со строчной. Названия языка тоже, кстати, не нуждается в заглавной. Поэтому языки — английский и немецкий, а не Английский и Немецкий.
Та же история с названиями школьных предметов. Это в английском Math, History, Art. В русском – математика, история, рисование.
Вода, тепло, газ и прочие услуги – со строчной. Просто они берутся из справочной таблицы по айдишке и подставляются как есть:
| id | title | |----|---------------| | 1 | Водоотведение | | 2 | Газоснабжение | | 3 | Отопление |Проблема решается вызовом
.toLowerCase.Любимая, Он, Она, Правда, Сила, Знание, Честь – все это лишний пафос. Напоминает творчество Ника Перумова, где в каждом предложении — Священный Меч, Древняя Сила, Темный Страж, Воин Пути и так далее.
“Вы” с большой пишется только если вы обращаетесь к конкретному человеку, при этом он старше вас в какой-то иерархии. Писать “Вы” в статьях – безграмотно, потому обращение обезличенно.
Вселенная пишется с большой.
Если праздник состоит из нескольких слов, с заглавной буквы пишется только первое. Новый год, а не Новый Год. Капитализировать все слова – разводить лишний пафос.
Если праздник начинается с даты (цифры, числа), то написание варьируется. Когда цифру пишут прописью, она принимает на себя заглавную букву:
- Восьмое марта
- Двадцать третье февраля
- Девятое мая
Обратите внимание: “Двадцать третье”, а не “Двадцать Третье”. Если число пишется цифрой, то заглавная буква уходит на следующее слово:
- 8 Марта
- 23 Февраля
- 9 Мая
Последнее особенно важно дизайнерам открыток и поздравительной мишуры.
-
Числа №16. Знаковость
Почему в Джаве байт имеет знаковый тип? Скажем, если прочитать из файла байт 249, то при печати увидим -7. Откуда минус?
Дело в том, что в Джаве тип byte и его старший брат Byte – знаковые.
Знаковые числа – те, что тратят первый бит на признак того, есть ли впереди минус. Например, число 3 в битовом виде записано так:
00000011А с минусом – так:
10000011Первый бит означает, что впереди минус. Если прочитать этот набор битов как беззнаковое число, то первый бит дает 128 (два в степени 8). Итоговое число становится 128 + 2 + 1 = 131.
Это как раз случай Джавы. Она смотрит на биты
10000011как на знаковое число, поэтому первый бит нарисует минус, а оставшиеся0000011– тройку.В интернете есть цитата Гослинга:
For me as a language designer, which I don’t really count myself as these days, what “simple” really ended up meaning was could I expect J. Random Developer to hold the spec in his head. That definition says that, for instance, Java isn’t – and in fact a lot of these languages end up with a lot of corner cases, things that nobody really understands. Quiz any C developer about unsigned, and pretty soon you discover that almost no C developers actually understand what goes on with unsigned, what unsigned arithmetic is. Things like that made C complex. The language part of Java is, I think, pretty simple. The libraries you have to look up.
Кому лень переводить: причина в том, чтобы сделать проще. В языках С и С++ есть знаковые и беззнаковые типы, и когда они выступают вместе, никто не знает, что произойдет. Да, в стандартах Си описаны правила, но легко ошибиться. Поэтому проще всего исключить беззнаковые числа.
Мое мнение таково: да, беззнаковые short, int, long лучше исключить. Пусть будут только знаковые. А вот с байтом вышла ошибка.
Беда в том, что в Джаве байт считается числом: тип Byte унаследован от Number. Я не согласен. Байт – это не число. Он никогда не интересует нас в качестве числа. Когда в последний раз вы прибавляли число к байту? Или умножали байт на байт? Вычитали их?
Байт – это группа битов, элемент алфавита из 256 символов. Да, ему можно сопоставить число для удобства, но не более того. Байт – это сырые данные, на которые можно смотреть по-разному в зависимости от контекста. Это может быть знаковое число или беззнаковое; это может быть несколько битовых групп, например, первые три – тип, а остальные пять – значение.
