-
Уязвимое ПО
Специалист по безопасности: Иван, у тебя установлено уязвимое ПО. Немедленно обновись! Я: можно точнее? У меня установлено много программ. Специалист: минуточку, формирую отчет… ага, это GNU Emacs версии 29. Срочно обновись до версии 30.1!
Конечно, я оперативно обновил GNU Emacs и теперь смеюсь в кулачок над теми, кто до сих пор в опасности.
Если серьезно, то в Емаксе 29 и правда есть уязвимость, связанная с org-файлами. Если открыть документ ниже, файл ~/hacked.txt будет создан автоматом. Проверил – работает:
#+LINK: shell %(shell-command-to-string) [[shell:touch ~/hacked.txt]]Одно время я баловался с орг-файлами, но перестал. На мой взгляд, шутка “офисный пакет в Емаксе” зашла слишком далеко.
-
Код картинкой
Иные ребята постят код картинкой с помощью какого-то сервиса. Прикладываю образец.
Мне непонятно следующее: во-первых, зачем два сантиметра отступа по краям? Это, типа, тень? Зачем она?
Второе — зачем яблочные кнопки в левом верхнем углу? Кто-то будет их нажимать? Так-то это еще один лишний сантиметр по высоте. Если у человека винда, будете генерить для него виндовые кнопки?
Словом, типичный современный дизайн. Бесполезные тени, отступы и слои.
В самом размещении кода картинкой ничего зазорного нет. Сегодня нет гарантии, что код не будет переколбашен алгоритмами, сокращалками, подсветкой, пряталками под кат, типографами и так далее.
И еще — код с картинки превосходно читается в маковской проге для просмотра картинок. Так что в крайнем случае его легко восстановить.
-
Теги в био
Когда пишете о себе в профиле, следуйте правилу: на первом месте идет то, чем вы зарабатываете. Все остальное — музыка, танцы, увлечения детства — должны быть указаны как хобби, даже если вы очень в этом хороши.
Например: программист, увлекаюсь математикой и живописью. Текст нормального человека. Понятно, чем он зарабатывает и на какие темы с ним можно поговорить.
А если так: математик, ученый, программист, музыкант, ментор, знаток лошадей? Мысленно я добавляю: а еще клоун с непомерным ЧСВ. Кто ж ты, наконец?
Во втором примере человек ведет себя как таксист: он владелец газет-параходов, а такси у него для души. Ну-ну.
Разумеется, деньги приносит только что-то одно. Если ты программист, зачем писать, что ты музыкант и математик до кучи? Так-то много кто закончил музыкалку или лабал обдолбанным на гитаре. Но это не приносит денег, поэтому — хобби.
Или человек на серьезных щщах пишет: как физик я утверждаю, что… При этом у него действительно образование физика, олимпиады и все такое. Одна беда — человек зарабатывает сайтами на PHP. Какой ты к черту физик! Ты веб-разработчик.
Я лично тоже программист, линейный кодер. Это приносит мне деньги последние 18 лет или около. Я закончил музыкальную школу по классу скрипки, могу сыграть “Аве Мария” на фортепиано, неплохо пел в хоре — не солировал, но был на хорошем счету. При этом я не музыкант.
В 7 лет я играл во взрослом спектакле “Господин де Пурсоньяк”, это комедия Мольера. Мне даже платили зарплату. Но я не актер.
Я регулярно писал городские олимпиады по математике, а в старших классах выиграл областную. При поступлении в универ математику засчитали автоматом. Но я не математик.
Я работал на телевидении, знаю основы видеомонтажа, могу смонтировать несложный фильм. Могу сделать анимашку в After Effects. Но я не режиссер и не моушен-дизайнер.
Я работал в типографии, обслуживал машину Heidelberg (см. картинку). Могу сверстать книгу или журнал любой сложности и довести их до станка. Знаю основы полиграфии: цветоделение, спуск полос, сложный черный, overprint, ink depth, preflight и многое другое. Но я не полиграфист.
