-
Видео с митапа о Postgres и JSON
Подъехала запись, очень оперативно, как раз на выходные. Сначала болтология минут на 30, потом техническая демка тоже на 30 минут. Потом вопросы. В сумме почти два часа.
-
Разрешения
Обновил яблочную операционку, и началось: слетели все разрешения. Каждое приложение при запуске кукарекает: можно ли сканить локальную сеть? Можно ли смотреть файлы в Downloads? Воткнул флешку — можно ли подключить Kingston Datatraveler 8Gb? Воткнул микрофон — можно ли подключить микрофон?
Причем это было минорное обновление (последняя правая цифра).
Увы, в 2025 году обновления по-прежнему ломают то, что работало до них. Что у Микрософта, что у Гугла, что у Эпла. Все одинаково хороши. Или это нарочно?
-
Большой запрос
Последние дни я безвылазно сижу в PGAdmin: пишу запрос, чтобы построить важный репорт. В нем уже 470 строк плюс понадобились пять функций для разных преобразований (например денег, округления дат). Итого 550 строк чистого скуля.
Не знаю, что обо мне скажут коллеги, когда это увидят. Наверное, проклянут и будут правы. Но дело в том, что у меня началась профдеформация: мне уже легче писать на SQL, чем на Кложе.
Со временем понимаешь следующий момент. В SQL любое значение — это таблица, а операторы — различные JOIN-ы: левое, правое, внутреннее или декартово произведение. Как только пришел к этому, мышление поворачивается под другим углом.
Скажем, вот список мап в Кложе:
[{:id 1 :name "Ivan"} {:id 2 :name "Huan"} {:id 3 :name "Juan"}]То же самое в SQL:
id name 1 Ivan 2 Huan 3 JuanЛюбая операция над этим списком сводится либо к фильтрации, либо джоину, либо агрегатной функции. Скажем, фильтрация по ID это обычный
where:select * from users where id > 2То же самое, что написать:
(filter #(> % 2) users)Предположим, есть список мап вида “пользователь -> аватар”. В SQL его легко выразить таблицей:
user_id photo_url 1 https://test.com/avatar.jpg 3 https://test.com/cat.jpgА вот их различные объединения: с сохранением левой части (пользователи без аватары останутся):
select users.*, p.photo_url from users u left join photos p on p.user_id = u.id id name photo_url 1 Ivan https://test.com/avatar.jpg 2 Huan 3 Juan https://test.com/cat.jpgи без:
select users.*, p.photo_url from users u join photos p on p.user_id = u.id id name photo_url 1 Ivan https://test.com/avatar.jpg 3 Juan https://test.com/cat.jpgВ общих словах, любой SQL-оператор сводится к джоину. Скажем, новички часто передают список айдишников с оператором IN:
where id in (1, 2, 3, ...999)И не знают, что гораздо эффективнее выразить то же самое джоином и таблицей с полем
id:select * from users u join user_ids on u.id = user_ids.idВ SQL даже одно значение является таблицей. Переменная
x=42— это таблица с колонкойXи кортежем(42, ). Примерно как в Матлабе все является матрицей.Есть расхожее мнение, что джоины тормозят, но вообще говоря это неправда. Джоины очень эффективны. Почти любой оператор можно ускорить, если свести его к джоину с другой таблицей. Если связующее поле индексировано, это будет быстро: почти как выборка. Важно, что выборка проекции двух и более таблиц быстрее, чем две отдельные выборки и обработка их силами Питона или другого языка.
Мышление таблицами и их проекциями — очень крутая вещь. Не знаю, во что это выльется, но чувствую себя как десять лет назад, когда ломал мозги об Кложу после императивного программирования. Волнует и возбуждает.
-
Возможности JSON_TABLE
Небольшая добавка ко вчерашнему посту. Приведу пример, очень близкий к реальности.
Предположим, есть пользователи, они совершают заказы. Каждый заказ состоит из позиций. У позиции есть стоимость и код валюты. Одна позиция может быть в евро, вторая в долларах и так далее.
Задача в том, чтобы собрать из микросервисов нужных пользователей с заказами и позициями и составить табицу: пользователь, заказ, сумма позиций в евро. Для конвертации валют использовать таблицу коэффициентов.
