-
Вставка со стилями (3)
В комментариях к прошлой заметке выяснилось, как сделать вставку без стилей. Для меня это настолько важно, что напишу отдельно.
Читатель @snffy дал ссылку на программу, которая делает в точности то, что нужно. Называется Pure Paste. Она прослушивает буфер обмена, и если там форматированная разметка, приводит ее к чистому тексту. Программа поддерживает всякие опции, например что делать со списками, ссылками и так далее. Можно указать программы, чей буфер игнорировать — по умолчанию это Эксель. У каждой опции есть выпадашка с примерами: как было и как будет, если ее включить.
В числе прочего программа чистит ссылки от utm-тегов, трекинговых айди, номеров сессий и остального. Поддерживаются 200 с лишним популярных сервисов и их параметров. Больше нет оправдания тем, кто кидает ссылку с миллионом тегов в адресной строке.
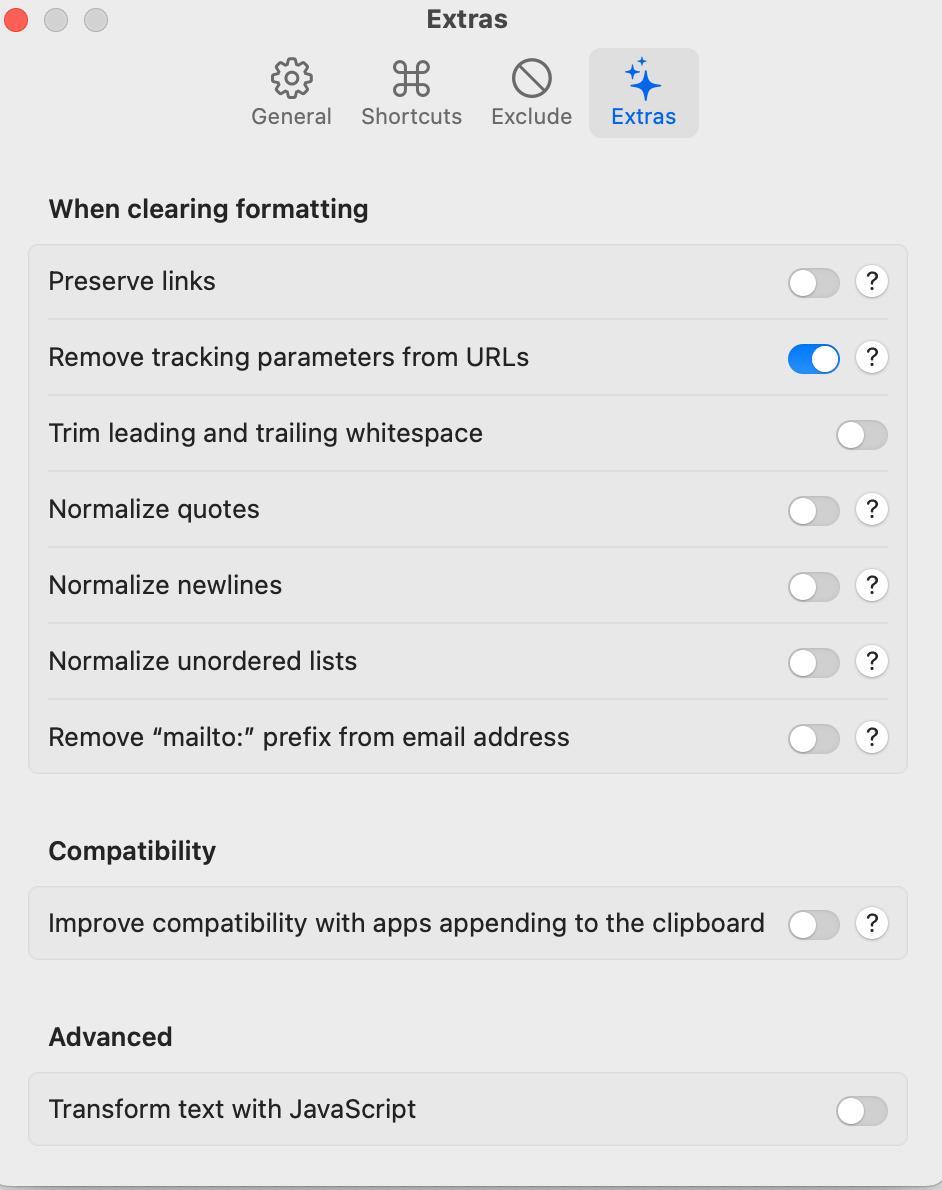
Идея проста и понятна, спрашивается — как же я сам не догадался сделать что-то похожее. Я немного умею в Swift и в принципе бы осилил.