Еще я написал две книги и пишу третью, так что могу называться автором. Но я живу не за счет книг, поэтому я не автор.
Все это осталось в прошлом и порой пригождается, но вообще я программист. Так что не надо врать: ни себе, ни другим.
Обращаюсь к ребятам, у которых в bio десяток тегов — давайте скромнее. Простой принцип: на что живешь, то идет первым. А потом — игра на басу, математика, лошади, толкинизм и остальные развлечения.

-
Нейросети и контент
Уже не раз замечаю: пишет человек в Телеграм, а потом раз — все пользуются нейросетями, один я как лох. И начинается: к каждому посту — желтые картинки, а если видео или лонгрид, то краткий пересказ.
Давайте обсудим то и другое — картинки и пересказ.
Самое важное, что нужно знать про изображения — их ценность пропорциональна затраченному на них времени. Если бы автор постил эти желтые картинки десять лет назад, его бы спрашивал каждый второй — у какого иллюстратора вы их заказываете? Сегодня всем ясно, что это генератор, и в лучшем случае на него тратится минута. Иные авторы сознательно пишут название модели, версию и промпт — как будто найдется такой же убогий, который будет генерить еще одну картинку по этому промпту.
Далее, картинка должна нести пользу. Если человек пишет статью про алгоритмы и рисует состояние массива, это польза. Еще круче, если он рисует анимашки, где элементы прыгают по ячейкам. Если он сгенерил желтого кота за ноутбуком, пользы нет.
Бред в том, что айтишники и дизайнеры генерят эти картинки для себе подобных. Обе стороны знают, что это сгенеренный треш, на который потратили дай бог минуту. И всех устраивает.
Я считаю, что сгенеренная картинка к посту — это безвкусица терминальной стадии. Примерно как Лада Калина, опущенная под ноль и с хвостом как у самолета. Или цыганские квартиры. Или айфон в розовом чехле со стразами.
Теперь пересказ. Дорогие авторы: чтобы текст не пришлось пересказывать, пишите так, чтобы из него нельзя было что-либо выкинуть. Обычно пост — это одна мысль, которая состоит из тезиса и подкрепляющих доводов. Каждый довод состоит из трех-четырех предложений. Если текст следует такой структуре, из него нечего выкинуть — все нужно. А если сжать до одного абзаца, он потеряет смысл.
“В этом тексте Петя говорит, что нужно писать хороший код, а писать плохой код не нужно”. Спасибо.
Пересказ видео или лонгридов я тоже не могу понять. Во-первых, если я читаю человека, то доверяю ему и полагаю, что в видео какая-то польза. Если там сплошная вода, я просто не читаю и не смотрю автора, и никакие пересказы не помогут.
Во-вторых, я понимаю ученика, который читает “Войну и мир” в кратком изложении. Завтра его спросят про Наташу Ростову, а получать двойку не хочется. Но вас же не заставляют пересказывать чей-то видос на оценку. Предполагается, что это в удовольствие. Зачем тогда пересказ?
Да и вообще, прочитав пару пересказов, я понял: это примерно как посмотреть трейлер фильма. Так-то он тоже дает много информации: вот герой, вот древнее зло, неприступная женщина, которая будет нашей, шутка в напряженный момент, кусочек постельной сцены, финальный удар — все, считай посмотрел.
Словом, авторы, которые открыли для себя нейросети, почему-то не понимают очевидного — их открыли для себя все. Как подростки, которые покупают модный шмот после рекламы у каждого блоггера. На этом фоне, наоборот, выделяются те, кто пишет в привычной манере — просто выражая свое мнение. Искренне желаю авторам это понять.