Вот что получается на практике. Вы идете в микросервис А и получаете джейсончик как на первой картинке:

Потом идете в микросервис В, чтобы получить курсы валют:
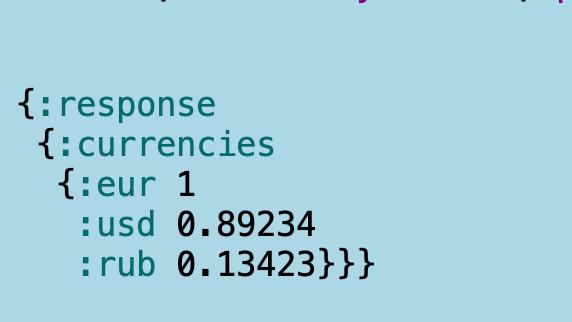
Из этих данных вам предстоит слепить конфету. Имейте в виду, что на картинах — лишь малые подмножества данных. В реальности и полей, и вложенных сущностей больше.
Первая беда в том, что данные вложены, и с ними нельзя нормально работать. Я уже сто раз писал об этом: когда у вас мапа с вектором мап с вектором мап с вектором мап, ни о каком удобстве не может быть и речи. Код, который обходит такое дерево, поддерживать невозможно, неважно Питон это или Кложа. В первом случае это будет императивный быдлокод, во втором — функциональный. Это когда код — цепочка из десяти вызовов
map/mapcat/reduce/group-by.В Кложе есть макрос
forдля декартовых произведений, но для каждого дерева нужно писать свою логику. Универсальный вариант я пока не придумал.Вот как сделать то же самое в SQL. Загоняем оба джейсона в базу. Теперь плющим первый функцией
JSON_TABLE: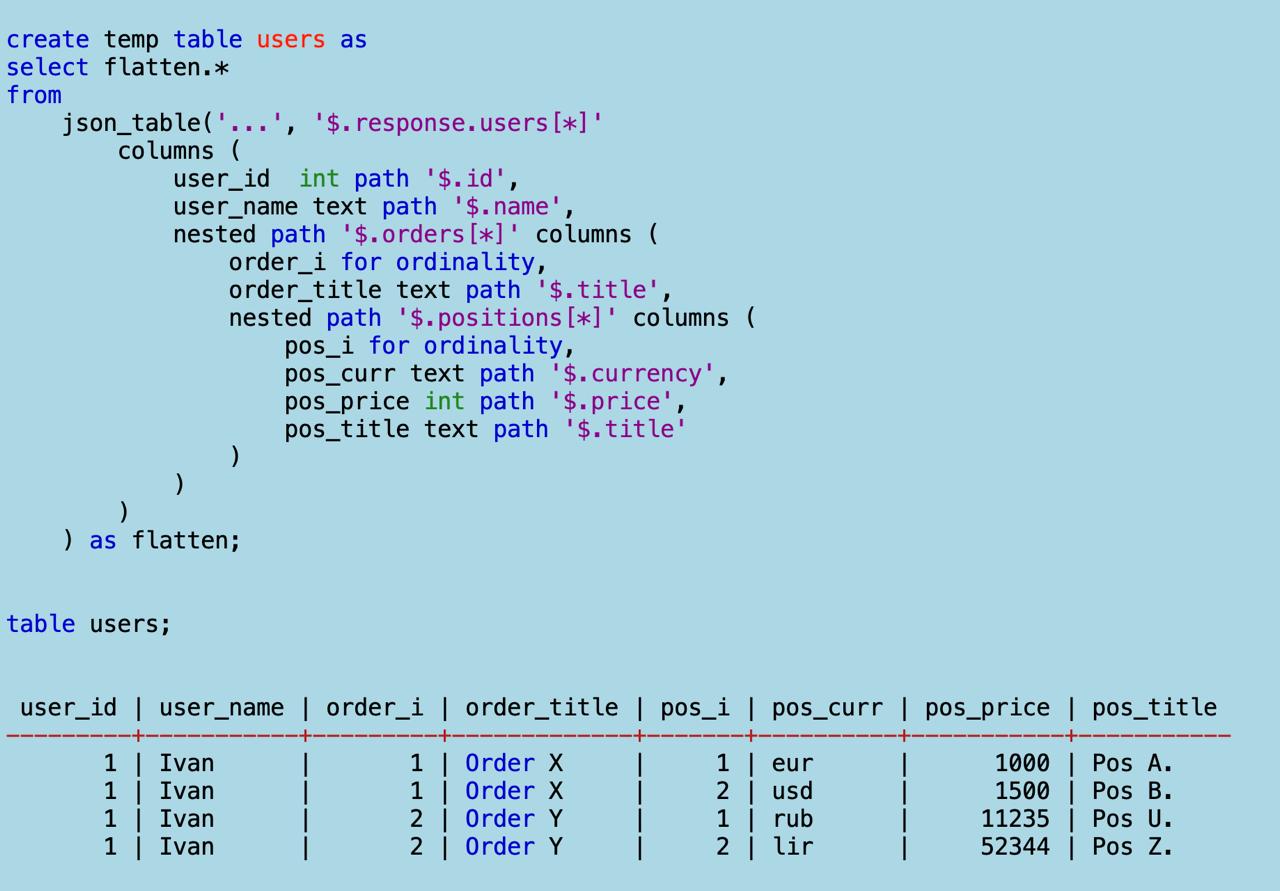
Получаем таблицу
users. Все плоско и декларативно. Обратите внимание на суррогатные поляorder_iиpos_i— номера мап в массивах. Это значит, если я захочу свернуть таблицу обратно в дерево, не будет никаких проблем.