-
Пустая истина (3)
После второго раунда обсуждений стало ясно, почему every от пустого множества дает истину. Читатель Миша Левченко внятное объяснение, которое понятно мне как программисту. Оно не опирается на кванторы и логику. И хотя вывод все равно не нравится, приведу объяснение здесь.
Дело в том, что операции над списками нужно рассматривать как свертку. Есть такая функция
reduce(она жеfold), которая принимает функцию двух аргументов и коллекцию. Результат функции такой:fn(fn(fn(fn(item0, item1), item2), item3), item4)...Например, для сложения чисел 1, 2, 3, 4 получим форму:
(((1 + 2) + 3) + 4)Reduceможет накапливать в том числе другую коллекцию: словарь или список. Это вообще очень мощная функция. Про себя я называю ее царицей функций, потому что через reduce можно выразить что угодно.Reduce выше прекрасно работает, если элементов два и более. Когда их один или ноль, начинаются граничные случаи. Одно из решений в том, что
reduceможет принимать т.к.init— первичный элемент, который подставляется в начало цепочки. Чаще всего он выступает коллекцией-аккумулятором, но может быть и простым скаляром.Если передать
init, форма будет такой:fn(fn(fn(init, item0), item1), item2)...Другими словами, он гарантирует, что элементов больше нуля. Если основной список пустой, просто вернем init.
Так вот, в терминах свертки функция
ALL(которую я раньше называлevery?) выглядит так:(func ALL [fn-pred items] (reduce (fn [x y] (and x (fn-pred y))) true items))Демо:
(ALL int? [1 2 3]) true (ALL int? [1 nil 3]) false (ALL int? []) trueА вот функция
ANY(что хотя бы один элемент вернул истину для предиката):(func ANY [fn-pred items] (reduce (fn [x y] (or x (fn-pred y))) false items))Демо:
(ANY int? [1 nil 3]) true (ANY int? [nil nil nil]) false (ANY int? []) falseАналогично работают функции суммирования: это
reduce, где начальные элементы равны 0 и 1. Поэтому(+)дает 0, а(*)— 1.Как видим, все это можно объяснить без греческих букв и терминов. А пустая истина, о которой я писал ранее, считается истиной только потому, что таков начальный элемент свертки.
Другое дело, что такой подход все равно мне не нравится. В каждом их них скрыт начальный элемент: для
ALL—true, дляANY—false, единица для умножения и так далее. Считается очевидным, что он должен быть именно таким. А мне это не очевидно. Я спотыкаюсь, когда вижу, что произведение элементов пустого списка равно единице. Я бы предпочел неопределённость — то есть null.Я в курсе про нейтральный элемент: ноль для сложения, единица для умножения. Но на пустых списках это как-то не очень. Душа не принимает, если совсем честно.
В самом деле, в математике оператор умножения — бинарный, ему нужно два операнда. Нельзя записать что-то вроде
5 * = 5— тут не хватает операнда справа. С какой стати мы обходим математические правила — не ясно.Я часто использую
reduceи вывел правило: всегда указываю начальный элемент. Например, чтобы сложить список чисел, я пишу так:(reduce + 0 numbers)вместо
(apply + numbers)Потому что во втором случае не очевидно, во что накапливается результат.
Словом, пока что меня отпустило на тему пустой истины. Все оказалось просто: это свертка, где начальный элемент — истина. Крайне неочевидно, на мой взгляд. Чтобы не отстрелить ногу, либо проверяйте коллекцию на пустоту, либо пишите явный
reduce, где начальный элемент — ложь, если того требует контекст. -
Пустая истина (2)
После прошлой заметки мне стали приходить, что называется, письма читателей. Их можно разделить на два вида.
Первый — ты не шаришь в логике, сейчас я все объясню. Гляди… (далее километр греческих букв, термины “антецедент”, “консеквент” и другие). Вывалив все это, человек считает, что открыл мне глаза. Я ничего из этого не понимаю, поэтому прошу — не утруждайтесь подобными доказательствами.