В байте может умещаться крошечное число с плавающей запятой! Бит на знак, три на экспоненту и четыре на мантису:
1 101 1010Такие числа называются tiny float 8 и поддерживаются видеокартами.
Факт, что отрицательные байты никем не используются, очевиден. Скажем, IP-адрес – это четыре байта через точку, но никто не записывает
192.168.0.1как-64.-88.0.1. Ни один hex-редактор не показывает отрицательные байты, не важно в hex- или decimal режимах.Тот же Турбо Паскаль разделял байт и знаковое 8-битное число: типы Byte и ShortInt. Первый фигурирует, когда читаешь сеть или файл. Второе – это преобразование группы бит к конкретному типу.
На примере Джавы можно вспомнить цитату Эйнштейна: вещи должны быть простыми, но не проще этого. Идея избавиться от беззнаковых типов в целом хороша, но повлияла на работу с байтами. Байты не должны трактоваться как числа, а если это допустимо, то знака не должно быть. Мы ведь не считаем буквы от -16? Так что с байтами упрощение пошло во вред.
Это была последняя заметка о числах – других заметок на эту тему в черновиках у меня нет. Надеюсь, вам понравилось, и кто-то что-то для себя извлек. Напомню, что все заметки про числа легко найти по тегу #numbers.
-
Числа №15. Об играх
Пока бы закончить с числами; осталось две заметки.
В прошлый раз я рассказывал о числах с фиксированной запятой и о том, как они использовались в играх. В том числе упомянул первый Старкрафт (BroodWar), о котором и хочу поговорить.
Старкрафт – это стратегия реального времени фирмы Blizzard; вышла в 1998 году. Она стала прорывом во многих областях и надолго задала планку. Старкрафт отличался запредельным числом игровых механик и их комбинаций. Расы были кардинально разными: зерги делали ставку на массу, протоссы – на мощь, терраны – на технологии. Юниты были наземные и летающие, транспортные, невидимые, с обычным уроном и массовым. Были псионики – юниты, которые атаковали только магией.
Игра, хотя и была двумерной, поддерживала многоуровневый ландшафт, и это влияло на исход боя: юниты ниже мазали по тем, что выше.
Не все тонкости игры были очевидны. Скажем, юниты делились на классы (легкий, тяжелый и другие), атака тоже была разных типов. Позже игроки составили таблицы, кто по кому наносит какой урон.
Добавьте к этому отличную кампанию, полную пафоса; крутые CGI-ролики; сетевую игру в компьютерном классе; Battle.net для счастливчиков с интернетом в 98 году – и станет ясно, что игра была прорывом. До сих пор она остается одной из главных киберспортивных дисциплин, а в Южной Корее – национальным видом спорта.
Чтобы обеспечить все это добро, движок считал много чисел. В 98 году не все процессоры поддерживали плавающие числа, поэтому в Старкрафте использовались числа с фиксированной запятой. Код игры никогда не открывали, однако ее устройство ясно из публикаций разработчиков и специального SDK для ботов. Последнее особенно интересно: Старкрафт был первой игрой, под которую писали ИИ-ботов. Были даже шоу-матчи между известными игроками и ботами по аналогии с шашками Go и AlphaStar. Ежегодно проходят турниры для разрабочиков ботов.
Интересен следующий факт: числа, что мы видим в игре, на самом деле являются дробными. Скажем, у морпеха (марика) 40 единиц здоровья, атака 6, броня 0. У зилота (zealot, воин протоссов) здоровье 100 единиц, защитное поле на 60 пунктов, атака 16. Все числа выглядят как целые, удобно складывать и вычитать их.
На уровне кода каждое число – это контейнер с фиксированной запятой. Тип, который его описывает, называется
fp8, что означает fixed point 8. Восьмерка подразумевает число битов, отведенных под дробную часть. Таким образом, fp8 хранит числа с точностью до1/256или0.00390625в десятичной системе.Я не видел полного описания этого типа. Однако логично предположить: если он занимал 16 бит, то на целую часть оставалось 8 бит. Таким образом целая часть вмещала диапазон от -128 до 127. Это мало. Поэтому скорее всего тип занимал 32 бита (обычный int), и на целую часть отводилось 24 бита вместе со знаком. Диапазон таком образом был от
-(2^23)до(2^23)-1или от-8,388,608до8,388,607.Восемь миллионов – достаточно, чтобы покрыть все случаи игры, включая особенные. Например, юнитов-боссов в кампании с колоссальным запасом здоровья.