Теперь плющу курсы валют:
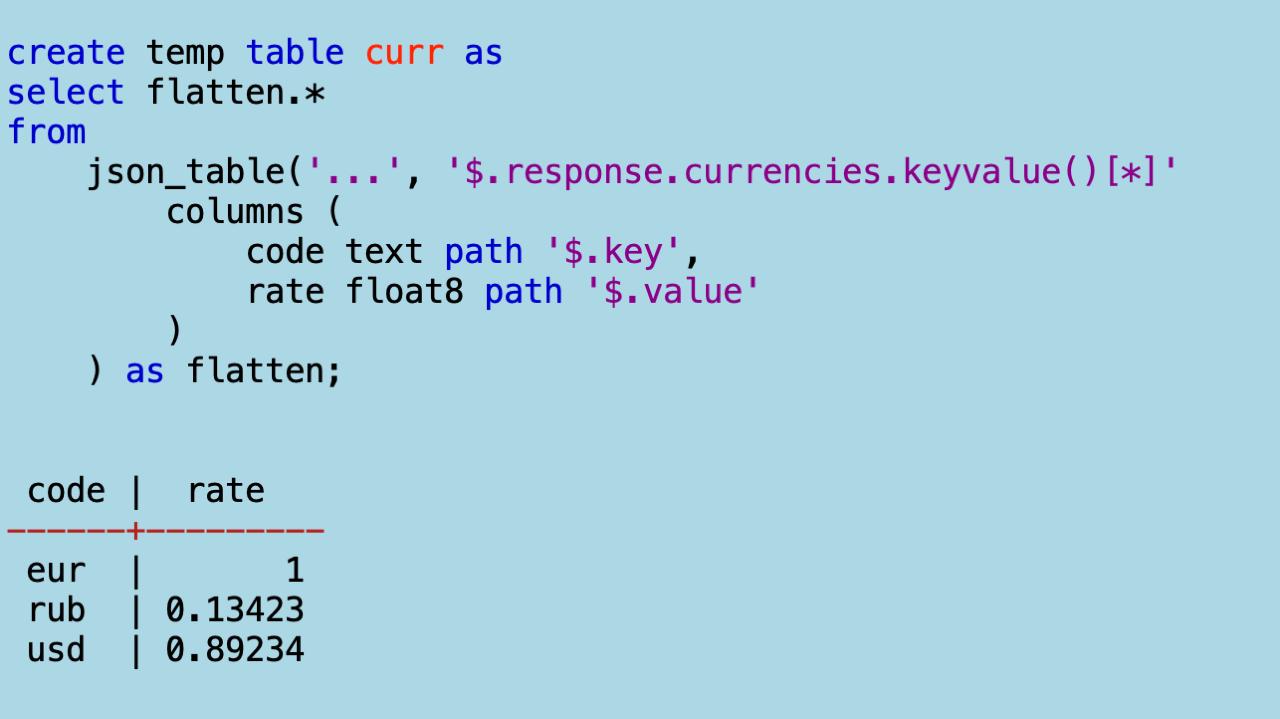
Потом присоединяю слева к юзерам курсы валют по их названиям. Это значит, каждая позиция получит коэфициент ее валюты:
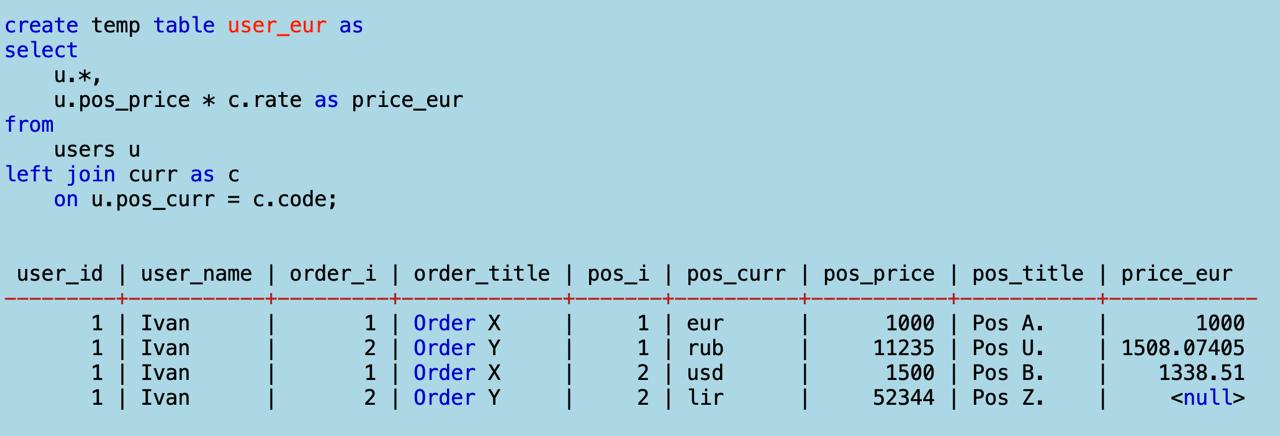
И последний шаг: считаю сумму
price_eurс группировкой по пользователю и заказу.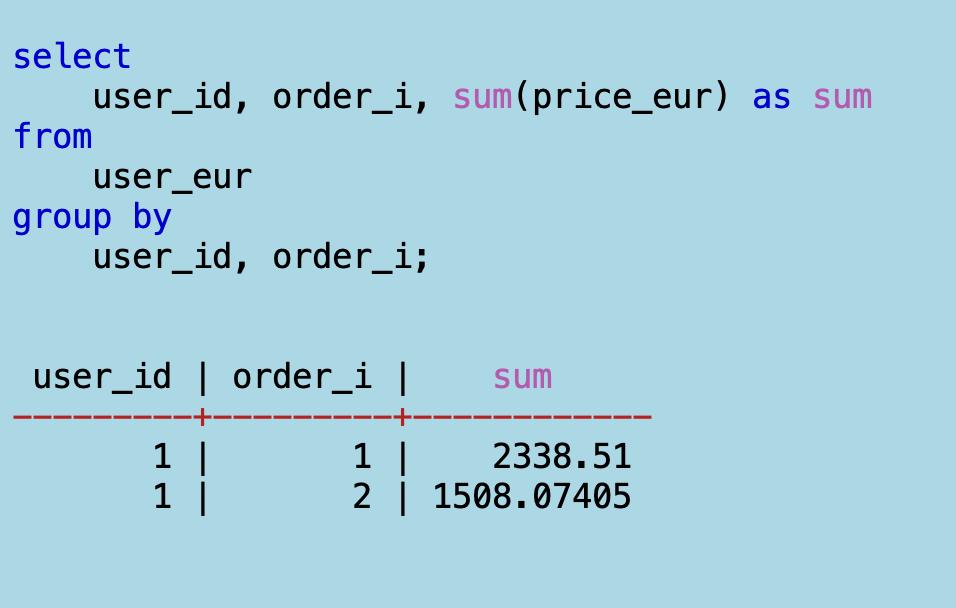
Готово. Самое важное: все декларативно и без циклов, без присваиваний и аккумуляции списков. Среда, что выполняет этот код, написана на чистом Си и многократно протестирована. Что еще нужно?