Второй тип писем — в языке X предикат every работает так же: для пустого множества вернет истину независимо от предиката. Да, согласен. Еще пять лет назад выполнил в Постгресе такой запрос:
select 1 = ALL (array[]::int[]); t, получил истину и опечалился. Если же поменять
ALLнаANY, получим противоположный результат:select 1 = ANY (array[]::int[]); fЗдесь мы уподобляемся Джаваскриптерам: подаем нелепый ввод, получаем нелепый вывод. При этом силимся подвести его под какую-то базу: антецеденты-консеквенты, кванторы и прочее.
А дело в другом: аппарат логики не учитывает неопределенность. Это утопичная модель, где есть только истина и ложь — третьего не дано. В тех местах, где модель не ложится на реальность, начинаются подтасовки: истину раз — и обозвали “пустой”. То есть как бы истина, но не совсем.
Меня это страшно бесит, прям так, что не передать словами. Если результат отличен от истины и лжи, заведи под него тип. Переработай модель логики, в конце концов. Признай, что старая модель ограничена и не подходит под прикладные задачи. И уж чего точно я не пойму, так это того, почему в языках программирования мы опираемся на логику бог знает какой давности. Нужно делать так, чтобы удобно здесь и сейчас, а не как принято в учебнике логики.
Правильный ответ в том, что в функции every пустое множество — это неопределенность, краевой случай. То же самое, что получить первый элемент массива, когда он пуст. В зависимости от языка мы получим null или исключение, но точно не число 42 с пометкой “пустое” — это нонсенс.
Обратимся к более достойной науке, чем логика — математике. Рассмотрим функцию
y = 1/x(см. график ниже). Прелесть этой функции в том, что в точке 0 ее значение не определено. Если точнее, приx=0результат будет бесконечностью, причем даже нельзя сказать, какой именно — положительной или отрицательной. В зависимости от того, с какой стороны приближаться к нулю — правой или левой — функция будет уходить в плюс- и минус-бесконечность.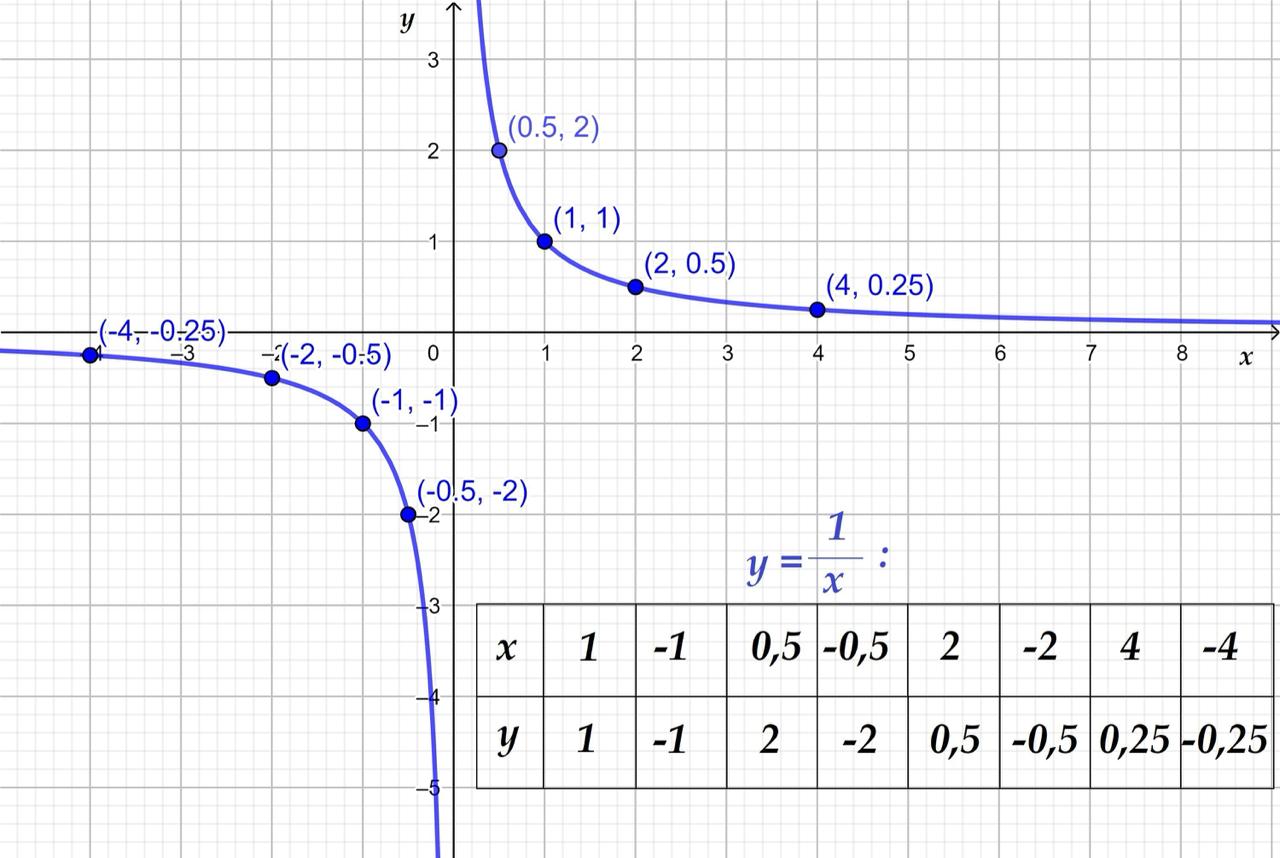
Область определения этой функции записывается так:
(-inf, 0);(0, +inf). В нуле функция не определена — и при этом никто не умер. Бывают функции и с большим количеством точек и даже целых областей, где они не определены. И ничего — нас это устраивает, с функцией можно работать.(В скобках отмечу, стандарт чисел с плавающей запятой предусматривает комбинации битов, которые трактуются как обычная бесконечность, а также плюс- и минус-версии. То же самое касается нуля: может быть ноль, минус ноль и плюс ноль. Это помогает при сходимости рядов, когда мы пришли к нулю и хотим знать откуда — справа или слева. По крайней мере в Фортране этими штуками пользовались).