И все-таки: зачем игре дробные числа? Мы ведь выяснили, что у зилота 160 здоровья, а у марика 6. Это значит, потребуется 27 атак, чтобы марик победил зилота. Все удобно, но нет – за этим удобством кроется фиксированная запятая.
Причина в следующем: если все числа целые, то в какой-то момент они портят игровой баланс. Такая сложная игра как Старкрафт обязана учитывать фракции, чтобы не вышла досадная вещь, которую мы рассмотрим ниже.
Про морпеха вы уже знаете; а у зергов есть юнит под названием ультралиск. Это слонопотам, который хорош против морпехов. Изначально у него 1 единица брони. Всем юнитам зергов можно сделать три апгрейда на броню +1. Наконец, ультралиску доступен его личный апгрейд +2 к броне. В сумме они дают 6 брони.
Единица брони снижает урон на единицу. А теперь смотрите: ультралиск со всеми апгрейдами имеет 6 брони, а морпех без апгрейдов на атаку наносит 6 урона. 6 - 6 = 0. Если задача решается в целых числах, то морпех наносит нулевой урон, и ультралиск полностью для него неуязвим!
Проблему можно решить тем, чтобы обязать игрока, который играет за терранов, сделать апгрейд +1 для мариков. Тогда морпех будет наносить единичку урона: 6 - 7 = -1. Но это слабое решение. Общая беда в том, что если у юнита высокая броня, он неуязвим для всех юнитов с атакой ниже брони.
Возможна абсурдная ситуация: у юнита слабая атака, но высокая броня, скажем атака 10 и броня 20. Представим теперь, что игроки выбрали одинакову расу. Оба настроили этих юнитов и пошли воевать. В результате ни одна армия не победит другую: каждая атака на 10 единиц нивелируется броней в 20 единиц. Такой себе геймдизайн.
На самом деле броня в 6 единиц – это не показатель -6 ко вражеской атаке. Это коэффициент ее снижения. В Старкрафте и других играх Blizzard броня устроена логарифмически. Вспомним как устроен логарифмический рост: на малых значениях он почти линейный. Значения брони 1 или 2 дают снижение урона на 1 и 2 соответственно. Однако далее рост замедляется: показатель 3 снижает урон не на 3, а на 2.9, 4 – на 3.5 и так далее.
Числа я беру из головы, потому что не готов запускать Старкрафт и все это проверять. Однако такая же механика справедлива для Warcraft, Diablo и других игр Blizzard. Логарифмическая броня – это залог того, юнит никогда не станет неуязвим. Даже если выдать юниту 100 брони, урон по нему будет снижен до условных 0.01 здоровья. Да, это мало, и здоровье будет тикать по единичке в минуту. Но урон все-таки будет, и сотня-другая обычных юнитов смогут победить тяжеловеса.
Как следствие, даже ультралиска с броней +6 можно победить морпехами без апгрейдов. Каждый марик будет наносить не 0, а 0.25 урона (условно). Разумеется, игроку за терранов в такой ситуации ничего не светит, но дизайн игры в этом не виноват. Не получится создать юнита, который полностью неуязвим, и это правильно.
Должно быть, вы замечали в других играх: долбишь врага, а здоровье убывает на единичку каждый сотый удар. На самом деле его здоровье — дробное число и урон наносится тоже дробный. В интерфейсе все показатели выглядят целыми, чтобы не смущать игрока длинными хвостами. Кому понравится
2.513523734353450003урона?Поскольку логарифмы ведут к дробным числам, вот откуда нужда в числах с фиксированной запятой.