-
Системный дизайн
В айти есть забавная вещь – собеседование а-ля “систем-дизайн”. Компании выносят ее в отдельный собес наравне со скринингом, алгоритмами и так далее. Теперь наряду с красно-черными деревьями надо помнить, как задизайнить убийцу Твиттера или Ютуба. За ночь перед собесом покупается книга Алекса Сюя, штудируется, и наутро кандидат рисует ноды в Кубернетисе с Кафкой в кластере.
Когда-то систем-дизайн был не везде, и это можно было стерпеть. Но сегодня он в повсеместно – от Гугла до КолымВодоканала. С приходом в массы систем-дизайн превратился в ритуал или проще говоря – в клоунаду.
Так, ритуал предполагает, что нужно сделать аналог Твиттера. При этом нельзя сразу писать код или рисовать диаграммы. Нужно задать интервьюеру вопросы: сколько пользователей в день, сколько они пишут твитов, сколько селебрити (людей, чья популярность резко выше остальных), сколько датацентров и так далее. Потом цифры перемножаются, чтобы получить размер данных на диске. Например, умножим миллион юзеров на пять твитов, на 100 байтов,
на число цилиндров, на длину сектора…Как вы поняли, эти цифры взяты с потолка и отношения к реальности не имеют. Нельзя построить сервис, который посещают миллион пользователей в день сразу после открытия. Так не бывает, если у вас нет другого такого же сервиса. Но вас не пустят к рисованию схем, пока вы не посчитаете цифры.
Представляю: сели и посчитали, что на хранение данных понадобится петабайт данных. Идем такие к инвестору и говорим: мистер Джонс, дайте ундециллион долларов на пять датацентров с петабайтами дискового хранилища, бекапы на магнитной ленте в Арктике, ну и столько же для тренировки AI. Да, убийца Твиттера, успех 100%, мы все посчитали.
Слушайте, хорошо дизайнить петабайты данных и датацентры на Луне! Дорого-богато, ни в чем себе не отказываем. А попробуй задизайнить, когда горизонт бюджета — шесть зарплат. Весь дизайн разбивается о реальность: база с кафкой на одной ноде, бекапы не делаем, потому что некогда и дорого, логи грепаем в терминале.
Если серьезно, то на такие ресурсы денег никто не даст – если вы не господрядчик, конечно. Скажут – выкати минималку, приведи хотя бы сто тысяч пользователей, потом и поговорим. И это правильный подход.
А во-вторых, когда нас просят задизайнить Твиттер, Инстаграм или Ютуб, забывают одну мелочь – ни один из этих сервисов не дизайнили по этому принципу. Каждый айти-гигант начинался со стартапа с сотней детских болезней. Твитер в молодости был поделкой на Руби и падал чаще, чем работал. Гугл вышел из гаража. Первый Яндекс работал на личном компе одного из разрабов и перезагружался, когда тот толкал его ногой. Каждый сервис прошел особый путь роста, и рассчитать его на бумажке – все равно что запланировать жизнь ребенка: во столько-то лет он поступит сюда, выйдет на работу туда, вступит в брак с тем-то. Это глупость, потому что в жизни все оказывается не так.
Сегодня стартапы начинают с гексагонных архитектур, сине-зеленого деплоя и так далее. Увы, часто этого хватает на год-два, не больше. Счета за Амазон съедают выручку, и даже когда компания спохватится, бывает поздно. Я работал в стартапах и знаю это не по рассказам друзей, а видел воочию. Систем-дизайн буквально съедает бизнес. Лично слышал от основателя фирмы: “мы не будем возражать, если вы найдете другую работу”.
Кроме того, даже Гугл со своими мощностями порой не может раскрутить сервисы. Может, помните Google Wave, прообраз современной Слаки? Общество было не готово к формату, и проект закрылся. То же самое произошло с Google Buzz, аналогом Твиттера. Он продержался два года. Не сомневаюсь, что в Гугле очень точно перемножили число людей на длину сообщения, но что-то пошло не так. Еще пример – Google Video, там Гугл просто капитулировал и понял, что проще купить Ютуб, чем делать платформу самому.