Если вдруг у вас корпоративный Мак, где запрещен AppStore, то программу можно скачать с сайта автора — правда, не последнюю версию.
Удивительно, что на столь специфический запрос нашлась утилита, которая делает в точности то, что нужно. Видимо, на другом конце планеты у автора тоже горела задница от уродской вставки. Приятно видеть, что ты не один такой. Потому что кому ни скажи о проблеме, каждый повторяет как попугай: просто нажми Alt+Shift+Command+V.
Желаю этим советчикам жать по четыре клавиши, пока рука не отвалится от гангрены.
Интересно было пошариться по сайту автора утилиты. У него их несколько десятков — судя по всему, он поставил цель обеспечить себя разработкой. С радостью перевел ему денег, потому что программа замечательная. Другие утилиты автора не пробовал, на это нет времени.
Что ж, еще одной головной болью меньше. Еще одно “преимущество” современных приложений отключено. Вообще, вы задумывались, сколько сил уходит на борьбу с ними? Блокировщики рекламы, блокировщики кук, блокировщики социальных виджетов, блокировка обновлений, отключение уведомлений, всевозможные прокси и noDPI… борьба, борьба, и конца этому не видно. Счастье, что нет-нет да попадется софт, который поставил и забыл о проблеме — хотя бы на некоторое время.
-
Вставка со стилями (2)
Прошлая заметка навеяна вот каким случаем. Я активно переписываюсь насчет одной задачи. Приходится копировать номера сущностей. Я пишу что-то вроде “Джон, пожалуйста проверь, что у сущности 152342662 атрибут
foo.barтакой же, как и в сущности 2362342623 при условии X”. Разумеется, эти номера я копирую из логов и разных систем. Все они работают в браузере, а значит у них свои шрифты и стили.И получается: фраза “Джон, … что у сущности” выглядит нормально. Потом я вставляю первый айдишник, он зеленый и подчеркнутый. Продолжаю писать — слова “…атрибут