По той же причине в раннем Старкрафте был баг: “мертвые” юниты с нулевым здоровьем. Такой юнит мог воевать и погибал только от следующего удара. Как вы поняли, он не был мертвым: целая часть здоровья была нулевой, но оставались единичные биты в дробной части. Это случалось из-за показателей брони, сплеш-урона с затуханием и многих других факторов. Старкрафт не округлял дробные числа: чтобы показать целую часть, он просто сдвигал fp8 на восемь битов вправо. Результат был 0, но юнит считался живым. Позже это исправили.
Да, многое я бы мог рассказать про Старкрафт – сколько времени в него прощелкал! В качестве бонуса предлагаю цикл статей разработчика, который пишет ботов и понимает устройство игры как бог.
-
Текущий case
Один из худших атавизмов в программировании – это протекающий оператор
switch/case. Он ведет родословную со времен Си и в настоящее время есть во всех императивных языках.switch (expression) { case constant1: // Code to execute if expression == constant1 break; case constant2: // Code to execute if expression == constant2 break; default: // Code to execute if no case matches }В чем проблема? В том, что без оператора
breakуправление передается в ниже. Если expression подходит под разные условия, сработают две ветки одна за другой. Счастливой отладки.Сколько людей погорело на протечках в
switch/case– я даже боюсь предположить.В Джаве
switch/caseустроен аналогично, но к счастью там это поправили. Есть другойswitch/caseсо стрелками, который гарантирует, что будет выполнена только одна ветка. Вдобавок он возвращает значение:int result = switch (input) { case "A" -> { System.out.println("Processing A"); yield 1; } case "B" -> { System.out.println("Processing B"); yield 2; } default -> 0; };В последних Джавах много внимания уделяют паттерн-матчингу. Можно сказать, что любой switch лучше свести к паттерн-матчингу, потому что иначе получается минное поле из-за протечек.
В Кложе, например, макрос
caseгарантирует, что сработает только одна ветка. При этом выражения должны быть литералами, потому что компилятор вычисляет от них хеши для таблицы переходов:(case (:status item) "active" (process-active item) "pending" (process-pending item) ;; default (throw-error "wrong status"))Есть макрос
condдля условий, которые вычисляются в рантайме. Будет вычеслена первая ветка, для которой условие вернет истину:(cond (-> item :status (= "active")) (process-active item) (or (-> item :status (= "pending")) (queue-is-blocked ...) (process-pending item) :else (default-case "..."))Наконец, есть скользящий, “протекающий”
cond->со стрелкой. Он принимает пары (условие->выражение) и пропускает сквозь них исходное выражение.(cond-> [] :always (conj (get-some-item ..)) (item-is-active? item) (conj the-item) :finally (into (get-additional-items)))Пишу я это потому, что погорел со
switch/caseв Питоне. Хотя с версии 3.10 в него завезли операторmatch, многие до сих пор пишут каскадыif...elif...elif...elif...else. И вот я добавил новую ветку в середину, а вместоelifнаписалif:if action == "foobar": do_this() elif action == "kek": do_that() if action == "some_action": do_lol() else: throw Exception("...")Ветка выполняется, но первый оператор
ifобрывается и начинается второй. Для него условие не находится и срабатываетelse, где бросается исключение. Получилось так, что действие выполняется, но из-за того, что было исключение, задача запускается еще раз. В итоге мой код вызвал действие три раза. Линтер ничего не заметил.На мой взгляд, старого оператора
switch/caseв коде быть не должно – только паттерн-матчинг, который гарантирует, что сработает только одна ветка. А второе – не знаю, как можно жить с языком без макросов. Это словно красть у себя самого. -
Закончили Гарри Поттера
Вчера закончили с дочкой Гарри Поттера – все семь книг. Это заняло год и пять месяцев. Я вычислил срок с помощью блога: оказалось, в январе 2025 года я публиковал маленькую заметку о денежной системе в мире ГП.
О каждой книге можно сказать разное: где-то лучше, где-то хуже. Кто-что затянуто; какие-то сцены никуда не ведут; от некоторых персонажей можно было отказаться. Однако в целом ГП – замечательный, монументальный труд. Это новая вселенная по образу Звездный Войн, и по ней еще долго будут делать приквелы-сиквелы, фанатский контент и прочее.