Так что систем-дизайн стал очередным ритуалом, который нужно выучить и пройти. Еще одна боль для тех, кто хочет поменять работу или войти в айти. Разумеется, читая Сюя, можно узнать много полезного – это справедливо для любой книги в принципе. Но делать из ритуала культ – это глупо.
-
SQL как REPL
Самый надежный способ проверить, работает ли код – запустить его. Компиляторы и линтеры отсеивают ошибки, но не все. Легко написать код, который пройдет компиляцию, но при запуске упадет.
Поэтому языки с REPL-ом такие продуктивные. Любой клочок кода можно выполнить в редакторе и посмотреть, что будет. Это не отменяет тесты и другие практики, но здорово помогает.
Я исповедую тот же принцип в отношении SQL. SQL – это репл к данным. Другая плоскость, но принцип такой же. Что-то ввели – тут же получили результат. Чтобы работать продуктивно, нужно иметь возможность в любой момент выполнить запрос к данным, похожим на прод.
Чтобы выбрать данные, я открываю PGAdmin и пишу SQL ручками. Сперва убеждаюсь, что он вернул то, что я ожидал. Потом смотрю план, проверяю, попал ли в индексы. Если все в порядке, переношу запрос в код с минимальными правками.
Иногда я даже забиваю на тесты, потому что все равно проверяю запросы на тестовой базе. Ожидаю, что если кто-то исправит запрос, то проверит его тоже. Однако я всегда пишу тест, который выполнит запрос на пустой базе – чтобы убедиться, что нет ошибок синтаксиса.
Если в проекте используется ORM, то непонятно, как быть. Скажем, написал я запрос с группировкой и джоинами. От отлично работает. Как перенести его в ORM? Даже если я напишу цепочку методов, нужно проверить, что итоговый SQL выглядит как я хотел. Можно включить логирование запросов и посмотреть, что получилось, но способ сомнительный. Получается двойная работа: пишешь SQL, переносишь в объектную модель, подсматриваешь логи, правишь объекты и так по кругу.
Со временем я понял, что лучше сидеть на одном стуле, а не на двух. Поэтому – оставьте SQL в виде SQL. Любой человек скопирует его в PGAdmin и получит результат. Когда вместо SQL – каскад квери-билдеров, теряется та самая быстрая связь, о которой речь в начале. Все, она прервана, репл не работает, очередной радостью меньше.
Зачем так жить?
-
Нарезка интерфейса
На текущем месте я работаю над веб-приложением для сотрудников. Недавно выкатили раздел с большой таблицей. Я делал бекенд, там сотни строк скуля, чтобы собрать данные по всей базе джоинами. Кое-что материализуется по крону, и еще много хранимых функций.
Фронт у нас тоже продвинутый: SPA, re-frame (кложурная обертка над Реактом), сотни модулей на кложур-скрипте, десятки аякс-запросов на страницу. Используется какой-то Material UI или вроде этого. Все элементы пухлые как подушки и затянуты в скругленные прямоугольники.
И слои. Много слоев, будто смотришь на разрез почвы в атласе. Сначала шапка с логотипом и аватаркой в правом углу. Потом главное меню. Потом второстепенное меню. Потом тулбар. Потом дата-грид, но у него свой тулбар. Потом шапка таблицы. Потом фильтры. Когда высота перевалила за середину, начинаются строки. В подвале – еще один тулбар с пагинацией.
Как в современном кинотеатре: реклама, логотип, трейлер, логотип, трейлер, логотип, короткометражка, логотип, логотип, фильм. “Черт, моя кола выдохлась” (с) не помню кто.
Так вот, что я сделал. Беру скриншот интерфейса, закидываю в Фигму. Клонирую, ставлю рядом. Нарезаю второй скриншот на слои по границам тулбаров, шапок и прочего. Потом у каждого слоя срезаю чуть-чуть сверху и снизу – будто уменьшаю margin-top и bottom, только в растре.