foo.barтакой же…” тоже зеленые и подчеркнутые. Вставляю второй айдишник — у него большой шрифт и болд. Пишу дальше — слова “при условии X” в два раза больше и вдобавок болдом.Со стороны это выглядит словно писал сумасшедший. Отправить такой текст значит быть полным уродом, заставляя других продираться сквозь кегли, подчеркивания и болды.
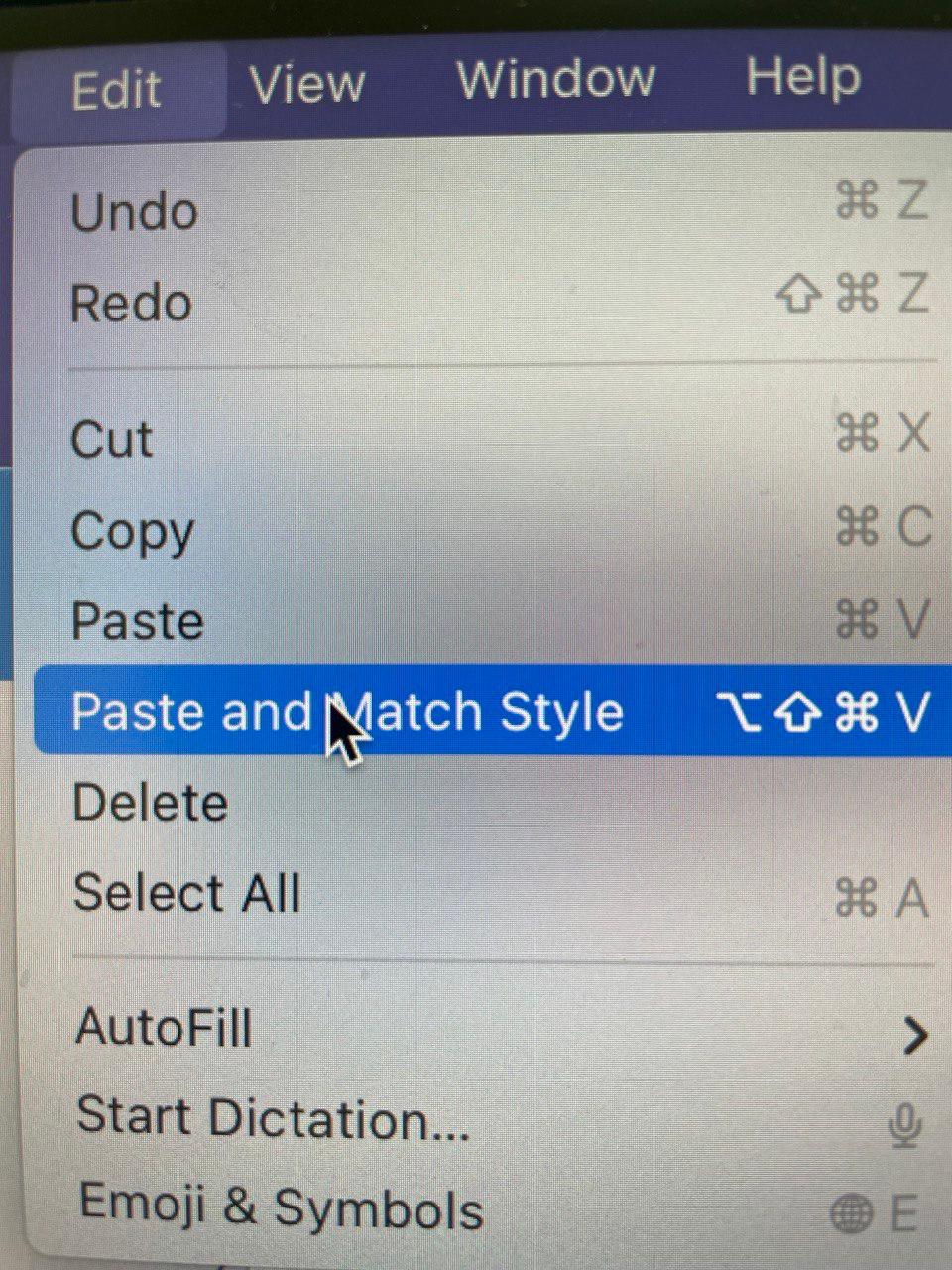
Проверил: в меню Edit есть пункт “вставить с текущим стилем”. Нужно всего-то нажать Alt + Shift + Command + V. Так вот: прямо сейчас потренируйтесь. Нажмите одной рукой V и ТРИ системных клавиши. Три, Карл. И это каждый раз, когда нужно что-то вставить.
Что было в голове у клоунов из Teams, которые это писали, я не представляю. Похоже, объяснение простое: люди ищут умысел там, где была глупость. Впрочем, как всегда.
-
Вставка со стилями (1)
Похоже, я никогда не пойму одну вещь. Вот пишешь ты текст в мессаджере или офисном документе. Вставляешь слово из другого документа или браузера. Оно вставляется с сохранением стиля, то есть с другим шрифтом, цветом, начертанием.
У меня вопрос — дальше-то что? После вставки новый стиль не откатывается. Если я продолжу печатать, то весь документ будет в новом стиле. Если я скопирую слово из еще одного документа, стиль опять станет другим, и если печатать дальше, продолжится.
В чем задумка, объясните? Почему в моем документе должны быть стили другого сайта или документа? В чем прикол?
Телеграм, который некоторое время считался адекватным, скатился в эту же яму. Там нет разных шрифтов, но сохраняются начертания (болды и италики). Недавно я писал текст и скопировал термин со StackOverflow, а он был болдом. Телеграм тоже вставил его болдом и не откатил стиль. Печатаешь дальше — все становится болдом. И даже нет кнопки “убрать стиль”.