Гарри Поттер – это современная детская литература. Ключевое слово “современная”, то есть описывает персонажа нашего времени. Несмотря на все нелепости вселенной ГП, ключевые темы вроде отношений, любви, долга, преданности совпадают с ориентирами нормального современного человека. При этом книга взрослеет вместе с читателем.
Я жалею лишь об одном: мы читали ГП в неудачном переводе. Нам подарили первые несколько книг, и на тот момент мне были безразличны все эти Снейпы-Злеи. Когда я разобрался, то уже был полный комплект, и покупать новый не хотелось. Считаю, что переводчиков Махаона, которые исковеркали все имена, нужно отпинать и сбросить в канализацию. Может, так они поймут, что нельзя портить чужой труд.
Прикупил пару книжек о ГП на английском. Развивает: много прилагательных, разговорных оборотов, художественные вещи, с которыми не имеешь дела на созвонах.
ГП — важная веха современности. Читайте детям Гарри Поттера. И детям хорошо, и вам понравится.
-
Keeping things apart
Один кудрявый разработчик сказал: design is about keeping things apart. Дизайн – это удежание вещей по отдельности. Полная цитата звучала так:
design is fundamentally about taking things apart (decomplecting) so they can be managed, understood, and put back together (composed) in a flexible wayСмысл в том, что пока элементы более-менее свободны, свободен и дизайн. Следовательно, свободны и мы в принятии решений.
Сегодня я осознал, насколько это важно.
Где-то полгода назад я запрограммировал сложный процесс. Много шагов и состояния, работает почти час, поднимает тысячу лямбд. Ширина картинки с диаграммой – 10 тысяч пикселей. Я этой сложностью не горжусь: была бы моя воля, я бы сделал проще и вообще по-другому. Но меня заставили сделать так.
Этот процесс производит много данных, которые нужны всем. Со временем я заметил, что разработчики “подсасываются” к процессу: добавляют новые шаги и побочные эффекты. Я говорю: ребята, давайте вы запустите свой процесс, который считает ваши штучки параллельно моему, а не во время. Я не хочу, чтобы мой процесс падал из-за ваших вычислений, да и вообще – растет сложность. Давайте по отдельности.
А мне говорят: уж если есть убер-комбайн, давай педалить его. Я свое мнение защитить не смог и проиграл. В итоге на пайплайн навесили кучу других операций.
И вот вчера случилась классика. Мне понадобилось вызвать процесс еще раз, но с особыми параметрами. Ну знаете, такой же, но с перламутровыми пуговицами (с). Новое бизнес-требование. Я запустил, и все эти допики, которые навесили другие разработчики, посыпались. Где-то создались дубли, где-то не те поля и так далее. Пришлось чистить и откатывать.
И вот теперь я должен пройтись по всей цепочке шагов и добавить if-else. Если режим запуска такой-то, то не вызывать эту примочку, не обращаться в этот сервис, не выполнять этот запрос и так далее. Фактически – вынести все обвесы в условие.
В итоге у нас things нифига не apart, и design тоже не задался. А если бы вынесли в отдельные пайплайны вместо того, чтобы бесконтрольно усложнять исходный, дело бы обошлось.
У докладов Рича Хикки двойное дно. Ты их смотришь и не понимаешь: кажется, что дед несет пургу. А через много лет понимаешь, но уже через боль. Жаль, что понимание приходит именно так.
-
Числа №14. Фиксированная запятая
Мы много говорили о числах с плавающей запятой. Есть и другой формат – дробные числа с фиксированной запятой. Давайте кратко их рассмотрим.
Об этих числах я упоминал в заметке о первой Playstation. Это эмуляция дробных чисел для архитектур без математического сопроцессора. Главное их преимущество в том, что все операции с ними выполняются как целочисленные.
У фиксированных чисел, как ясно из определения, дробный разделитель не плавает туда-сюда. Например, мы решили, что после запятой хранится два разряда, и так будет всегда. Не нужно нормализовать числа и приводить их к общим экспонентам.