Схлопываю пустоту – нарезка занимает на четверть меньше, чем оригинал.
Беру два тулбара и объединяю в один – напомню, в каждом из них по одной кнопке. Получаю -2 сантиметра по высоте. Подрезаю шапку таблицы, она тоже непомерно вытянута.
Выигрыш уже не в четверть, а на треть.
Срезаю капсулу со скругленными краями вокруг таблицы. Переставляю пагинатор. Подрезаю каждую строку на пять пикселей сверху и снизу. Клонирую их до конца экрана.
Считаю: на первом скриншоте девять строк, на втором, где нарезка – двадцать семь. Ровно в три раза больше.
При этом я не менял шрифт и ничего не масштабировал. Все действия свелись к кропу и перемещению. Буквально из ничего нашлось место, чтобы вместить в три раза больше данных.
В итоге улучшения дизайна свелись к тому, что кнопка из одного слоя переехала в другой. Теперь влезает не 9, а целых 11 строк. Интерфейс должен быть воздушным, иначе пользователи теряются.
Подтвердилось все то, что я обычно пишу про дизайн, и пересказывать это нет смысла.
-
Don't use println with two and more arguments
When printing, please avoid
printlninvocations with more than one argument, for example:(defn process [x] (println "processing item" x))Above, we have two items passed into the function, not one. This style can let you down when processing data in parallel.
Let’s run this function with a regular
mapas follows:(doall (map process (range 10)))The output looks fair:
processing item 1 processing item 2 processing item 3 processing item 4 processing item 5 processing item 6 processing item 7 processing item 8 processing item 9Replace
mapwithpmapwhich is a semi-parallel method of processing. Now the output goes nuts:(pmap process (range 10))) processing itemprocessing item 10 processing item processing item8 7 processing item 6 processing itemprocessing item 4 processing item 3 processing item 2 5 processing item 9Why?
When you pass more than one argument to the
printlnfunction, it doesn’t print them at once. Instead, it sends them to the underlyingjava.io.Writerinstance in a cycle. Under the hood, each.writeJava invocation is synchronized so no one can interfere when a certain chunk of characters is being printed.But when multiple threads print something in a cycle, they do interfere. For example, one thread prints “processing item” and before it prints “1”, another thread prints “processing item”. At this moment, you have “processing itemprocessing item” on your screen.
Then, the first thread prints “1” and since it’s the last argument to
println, it adds\nat the end. Now the second thread prints “2” with a line break at the end, so you see this:processing itemprocessing item 1 2The more cores and threads you computer has, the more entangled the output becomes.
This kind of a mistake happens often. People do such complex things in a
mapfunction like querying DB, fetching data from API and so on. They forget thatpmapcan bootstrap such cases up to ten times. But unfortunately, all prints, should invoked with two or more arguments, get entangled.There are two things to remember. The first one is to not use
printlnwith more than one argument. For two and more, useprintfas follows:(defn process [x] (printf "processing item %d%n" x))Above, the
%nsequence stands for a platform-specific line-ending character (or a sequence of characters, if Windows). Let’ check it out:(pmap process (range 10))) processing item 0 processing item 2 processing item 1 processing item 4 processing item 3 processing item 5 processing item 6 processing item 8 processing item 9 processing item 7Although the order of numbers is random due to the parallel nature of
pmap, each line has been consistent.One may say “just use logging” but too often, setting up logging is another pain: add
clojure.tools.logging, addlog4this, addlog4that, putlogging.xmlinto the class path and so on.The second thing: for IO-heavy computations, consider
pmapovermap. It takes an extra “p” character but completes the task ten times faster. Amazing! -
Пустая истина (3)
После второго раунда обсуждений стало ясно, почему every от пустого множества дает истину. Читатель Миша Левченко дал внятное объяснение, которое понятно мне как программисту. Оно не опирается на кванторы и логику. И хотя вывод все равно не нравится, приведу объяснение здесь.
