Степень схожести строк (коэффициент Танимото)
Иногда нужно определить степень схожести двух строк, т.е., насколько одна строка похожа на другую. Например, у вас есть список названий фильмов. Источники разные, нет никаких уникальных идентификаторов, только заголовки. При этом стоит учесть, что даже самые простые названия могут быть написаны по-разному: «ЗАЛОЖНИЦА 2» и Заложница 2. Очевидно, что сравнение этих строк в лоб ничего не даст: лишние символы, разный регистр.
Строки можно рассматривать как множество символов. Две строки — два множества. Коэффициент Танимото позволяет определить степень схожести двух множеств:
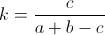
, где:
- k — сам коэффициент от 0 до 1;
- a — количество элементов в первом множестве;
- b — количество элементов во втором множестве;
- c — количество общих элементов в двух множествах.
Изящная функция на Питоне:
def tanimoto(s1, s2):
a, b, c = len(s1), len(s2), 0.0
for sym in s1:
if sym in s2:
c += 1
return c / (a + b - c)
Пара примеров:
print tanimoto('Иван Гришаев', 'Гришаев И.В.')
0.846153846154
print tanimoto('tanimoto test 1', 'testing Tanimoto #2')
0.7
В Питоне работает т.н. утиная типизация, когда важен не тип объекта, а его поля и методы. Нетрудно заметить, что код функции требует от объектов методов длины, вхождения элемента и итерации. Это значит, что вместо строк можно передавать списки, кортежи, словари и другие структуры:
print tanimoto(
(1, 2, 3, 4, 5, 4),
(4, 2, 5, 4, 9, 3),
)
0.714285714286
Конечно, расчет коэффициента нужно производить с умом. Например, вычистить регулярными выражениями лишние символы или передавать строки в одинаковом регистре. И конечно, лучше оперировать строками в юникоде.
Возвращаясь к нашему примеру:
print tanimoto(
u'«ЗАЛОЖНИЦА 2»'.lower(),
u'Заложница 2'.lower(),
)
0.846153846154
Величина 0.85 говорит о том, что оба названия указывают на один и тот же фильм. Однако, не лишним будет на всякий случай сверить год выпуска.
Нашли ошибку? Выделите мышкой и нажмите Ctrl/⌘+Enter
Fc Kuntsevo04, 3rd Mar 2017, link
А на такие строки будет коэффициент 1:
abc и cba
Но они совсем разные. Бесполезный способ.
Ivan Grishaev, 3rd Mar 2017, link , parent
Строки слишком короткие. И лучше сравнивать не по Танимото, а триграммами.
Fc Kuntsevo04, 3rd Mar 2017, link , parent
Проведенный метод сравнивает не строки, множества символов. Можно привести пример длинной строки, что это изменит в алгоритме?
Ivan Grishaev, 4th Mar 2017, link , parent
Я уже написал: Танимото не подходит для строк, потому что в строках важен порядок. Этому посту 4 года, сделайте скидку. Сравнивайте триграммами.
Zverushko, 16th Apr 2019, link
Здравствуйте!
Код имеет ошибки:
1. если сравнивать '1111' и '11', то результат больше единицы.
2. Сравните слова "фотосессии" и "фотосессию" - результат будет 1.
Исправленный вариант на js:
function tanimoto(s1, s2){
s1 = Array.from(s1);
s2 = Array.from(s2);
var a = s1.length;
var b = s2.length;
var c = 0;
for (var sym of s1){
var index = s2.indexOf(sym);
if ( index > -1) {
s2.splice(index, 1);
c += 1;
}
}
return c / (a + b - c)
}
смысл в том, что мы убираем символы, которые уже встречались из второго массива.
Eugene Kartoyev, 17th Oct 2020, link
u'«ЗАЛОЖНИЦА 2»'.lower(),
u'Заложница 2'.lower(),
Вы же привели к единому регистру. Совпадение должно быть 100%.
Если нет, то в алгоритме ошибка.
Как вариант - не учитывать повтор букв. А во второй позиции не то же самое, что А в последней позиции.