Число с фиксированной запятой хранится как целое, умноженное на некий коэффициент. Для простоты рассмотрим десятичные числа. Будем хранить цены в рублях с двумя десятичными знаками (копейками):
Кофе 80.99 Булочка 115.50Коэффициент равен
10^-2(или 0.01), а их целые представления равны:Кофе 8099 Булочка 11550Складываются и вычитаются такие числа в одну машинную команду. Найдем сумму покупки:
1 8099 11550 ----- 19649Приведем к дробному виду, чтобы были видны копейки:
19649 * 10^-2 = 196.49Это было сложение, а теперь рассмотрим умножение. Умножать булочку на кофе немного странно, но давайте не думать об этом.
Числа 80.99 и 115.50 можно записать таким образом:
80.99 = 8099 * 10^-2 115.50 = 11550 * 10^-2Их произведение:
8099 * 10^-2 * 11550 * 10^-2Две степени десяти схлопываются в одну:
-2 + -2 = -48099 * 11550 * 10^-4Умножение на степень десяти равносильно тому, чтобы сдвинуть разряд влево или вправо. Произведение
8099 * 11550дает93543450, и нужно сдвинуть разделитель влево на 4 позиции. Результат:9354.3450Однако мы храним только две цифры после запятой. Поэтому хвост
3450округляется до двух знаков. Цифра 5 округляется вверх, и на конце оказывается 35:9354.35Целое (внутреннее) представление становится таким образом
935435.Вот как устроены числа с фиксированной запятой.
Выше мы рассматрели их в десятичном виде, потому что так удобней. В двоичном виде происходит то же самое. Договариваются, что первые 16 бит хранят целую часть, а остальные 16 – дробную. Сокращенно записывают так:
Q16.16. Могут быть и другие варианты: больше бит на целую часть (Q24.8) или наоборот – на дробную (Q8.24). Вместо десятичного сдвига происходит битовый силами процессора.С такими числами работали игровые консоли вроде Playstation, Sega Saturn и GameBoy. Очевидный их минус в том, что, во-первых, диапазон значений гораздо ниже, чем у float. Во-вторых, нужно следить за переполнением целой части. Чтобы не допустить переполнения, числа приводят к аналогам, где у целой части больше бит. Например, конвертируют Q16.16 в Q24.8, выполняют расчеты, а затем возвращаются к Q16.16.
Раньше числа с фиксированной запятой использовались часто. Например, в Doom для расчета углов; в LaTeX для растеризации шрифтов; в ранних играх Blizzard (Starcraft).
В следующей заметке я хочу рассказать о Старкрафте: какую роль в нем играли числа с фиксированной запятой и почему разработчики не использовали целые.
-
Числа №13. Ошибка Pentium FDIV
Еще одна кулстори на тему чисел с плавающей запятой.
Мы привыкли, что железо не ошибается, но иногда бывает обратное. В 1994 году Intel выпустила первые процессоры линейки Pentium. Процессоры эти печально прославились тем, что неправильно считали некоторые флоаты (инструкция FDIV). Вот это правильный результат:
4195835,0/3145727,0 = 1,333820449136241002А вот что выдавал бракованный процессор:
4195835,0/3145727,0 = 1,333739068902037589Казалось бы, ошибка начинается с четвертой цифры после запятой, пустяки. Но вот что случиться, если поделить и умножить на одно и то же число:
(4195835/3145727)*3145727 = 4195835против
(4195835/3145727)*3145727 = 4195579Разница 256 – прилично.
Ошибку обнаружил ученый Томас Найсли. Он написал код, проверяющий процессор на корректность, уведомил Intel об ошибке и вообще сделал многое для того, чтобы о проблеме узнали.
Реакция Intel была потрясающей. Во-первых, в фирме знали о неверных операциях с числами, но считали, что проблема коснется только узкого круга лиц. Во-вторых, компания предложила замену процессора только тем, кто докажет, что испытывает проблемы. Мол, если ты хомяк, купивший процессор ради Doom, тебе и так сойдет.
К счастью, реакция общества, конкурентов и даже партнеров Intel была крайне негативной. Уже тогда процессорам доверяли лифты, оборудование, самолеты. Было ясно, что процессор, который неверно считает – это тикающая бомба. В результате Intel все-таки заменила процессоры, и общий убыток составил 475 миллионов долларов. Даже сегодня это много, а в 1994 году сумма была космической.