Другой пример из математики — решение квадратного уравнения вида
ax^2 + bx + c = 0. У него может быть либо два корня, либо один, либо никаких. Во втором случае еще можно слукавить: сказать, что один корень — это два одинаковых. Ладно, но с третьим вариантом это не прокатит. Нельзя вернуть какое-то левое число и сказать, что это пустой корень. Они не определены.Пример из географии: чтобы попасть на северный полюс, нужно идти на сервер. Каким же будет северное направление на Северном полюсе? Ответ — никаким, оно не определено.
То же самое с предикатами: когда нас просят сказать, что все камни белые, но камней нет, это неопределенность. Потому что если сказать да, оказывается, что камни в том числе черные, прозрачные, резиновые — и все это одновременно. Этого не было, если бы every возвращал NULL — я имею в виду не в коде, а на уровне логики.
Уж не говорю, что пустая истина совершенно неприемлема на бытовом уровне. Это либо троллинг, либо саботаж, либо неразбериха.
Когда я читаю в документации: if the stream is empty then true is returned and the predicate is not evaluated — мне немного плохеет. Выходит так, что функция возвращает один и тот же результат при РАЗНЫХ случаях. А значит, ответственность перекладывается на тебя — будь добр сам проверяй, пустое множество или не пустое.
Это просто плохой API — что, в общем-то, не редкость. Надо это признать и больше так не делать. А вот оправдываться логикой и чепухой а-ля “антецедент-квантор” — это отстой.
Под конец напомню вам о Булгакове. Если свежесть отлична от первой, это уже не свежесть. Если перед истиной стоит какой-то тег — пустая, неполная, вторичная — то это не истина. Вот и все, что нужно запомнить. И это — истина.
-
Пустая истина (1)
Расскажу, как однажды погорел на забавной вещи под названием “пустая истина”. Это было лет пять назад, когда я ничего про это не знал.
Значит, смотрите: когда мускулистые греки работали над логикой, они ввели в том числе предикаты. Например, белый? – это предикат. Если применить его к любому предмету, получим истину или ложь.
Также греки придумали пакетную версию предикатов, батч, так сказать. Это супер-предикаты “каждый из”, “любой из”, “ни один из”. Все они принимают другой предикат и множество объектов. Далее они редьюсят множество логических результатов в один (простите за функциональные термины).