Вы, конечно, скажете: при вставке зажми Ctrl + Shift + Alt + Command, и оно вставится нормально. А вам не кажется странным зажимать две-три системных кнопки просто для того, чтобы сработало как надо? Может быть, кому нужнен розовый Комик-санс, тот пусть и нажимает?
Словом, может кто-нибудь объяснить, зачем так делают?
-
Журнальный столик
У отелей, гостиниц и съемных квартир есть нечто общее. Точнее, наоборот — кое-чего не хватает, а именно — письменного стола.
Журнальные столики встречаются во множестве. Это убогие поделия не выше колена, от которых ноль пользы и максимум вреда. Пользоваться ими как полноценным столом невозможно. Предполагается, что ты сидишь в кресле, на столике перед тобой — журналы, напитки и гаджеты. На практике до всего этого нужно тянуться, каждую вещь держать в руках, чтобы не брать и ставить по многу раз. Журнальный столик быстро становится пылесборником, а если учесть, что он занимает немало места — хламом.
Журнальный столик банально опасен. Сотню раз было так, что не видишь его из-за своего высокого роста и его низкого. В лучшем случае материшься и жмешь ушибленное место. В худшем легко сыграть в больничку. Дети тоже без конца нарываются на столики, бьют об них бока и пальцы на ногах. Совсем маленькие принимают его за батут: залезают и прыгают по стеклу. Чем это может закончится, ясно всем.
Поэтому когда я заселяюсь в отель или съемную квартиру, отправляю журнальные столики подальше: в шкаф, чулан, на балкон. Если стекло снимается, прячу его под кровать.
Удивляет нелепость ситуации: в квартире якобы два стола, но оба они журнальные, и работать за ними невозможно. Остается работать за кухонным столом, но нужно убрать посуду, крошки, все жидкости.
Как никто другой я понял коллегу, когда подслушал его разговор с эйчаром. Та собирала его в командировку и спрашивала пожелания к квартире. Он ответил: главное, чтобы там был большой письменный стол. Не педерастический журнальный столик, а нормальный стол здорового человека.
Мысленно обнял его и сказал: чел, ты не один такой, я знаю как оно чувствуется.
-
Презентация в Хроме
Только что разговаривал по телефону, объяснял, как открыть PDF-презентацию на компьютере. Ощущения — сплошная гребаная боль.
Во-первых, как бы глупо это ни звучало, на Винде нет встроенной открывашки PDF. На дворе 2025 год, но для этих целей нам предлагают Хром и Edge. Можно пинать Мак за что угодно, но только не за качество коробочного софта. Мак полностью готов к работе: там и мощный PDF-редактор, и почтовый клиент, и что угодно. А на Винде этого нет.
Ладно, нашли комп с Хромом. Открывают PDF и не понимают, как его презентовать — ну то есть чтобы по нажатию стрелочек он не скроллился, а листал страницы. Оказалось, в правом верхнем углу нужно нажать три вертикальные точки, выпадет меню, там выбрать “Present”. Места в тулбаре — хоть самолет сажай. Но дизайнеру опять не хватило места, и он спрятал кнопку по выпадашку.
Спрашивается, почему стоматолог должен разгребать это дерьмо? Ставить на комп Акробаты и Хромы, чтобы открыть формат, которому 30 лет? Почему он должен обшаривать выпадашки в поисках нужной кнопки?
Частично эта заметка перекликается с прошлой про дизайнеров. Причина в том, что дизайнер интерфейса — это обезьянка, которая отрабатывает зарплату. Если бы дизайнер хоть раз что-то презентовал из Хрома, он бы понял, что шариться по выпадашкам неудобно, а нетехнический человек вообще не поймет, что делать.
Микрософт тоже молодцы: в который раз обновляют “Блокнот”, превращая его черт знает во что. А как открыть PDF — ставьте Хром.
Все это вроде как незаметно, но проступает, когда проговариваешь вслух. Натурально, когда говоришь “старт, программы, Хром, перетащи в него файл, потом правый верхний угол, многоточие, презентовать” — понимаешь, какой бред ты несешь.
И пока что не видно, чтобы из этого бреда был какой-то выход.