Проблема Пентиума коснулась и софта. В компиляторы Delphi, Basic и других языков добавили костыль: если текущий процессор равен “Pentium такой-то”, то операции с числами эмулируются программно. Это и замедление вычислений, и лишний код в компиляторе.
Больше Intel не позволяла себе таких фокусов. Наработки Томаса Найсли включили в процесс верификации процессоров, чтобы не допустить ошибок в будущем.
Почитать об ошибке Pentium FDIV можно в Википедии; есть краткая версия статьи на русском. На Ютубе по словам Pentium FDIV ищутся подробные разборы ошибки.
-
Числа №12. Числа в приставках
Думаю, с числами мы разобрали самые сложные моменты. Приведение к двоичной дроби, нормализация, битовый формат, сложение – все это мы прошли. Тему пора заканчивать, и чтобы плавно из нее выйти, расскажу несколько шуток-прибауток.
Первая из них в следующем. Мы привыкли, что числа с плавающей запятой есть в каждом утюге. Так было не всегда: ранние процессоры считали только целые числа. Дробные, если они были нужны, писали вручную. Использовали комбинации шагов, что мы рассмотрели. Конечно, это был бардак: представьте, что числа складываются по-разному в разрезе даже не компиляторов, а их версий. Именно из этого бардака вышел стандарт IEEE 754 Floating Point Arithmetics.
Позже в компьютерах появился математический сопроцессор. Среди прочего он считал не только флоаты, но и тригонометрию, степени и логарифмы. Сегодня такой сопроцессор является частью любого процессора, но раньше был отдельным устройством.
Какое-то время математический сопроцессор был дорогим удовольствием. Его не было в игровых приставках. Поскольку они ориентированы на массового потребителя, то устроены максимально дешево. Игры под них писали без использования флотов.
Скорее всего, вы подумали о приставках типа Денди и Сеги. Все верно, но мат-сопроцессора не было и в приставках более высокого класса, например Playstation! Да, первая плойка ничего не знала про числа с плавающей запятой, но при этом стала прорывом в индустрии.
Как же выкручивались разработчики? На Playstation были спортивные симуляторы, стратегии, писишные порты Quake 2 или Diablo. Все это добро работало на целых числах. Если точнее, сишный SDK для Playstation предлагал эмуляцию дробных чисел в двух вариантах: 16/16 или 20/12. Цифры означают число бит под целую и дробные части.
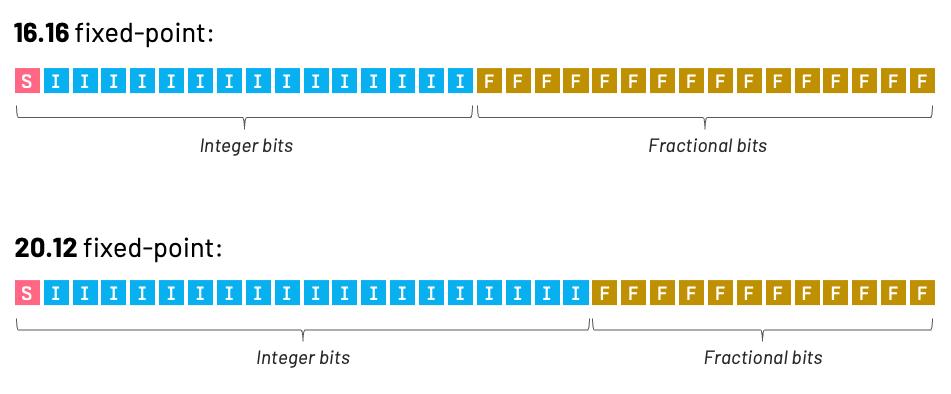
Операции с такими числами выполнялись медленно, потому что раскладывались в серию машинных команд. Но графический процессор Playstation, который воплощал цифры в полигоны и вершины, не знал ни про какие дробные числа. Он работал только с целыми – пикселями.