Дело в том, что операции над списками нужно рассматривать как свертку. Есть такая функция
reduce(она жеfold), которая принимает функцию двух аргументов и коллекцию. Результат функции такой:fn(fn(fn(fn(item0, item1), item2), item3), item4)...Например, для сложения чисел 1, 2, 3, 4 получим форму:
(((1 + 2) + 3) + 4)Reduceможет накапливать в том числе другую коллекцию: словарь или список. Это вообще очень мощная функция. Про себя я называю ее царицей функций, потому что через reduce можно выразить что угодно.Reduce выше прекрасно работает, если элементов два и более. Когда их один или ноль, начинаются граничные случаи. Одно из решений в том, что
reduceможет принимать т.к.init— первичный элемент, который подставляется в начало цепочки. Чаще всего он выступает коллекцией-аккумулятором, но может быть и простым скаляром.Если передать
init, форма будет такой:fn(fn(fn(init, item0), item1), item2)...Другими словами, он гарантирует, что элементов больше нуля. Если основной список пустой, просто вернем init.
Так вот, в терминах свертки функция
ALL(которую я раньше называлevery?) выглядит так:(func ALL [fn-pred items] (reduce (fn [x y] (and x (fn-pred y))) true items))Демо:
(ALL int? [1 2 3]) true (ALL int? [1 nil 3]) false (ALL int? []) trueА вот функция
ANY(что хотя бы один элемент вернул истину для предиката):(func ANY [fn-pred items] (reduce (fn [x y] (or x (fn-pred y))) false items))Демо:
(ANY int? [1 nil 3]) true (ANY int? [nil nil nil]) false (ANY int? []) falseАналогично работают функции суммирования: это
reduce, где начальные элементы равны 0 и 1. Поэтому(+)дает 0, а(*)— 1.Как видим, все это можно объяснить без греческих букв и терминов. А пустая истина, о которой я писал ранее, считается истиной только потому, что таков начальный элемент свертки.
Другое дело, что такой подход все равно мне не нравится. В каждом из них скрыт начальный элемент: для
ALL—true, дляANY—false, единица для умножения и так далее. Считается очевидным, что он должен быть именно таким. А мне это не очевидно. Я спотыкаюсь, когда вижу, что произведение элементов пустого списка равно единице. Я бы предпочел неопределённость — то есть null.Я в курсе про нейтральный элемент: ноль для сложения, единица для умножения. Но на пустых списках это как-то не очень. Душа не принимает, если совсем честно.
В самом деле, в математике оператор умножения — бинарный, ему нужно два операнда. Нельзя записать что-то вроде
5 * = 5— тут не хватает операнда справа. С какой стати мы обходим математические правила — не ясно.Я часто использую
reduceи вывел правило: всегда указываю начальный элемент. Например, чтобы сложить список чисел, я пишу так:(reduce + 0 numbers)вместо
(apply + numbers)Потому что во втором случае не очевидно, во что накапливается результат.
Словом, пока что меня отпустило на тему пустой истины. Все оказалось просто: это свертка, где начальный элемент — истина. Крайне неочевидно, на мой взгляд. Чтобы не отстрелить ногу, либо проверяйте коллекцию на пустоту, либо пишите явный
reduce, где начальный элемент — ложь, если того требует контекст. -
Пустая истина (2)
После прошлой заметки мне стали приходить, что называется, письма читателей. Их можно разделить на два вида.
Первый — ты не шаришь в логике, сейчас я все объясню. Гляди… (далее километр греческих букв, термины “антецедент”, “консеквент” и другие). Вывалив все это, человек считает, что открыл мне глаза. Я ничего из этого не понимаю, поэтому прошу — не утруждайтесь подобными доказательствами.