Если на столе три белых камня, то выражение “все камни – белые” вернет истину. Если один – тоже истину. Если сто белых и один черный – ложь. А что случится, если камней нет? Греки почесали бороды и сказали – будет тоже истина, только назовем ее пустой.
В результате: если на столе нет камней, выражение “все камни – белые” будет истинно. Таким же истинным будет выражение “все камни – черные”, в крапинку и полоску. Все камни обладают какими угодно свойствами одновременно. Одна беда – их нет.
На мой взгляд, греки подложили нам свинью. Истина, как известно, одна – не бывает двух разных истин. Когда вводят истину с какой-то характеристикой, получается черт знает что. Вроде бы это истина, но какая-то другая, что требует особого обращения с ней.
Напоминает диалог Булгакова об осетрине второй свежести: голубчик, это вздор! Свежесть бывает только одна – первая, она же последняя. Если осетрина второй свежести, значит, она тухлая.
Знал же человек!
Интересно, что греческая вторая свежесть, тьфу, пустая истина идеально ложится на быдлокод! Это при том, что программировать греки не умели.
Предположим, нужно написать функцию, которая принимает предикат и список объектов. Функция возвращает истину, если предикат справедлив для каждого элемента. Вот как выглядит самая тупая реализация:
func is_every(fn_pred, items): for item in items: if not fn_pred(item): return false; return true;Все просто: бежим по списку, как только предикат вернул ложь, мы тоже возвращаем ложь. Если прошли по всем элементам, значит, лжи ни разу не было, и мы возвращаем истину. Если список пуст, мы благополучно пропустим цикл и перейдем к выражению с истиной.
Как это связано с моей работой? Несколько лет назад в Exoscale я делал систему прав доступа, аналог IAM в Амазоне. Из базы читались разрешения, и нужно было проверить, что каждое из них совпадает с политикой ресурса. Для этого я вызывал кложурную функцию
every?:(every? policy-match? permissions)Оказалось, Рич Хикки знал эти штучки, и для пустого множества
every?возвращает истину. Это легко проверить:(every? int? [1 2 3]) true (every? int? [1 "a" 3]) false (every? int? []) trueВышло так, что если у пользователя вообще не было прав, то список был пуст и every? возвращала истину. В результате пользователь, который не имел доступа ни к чему, имел доступ ко всему – из-за моих бедных знаний в этой области.
С тех пор у меня отпечаталось в подкорке, что перед
every?должна быть проверка на пустоту. Пустая истина может трактоваться как угодно, но мне нужна точность.Второе – я не согласен с греками. Видимо, они еще не знали про NULL и неопределенность, плохо понимали троичную логику. Увы, наш мир сложнее, чем
trueиfalse, есть нуллы и другие досадные вещи. Но нужно жить с ними, а не сводить к каким-то сомнительным истинам.Кстати, пустая истина позволяет сказать жене: все мои любовницы – брюнетки. Если у вас нет любовниц, это тоже будет истиной. Разве что придется потратить время на объяснение, но ничего. Истина дороже.
-
Подорожание Google Workspace
Гугл пишет, что поднимет цену на подписку Google Workspace. Это для тех, кто привязял домен к Гуглу и тем самым создал мини-организацию из одного человека. Правда, со временем я открыл учетки для других членов семьи, включая маму, потому что никто не помнит пароль, да и пройдет авторизацию Гугла сегодня не каждый. Так что сейчас в моей организации пять человек.
Интересна причина роста цен — это внедрение AI и некие фичи:
The updated subscription pricing reflects the significant added AI value, as well as the many new features we have introduced and are launching to Google Workspace editions
В тот момент я подумал: Гугл напоминает российский Газпром. Потому что все развлечения Газпрома оплачивает потребитель — покупку футбольных клубов, километры списанных труб, бонусы менеждеров. За все это платит простолюдин, неважно какие успехи рапортует Газпром по телевизору.
То же самое с Гуглом — казалось бы, он и так гребет деньги лопатой за рекламу; собирает и продает личные данные; везде где можно предлагает платный Gemini. И все равно этого мало, поэтому пусть заплатит потребитель.