Из-за того, что пикселей приставка выдавала немного, некоторые объекты дребезжали – чуть подергивались. Это называлось Jitter и было особенно заметно в играх “а-ля Кодзима”, то есть с закосом под кинематографичность. Сцены на движке игры, плавные движения камеры… при малейшем ее смещении объект мог дернуться на несколько пикселей, потому что все расчеты были в целых числах. Отсюда эти дребезжания и подергивания. Частично эту проблему решили в эмуляторах.
Материал этой заметки основан на статье How PlayStation Graphics & Visual Artefacts Work. Я прочитал ее пару лет назад и был поражен сложностью, на которую шли инженеры и программисты, чтобы порадовать нас – школьников-нищебродов. Спасибо им за игры, сюжеты, контент, на котором я вырос. Не все мои друзья увлекались плейстейшеном, но для меня он был главным увлечением и дал много пищи для ума.
-
Числа №11. Большие десятичные типы
Из прошлых заметок ясно, почему Float нельзя использовать для денег: вы не контролируете точность. В этих случаях говорят: используйте классы
BigIntegerиBigDecimal. Они хранят циклопические числа с гарантией точности. Что это за классы такие и как они устроены?Вспомним, что целое число можно представить массивом разрядов. При сложении разряды складываются и проверяется переполнение. Если оно было, то к следующему разряду прибавляется единица и так далее.
Условный класс
BigIntegerустроен именно так: он хранит знак и числовой массив. Каждый его элемент — разряд. При этом разряд очень велик: как правило это integer, то есть около двух миллиардов! За счет этого достигается невероятная емкость. Если в каждом элементеMAX_INTзначений, а всего их — тожеMAX_INT, то итоговое число равноMAX_INT ^ MAX_INT, то есть два миллиарда в степени два миллиарда. Наверное, если бы каждый атом был Вселенной, то и тогда итоговое число атомов не превысило бы этой цифры.
Складываются такие числа поразрядно, в столбик. Берутся нулевые элементы массивов и суммируются как два integer с учетом переполнения. Если оно было, в нулевой разряд идет остаток, а в следующий накидывается единичка. Аналогично устроено вычитание.
Класс
BigDecimalустроен просто: этоBigIntegerс данными о том, сколько разрядов хранится после десятичной запятой. Как и в случае сFloat, при сложении и вычитании число “плавает”, но на этот раз без потери точности. Мы не ограничены 32 битами, в нашем распоряжении вся оперативная память.Получается, что условные
BigDecimalиBigInteger— это программная эмуляция больших чисел. Операции над ними раскладываются в серию машинных команд, например когда складываются два разряда. Однако таких разрядов много, плюс мы проверяем переполнение вручную. Такие операции очень медленны в сравнении с теми, что выполняются на процессоре. Поэтому к программной эмуляции прибегают только если точность критически важна.Postgres предлагает тип
numeric— высокоточное хранилище чисел. Он хранит знак, масштаб и точность — сколько разрядов выделить на число и сколько проходится на дробную часть. Далее идет массив типаshort[]— двухбайтовых элементов. Каждый элемент — это разряд от 0 до 9999; их число не ограничено.Один элемент хранит 10.000 значений, два элемента — 100.000.000 значений. Три — накиньте еще четыре нуля и так далее. Складываются
numericкак описано выше, только переполнение проверяется для порога в 10 тысяч.Почему в Postgres выбрали именно такой порог, я не знаю. Скорее всего, это ускоряет десятичные операции, например умножение на десятки, деление на сто и так далее.
Если вы пользуетесь
numeric, обязательно указывайте точность. Иначе возможна ситуация, когда в целой части, скажем, 123, а в дробной — километровый хвост.Numericотносится к типам произвольной длины, и если значение не поместиться в 512 байтов (или около того), то будет сброшено в TOAST-хранилище. Проблемы можно избежать, указав точность:sum numeric(15, 2).Впрочем, даже столь мощные десятичные типы бывают избыточны. Иногда деньги хранят в микроцентах, положение на плоскости — в нанометрах и так далее. Типа
longвполне хватает для этого. Главное — найти такой масштаб, в рамках которого вам удобно.
Writing on programming, education, books and negotiations.