Второй тип писем — в языке X предикат every работает так же: для пустого множества вернет истину независимо от предиката. Да, согласен. Еще пять лет назад выполнил в Постгресе такой запрос:
select 1 = ALL (array[]::int[]); t, получил истину и опечалился. Если же поменять
ALLнаANY, получим противоположный результат:select 1 = ANY (array[]::int[]); fЗдесь мы уподобляемся Джаваскриптерам: подаем нелепый ввод, получаем нелепый вывод. При этом силимся подвести его под какую-то базу: антецеденты-консеквенты, кванторы и прочее.
А дело в другом: аппарат логики не учитывает неопределенность. Это утопичная модель, где есть только истина и ложь — третьего не дано. В тех местах, где модель не ложится на реальность, начинаются подтасовки: истину раз — и обозвали “пустой”. То есть как бы истина, но не совсем.
Меня это страшно бесит, прям так, что не передать словами. Если результат отличен от истины и лжи, заведи под него тип. Переработай модель логики, в конце концов. Признай, что старая модель ограничена и не подходит под прикладные задачи. И уж чего точно я не пойму, так это того, почему в языках программирования мы опираемся на логику бог знает какой давности. Нужно делать так, чтобы удобно здесь и сейчас, а не как принято в учебнике логики.
Правильный ответ в том, что в функции every пустое множество — это неопределенность, краевой случай. То же самое, что получить первый элемент массива, когда он пуст. В зависимости от языка мы получим null или исключение, но точно не число 42 с пометкой “пустое” — это нонсенс.
Обратимся к более достойной науке, чем логика — математике. Рассмотрим функцию
y = 1/x(см. график ниже). Прелесть этой функции в том, что в точке 0 ее значение не определено. Если точнее, приx=0результат будет бесконечностью, причем даже нельзя сказать, какой именно — положительной или отрицательной. В зависимости от того, с какой стороны приближаться к нулю — правой или левой — функция будет уходить в плюс- и минус-бесконечность.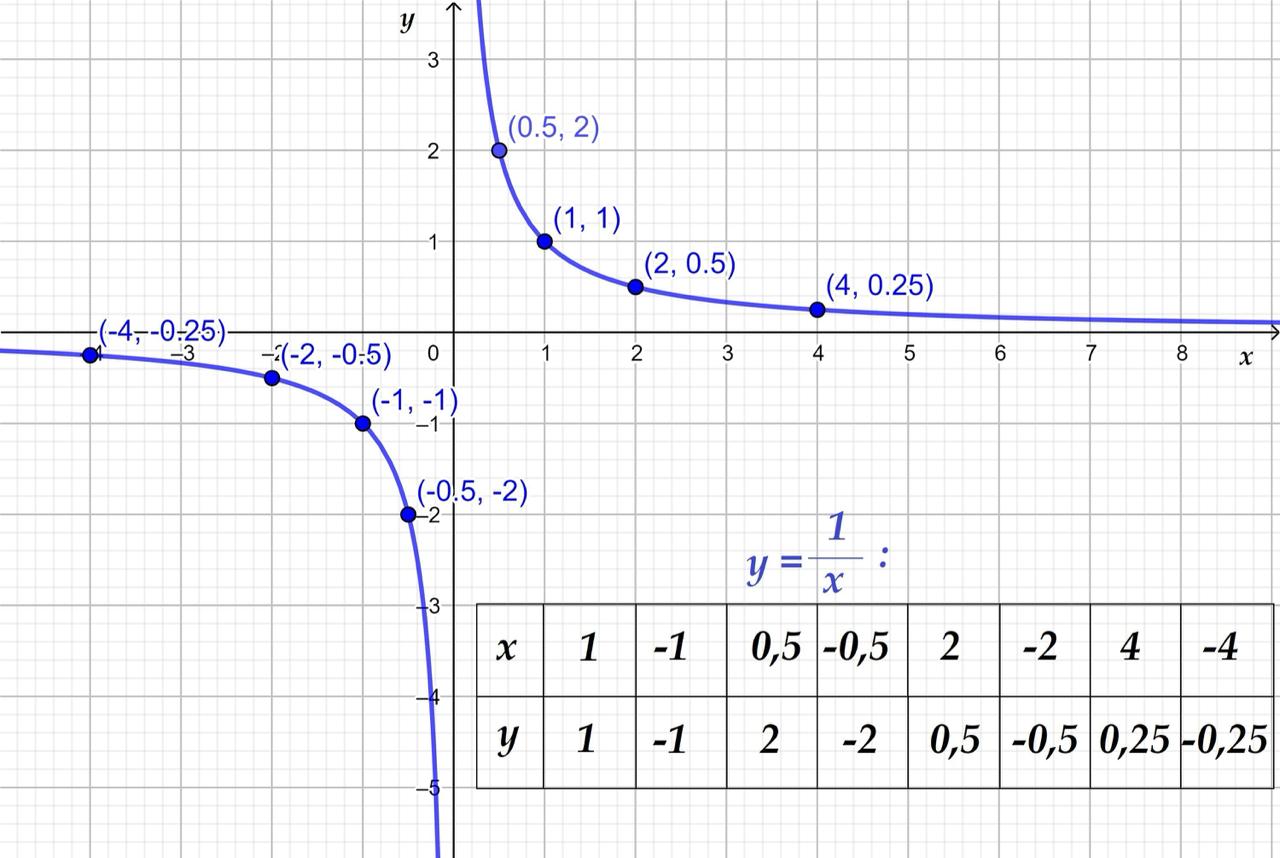
Область определения этой функции записывается так:
(-inf, 0);(0, +inf). В нуле функция не определена — и при этом никто не умер. Бывают функции и с большим количеством точек и даже целых областей, где они не определены. И ничего — нас это устраивает, с функцией можно работать.(В скобках отмечу, стандарт чисел с плавающей запятой предусматривает комбинации битов, которые трактуются как обычная бесконечность, а также плюс- и минус-версии. То же самое касается нуля: может быть ноль, минус ноль и плюс ноль. Это помогает при сходимости рядов, когда мы пришли к нулю и хотим знать откуда — справа или слева. По крайней мере в Фортране этими штуками пользовались).
Другой пример из математики — решение квадратного уравнения вида
ax^2 + bx + c = 0. У него может быть либо два корня, либо один, либо никаких. Во втором случае еще можно слукавить: сказать, что один корень — это два одинаковых. Ладно, но с третьим вариантом это не прокатит. Нельзя вернуть какое-то левое число и сказать, что это пустой корень. Они не определены.Пример из географии: чтобы попасть на северный полюс, нужно идти на север. Каким же будет северное направление на Северном полюсе? Ответ — никаким, оно не определено.
То же самое с предикатами: когда нас просят сказать, что все камни белые, но камней нет, это неопределенность. Потому что если сказать да, оказывается, что камни в том числе черные, прозрачные, резиновые — и все это одновременно. Этого не было, если бы every возвращал NULL — я имею в виду не в коде, а на уровне логики.
Уж не говорю, что пустая истина совершенно неприемлема на бытовом уровне. Это либо троллинг, либо саботаж, либо неразбериха.
Когда я читаю в документации: if the stream is empty then true is returned and the predicate is not evaluated — мне немного плохеет. Выходит так, что функция возвращает один и тот же результат при РАЗНЫХ случаях. А значит, ответственность перекладывается на тебя — будь добр сам проверяй, пустое множество или не пустое.
Это просто плохой API — что, в общем-то, не редкость. Надо это признать и больше так не делать. А вот оправдываться логикой и чепухой а-ля “антецедент-квантор” — это отстой.
Под конец напомню вам о Булгакове. Если свежесть отлична от первой, это уже не свежесть. Если перед истиной стоит какой-то тег — пустая, неполная, вторичная — то это не истина. Вот и все, что нужно запомнить. И это — истина.
Writing on programming, education, books and negotiations.