-
AI и Apple
В определенном смысле мне жаль компанию Apple. Каждый вшивый блоггер пинает их за то, что они отстают в гонке ИИ. Гугл в этом плане, наоборот, на коне: пихают ИИ в каждую выпадашку, в каждую менюшку. У Гугла есть свой браузер, абсолютный монополист, и сегодня он напичкан ИИ-функциями. Фактически Хром — выставка достижений Гугла, витрина всех его сервисов.
Мне жаль Apple, потому что ИИ — определенно не их конек, но их вынудили играть на чужом поле и по чужим правилам. О том, чтобы догнать Гугл, речь уже не идет: тут хотя бы показать что-нибудь. Но пока что все громкие обещания отложены. Стоит ли говорить, что в таких условиях выиграть невозможно.
Меня печалит, что лучшие разработчики Эпла работают день и ночь, чтобы выкатить сырую ИИ-хрень и успокоить инвесторов. Эту хрень я в лучшем случае выключу, либо научусь ее игнорировать. Эти усилия можно было направить в полезное русло: стабилизацию софта и его производительность, например. Но об этом сегодня смешно говорить.
Так, в последнем обновлении Эпл предложил “интеллектуальную” сортировку писем. Разумеется, я отказался, даже не проверяя, что это. Я работаю с почтой 25 лет и за это время сформировал свои правила. Если письма начнут падать не туда, где я их ожидаю, это будет катастрофа. И вообще, почту уже некуда развивать: ей полвека, есть система папок, фильтры, правила. А ведь какой-то бедняга сидел и программировал этот ИИ-бред. Пил кофе, курил сигареты, трекал часы. Жаль человека.
На мой взгляд, борьба на рынке ИИ не принесет Эплу пользы. По-хорошему им нужно ответить чем-то другим, чтобы переломить повестку. Например, выкатить принципиально новый дизайн, причем не скруглить кнопки и добавить воздуха, а придумать что-то принципиально иное. Примерно как в прошлом веке придумали кнопки “копировать” и “вставить”. Это сейчас они в каждом утюге, а тогда стали революцией. Вот и сейчас нужно что-то такого же масштаба. Это может быть и не дизайн, а некое переосмысление того, как человек взаимодействует с устройствами и софтом.
Словом, нужно то, что позволит сказать: ребята, пока вы долбились со своим ИИ, лучшие умы опять всех опередили. Теперь правильно делать так, а не эдак. Лузеры будут скулить, но все равно перейдут на нашу сторону. Так делал Джобс. Справедливости ради, даже с учетом всех искажений продукты у него выходили что надо.
История знает случаи, когда руководитель не ввязывался в текущую повестку, а навязывал свою. Например, товарищ Сталин прекрасно знал, что конкурировать с Америкой в океане он не может, а танки плавать не умеют. Поэтому он сделал ставку на космос и добился там первенства. Американские космонавты в обязательном порядке учили русский язык, он играл в космосе такую же роль, как итальянский — в музыке, а латынь — в медицине. Сейчас это кажется небылицей: представьте, что в айти международным языком стал русский. А ведь на короткий период именно так и было.
Мораль тут простая: нельзя играть против конкурента на его поле. Я бы искренне не хотел, чтобы лучших разработчиков Эпла бросали в ИИ, а остальное делали по остаточному принципу. Эпл должен навязать что-то свое. Других способов выбраться из ямы, в которую они себя загнали, я не вижу.
-
ИИ заменит
Говорят, что ИИ скоро заменит разработчиков. Похоже, это наконец сбылось — вместо человека мне отвечает нейросеть.
Вот как это было: с утра падают билды. Причина в том, что определенный образ качается из Докера слишком часто, и он отвечает с кодом 429: Too many requests. И сообщенька: мол, убавь пыл, горячий ты наш.
Пишу об этом девопсу: Джон, давай перенесем этот образ из Докера в наш репозиторий? Потому что иначе ошибка 429, слишком много запросов к Докеру.
Что же ответил Джон? Иван, я посмотрел документацию, код 429 означает слишком частые обращения. Подожди немного и повтори билд. И заботливая ссылка на сайт Мозиллы со статьей про HTTP-код 429.