Тем чудикам, которые топят за ИИ, советую подумать: на ровном месте мы получили прибавку к цене только потому, что компания внедряет ИИ. Такая вот новая нормальность.
-
Кнопки в Гитхабе
У Гитхаба странный интерфейс — посмотрите на картинки ниже.
Первая картинка: я хочу смержить пул-реквест. Нажимаю кнопку Squash and merge, ожидаю, что произойдет то, что написано на кнопке — логично же?

Но мерджа не происходит. Вместо этого появляется форма с двумя полями, а кнопка Confirm squash and merge проваливается ниже. Как у Чуковского: “и подушка как лягушка ускакала от меня”. Нужно мотать вниз и жать ее еще раз.

Вот эти убегающие кнопки — бич Гитхаба. Вроде нажал, а всплыло что-то другое. Кстати, после мерджа обычно я удаляю ветку, и кнопка Delete branch оказывается на 10 сантиметров ВЫШЕ. То есть сначала нажал кнопку на высоте X, потом X+10 см, потом снова X-10 см. Дизайнеру Гитхаба это норм — не жмет, не чешется.
Вы, конечно, скажете: надо запросить описание коммита. Ну вот ниже на картинке есть форма комментариев — она статична и не появляется по клику. Можно сделать такой же статичный инбокс для мерджа. Еще лучше — сделать так, чтобы кнопка не уплывала вниз, а оставалась на месте, при этом поле повляется ПОД ней. Чаще всего я ничего не пишу, поэтому просто нажал бы кнопку еще раз.
Решений может быть много, но то, что сейчас — крайне неудачно.
-
Игрушечный парсер
Месяц назад я помогал одной студентке с домашней работой по Кложе. Да, я тоже удивился: есть вуз, где на первом курсе пишут парсеры на этом языке. Сомневаюсь, что у студентов что-то останется в голове: после интенсива Кложи их перебросили на Пролог, и в чем замысел такого обучения — загадка.
Тем не менее была домашка, которую нужно было сделать. Я помогал с двумя заданиями: написать комбинаторные парсеры для разбора постфиксной и инфиксной нотаций. Я всегда любил парсеры, и хоть не силен в них, не прочь что-нибудь распарсить своими силами.
Так что если вы студент(ка) и пишете парсеры, загляните в репозиторий.
Там простой модуль с комментариями и базовыми парсерами. Также есть два модуля demo1 и demo2. В одном пример с префиксной нотацией, во втором — с инфиксной. Второй пример интересен тем, что там используется рекурсивный парсер, и поэтому нужны конструкции declare и var.
Эти парсеры в высшей степени просты, и по-хорошему им нужна доработка. Скажем, в случае ошибки возвращать не nil, а сообщение о том, что пошло не так. Это сделано нарочно, чтобы акцент остался на главном: парсинге и комбинации парсеров.
Если будут вопросы, пишите.
-
Поддежка и Джира
Как-то раз я общался с поддержкой крупного сервиса. У них что-то поплыло, консоль залита кровью, все ответы — 500. В углу виджет поддержки, и я пишу: ребята, у вас все плохо. Хром такой-то, вот скриншот.
Сотрудник отвечает: ах, спасибо, что известили, сейчас поправим. Скажите, какой у вас хром? Я говорю, вот же написал: версия 100500.42. Он такой — отлично, считайте уже сделали.
Через минуту: еще одна деталь, какая у вас операционная система? Мак, говорю. Отлично, чиним в поте лица.
Через минуту: а какая версия системы? 14 с копейками. Спасибо, уже патчим прод.
Через минуту: какая у вас часовая зона? Тут я слегка разозлился и ответил, что хватит приседать на уши. На что сотрудник ответил, что ему нужно заполнить тикет в Джире: там 20 полей, и все обязательны. Уже заполнили 6, осталось 14. Без заполнения он не сможет создать заявку, и она не пойдет программистам. И вообще ничего не будет.
Конечно, ничего я заполнять не стал и закрыл окно. Все это рассказал затем, чтобы вы знали, как иной раз работает поддержка. Нет ответа на вопрос — нечего ввести в поле — нет заявки — нет проблемы.
Вот и отлично!