Все это можно уместить в один запрос, но я специально расписал по шагам.
Обратите внимание, что в списке валют специально нет одной. Это частая история с микросервисами, когда у них неполные данные. В результате запрос не упадет с NPE, как упал бы ваш Питон или Джава. Просто результат будет NULL, и на посчете суммы это никак не скажется.
Предлагаю вам написать то же самое на своем языке и посмотреть, что получится. Только учтите, что вложенность может быть еще глубже, а данных больше.
-
Покупка нот

Часто ищу маме ноты. И порой думаю: хватит шариться по ВК-помойкам, куплю за деньги как белый человек. Открывается форма заказа. Смотрю на нее минуту и опять иду на помойку. С такой формой я ничего не куплю. Интересно, нашелся ли отважный, кто прошел эту форму и купил? Сомневаюсь.
-
Онлайн-книги по программированию
Вчера в одном чатике набросили сайт, и он произвел на меня впечатление. Не совсем в хорошем ключе, но все-таки. Вот он:
Онлайн-книги по программированию
На сайте собраны учебники по разным языкам программирования. На главной странице примерно 60 языков, в каждом от 20 до 50 уроков. В числе прочего есть Кложа, Хаскель, F# и прочая экзотика.
Сайт интересен следующим: на мой взгляд, он полностью сделан на AI-утилитах. Думаю так, потому что:
-
сайт максимально обезличен. Никаких контактов, имен, адресов, только почта. В блоге не упоминаются авторы уроков; есть только абстрактные “мы”: мы обновили сайт, мы добавили уроки и прочее.
-
Все уроки написаны в одинаковом нейтральном стиле. Написать столько уроков одному человеку невозможно, а если бы это была группа авторов, стиль бы различался.
-
Уроки максимально поверхностны. Дается самая базовая информация, например как вызывать функцию. Нет пояснений, когда эта функция полезна, а когда вредна, нет случаев из практики.
-
На сайте нет регистрации и покупки уроков, нет прогресса обучения, как принято в онлайн-школах. Все открыто, сайт зарабатывает на мобильной рекламе.
Ради интереса я походил по сайту, почитал уроки по языкам, которые хорошо знаю. Очень похоже на правду, но местами есть неточности. Например, в одном уроке по Кложе написано, что поток создается функцией
(Thread.). Все бы хорошо, но такой функции нет: эта форма — инициация классаThread, краткий вариант записи(new Thread ...). Ну и местами похожие огрехи.При этом я нисколько не умаляю заслуг создателя сайта. Из метаданных домена видно, что это некий Дмитрий из Казахстана. Полагаю, каждый день он генерит урок за уроком и выкладывает на сайт, а заодно занимается продвижением. Структуру уроков, скорее всего, подглядывает у Хекслета или в других онлайн-школах.
Как относиться к подобным “учебникам”, я для себя еще не решил. Возможно, кому-то они будут полезны в роли конспектов: все в одном месте и максимально кратко. Но как всегда, напрягает, что продукт нейросети не маркируется. Авторство приписано неким “мы”, которые не несут ответственности. Если нейросеть проглючит, например выдумает функцию, которой нет, разгребать придется вам.
Тем, кому не нужны конспекты, все равно советую сходить на сайт: посмотреть как выглядит нейро-контент. Так сказать, подучить свою сеть для выявления таких случаев. Ну и Дмитрию из Казахстана капнет денежка за рекламу.
-
-
Выпадашки в Телеграме
А вот прикол с выпадашками в мобильном Телеграме. Если открыть диалог в режиме просмотра, то он будет в выпадающем окне. Точнее, их будет два: диалог и контекстное меню. Если долбить кнопку Block User, то Телеграм выкинет бесконечное число попапов с затемняющим слоем. При этом диалог и затеняшка будут ПОД выпадашкой с диалогом.
Когда вы закроете диалог, у вас будет сотня модальных попапов и абсолютно черный экран. Каждый затеняет то, что под ним на 5 процентов, и они суммируются.