Словом, и не поспоришь — да, заменил. Возразить нечем.
-
Стереокартинки
В детстве я любил стереокартинки. У меня был альбом с ними, и я их подолгу рассматривал. Мне казалось это магией: на плоской бумаге возникала 3D-сцена, и это было невероятно. Были картинки, где текстура удачно совпадала с моделью, и от этого становилось еще круче.
Недавно ходили с дочкой в книжный магазин, и я купил набор карточек со стереокартинками. Теперь сижу и рассматриваю по вечерам. Такая вот простая радость.
Оказалось, в семье никто кроме меня этого не умеет. Пытаюсь научить жену и старших детей, но не получается (UPD: получилось). Младшая, которой три с половиной, посмотрела на карточку и сказала: папа, что ты тут намазал?
Завтра попробую другой подход. А вам вопрос: любите стереокартинки? Умеете их смотреть?
-
Правильное ООП
Словосочетание “правильное ООП” звучит для меня как “коренной москвич”. В середине прошлого века кому-то было важно, приехал человек из региона или родился в столице. А сегодня в адрес тех, кто применяет этот тезис, крутят пальцем у виска.
То же самое я чувствую, когда говорящая голова ездит по городам с лекцией о “правильном” ООП. Тут можно сказать одно: современное программирование настолько широко и сложно, что искать в нем “правильное” ООП — то же самое, что искать “правильное” изложение “Колобка” или “Курочки Рябы”. Все версии правильные — бери по вкусу.
Этот тезис закрывает любую лекцию по ООП.
-
Форматирование строк
Шел 2025 год, а в Питоне делают очередное форматирование строк. На этот раз оно называется t-строки из-за префикса t. Такие строки по-настоящему всемогущи: могут делать любые преобразования, ходить по модулям, вызывать такси и заказывать пиццу. Без шуток, найдется тот, кто напишет на них интерпретатор Питона.
Может показаться странным, но именно из-за подобных штучек я завязал с Питоном. Я любил его где-то до версии 2.7, ну и немного третью. Переход на тройку был тяжелым, но необходимым, и это можно было стерпеть. А потом начались бесконечные улучшения: новые операторы, синтаксический сахар на каждый чих, f-строки, t-строки и так далее.
Я понял, что не успеваю за Питоном. Как его ни изучай, энтузиасты навалят новых PEP-ов. Для конкретного проекта это не страшно, но перейдешь в другой — а там уже затянули все нововведения, и сиди разбирайся.
Особенно меня коробит форматирование строк. Напомню, что в Питоне, наверное, десять способов форматировать строки, и число вариантов все растет. Есть процент с кортежем, есть метод
.format, есть f-строки,string.Template, сейчас готовят t-строки. Это только стандартная библиотека, а еще полно сторонних пакетов.Крафтить подобные вещи интересно, я не спорю. Но почему не нашлось никого, кто бы сказал: братцы, мы делаем херню. Плодим одно и то же, засоряем стандартную библиотеку. Неужели, имея с десяток способов сделать X, нужно писать еще один? Где был это человек? Или их выгнали?
Мое любимое занятие — форматировать процентом (как в Си) и выкладывать на ревью. У питонистов начинается пожар: они говорят, что есть f-строки, что процент использовать не надо, а почему — объяснить не могут. Со стороны кажется, что у них чешутся внутренности: так странно они себя ведут. Если здесь уязвимость, покажи, как она работает. Если медленно, сделай замеры. Но нет, карго культ: мы делаем так, потому что мы так делаем.
Современный Питон переусложнен. Он без конца развивается, и это обратная сторона популярности. Как писатель, которого вынудили писать одно, хотя душа лежит к другому. Каждый раз, когда читаю про новый оператор, думаю об одном: боже, как хорошо, что в Кложе нет новых операторов в каждом релизе. Там все просто: хочешь оператор — пишешь макрос, выносишь в библиотеку и делаешь анонс в Слаке. Все довольны и ставят пальчики.
Бесконтрольное развитие языка — тоже плохо. Это трудно заметить в моменте, потому что эффект проявляет себя десятилетиями. Но нужно держать его в голове.
Writing on programming, education, books and negotiations.