-
Неэффективный ввод и вывод
Мое частое замечание к коду — неэффективный ввод-вывод. Примеры:
-
чтобы пройтись по строкам файла, человек читает его в память целиком и разбивает символами
\r\n. Рано или поздно прилетает CSV на 5 гигабайт, и машине становится плохо. -
То же самое с джейсоном: есть стрим, но разработчик читает его в гигантскую строку, а потом парсит ее.
-
Нужно записать в файл 100 тысяч строк? Человек джойнит их разделителем, получает километровую строку и пишет в файл.
-
Различные кодирования — base64, gzip и другие — делаются также: данные читаются в память целиком, из них получается результат тоже в памяти.
-
При загрузке файла в S3 он целиком читается в байтовый массив, затем массив передается в запрос.
При этом разработчик обмазывает код вызовами gc в надежде, что это поможет.
Сколько подобных ошибок я исправил — не перечесть. В числе прочего был сервис, который падал от недостатка памяти, хотя ее было выделено запредельное количество. Оказалось, разработчик делал все из списка выше. Он получал огромные файлы, читал их в память, парсил, кодировал в JSON и gzip, используя строки и массивы. Когда код падал от OOM, он поднимал лимиты в облаке.
Это лишний раз подтверждает: сколько памяти ни дай, плохой код сожрет ее всю.
А решение простое — байтовые и символьные потоки. Ту же Джаву можно ругать за многое, но в ней очень хорошие потоки (абстрактные классы
Input-иOutputStream,ReaderиWriter). У них много наследников, каждый из которых делает свою работу. Например, буферизирующий поток, который сглаживает неравномерность сети и файлов. Потоки для сжатия, когда пишешь в него, а данные сжимаются в полете. Потоки, связанные с файлами, сокетами или устройствами. Потоки с подсчетом текущей строки и символа, потоки-пайпы (piped) для “переливания” данных между тредами — всего этого навалом.Легко найти сторонние потоки для подсчета MD5 и других хешей. Например, пишешь в условный
MD5OutputStream, и хеш считается в полете. В конце вызываешь .getHash, и готово.Часто задача решается тем, что нужно построить стек потоков и скормить ему данные. Это труднее, чем прочитать файл в память и разбить на строки. Но не придется чинить в пятницу вечером.
Уделите время потокам ввода-вывода. Это прям очень полезная вещь.
-
-
У заказчика праздник
Когда у заказчика праздник — это праздник для меня, потому что я могу поработать спокойно. Нет созвонов и трескотни в чатах. Даже если заглушено все что можно, шум настигает все равно.
Заметил, что важно само ощущение того, что тебя никто не беспокоит. Так сказать, предвкушение тихого дня. Бывает, в такой день делаешь то, что собирался неделями.
Сегодня как раз такой случай. У заказчика выходной, и я сделал то, что долго планировал. Формально никто не мешал сделать это в обычные дни, но уверенность в том, что никто не потревожит, дала прилив сил.
Честное слово, нам нужны дни, когда нет ни созвонов, ни чатов, ни почты. Дни, когда можно поработать в полном отрыве от команды и вечером написать, как много сделал.
-
Австралийское время
Несколько раз я упоминал про один австралийский стартап. При всех минусах кодовой базы у него было и преимущество: разница во времени с заказчиком. Пересечение было совсем небольшим, буквально два-три часа. День начинался с созвона, мне давали задачу, мы ее обсуждали. Потом народ из Австралии шел ужинать, и день был полностью моим. Без созвонов, чатов и обсуждений. При этом я всегда имел две активных задачи, чтобы в случае зависания одной переключиться на другую. Утром я докладывал, что сделал вчера, и все были довольны.
Много воды с тех пор утекло, но порой я скучаю по такому формату. Разница с заказчиком в час-два означает, что ты не делишь с ним головные боли и причуды: планинги, ретро, спринты, тимбилдинги, уведомления в Тимс. Иной раз хочется, чтобы ничего этого не было. Чтобы был только git pull и git push, ну и зарплата. А на тимбилдинге и без меня обойдутся.
Это так, минутка малодушия. Вздохнул и пошел дальше.
Writing on programming, education, books and negotiations.