Лет 7 назад я делал мобильное приложение на гремучей смеси технологий: Кложа, React.Native и Objective-C для доступа к нативным штучкам. В том числе я делал интерфейс. И быстро понял: если лепить на каждый чих выпадашку, рано или поздно проиграешь. Легко сделать так, что человек ушел на другой экран, а выпадашка осталась. Либо ты не закрыл ее, и чел наспамил их триста штук.
А когда выпадашка появляется из выпадашки или диалог из диалога, то это прямой билет в ад. Исключений не бывает. Поэтому не делай выпадашки там, где можно обойтись без них. Искренне желаю, чтобы и остальные разработчики поняли это скорее.
-
Ненависть к SQL
Нынче такая мода — ненавидеть SQL. Проходя мимо, нужно обязательно поддать его ногой: и синтаксис уродлив, и плохо ложится на объекты, и джоины всякие… Под каждой статьей народ стоит в очереди, чтобы накласть комментарий: да, плохой. Да, фу-фу.
Я считаю, что SQL замечателен, но сначала расскажу анекдот.
Приезжает Тарантино на фестиваль. Журналист берет у него интервью и троллит: Квентин, вы замечательный режиссер, но вы так и не сняли фильма лучше “Криминального чтива”. Тарантино думает и отвечает: а кто снял?
Вот так и с SQL — кто снял? У нас есть что-то лучше? Я лично не уверен.
Напротив, я все больше убеждаюсь, что SQL удобен и гибок. Этим объясняется то, что он дожил до наших дней. Помните, в начале десятых годов каждый клоун кричал в Твиттере, что пришло время noSQL? Каждый день была статья “как я переехал на Монгу”. Кончилось тем, что Postgres сделал jsonb и съел Монгу с потрохами. А у тех, кто на нее переехал, начались другие проблемы, потому что чудес не бывает.
Когда говорят про SQL, забывают, что он не зависит от языка, на котором пишут код. Ему не важно, что у вас — Питон, Джава или пы-хы-пе. Это по-настоящему классно. SQL дает универсальный доступ к данным из любой технологии. Им можно пользоваться без программного окружения, например в psql или PgAdmin.
Помните аббревиатуру LAMP: Linux, Apache, Mysql, PHP? Вот что по-настоящему важно: SQL — это часть стека. Сегодня буквы поменялись, но принцип остался: это операционка, сервер, данные и язык, который ими управляет.
Каждый элемент стека — как слой жидкости в лава-лампе. Можно перемешать слои, то есть внести хаос: взять базу, которая встраивается в язык; сделать проект на no-code-решениях, тем самым выкинув условный PHP. Такие случаи есть, и каждый из них обсуждают на айтишных сайтах. Но в долгосрочной перспективе слои лава-лампы приходят в норму. Потому что вещи должны быть простыми, но не проще определенного порога.
Мало кто думает о том, что noSQL-решения дороги и трудны в развертке. Я уже писал, что Postgres и Mariadb работают на каждом утюге. Первый уже гоняют в браузере. А базы вроде Datomic или XTDB напоминают черепах на трех китах. Их работа сводится к оркестрации других хранилищ. Например, Datomic использует Посгрес или Марию для хранения индексов, плюс ему нужен мемкеш-кластер, плюс в облаке он ходит в S3. Базе XDTB нужен кластер Кафки. Вы точно готовы в этом разбираться? Осилите развернуть продакшен-версию локально?
Разумеется, у этих баз есть dev-режим для локального запуска. Но в случае с Postgres я знаю, что локальная база идентична той, что в проде. В обоих случаях крутится один и тот же код. Я могу воспроизвести любую ситуацию локально. В случае с Датомиком это лишь имитация.
Сюда же относится OpenSearch. Формально он open source, бери и пользуйся. На практике его развертка настолько сложна — нужно минимум три узла в кубере, — что все пользуются облачной версией поставщиков. А это дорого.
Апишку OpenSearch вы видели? Казалось бы, HTTP и REST, шли джейсоны и живи спокойно. Я с ней работал и скажу — неудобно. Синтаксис жуткий, нужно учить с нуля. Тройная вложенность: мапа внутри мапы внутри мапы. Нельзя выбрать больше 10 тысяч записей за раз (Посгрес выплюнет миллион за долю секунды). Пагинация ужасная и состоит их двух апишек, а не одной. Наконец, я лично спровоцировал исключение, когда переполняется
ByteArrayOutputStream, и запрос падает с ошибкой 500. Когда в последний раз вы видели переполнение буфера в Посгресе?Когда я стал работать в крупной фирме, поразился тому, что почти каждый знает SQL. Менеджеров и аналитиков этому учат на курсах. Человек, который путает Java и JavaScript, может написать сложный запрос на два экрана. Ощущение, что даже уборщица напишет выборку часов с нарастающим итогом. Было такое, что человек приносил запрос и просил поставить на ежедневную выгрузку. А это значит, он снимал с меня тяжкий груз — сопоставлять бизнес-требования с данными. Без него я писал бы запрос неделю, потому что не понимаю бизнес-жаргон. А он сделал это за меня, и осталось только завернуть запрос в техническую шкурку.
В крупных фирмах SQL становится языком коммуникации, посредником между бизнесом и технарями. А что с условным Датомиком и Даталогом? Все это прибито гвоздями к Кложе; с ним у людей нет доступа к данным. К вам без конца будут приходить и просить: выгрузи то, выгрузи это, напиши такой запрос, сякой запрос. Вам это нужно?
Некоторые сотрудники знают Питон и решают задачи скриптами с запросами к базе. Нейросеть пишет болванку, а они ее адаптируют. Что с Датомиком или XTDB? У них до сих пор нет клиента для Питона. Когда-то давно у Датомика был REST-интерфейс, но его упразднили. А XTDB вообще предоставляет Wire Protocol, притворяясь, что на том конце Postgres. Играет по правилам конкурента, лишь бы отхватить пользователей.
Все говорит об одном: дай людям SQL, и они сами все сделают.
Базы, которые встраиваются в язык, предлагают удобный доступ к данным. Он красивее и изящней, чем голый SQL — с этим я не спорю. Но повторю: данные нужны всем, а не только кложуристам. Мне приходилось писать запросы в веб-консоли Датомика, и уверяю вас: магия пропадает. Одно дело писать их в редакторе с балансировкой скобок, подсветкой синтаксиса и хоткеями. А когда перед тобой унылый text area — все, завяли помидоры. Написание запроса становится рутиной: не закрыл скобку, опечатался в ключевом слове. Набранные запросы копируешь в файлик, чтобы сохранились.
Когда пишешь SQL днями напролет, воспринимаешь его как язык. На нем удобно выражать мысли. Например, я не вижу причины писать
{select [foo bar baz]}вместоselect foo bar baz— то есть ставить скобочки и структурировать данные. Пусть этим занимаются построители SQL. Недавно сотрудники Гугла выкатили пейпер, где на 20 страницах объясняли необходимость писатьfrom users select idвместоselect id from users. Ну ок, напишите препроцессор для клиента к БД. А разговоров-то было…Наша работа всегда будет сложной — иначе бы айтишники не получали как депутаты. Сложность следует из разнообразия случаев, с которыми сталкиваешься. Решения вроде Датомика и прочих noSQL-баз хороши в моменте. Они подкупают красотой в тех местах, где SQL не вышел лицом. Если хотите, это показ мод или акаунты моделей в Инстаграме. Но когда ты женился на модели, выясняется, что из-за длинных ногтей она не может почистить картошку или пришить пуговицу.
SQL — это не про красоту, а про getting shit done. Понимание этого приходит на долгой дистанции.
-
Синглтон (2)
Вдогонку о синглтоне — пара мелочей, о которых забыл вчера. Рассмотрим простую функцию:
(func get-user-by-id [db id] (first (jdbc/execute! db "where id = ?" id)))Она принимает объект базы и работает с ним. Все прозрачно и логично. А вот варианты этой же функции, которые рассчитывают на глобальное подключение к базе:
(func get-user-by-id [id] (let [db some.namespace/*DB*] (first (jdbc/execute! db "..." id))))или
(func get-user-by-id [id] (let [db (db/get-or-create ...)] (first (jdbc/execute! db "..." id))))Оба варианта плохи по многим критериям. Если глобальный объект куда-то переедет, придется менять все функции. Нарушается связность системы — функции лезут в кишки, куда им лезть не следует. Объект может быть не инициирован — вполне возможная ситуация, если он включается по запросу. Наконец, функцию db/get-or-create нужно проверить на потокобезопасность, чтобы несколько потоков не наплодили более одного объекта.
А теперь вернемся к первому варианту:
(func get-user-by-id [db id] (first (jdbc/execute! db "..." id)))Очевидно, что когда функция принимает объект, все претензии снимаются. Ей все равно, синглтон это или нет, это не играет роли. Даже если в системе десять подключений к разным базам, на функции это не скажется. Наоборот, сплошная польза: я могу прочитать пользователя из мастера, из реплики, из исторической базы. В некоторых случаях это важно.
Если отбросить красивые слова, синглтон — это глобальное состояние, подпертое костылями. А состояния лучше избегать — сегодня это ясно как день, причем независимо от языка.
Пока писал, вспомнил, как словил неприятное поведение из-за синглтона. В одном проекте авторы сделали глобальный пул соединений с базой. Синглтон, все по статьям в интернете. А потом я стал писать тесты и обнаружил: если тест закроет пул, то все, капут — система становится нерабочей. При попытке обратиться к пулу получишь исключение, что он закрыт. А пересоздать нельзя, потому что пул глобален. Нога прострелена, и нужно перезапускать приложение. Я это починил, но шлю авторам лучиков знаний, чтобы так не делать.
Повторюсь, сегодня нет причин использовать синглтон. Ни под каким видом. Знать, что это такое, нужно, но только за тем, чтобы не напороться на описанные грабли.
-
Синглтон (1)
Казалось бы, сложно придумать паттерн хуже, чем синглтон. Но нет: на его примере объясняют, как хорошо иметь единственное подключение к базе данных. Специально проверил в Википедии и образовательных статьях.
Делать подключение синглтоном — это примерно как подвесить больного человека вверх ногами и привязать к шее кирпич, думая, что ему станет легче. То есть двигаться в худшую сторону по градиенту — вектору, когда величина нарастает максимально быстро.
Подключение к базе — и вообще любое сетевое подключение — никогда не должно быть синглтоном, и вот почему.
Если подключение не потокобезопасно, то обращение к нему из разных потоков вызовет “рассинхрон”. Например, поток А отправил сообщение, а поток В прочел ответ. В лучшем случае конечный автомат выкинет ошибку, а в худшем — получим неопределенное поведение.
Если же подключение потокобезопасно, то каждый запрос будет блокировать другие потоки: они будут ждать, пока соединение отпустит. В результате 4, 8 или 16 потоков будут работать как один.
Конечно, если у нас скрипт на PHP для заказа пиццы, можно писать в таком ключе: объявить подключение на старте и ссылаться глобально. Для чего-то посложнее так лучше не делать.
Вместо подключения должен быть пул соединений. Каждый раз из него занимают подключение, работают с ним и кладут обратно. Чтобы гарантировать возврат, процесс займа оборачивают в макрос или контекстный менеджер (with в Питоне, try with resource в Джаве).
Но и пул соединений не должен быть синглтоном! Должна быть система компонентов с зависимостями. Пул — один из компонентов, а другие компоненты зависят от него. Специальный код строит граф зависимостей, включает компоненты в нужном порядке и передает им рабочие зависимости.
Другими словами, функция для работы с базой и очередью задач не должна порождать эти компоненты. Она либо принимает их, либо является компонентом, который инициализируется с ними.
Даже если какая-то сущность глобальна по причине легаси, не следуйте плохим практикам. Передавайте ее обычным аргументом. Быть может, ее получится убрать из глобального скоупа, и не придется рефакторить код.
Это в точности мой случай. У нас пул объектов является глобальным — и все равно я ссылаюсь на него лишь однажды, а затем пробрасываю параметром. Верю, что этот промах получится исправить.
Синглтон — это прекрасно для собеса, но никогда не берите его в проект. Включайте, но не пользуйтесь. Пользуйтесь, но не включайте. Не считая этой мелочи, с ним все хорошо.
Writing on programming, education, books and negotiations.